고객 서비스 자동화를 위한 Agentic RAG 배포 가이드
2026년 4월 8일Lin Ivan
고객 서비스는 LLM에게 매우 가혹한 환경입니다. 질문은 애매하고, 문서는 낡기 쉽고, 데이터는 민감하며, 실패는 바로 실제 고객 앞에서 드러납니다.
프로덕션 트래픽을 견디는 자동화를 원한다면 단순한 RAG 데모로는 부족합니다. 요청을 라우팅하고, 올바른 근거를 찾고, 툴을 안전하게 호출하며, 확신이 없을 때는 사람에게 넘길 수 있는 agentic 시스템이 필요합니다.
배포 전에 무엇을 자동화할지 정의하기
많은 팀이 곧바로 챗봇부터 만들려 합니다. 먼저 해야 할 일은 어떤 workflow를 자동화할지, 그리고 각 workflow에서 "완료"가 무엇인지 정의하는 것입니다.
배포 모드 선택
현실적인 시작점은 다음 중 하나입니다.
- Agent-assist: 시스템이 답변 초안과 근거를 준비하고, 사람 상담원이 전송한다.
- 부분 자동화: 비밀번호 재설정처럼 저위험 intent만 자동 처리한다.
- 확장 자동화: 대부분의 intent를 자동화하지만, 그 전에 충분한 검증을 거친다.
"절대 자동화하지 말 것" 경계 세우기
최소한 다음은 denylist에 넣는 편이 안전합니다.
- 일정 금액 이상의 금전 처리
- 계정 소유권 변경
- 데이터 내보내기
- 규제 대상이거나 고위험인 업무
이런 경우는 즉시 에스컬레이션 하는 편이 맞습니다.
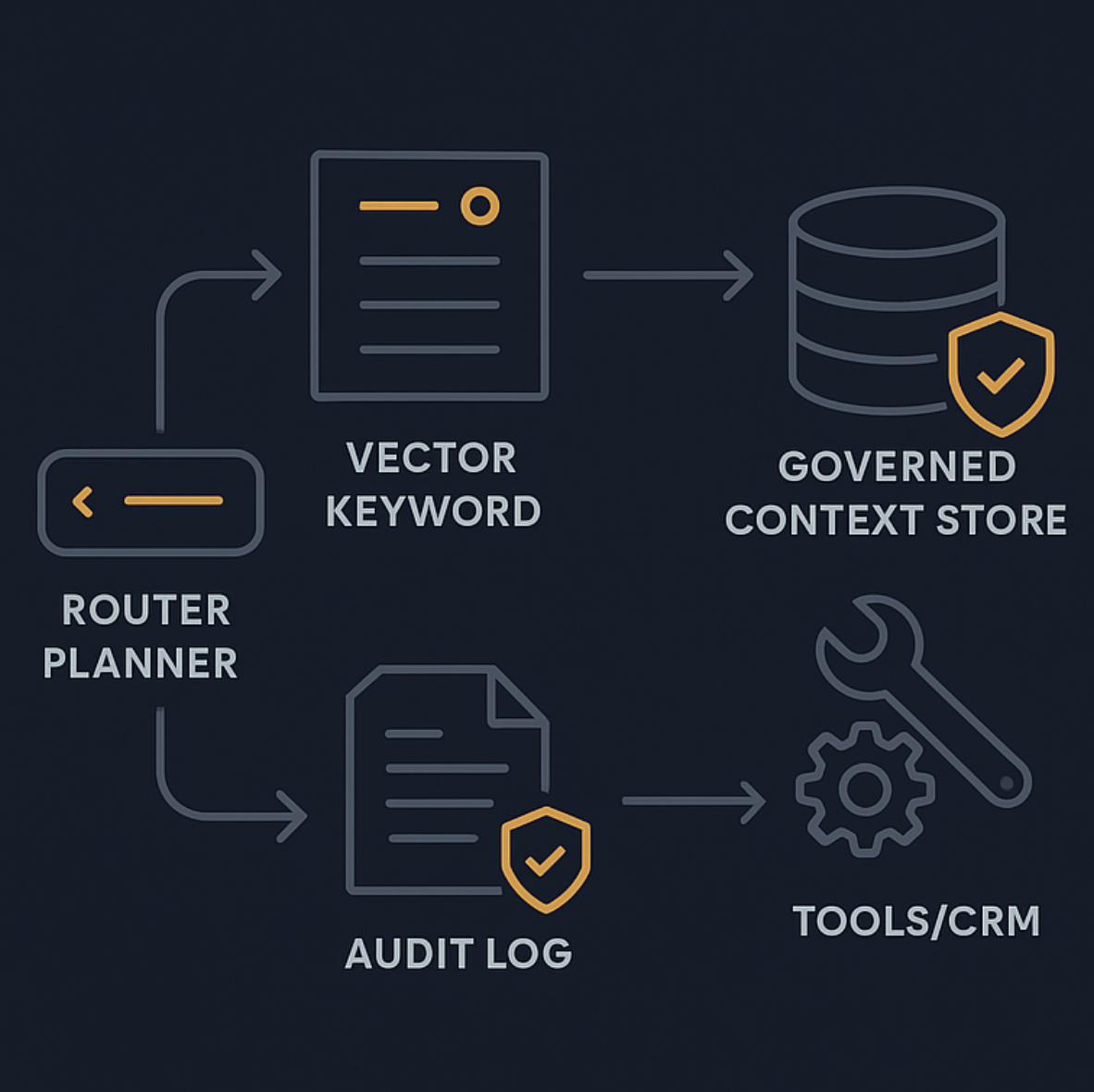
참조 아키텍처: 고객 지원용 Agentic RAG
프로덕션 시스템은 단일 파이프라인이 아니라 guardrail을 가진 의사결정 시스템입니다.
생각을 정리하기 좋은 방법은 Adaline Labs의 production-ready agentic RAG architecture and observability처럼 orchestration, execution, infrastructure 세 층으로 나누는 것입니다.
Orchestration: router + policy engine
이 레이어가 다음 행동을 결정합니다.
- intent 분류
- retrieval이 필요한지 판단
- CRM, 주문 시스템, 티켓 시스템 같은 tool 선택
- 에스컬레이션 규칙과 "절대 자동화 금지" 경계 적용
Execution: retrieval + tool call + response synthesis
이 레이어가 실제 일을 합니다.
- retrieval query 생성
- hybrid retrieval과 reranking으로 evidence 수집
- least privilege로 tool 호출
- evidence 기반 답변 생성
retrieval 결과는 신뢰할 수 없는 입력으로 다뤄야 합니다.
Infrastructure: observability + evaluation + reliability
프로덕션에는 최소한 다음이 필요합니다.
- routing, retrieval, tool call별 trace
- grounding 여부를 판단하는 평가 신호
- retries, timeouts, fallbacks
어떤 근거를 사용했고 왜 그 행동을 했는지 설명할 수 없다면 아직 프로덕션 배포 단계가 아닙니다.
데이터와 retrieval 준비 조건
문서가 지저분하면 모델은 자신 있게 틀립니다.
1. 지원용 지식 코퍼스 만들기
보통 다음이 최소 구성입니다.
- 공개 help center
- 범위가 정해진 내부 runbook
- 환불, 취소, SLA 정책
- 제품 changelog
2. 문맥을 유지하는 chunking 선택
많은 RAG 프로젝트가 여기서 조용히 실패합니다.
의미 단위로 자르고, 각 chunk에 제목이나 요약 같은 contextual header를 붙이는 편이 실무적으로 낫습니다. 참고로 best practices for chunking and hybrid retrieval in production RAG가 있습니다.
3. Hybrid retrieval + reranking 사용
고객 문의에는 정확한 문자열과 애매한 의도가 섞여 있습니다.
그래서 일반적으로는:
- keyword search로 ID와 정확한 용어를 잡고
- vector search로 패러프레이즈를 잡고
- reranking으로 최종 evidence set을 정리합니다
4. freshness와 ownership 메타데이터 추가
최소한 다음은 필요합니다.
- source type
- 마지막 업데이트 시간
- owner 또는 담당 팀
- product / version tag
- 민감도 분류
고객 서비스 자동화를 위한 Agentic RAG 배포 절차
각 단계에는 목적, 출력, done 조건이 있어야 합니다.
Step 1: intent router를 넣고 필요할 때만 retrieval하기
Action: 요청을 소수의 workflow로 분류하는 classifier를 둡니다.
Done when:
- 요청별 intent를 로그로 남길 수 있다
- retrieval이 얼마나 자주 실행됐는지 측정할 수 있다
Step 2: least privilege로 tool boundary 나누기
Action: intent와 risk에 따라 tool access를 분리합니다.
예:
- billing status는 invoice 조회만 가능하고 refund는 불가
- account access는 reset link 전송만 가능하고 ownership 변경은 불가
- 민감한 read 권한과 넓은 write 권한을 같은 workflow에 무제한으로 주지 않기
Step 3: retrieval-time authorization 적용
멀티테넌트 환경에서 여기서의 실패는 치명적입니다.
가장 견고한 패턴은 권한을 authoritative data source에서 집행하고, identity를 retrieval까지 전달하는 것입니다. AWS의 retrieval-time authorization and identity propagation for RAG가 좋은 참고입니다.
Step 4: retrieved text를 untrusted로 취급하고 간접 prompt injection 방어
knowledge base는 일종의 공급망입니다.
retrieved content 안에 악성 지시가 들어 있으면, 시스템 경계가 약할 때 모델은 그 지시를 따를 수 있습니다. 따라서:
- input과 output을 sanitize하고
- system instruction과 retrieved content를 엄격히 분리하고
- 상태 변경 전에는 확인 절차를 두고
- 모든 것을 로그로 남겨야 합니다
Step 5: grounding contract 만들기
모델은 다음을 지켜야 합니다.
- 지식형 질문에는 retrieved evidence만으로 답한다
- 출처를 인용한다
- 근거가 부족하면 거부하거나 에스컬레이션한다
Step 6: verification과 escalation 추가
verifier는 다음을 확인해야 합니다.
- 답변이 policy와 충돌하지 않는가
- intent와 evidence가 어긋나지 않는가
- 금지된 action을 시도하고 있지 않은가
Governance: versioned context, auditability, 안전한 협업
context를 단순한 embeddings 모음처럼 다루는 것은 지원 환경에서는 위험합니다.
프로덕션에서는 최소한 다음을 통제할 수 있어야 합니다.
- 누가 지식을 수정했는지
- 무엇이 바뀌었는지
- 언제 바뀌었는지
- 어떤 버전이 어떤 결정에 사용됐는지
agent-readable file, permission scope, versioning, audit log를 갖춘 governed context layer가 실무적으로 유효합니다.
Evaluation과 observability를 갖춘 뒤 확장하기
측정하지 못하면 개선도 어렵습니다.
최소한 봐야 할 지표:
- retrieval quality
- faithfulness
- escalation rate
- p50 / p95 latency
- intent별 비용
그리고 실제 티켓 기반 eval set을 만들어야 합니다.
Rollout: shadow mode에서 자동화까지
Stage 0: shadow mode
- 시스템이 병렬로 동작하지만 고객에게는 직접 응답하지 않는다
- intents, retrieval, drafts, escalation triggers를 기록한다
Stage 1: agent-assist
- 사람 상담원이 계속 발송한다
- 시스템이 근거와 초안을 제공한다
Stage 2: 부분 자동화
- 좁고 저위험한 intent만 자동 처리한다
- 고위험 흐름은 human-gated로 남긴다
Stage 3: 확장 자동화
모든 action을 evidence에 연결해 설명할 수 있고, knowledge change를 rollback할 수 있으며, tool execution을 kill-switch로 멈출 수 있을 때만 확장합니다.
Troubleshooting: 흔한 실패 패턴
근거 없이 자신 있게 답변함
- 낮은 confidence에서는 거부
- citation 의무화
- routing 정교화
잘못된 policy version을 가져옴
- freshness metadata 사용
- priority rule 추가
- drift detection과 rollback 준비
retrieved content를 통한 prompt injection
- untrusted로 취급
- tool gating 추가
- system과 content 경계 분리
지연 시간 급증
- 모든 요청에 retrieval하지 않기
- 자주 오는 intent 캐시
- 필요한 경우에만 reranking
Key takeaways
- 고객 지원용 Agentic RAG는 router, retrieval, tools, verification, escalation으로 이루어진 workflow system입니다.
- 어려운 부분은 authorization, injection 방어, evaluation, staged rollout 같은 운영 요소입니다.
- context와 decision을 버전 관리하고 감사할 수 있는 governance가 필수입니다.
Next steps
이미 RAG와 tools를 이어 붙이고 있고 permissions, audit trails, rollback 문제를 겪고 있다면 다음을 참고해 보세요.