AI 에이전트의 90%가 '이중 절벽'에 직면: 범용 AI의 한계와 전문 AI의 딜레마
2025년 8월 28일Ollie @puppyone
 이미지 출처:puppyone
이미지 출처:puppyone
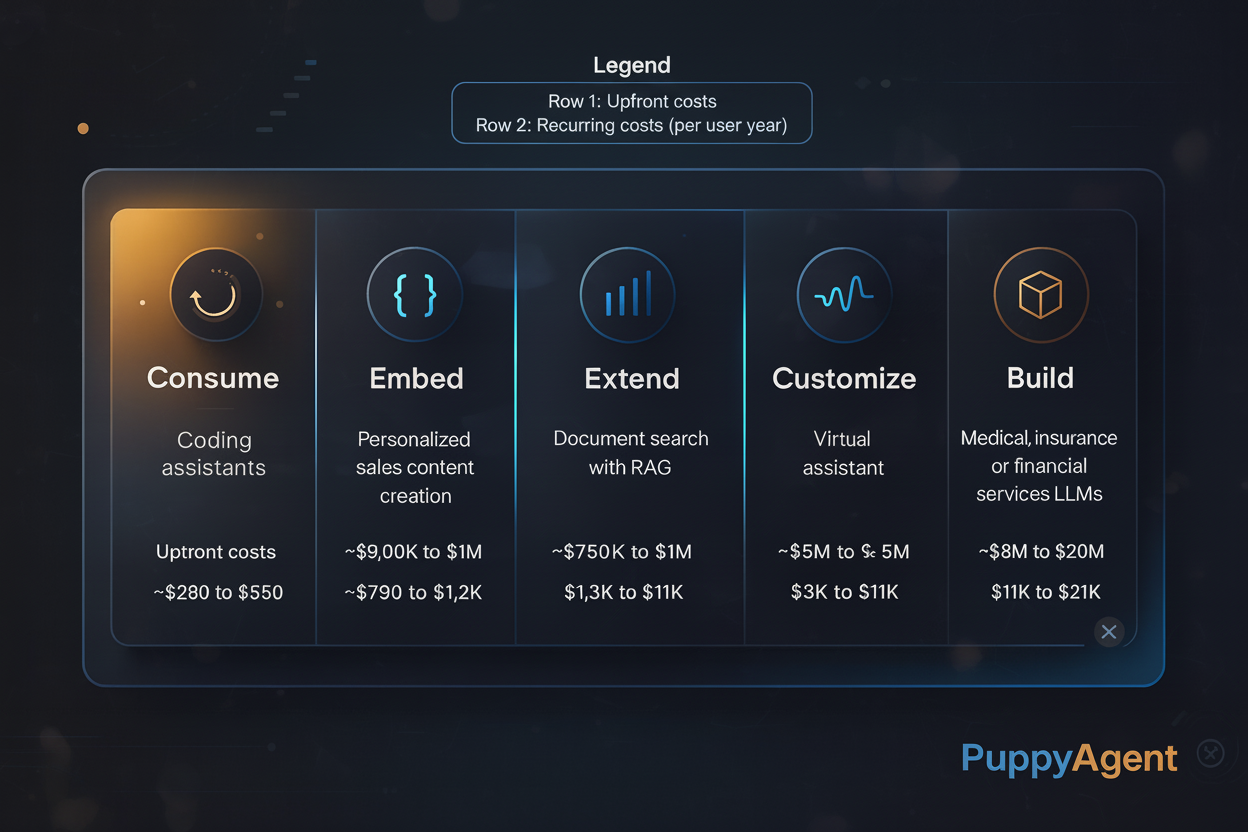
가트너 2025 보고서에 따르면 기업 AI 프로젝트의 83%가 기대에 미치지 못한다고 합니다. AI 산업은 여전히 "범용주의자" 대 "수직적 전문가"의 장점을 논쟁하고 있지만, 혹독한 현실이 나타나고 있습니다: AI 에이전트 회사의 90%가 "불충분한 일반 역량 + 수직적 데이터 부족"이라는 이중고에 빠져 있습니다. 정답이 없는 이 딜레마 속에서 에이전트 프로젝트의 90%가 조용히 실패를 향해 가고 있으며, 생존자들은 절벽 끝에서 살아남기 위한 새로운 방법을 찾고 있습니다.
앞쪽 절벽: 범용 에이전트의 "역량 절벽"
의도 이해와 지시 따르기는 에이전트의 두 가지 중요한 기본 역량입니다. 전통적인 기초 대형 모델은 더 이상 복잡한 작업의 요구를 충족할 수 없습니다. 에이전트는 다양한 워크플로우, 시스템 및 제어를 필요로 하며... 기본 모델을 구현 가능한 시스템으로 캡슐화해야 합니다.
범용 에이전트의 비전은 매력적입니다—다양한 분야의 문제를 해결할 수 있는 단일 지능형 개체입니다.
 이미지 출처:puppyone
이미지 출처:puppyone
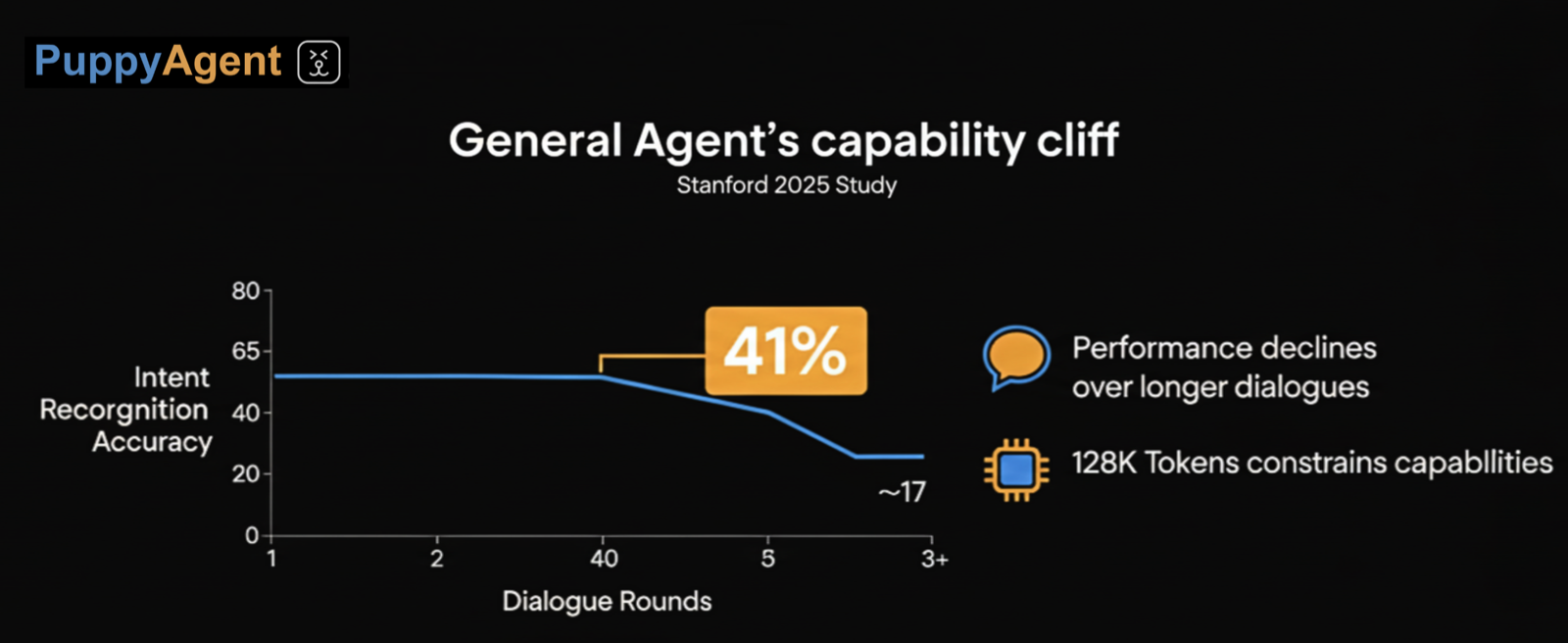
그러나 대부분의 회사가 소위 범용 AI 에이전트를 전문적인 시나리오에 적용하려고 할 때, 종종 "역량 절벽"에 부딪힙니다. 스탠포드 대학의 2025년 테스트는 충격적인 사실을 밝혔습니다: 사용자 지시가 세 번의 대화를 초과하면 범용 에이전트의 의도 인식 정확도가 41%로 급락합니다. 클로드와 같은 모델이 시스템 프롬프트를 128K 토큰으로 확장했지만, 다중 역할 시나리오에서 이러한 에이전트는 여전히 사용자의 진정한 요구를 자주 혼동하여 간단한 문의를 복잡한 결정으로 잘못 판단합니다.
더 위험한 것은 확장된 환각의 덫입니다.
금융 리스크 통제와 같은 전문적인 시나리오에서 범용 에이전트가 생성한 콘텐츠의 오류율은 52%에 달하며, 이러한 오류는 종종 규제 조항을 조작하거나 통계 데이터를 꾸며내는 등 전문적인 어조로 제시됩니다. 한 은행은 한때 일반적인 리스크 통제 에이전트 개발에 막대한 투자를 했지만, "고객 과거 행동 + 시장 변동 + 정책 변경"을 포함하는 복합적인 결정을 처리할 때 오류율이 65%를 초과하여 회사가 검증을 위해 3.2배의 인력을 투자해야 했습니다. 교차 분야 마이그레이션에 대한 MIT 실험은 의료 분야에서 훈련된 에이전트를 법률 시나리오로 이전했을 때 작업 통과율이 78%에서 32%로 떨어졌다는 것을 증명했습니다. 핵심 문제는 행동 공간의 일반화 불가능성에 있습니다. 도구 사용 인터페이스가 의료 API에서 금융 API로 전환될 때 에이전트는 행동 공간을 적응적으로 조정할 수 없습니다.
많은 회사들이 "데모를 실행할 수 있다"를 "비즈니스 가치가 있다"와 동일시하는 위험한 오해에 빠져 있습니다.
 이미지 출처:puppyone
이미지 출처:puppyone
한 자동차 제조업체는 한때 "범용 고객 서비스 에이전트" 훈련에 2천만 달러를 투자했지만, "타이어 유형 + 날씨 + 운전 습관"과 관련된 복합적인 결정을 처리할 수 없었기 때문에 실제 시나리오에서는 실패했습니다. 이는 핵심적인 역설을 드러냅니다: 범용 에이전트가 "만능"을 추구할수록 수직적 시나리오에서의 신뢰성은 낮아집니다.
"우리는 지능형 에이전트를 훈련하는 것이 아니라, 전문적인 복장으로 환각을 꾸미고 있습니다." 범용 에이전트의 딜레마는 모든 것을 할 수 없다는 것이 아니라, 전문적인 시나리오에서 기본적인 행동조차 안정적으로 수행할 수 없다는 것입니다.
Back Cliff: The "Resource Cliff" of Vertical Agents
When companies turn to vertical Agents for a breakthrough, they find themselves falling into another "resource cliff."
Core industry data is like treasure locked on an island: diagnostic data from top-tier hospitals, bank risk control logs, and other key assets are inaccessible to 91% of companies due to compliance barriers. What's more severe is the data quality trap. An industrial AI team spent eight months obtaining equipment failure data, but 67% of it was invalidated due to inconsistent labeling standards—vertical data requires industry know-how to be used correctly. Real cases show that the cost for a medical AI company to obtain 100,000 compliant and labeled data points has soared from 830,000 yuan in 2022 to 4.12 million yuan in 2024, a staggering increase of 400%.
 Image Source:puppyone
Image Source:puppyone
Even more scarce than data are the hybrid talents who can bridge the gap between technology and industry. In the development of financial Agents, engineers who can master both quantitative trading logic and RLHF (Reinforcement Learning from Human Feedback) tuning are in short supply, with a market availability of less than 3.7% of the demand, resulting in an astonishing supply-to-demand ratio of 1:27. The communication breakdown between industry experts and AI engineers often leads to disastrous outcomes: industry experts produce vague experience-based "rule fragments," which AI engineers then force into "erroneous knowledge graphs," causing the final Agents to deviate significantly from the essence of the business. A manufacturing client requested the development of a "device failure prediction Agent," but the industry experts were unable to describe the "spectral characteristics of bearing noise" in technical terms, leading to model training that completely missed the actual requirements.
The dilemma of vertical Agents is not only about not being able to obtain data, but also about not being able to understand or use the data correctly even when it is obtained.
Survival Strategy: The Three-Step Breakthrough Method to Bridge the Double Cliff
At present, most base models rely on distillation from series of models like GPT and Claude. The majority of data has not been labeled for their own business scenarios and regional/national conditions. Simply constructing workflows and adding RAG (Retrieval-Augmented Generation) and other means cannot achieve truly end-to-end implementation capabilities.
Many companies or organizations haven't even sorted out their own business data flywheels, let alone drive business growth with Agents.
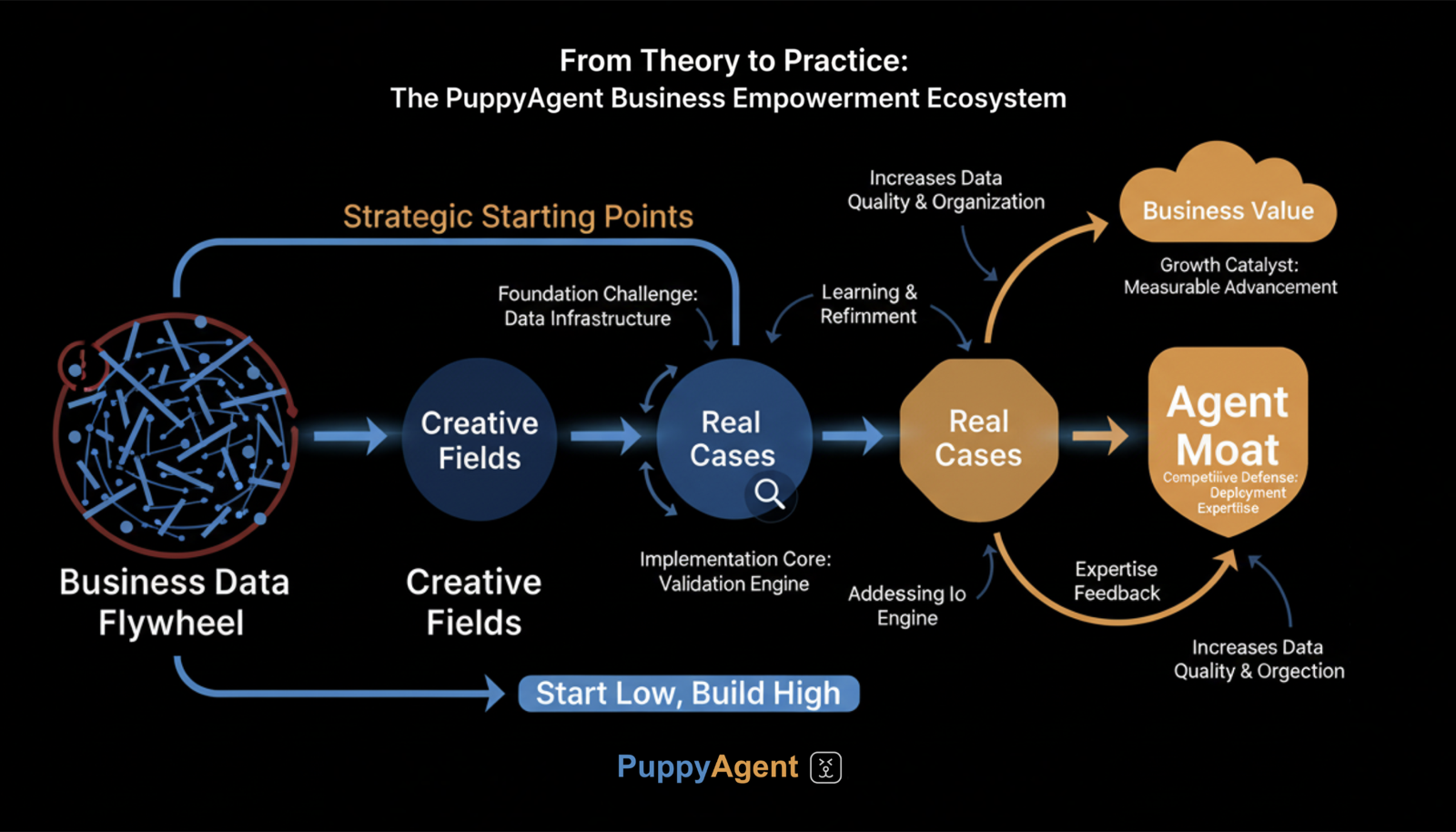 Image Source:pexels
Image Source:pexels
In this awkward situation, what may be more important is to be able to use Agents to truly create more business value-adding scenarios. If high accuracy is not available, one can start with creative fields that require lower accuracy; if there is a lack of data, one can explore business entry points with more open-source data. The fundamental thing is to obtain more real cases, so as to build one's own Agent moat in actual combat.
If you also want to throw away the complicated work at hand, please click the "Get Started" on the side to explore the business possibilities brought by puppyone.
puppyone has always been exploring the use of dynamic interactive RAG and Agents to serve real business growth in workflows. We hope to inspire users with each end-to-end case, rather than boasting about our generalizability, nor being confined to a single vertical scenario. We have now implemented numerous cases in fields such as customer service,housing rental,legal affairs,and document management.You can click to watch the case videos.
Conclusion
Excellent cases and companies all share a common feature: they no longer focus on creating the "perfect Agent," but on building a "human-machine collaborative decision-making system," setting up safety rails at key nodes and unleashing Agent efficiency in routine scenarios.
For companies teetering on the edge of the cliff, the primary task is to face the reality: general Agents can't do everything, and vertical Agents can't firmly grasp core resources. The real way out lies in systematic thinking—organically combining industry knowledge distillation, small data enhancement, and human-machine collaborative verification to form an implementable "three-step breakthrough method."
 Image Source:puppyone
Image Source:puppyone
We may repeatedly ask Manus/Genspark, if one day OpenAI and Google really achieve general Agents, where will your competitiveness be? We may also ask OpenAI and Google what the real difficulties in scaling scenarios and generalizing workflows are. Essentially, this is a tightrope hanging between cliffs.
Is your company ready to walk this tightrope?