컨텍스트 엔지니어링: RAG로 충분하지 않을 때
2026년 2월 10일Ollie @puppyone
핵심 요약
- 코퍼스가 작고, 질문이 로컬이며, 거버넌스가 가벼우면 기본 RAG로 충분하다. 그 외에는 전용 컨텍스트 레이어가 필요하다.
- 컨텍스트 레이어는 지식을 구조화 Know‑How(JSON/그래프)로 재구성하고, 하이브리드 인덱싱(dense + sparse + graph)과 결합하며, 출처·ACL·버전 관리로 거버넌스한다.
- 그래프·트리 강화 검색은 벡터 전용 RAG가 교차 문서·글로벌 쿼리에서 어려움을 겪는 격차를 메운다. Microsoft Research의 GraphRAG(2024) 참조.
- 서브 에이전트 오케스트레이션과 엄격한 요약 예산으로 컨텍스트를 고신호·테스트 가능하게 유지한다. Anthropic의 효과적 컨텍스트 엔지니어링 가이드와 일치.
- 거버넌스는 선택 사항이 아니다. NIST AI RMF는 출처와 라이프사이클 제어를 신뢰 시스템의 중심에 둔다.
반론적 판단 기준: RAG로 충분한가 vs. 컨텍스트 레이어가 필요한가
단순하게 시작하고 조급한 인프라를 피한다. 다음이면 컨텍스트 레이어는 아마 불필요하다:
- 코퍼스가 작고, 대부분 정적이며, 한두 시스템에 존재한다.
- 질문이 로컬이고 단일 홉이다(예: "제품 X의 보증은?").
- 지연 시간 SLO가 유연하고, 가끔 놓치는 것을 견딜 수 있다.
- 거버넌스가 가볍고, 감사 가능한 트레이스나 엄격한 ACL이 필요 없다.
전용 컨텍스트 레이어가 필요한 경우:
- 데이터가 Docs, Slack, Notion, DB, 외부 SaaS에 분산되어 있고 자주 변경된다. 검색 기업도 커넥터에 투자 중. Perplexity의 Carbon 인수 2024 참조: Perplexity welcoming Carbon.
- 에이전트가 글로벌·교차 문서 질문에 답하고 다단계 워크플로를 계획해야 한다. 벡터 전용 검색은 여기서 실패한다. Microsoft 팀이 arXiv 2024에서 그래프 강화 전략을 설명: A Graph RAG approach to query‑focused summarization.
- 출처, 접근 제어, 버전 관리, 롤백이 필요하다. NIST AI Risk Management Framework의 GOVERN 기능과 일치.
- 결정론과 테스트 용이성이 중요하다: 재현 가능한 컨텍스트 조립, 설명 가능한 검색 트레이스, 컨텍스트 업데이트용 CI. Anthropic의 서브 에이전트와 엄격한 컨텍스트 위생 가이드 참조: Effective context engineering for AI agents.
RAG를 넘어서는 컨텍스트 엔지니어링 아키텍처
구조화 Know‑How와 스키마
비구조화 HTML은 기계에 노이즈다. 컨텍스트 레이어는 절차, 엔티티, 제약, 비즈니스 규칙을 구조화 Know‑How로 변환한다: 명확한 스키마를 가진 JSON 문서와 그래프:
{
"entity": "PurchaseOrder",
"id": "PO-2026-1783",
"vendor": {"name": "Acme", "id": "V-882"},
"line_items": [
{"sku": "X12", "qty": 5, "unit_price": 49.00}
],
"approval_policy": {
"threshold": 10000,
"requires_dual_signoff": true,
"exceptions": ["emergency"]
},
"provenance": {"source": "ERP", "version": "v14.2", "ingested_at": "2026-02-06"}
}
이 스키마화된 컨텍스트는 에이전트에게 부서지기 쉬운 텍스트 스팬 대신 기계 가독 로직과 감사 용이성을 위한 출처를 제공한다.
하이브리드 인덱싱과 라우팅
- 밀집 의미 검색이 토픽 유사성을 빠르게 찾는다.
- 희소 어휘 인덱스가 정확한 용어, ID, 정책 언어를 보존한다.
- 그래프/트리 구조가 다중 홉 추론을 위한 관계와 계층을 인코딩한다.
함께 결정론적 검색을 가능하게 한다: 클러스터 또는 그래프 이웃으로 라우팅한 뒤, 최소·관련 컨텍스트를 stitch. Weaviate best practices for hybrid search 참조.
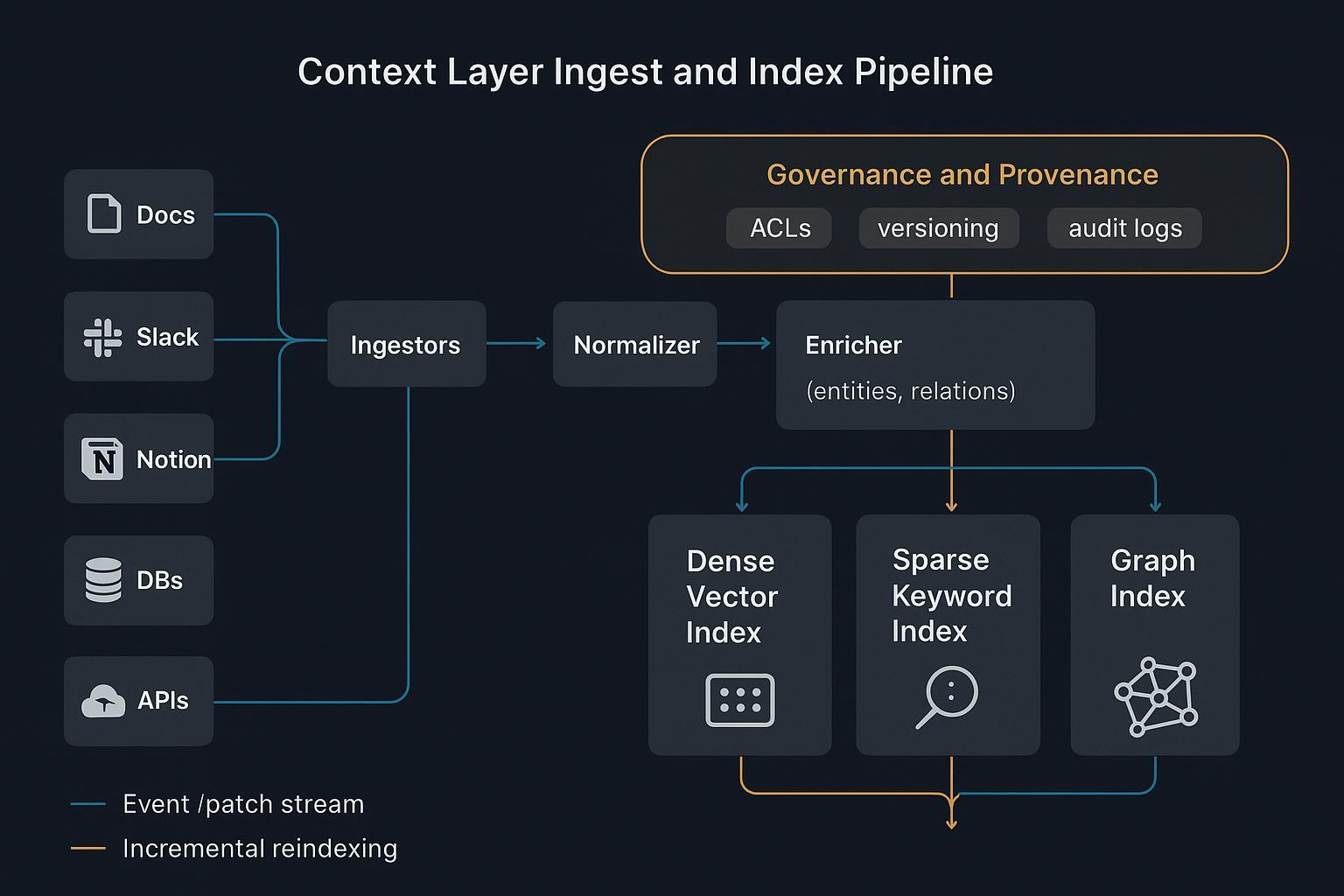
런타임 스티칭과 오케스트레이션
에이전트는 원시·노이즈 많은 덤프를 "생각"하려 할 때 실패한다. 런타임은 이렇게 보여야 한다:
- 플래너가 필요한 증거와 도구를 가설화한다.
- 라우터가 dense, sparse, graph 인덱스에 쿼리를 분산한다.
- 게이트가 출처와 정책으로 필터링한다; 스티처가 컴팩트하고 잘 정의된 번들을 구성한다.
- 서브 에이전트가 좁은 작업을 수행하고 합성기에게 엄격한 요약을 반환한다.
# 하이브리드 검색 + 스티칭 의사코드
plan = planner.make_plan(user_query)
results = []
for hop in plan.hops:
dense = dense_index.search(hop.query, k=10)
sparse = sparse_index.search(hop.query, k=10, filter=plan.filters)
graph_ctx = graph.walk(hop.entities, depth=2)
gated = gate.by_provenance(dense + sparse + graph_ctx)
stitched = stitch.compact(gated, budget_tokens=1200)
results.append(stitched)
final = synthesize(results, tools=plan.tools)
return final
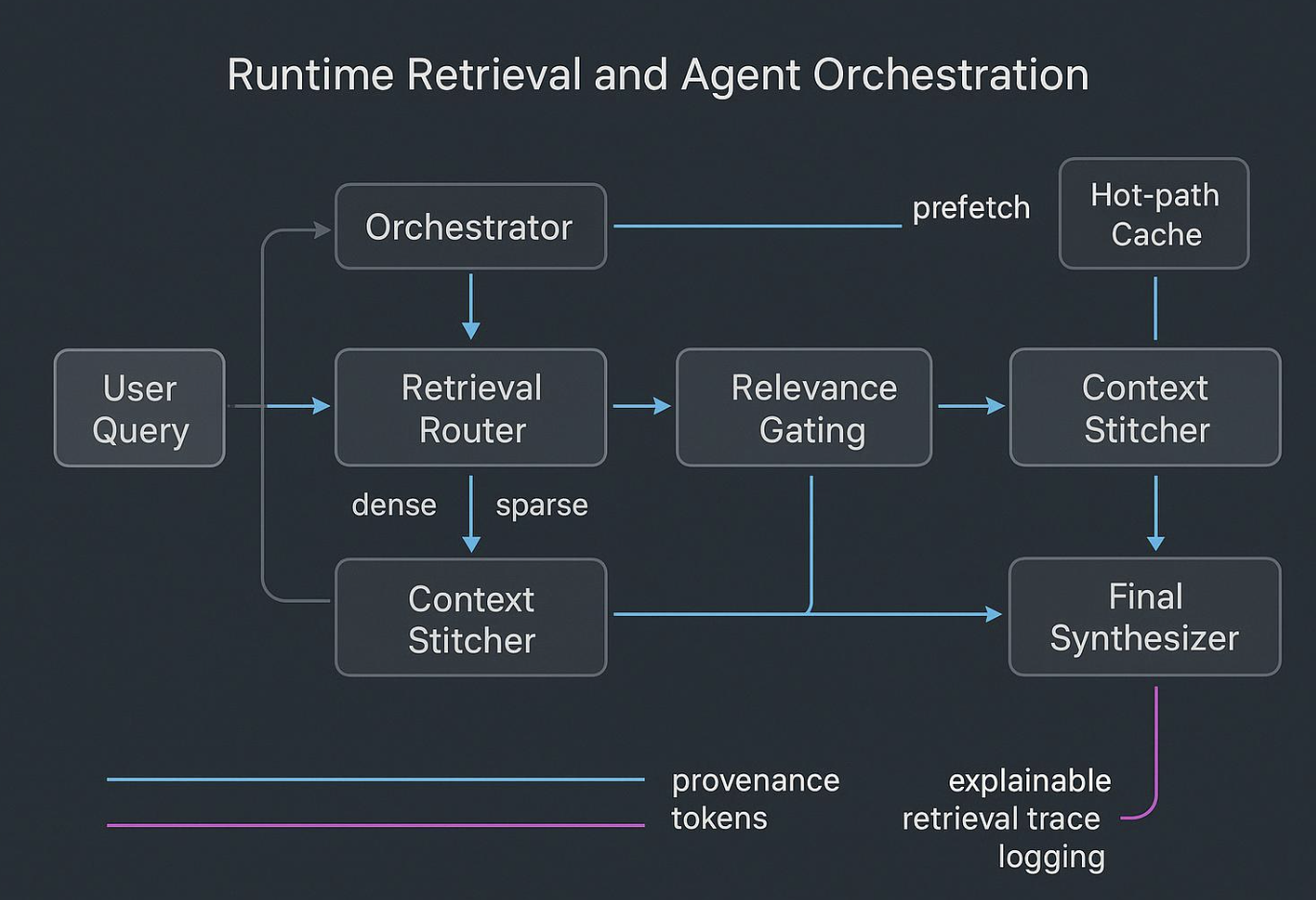
컨텍스트 파이프라인 체크리스트
- 소스 수집 → 정규화 → 스키마 매핑.
- 엔티티와 관계로 풍부화 → 구조화 Know‑How로 저장.
- 출처 메타데이터와 함께 하이브리드 인덱스(dense, sparse, graph) 구축.
- ACL, 버전 관리, 감사 로그로 게이트.
- 배포 전 검색 충실도와 태스크 수준 결과 평가.
- 핫 경로 캐시와 프리페치로 배포.
- 지연 시간, 정밀도/재현율, 드리프트, 감사 트레이스 모니터링.
경량 마이크로 벤치마크: 지연 시간 vs. 답변 품질
이 설계로 세 가지 검색 패턴을 비교할 수 있다. 작고 재현 가능하게 유지한다.
가정: 5만 문서(정책, 티켓, 제품 스펙); 75개 평가 쿼리, 40개에 ground truth; 동일 LLM; 하드웨어 동등; 해당 시 리랭커. p50/p90 중앙값 지연 시간과 EM/F1 또는 문서화 LLM 판사로 품질 보고.
| 패턴 | 검색 스택 | 예상 특성 |
|---|---|---|
| 순수 RAG | Dense만 | 빠름, 글로벌 일관성 낮음; 교차 문서 질문에서 어려움 |
| 튜닝 RAG | Dense + sparse + 리랭커 | 중간 지연, ID·정책 용어에서 정밀도 향상 |
| 컨텍스트 레이어 | Hybrid + graph + 스티칭 + 요약 | p50 지연 약간 높지만 p90은 타이트; 더 안정적인 글로벌 답변 |
해석: 튜닝 RAG는 많은 쉬운 놓침을 고친다; 컨텍스트 레이어는 교차 문서·다단계 태스크에서 빛나며, 라우팅과 캐시로 테일 지연이 더 예측 가능해진다.
실패 모드와 완화
- 문서 간 파편화: 엔티티/관계 그래프 구축, 로컬/글로벌 순회로 응집 번들 수집; 긴 서사에 계층적 앵커 추가.
- 부패와 드리프트: 이벤트 소스 수집, 증분 재인덱싱, TTL; 스키마 업그레이드 시 변경 로그 재생.
- 부하 시 지연 스파이크: 계층형 핫 경로 캐시, 클러스터 라우팅, 흔한 서브 쿼리 프리페치; 샤드 크기 조정, 가능한 곳에서 양자화.
- 노이즈 컨텍스트로 인한 환각: 스키마와 출처 필터 적용; 서브 에이전트 범위 축소; 원시 덤프 대신 컴팩트 요약 선호.
- 거버넌스 격차: 검색 트레이스와 도구 호출 로깅; 설명 가능한 증거 라인 요구; 평가 임계값과 롤백 계획으로 배포 게이트.
실용 마이크로 예시: 구조화 Know‑How와 하이브리드 인덱싱 실전
구매 에이전트를 구축하며 공급업체 견적을 조립하는 동시에 승인 정책을 적용한다고 가정한다. ERP 내보내기, 계약 PDF, Slack 승인, 이메일 요약을 수집한다. 수집 파이프라인은 공통 스키마(PurchaseOrder, Vendor, Policy, Exception)에 매핑한다. 엔티티 링크로 풍부화해 각 PurchaseOrder가 Vendor와 해당 Policy 노드를 알도록 한다. 밀집 인덱스로 의미적 회상, 희소 인덱스로 ID와 법적 용어, 그래프 인덱스로 Policy→Exception→Approver 경로를 탐색한다.
이 설정에서 오케스트레이션 루프는 "PO‑2026‑1783을 오늘 승인할 수 있는가?" 쿼리를: PO ID 희소 조회, 해당 PO에서 Policy와 예외로의 그래프 순회, 최신 승인자 메모 밀집 검색으로 라우팅한다. 스티처가 1.2K 토큰 번들로 압축하고, 에이전트는 승인 결정과 출처 링크가 있는 간결한 인용 답변을 생성한다.
Puppyone 같은 플랫폼은 지식을 구조화 Know‑How(JSON/그래프)로 저장하고 텍스트와 구조에 대한 하이브리드 인덱싱을 지원해 도움이 된다. 이 조합으로 부서지기 쉬운 텍스트 스크래핑에 의존하지 않고 결정론적 검색 패턴과 감사 가능한 트레이스를 가능하게 한다.
컨텍스트의 거버넌스와 CI
컨텍스트를 코드처럼 취급한다. 모든 변경에 출처, 리뷰, 테스트를. 버전 관리된 스키마, 접근 정책, 평가 스위트 유지. 롤아웃 전 검색 충실도 검사와 태스크 수준 테스트 실행; 설명 가능 트레이스 캡처 및 롤백 준비. 에이전트가 규제·민감 데이터를 다루면 NIST AI Risk Management Framework의 GOVERN에 맞춘다. 상호운용: Model Context Protocol.
다음 단계
문제가 로컬이고 위험이 낮으면 튜닝 RAG로 시작한다. 교차 문서 질문, 거버넌스 요구, 변동 코퍼스가 보이면 한 워크플로에 초점을 둔 컨텍스트 레이어 파일럿을 계획한다. 먼저 구조화 Know‑How를 구축한다; 스키마가 안정되면 하이브리드 인덱싱과 오케스트레이션이 훨씬 간단해진다. 평가를 꽉 짜고 사람답게: 실제 태스크 테스트, 트레이스 로깅, 개선을 비즈니스 SLO에 연결한다.
FAQs
Q1: 지금 그래프가 필요한가?
A: 아니오. 먼저 dense + sparse; 교차 문서 추론이나 글로벌 요약 격차가 생기면 그래프를 추가한다.
Q2: 청크 크기는?
A: 스키마에 묶인 의미 단위(엔티티, 절차)로 청크. 고정 토큰 수가 아니다. 리랭커와 요약에 나머지를 맡긴다.
Q3: 거버넌스를 나중에 해도 되는가?
A: 할 수 있지만 대가를 치른다. 평가와 롤백이 가능하도록 첫날부터 가벼운 출처와 접근 제어를 추가한다.