Ingénierie du contexte : quand le RAG ne suffit pas
10 février 2026Ollie @puppyone
Points clés
- Le RAG basique suffit quand votre corpus est petit, les questions sont locales et la gouvernance est légère ; au-delà, une couche de contexte dédiée s'impose.
- Une couche de contexte transforme le savoir en Know‑How structuré (JSON/graphe), la couple avec une indexation hybride (dense + sparse + graph) et la gouverne avec traçabilité, ACLs et versioning.
- La récupération enrichie graphe/arbre comble les lacunes où le RAG purement vectoriel échoue sur les requêtes cross-document et globales ; voir GraphRAG (2024) de Microsoft Research.
- L'orchestration de sous-agents et des budgets de résumé stricts maintiennent le contexte à fort signal et testable, aligné avec les notes d'Anthropic sur l'ingénierie efficace du contexte.
- La gouvernance n'est pas optionnelle ; le cadre AI RMF de NIST place la traçabilité et les contrôles de cycle de vie au centre des systèmes de confiance.
La rubrique décisionnelle : RAG suffisant vs. couche de contexte
Commencez simple et résistez à l'infrastructure prématurée. Vous n'avez probablement pas besoin d'une couche de contexte si :
- Votre corpus est petit, en grande partie statique et vit dans un ou deux systèmes.
- Les questions sont locales et en un seul saut (ex. « Quelle est la garantie du produit X ? »).
- Les SLO de latence sont flexibles et vous tolérez des ratés occasionnels.
- La gouvernance est légère ; pas de traces audivables ni d'ACLs rigoureuses.
Vous avez besoin d'une couche de contexte dédiée quand :
- Vos données vivent dans Docs, Slack, Notion, bases de données et SaaS externes et changent fréquemment. Même les entreprises de recherche investissent dans des connecteurs ; voir l'acquisition de Carbon par Perplexity en 2024 : Perplexity welcoming Carbon.
- Vos agents doivent répondre à des questions globales ou cross-document et planifier des workflows multi-étapes. La récupération pure vectorielle échoue ici ; l'équipe Microsoft décrit des stratégies graphes dans arXiv 2024 : A Graph RAG approach to query‑focused summarization.
- Vous avez besoin de traçabilité, contrôle d'accès, versioning et rollback. Cela s'aligne sur la fonction GOVERN du cadre NIST AI Risk Management.
- Le déterminisme et la testabilité comptent : vous voulez un assemblage de contexte reproductible, des traces de récupération expliquables et du CI pour les mises à jour de contexte. Les recommandations d'Anthropic sur les sous-agents et l'hygiène du contexte appuient cette direction ; voir Effective context engineering for AI agents.
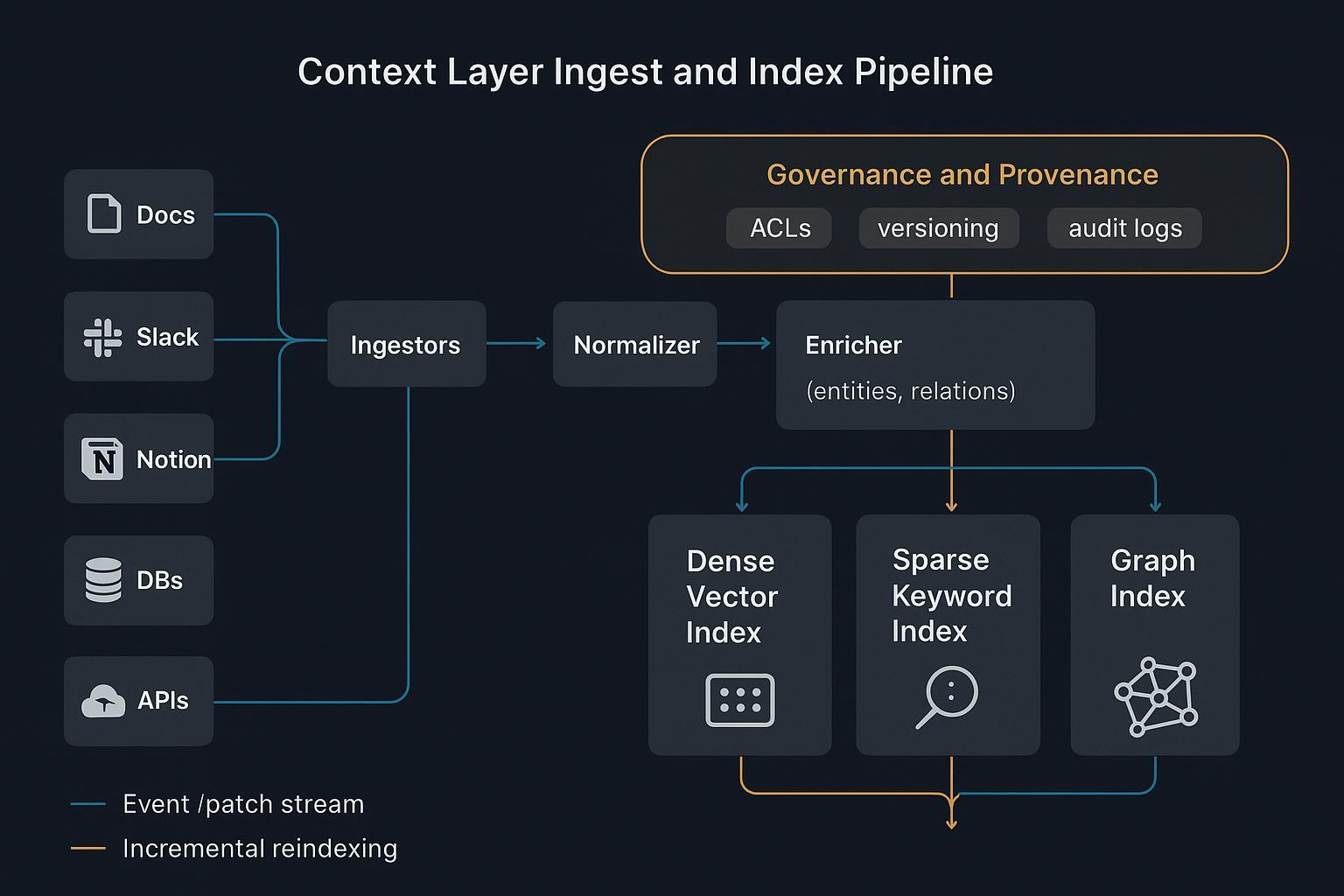
Architecture d'ingénierie du contexte au-delà du RAG
Know‑How structuré et schémas
Le HTML non structuré est du bruit pour les machines. Une couche de contexte transforme procédures, entités, contraintes et règles métier en Know‑How structuré : documents JSON et graphes avec schémas clairs :
{
"entity": "PurchaseOrder",
"id": "PO-2026-1783",
"vendor": {"name": "Acme", "id": "V-882"},
"line_items": [
{"sku": "X12", "qty": 5, "unit_price": 49.00}
],
"approval_policy": {
"threshold": 10000,
"requires_dual_signoff": true,
"exceptions": ["emergency"]
},
"provenance": {"source": "ERP", "version": "v14.2", "ingested_at": "2026-02-06"}
}
Ce contexte schématisé donne aux agents une logique lisible par machine et une traçabilité pour l'audit, au lieu de s'appuyer sur des fragments de texte fragiles.
Indexation hybride et routage
- La recherche sémantique dense trouve rapidement la similarité topique.
- Les index lexicaux sparse préservent les termes exacts, IDs et langage de politiques.
- Les structures graphe/arbre encodent relations et hiérarchie pour le raisonnement multi-sauts.
Ensemble, ils permettent une récupération déterministe : router par cluster ou voisinage de graphe, puis assembler un contexte minimal et pertinent. Patterns opérationnels dans Weaviate best practices for hybrid search.
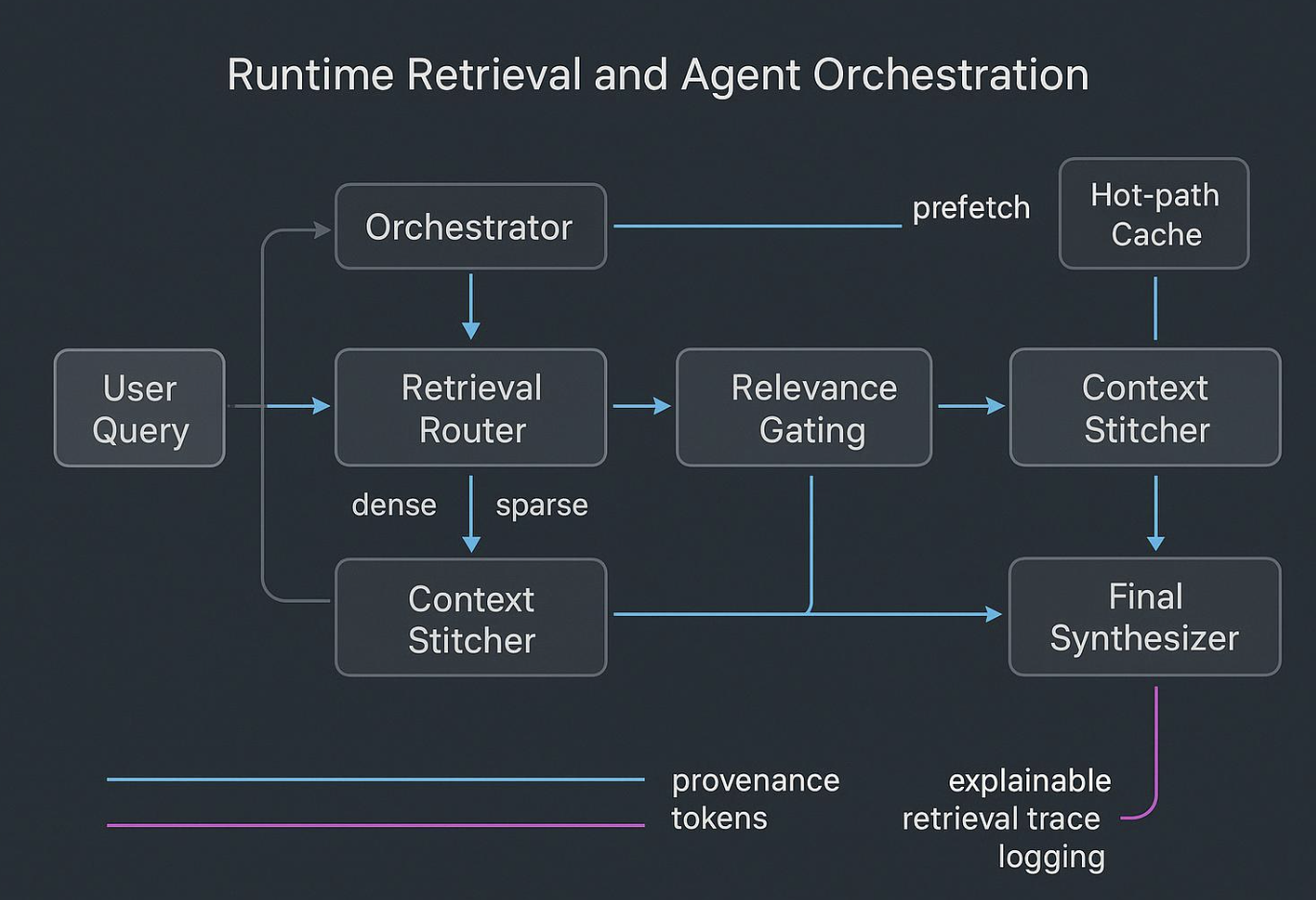
Assemblage et orchestration runtime
Les agents échouent quand ils essaient de « réfléchir » sur des dumps bruts et bruités. Le runtime doit ressembler à :
- Un planner émet des hypothèses sur les preuves et outils nécessaires.
- Un router distribue les requêtes sur les index dense, sparse et graph.
- Un gate filtre par traçabilité et politique ; un stitcher compose un bundle compact et bien délimité.
- Les sous-agents exécutent des tâches étroites et renvoient des résumés stricts à un synthétiseur.
# Pseudocode pour récupération hybride + assemblage
plan = planner.make_plan(user_query)
results = []
for hop in plan.hops:
dense = dense_index.search(hop.query, k=10)
sparse = sparse_index.search(hop.query, k=10, filter=plan.filters)
graph_ctx = graph.walk(hop.entities, depth=2)
gated = gate.by_provenance(dense + sparse + graph_ctx)
stitched = stitch.compact(gated, budget_tokens=1200)
results.append(stitched)
final = synthesize(results, tools=plan.tools)
return final
Checklist du pipeline de contexte
- Ingérer les sources → normaliser → mapper au schéma.
- Enrichir avec entités et relations → stocker en Know‑How structuré.
- Construire des index hybrides (dense, sparse, graph) avec métadonnées de traçabilité.
- Gater avec ACLs, versioning et journaux d'audit.
- Évaluer fidélité de récupération et résultats au niveau des tâches avant le déploiement.
- Déployer avec caches hot-path et prefetch.
- Surveiller latence, précision/rappel, drift et traces d'audit.
Micro-benchmark léger : latence vs. qualité des réponses
Ce design aide à comparer trois patterns de récupération. Garder petit et reproductible.
Hypothèses : 50K documents (politiques, tickets, specs) ; 75 requêtes d'évaluation avec ground truth pour 40 ; même LLM ; parité matérielle ; reranker si applicable. Rapporter latence médiane p50/p90 et qualité via EM/F1 ou LLM-juge documenté.
| Pattern | Stack de récupération | Caractéristiques attendues |
|---|---|---|
| RAG naïf | Dense uniquement | Rapide, cohérence globale plus faible ; difficultés sur questions cross-doc |
| RAG affiné | Dense + sparse + reranker | Latence modérée, meilleure précision sur IDs et termes de politique |
| Couche de contexte | Hybride + graph + assemblage + résumés | Latence p50 un peu plus élevée mais p90 plus serrée ; réponses globales plus stables |
Interprétation : le RAG affiné corrige beaucoup de lacunes faciles ; la couche de contexte brille sur les tâches cross-document et multi-étapes, avec latence de queue plus prévisible grâce au routage et aux caches.
Modes de défaillance et mitigation
- Fragmentation entre documents : construire des graphes entité/relation et traversées locales/globales ; ajouter ancres hiérarchiques aux narratifs longs.
- Obsolescence et drift : ingestion event-sourced, réindexation incrémentale, TTLs ; rejouer changelogs lors d'upgrades de schéma.
- Pics de latence : caches hot-path par niveaux, routage par cluster, prefetch pour sous-requêtes fréquentes ; dimensionner les shards et activer la quantification.
- Hallucinations par contexte bruité : imposer schémas et filtres de traçabilité ; restreindre les périmètres de sous-agents ; préférer résumés compacts aux dumps bruts.
- Lacunes de gouvernance : logger traces de récupération et appels d'outils ; exiger des lignes de preuve explicables ; gater les déploiements avec seuils d'évaluation et plans de rollback.
Micro-exemple pratique : Know‑How structuré et indexation hybride en action
Supposons que vous construisez un agent d'achat qui doit appliquer des politiques d'approbation tout en assemblant des devis fournisseurs. Vous ingérez des exports ERP, des PDF de contrats, des approbations Slack et des résumés email. Le pipeline mappe tout à un schéma commun : PurchaseOrder, Vendor, Policy, Exception. Vous enrichissez avec du entity linking pour que chaque PurchaseOrder connaisse son Vendor et ses nœuds Policy applicables. Puis vous construisez un index dense pour le recall sémantique, un index sparse pour les IDs et termes juridiques, et un index graphe pour les chemins Policy → Exception → Approver.
Dans ce setup, une boucle d'orchestration route une requête « Pouvons-nous approuver PO‑2026‑1783 aujourd'hui ? » via : lookup sparse de l'ID PO, parcours de graphe de cette PO vers sa Policy et exceptions, et récupération dense des notes récentes d'approbateurs. Le stitcher compacte le tout en un bundle de 1,2K tokens et l'agent produit une réponse courte et citée avec décision d'approbation et liens vers la traçabilité.
Une plateforme comme puppyone peut aider car elle stocke le savoir en Know‑How structuré (JSON/graphe) et supporte l'indexation hybride sur texte et structure, permettant des patterns de récupération déterministes et des traces audivables sans dépendre du scraping de texte fragile.
Gouvernance et CI pour le contexte
Traitez le contexte comme du code. Chaque changement doit avoir traçabilité, revue et tests. Maintenir schémas versionnés, politiques d'accès et suites d'évaluation. Avant les déploiements : exécuter contrôles de fidélité de récupération et tests au niveau des tâches ; capturer traces explicables et garder le rollback prêt. Si vos agents touchent des données régulées ou sensibles, alignez vos processus sur le cadre NIST AI Risk Management. Pour l'interop : Model Context Protocol.
Prochaines étapes
Commencez avec un RAG affiné si votre problème est local et à faible risque. Si vous voyez des questions cross-doc, des besoins de gouvernance ou des corpus volatils, planifiez un pilote de couche de contexte centré sur un workflow. Construisez d'abord le Know‑How structuré ; l'indexation hybride et l'orchestration deviennent bien plus simples une fois les schémas stables. Gardez l'évaluation serrée et humaine : tester des tâches réelles, logger les traces, lier les améliorations aux SLO métier.
FAQs
Q1 : Ai-je besoin d'un graphe tout de suite ?
R : Non. Démarrez avec dense + sparse ; ajoutez un graphe quand apparaissent des lacunes de raisonnement cross-document ou de résumé global.
Q2 : Quelle taille pour mes chunks ?
R : Découpez par unités sémantiques liées à votre schéma (entités, procédures), pas par comptage fixe de tokens. Laissez le reste aux rerankers et résumés.
Q3 : Puis-je repousser la gouvernance ?
R : Oui, mais vous le paierez. Ajoutez traçabilité légère et contrôles d'accès dès le premier jour pour que l'évaluation et les rollbacks soient possibles.