컨텍스트 학습을 위한 하이브리드 인덱싱 궁극 가이드
2026년 2월 7일Ollie @puppyone
핵심 요약
- 하이브리드·필드 인식 검색은 «그냥 컨텍스트를 더 길게»보다 낫다. 단계별 결정론적 슬라이스가 필요하지, 텍스트 벽이 아니다.
- 모델 한계는 현실이다: 벤치마크는 무시/오용되는 컨텍스트 비율이 높음을 보인다; 스택을 설계해 이를 방지·탐지·수정하라.
- 운영/지원에서는 Know-How JSON/그래프와 하이브리드 인덱싱, 그리고 플래너→실행기→검증자 에이전트 루프를 결합해 단계 준수와 감사 가능성을 확보하라.
모델이 SOP에서 컨텍스트를 무시·오용하는 이유
새 벤치마크(CL-bench: 500 컨텍스트, 1,899 태스크, 31,607 검증 루브릭)는 주어진 컨텍스트에서 학습할 때 오늘날 모델이 얼마나 취약한지 보여 준다: 10개 프론티어 모델이 평균 약 17.2%의 태스크만 해결; 최고 모델도 추론 모드에서 약 23.7%. 지배적 오류는 제공된 컨텍스트를 올바르게 사용하지 않는 것—핵심 세부사항 누락 또는 잘못된 규칙 적용. 참고 CL-bench paper (arXiv), Tencent Hunyuan research blog. 긴 컨텍스트만으로는 해결되지 않는다; LongBench v2 등은 더 나은 윈도우 처리도 다문서 입력에 대한 추론·집계에 공백을 남김을 보인다(LongBench v2 ACL). 다단계 SOP에서는 단계 건너뛰기, 지시 드리프트, 불안전한 동작으로 나타난다.
SOP 실행에서 순진 RAG의 흔한 실패 모드
검색 단위가 동작 단위와 맞지 않아 RAG 스택이 운영 워크플로에서 흔들린다: 과도하게 넓은 청크 → 검색 드리프트; 가중치 없는 필드가 중요 토큰(단계 ID, 전제조건, 경고)을 묻는다. 단일 프로ンプ트는 즉흥을 부추긴다. 대안: 결정론적 검색과 검증 가능한 실행을 설계한다.
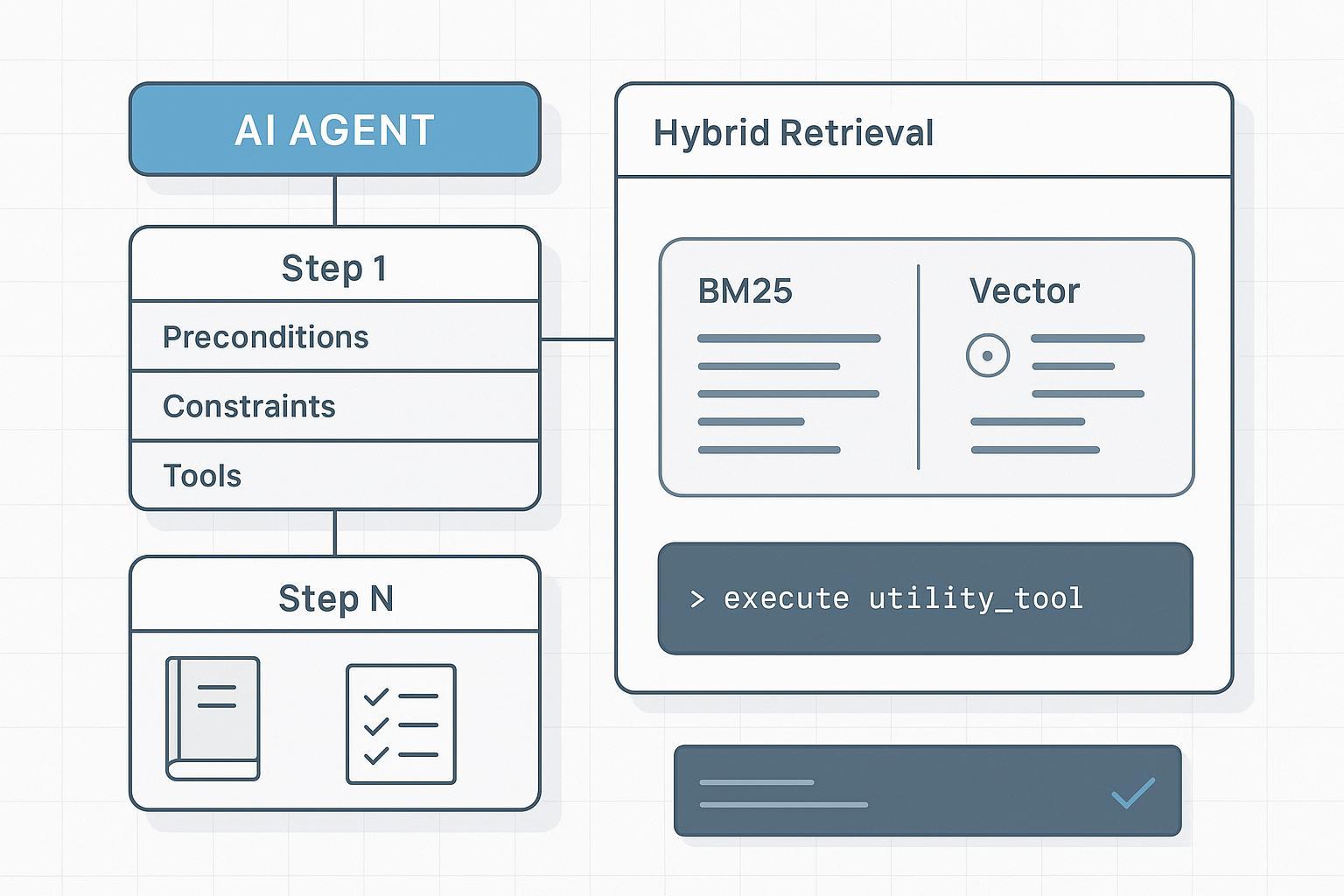
기초: SOP를 Know-How JSON/그래프로 모델링
에이전트는 구조화·필드화된 지식이 필요하다. 실용 스키마는 단계, 의존성, 제약, 검증 방법을 인코딩한다. 영문 글의 JSON 예(sop.router.reset.v3, step_number, preconditions, constraints, tools_allowed, checkpoints, verification_method, dependencies)는 그대로 유지. 이렇게 하면 검색기가 제목, step_number, preconditions, constraints를 서술보다 더 높이 둘 수 있다. Context Base: puppyone About.
길고 밀집한 매뉴얼에서 컨텍스트 학습을 위한 하이브리드 인덱싱
핵심은 «더 긴 컨텍스트»가 아니라 «더 나은 검색 단위와 랭킹 신호»다. 실제로는 필드 인식 하이브리드 인덱싱과 소규모 리랭크.
- 스파스 어휘 신호(BM25/BM25F)와 밀집 벡터를 결합. 어휘: 정확한 ID, 경고, 제약; 밀집: 의미적으로 표현된 단계의 리콜 향상. 참고 Elastic — What is hybrid search, Elastic retrievers and RRF, Weaviate — Hybrid search explained.
- 필드 인식 부스트: 제목, step_number, preconditions, constraints, tools_allowed를 서술보다 우선.
- 단계당 최소·결정론적 슬라이스만 검색; 매번 SOP 전체를 넣지 않는다.
- 선택: 크로스 인코더 또는 구조 인식 리랭커로 top-k 리랭크.
SOP용 에이전트 RAG: 플래너→검색기→실행기→검증자
플래너가 작업을 단계별 의도로 분해하고 step_number, 필요 도구 등 필드로 검색 쿼리를 만든다. 검색기는 ID가 붙은 최소 필드 슬라이스(전제조건, 제약, 파라미터, 체크포인트)를 반환한다. 실행기는 나열된 도구만 스키마 검증된 파라미터로 호출하고 사용한 슬라이스 ID를 인용한다. 검증자는 진행 전에 체크포인트와 제약을 확인; 이탈 시 재계획 또는 인간 검토. 참고 Anthropic — Multi-agent research system.
핸즈온 예: 한 단계 엔드투엔드
고지: Puppyone은 자사 제품. 여기서는 중립적으로 가능한 context base 중 하나로 언급. 자세한 내용은 puppyone. 목표: 하이브리드 검색과 에이전트 루프로 «Router Safe Reset» 7단계 실행. 쿼리 계획, 의사코드(Python 스타일), 상태 로그는 영문 글과 동일. 동일 루프는 Elastic/OpenSearch/Vespa/Weaviate 또는 RDBMS+pgvector+BM25로 구현 가능.
평가 플레이북: 신뢰성 입증 후 스케일
검색 품질: Recall@k, 단계별 MRR/nDCG, Context Precision, Context Sufficiency. 실행: Step Adherence %, Action Success Rate, Instruction Drift Rate, 1,000회 실행당 사고, Time-to-Resolution. SOP 단계마다 ground truth 슬라이스 ID와 기대 도구/결과 패턴 저장; 실행기가 사용 슬라이스를 인용하고 진행 전 체크포인트가 통과하는지 assert. 개요: RAG evaluation survey (2024).
대안과 동등 선택
| 스택 | 하이브리드 융합 | 필드 인식 부스트 | 온프레미스/VPC | 비고 |
|---|---|---|---|---|
| Elasticsearch | RRF, 가중 블렌딩 | BM25F, 다중 필드 | 성숙한 self-host | 리트리버 API, 크로스 인코더 리랭커 |
| OpenSearch | 가중+리랭크 패턴 | 분석기 통한 필드 부스트 | first-class self-host | 벡터 성능 작업 |
| Vespa | Lexical+ANN+리랭크 | 필드별 특징 | Self-host, 스케일아웃 | 강한 랭킹/ML 파이프라인 |
| Weaviate | RRF/가중 하이브리드 | 속성 가중치/필터 | Managed+self-host | 하이브리드 문서 명확 |
«Agent Context Base» 접근을 선호하면 예: puppyone. 기준: 필드 인식 스코어링, 결정론적 슬라이싱 보장, 감사 로그, 평가 하네스 지원.
실무에서 «좋음»의 모습
파일럿에서, 전체 문서 프로ンプ트에서 단계·필드별 슬라이스로 바꾸면 지시 드리프트가 줄고 단계 준수가 올라간다. 컨텍스트 학습을 위한 하이브리드 인덱싱의 요점은 정확한 제약 면을 에이전트 손에 넣고, 진행 전 검증을 요구하는 것이다.
다음 단계
SOP 자동화를 위한 프로덕션급 접근—구조화 Know-How, 하이브리드 인덱싱, 플래너→실행기→검증자 루프—을 평가 중이라면, 코퍼스와 제약을 함께 살펴보자. 귀사 환경에 맞는 하이브리드 인덱싱+에이전트 RAG 기술 데모를 예약하세요.