RAG는 죽지 않았다, 에이전틱 RAG가 더 나을 뿐
2025년 11월 27일Guanqun @puppyone
요약: 이 프로젝트는 오픈소스입니다: https://github.com/puppyone/DeepWideResearch
깨지기 쉬운 RAG 파이프라인을 에이전틱 워크플로우로 대체하여 유지보수의 악몽과 품질 저하 문제를 해결합니다.
하지만 트레이드오프는 분명합니다: 에이전틱 RAG는 기존 RAG(쿼리당 ~$0.01)에 비해 비용(쿼리당 $0.1 이상)이 더 많이 들고 속도(3초 미만 대비 10초 이상)도 느립니다. 대규모 환경에서 1초 미만의 응답 속도가 필요하다면 이 방식은 적합하지 않습니다. 하지만 정확하고 유지보수 가능한 지식 QA가 필요하다면 계속 읽어보세요.
이 글에서는 저희가 새로운 에이전틱 RAG 아키텍처를 구축한 경험을 공유하고, 왜 에이전틱 RAG가 기업용 지식 QA에 필수적인 단계인지 탐구해 보겠습니다.
지난 1년간 저는 각각 100~1000페이지 분량의 문서를 다루는 5개의 기존 RAG 프로젝트를 진행했습니다. 기술 스택은 쿼리 작성, 쿼리 라우팅, 청킹, 임베딩, 재순위화 등 표준적인 방식이었습니다. 처음에는 모든 것이 순조로웠지만, 곧 함정에 빠졌습니다. 전체 프로세스가 극도로 경직되어 유지보수가 매우 어려웠던 것입니다.
가장 고통스러웠던 순간은 문서가 변경되었을 때였습니다. 간단한 변경만으로도 전체 RAG 점수가 떨어졌습니다. 동일한 점수를 유지하려면 전체 파이프라인 전략을 처음부터 다시 구축해야 했습니다. 새로운 데이터 소스가 추가될 때마다 새로운 전쟁을 치르는 기분이었습니다. 복잡한 메타데이터 태깅과 세분화된 청킹으로 땜질 처방을 시도했지만, 이는 무너진 아키텍처에 임시방편일 뿐이었습니다.
우리는 스스로에게 묻기 시작했습니다. 무엇을 잘못하고 있는 걸까?
문제는 로직에 있었습니다. 기존 RAG는 본질적으로 데이터셋에 커브 피팅하기 위해 하드코딩된 if-else 규칙을 작성하는 것과 같습니다. 이는 정적인 코드에는 효과가 있지만, 진정한 지능이 필요할 때는 제대로 작동하지 않습니다.
OpenAI의 Deep Research에서 영감을 받아, 저는 경직된 파이프라인을 버리기로 결정했습니다.
저는 에이전틱 + MCP(모델 컨텍스트 프로토콜) 아키텍처로 전환했습니다. 아이디어는 간단합니다. 복잡한 검색 체인 대신, 에이전트에게 각 데이터 소스를 직접 검색할 수 있는 도구를 제공하는 것입니다.
시스템 아키텍처는 다음과 같습니다.
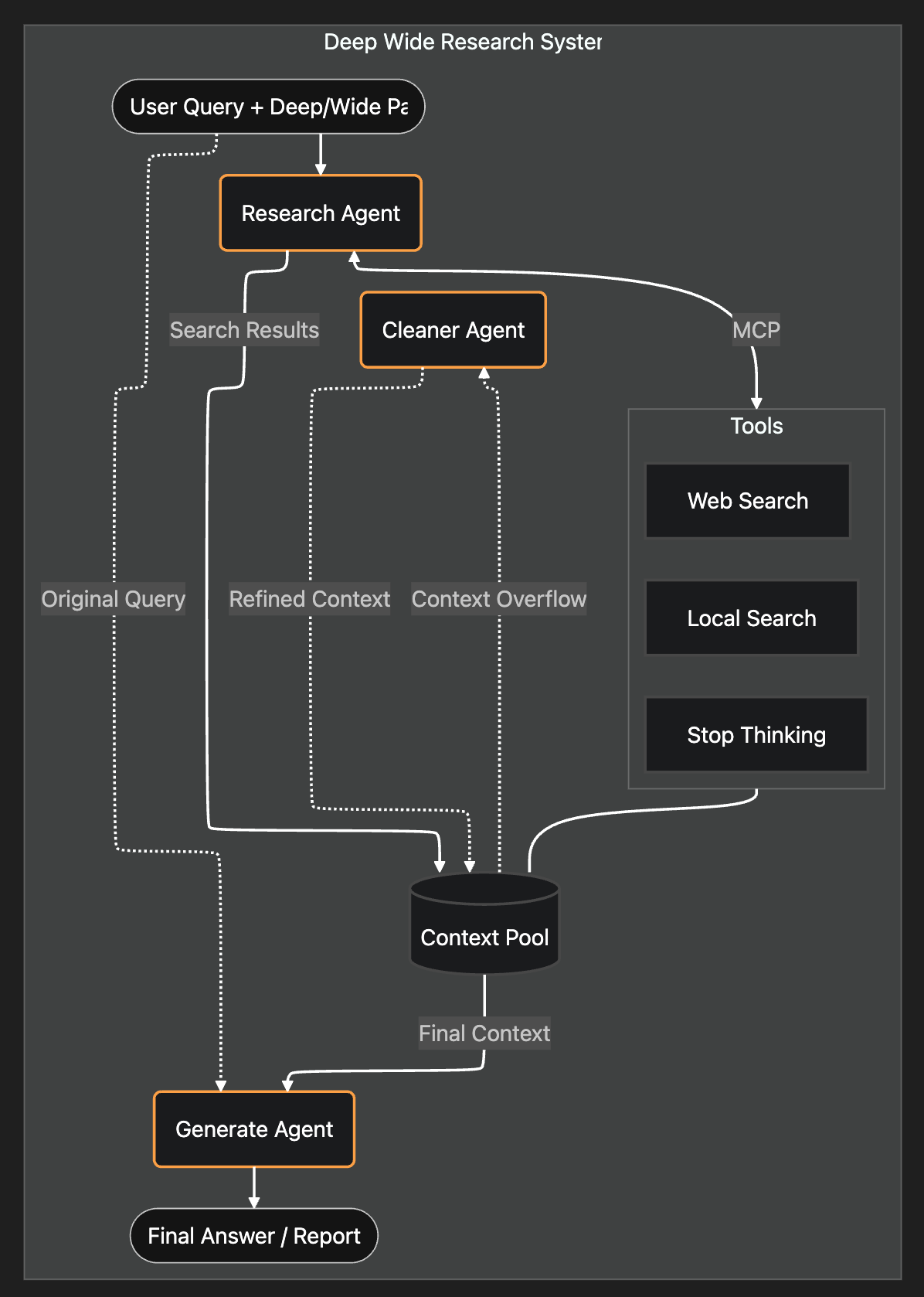
1. 리서치 에이전트는 어떻게 구축하는가?
에이전틱 RAG는 전체 검색 파이프라인을 단일 자율 리서치 에이전트로 대체합니다.
재작성이나 라우팅 규칙을 하드코딩하는 대신, **리서처(Researcher)**와 **생성기(Generator)**라는 두 개의 에이전트를 설정했습니다.
리서처에게는 세 가지 간단한 도구를 주었습니다.

<Stop_thinking><Web_search><Local_search>
하지만 에이전트에게 도구를 주는 것만으로는 충분하지 않습니다. 언제 멈춰야 하는지 알려줘야 합니다.
단순한 while 루프나 고정된 단계 수를 사용하는 대신, 에이전트가 모든 행동 전에 **자기 성찰 단계(Self-Reflection Step)**를 거치도록 강제했습니다.
저희는 단순한 루프나 반복 횟수를 사용하지 않습니다. 대신, 에이전트가 행동하기 전에 **"아티클 준비 상태 확인"**을 통해 스스로를 성찰하도록 강제합니다.
## 아티클 준비 상태 확인:
- 지금 당장 포괄적이고 상세한 답변과 아티클을 작성할 수 있는가? (예/아니오)
- 지금 작성한다면, 어떤 섹션이 취약하거나 모호하거나, 구체적인 예시/데이터가 부족한가?
- 모든 주장을 뒷받침할 만큼 구체적인 사실, 수치, 예시가 충분한가?
이 확인 단계를 통과해야만 에이전트는 <Stop_thinking>을 호출합니다. 저희는 이 로직을 SOTA 모델(Gemini 3 pro / Claude 4.5 Opus / GPT-5)로 테스트했고, 모델들은 완벽하게 로직을 따랐습니다.
모든 리서치 결과는 공유된 **컨텍스트 풀(Context Pool)**에 저장됩니다. 리서처가 "중지" 신호를 보내면, **생성 에이전트(Generate Agent)**가 컨텍스트 풀을 가져와 최종 답변을 작성합니다.
결과는 우리가 지금까지 구축했던 어떤 파이프라인보다 뛰어났습니다. 경직된 구조를 이긴 지능의 승리입니다.
우리는 본질적으로 기존 RAG 구성 요소를 동적인 에이전트 행동에 매핑했습니다.
- 쿼리 라우팅? -> 에이전트가 올바른 도구를 선택합니다.
- 쿼리 재작성? -> 에이전트가 함수 인수를 채웁니다.
- 멀티홉 QA? -> 에이전트가 언제
<Stop_thinking>을 호출할지 결정합니다. - 재순위화 -> 에이전트가 컨텍스트 풀을 기반으로 답변을 생성합니다.
2. 컨텍스트 오버플로우 처리하기
저는 두 번째 문제에 부딪혔습니다. 검색된 컨텍스트가 너무 길어지면 어떻게 해야 할까요?
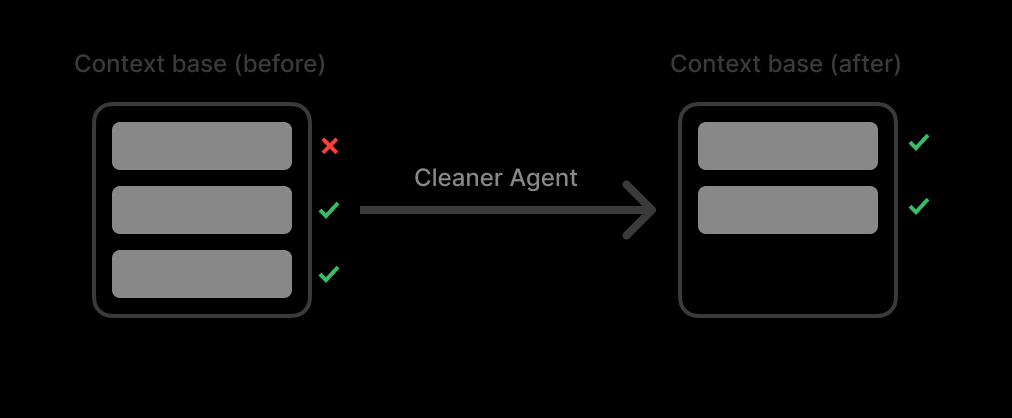
저는 **컨텍스트 풀(Context Pool)**을 만들었습니다. 이 풀은 모든 검색 결과의 목록으로 기능합니다. 컨텍스트 풀이 임계값(최대 토큰의 90%)에 도달하면 컨텍스트를 정리하는 **클리너 에이전트(Cleaner Agent)**를 구축했습니다.
핵심은 요약하지 않는 것입니다. 요약은 세부 정보를 없애버립니다.
대신, 클리너 에이전트는 쓰레기 필터처럼 작동합니다. 관련 없는 소스는 통째로 삭제하고, 관련 있는 소스는 100% 원본 그대로 유지합니다.
마지막으로, **생성 에이전트(Generate Agent)**가 컨텍스트 풀의 정제된 내용과 원본 쿼리를 기반으로 최종 답변을 생성합니다.
3. 비용 및 지연 시간을 위한 "Deep-Wide" 솔루션
저는 곧 세 번째 도전 과제에 직면했습니다. 바로 비용 및 지연 시간의 장벽입니다.
수치에 대해 솔직하게 말씀드리겠습니다.
- 지연 시간: 에이전틱 RAG는 약 10초의 최소 지연 시간이 있습니다. 추론 루프가 병목 현상을 일으키기 때문에 이보다 더 줄일 수 없습니다. 기존 RAG는 3초 미만으로 응답할 수 있습니다.
- 비용: GPT-5를 사용하면 쿼리당 약 $0.05~$1가 예상됩니다. 임베딩을 사용하는 기존 RAG는 약 $0.005~$0.01의 비용이 듭니다.
이 최소치 이상에서 트레이드오프를 제어할 수 있도록, 저는 **"Deep-Wide 리서치"**를 도입했습니다.
- Deep(깊이): 반복적인 추론 단계를 제어합니다. 범위는 최소 약 10초에서 포괄적인 보고서를 위한 최대 깊이인 5분 이상까지입니다.
- Wide(너비): 병렬 쿼리 확장을 제어합니다. 너비가 넓을수록 더 많은 소스를 탐색하게 되므로 토큰 비용이 증가합니다.
DEEP × WIDE ≈ 비용. 이 두 가지 차원을 조정하여 응답 시간(10초 ~ 5분), 품질, 비용을 제어할 수 있지만, 10초라는 최소 지연 시간 이하로 내려갈 수는 없습니다.
저희는 DEEP WIDE RESEARCH를 오픈소스로 공개했습니다. 프로젝트 URL: https://github.com/puppyone/DeepWideResearch (Apache 라이선스)
이 프로젝트가 해결하지 못하는 것
이 프로젝트는 에이전틱 RAG 문제의 절반, 즉 "추론 및 검색" 측면을 다룹니다.
나머지 절반인 사내 비공개 데이터 처리 문제는 아직 해결되지 않았습니다.
- 정리되지 않은 기업 문서 클리닝
- 에이전트가 사용하기에 최적화된 인덱스 구축
- 세분화된 권한 제어
저희는 이 문제를 별도로 작업하고 있습니다. 만약 이러한 문제에 직면했거나 아이디어가 있으시면, 언제든지 연락 주세요: [email protected]