RAG: Lösung der Genauigkeitskrise von KI-Agenten in Hochrisikoszenarien
22. September 2025Ruixi @puppyone
Obwohl KI-Agenten ein immenses Potenzial zur Automatisierung von Unternehmensabläufen bergen, stellt die inhärente Volatilität von Großen Sprachmodellen (LLMs) in stark regulierten Branchen wie Finanzen, Recht und Gesundheitswesen ein erhebliches Risiko dar. Eine einzige falsche Ausgabe kann schwerwiegende rechtliche oder finanzielle Konsequenzen nach sich ziehen.
Um KI-gesteuerte Risiken systematisch zu managen und Geschäftswert zu erschließen, benötigen Führungskräfte zunächst ein klares Framework zur Bewertung der Genauigkeitsanforderungen verschiedener Anwendungsfälle. Das nachstehende Framework "Genauigkeitsstufen für KI-Anwendungsfälle" kategorisiert KI-Anwendungen nach ihrer erforderlichen Präzision und Risikotoleranz.

| Genauigkeitsstufe | Erforderliche Genauigkeit | Typische Anwendungsfälle | Mögliche Risiken |
|---|---|---|---|
| Stufe 1: Null-Toleranz | 99,9%+ | Medizinische Diagnostik, rechtliche Compliance, Finanzkreditgenehmigung, AML | Katastrophale rechtliche, finanzielle oder Sicherheitsrisiken |
| Stufe 2: Hohe Einsätze | 90-99% | Komplexer Kundensupport, internes Wissensmanagement, Risikobewertung bei der Versicherungsübernahme | Erheblicher Geschäftsverlust, Kundenabwanderung, Compliance-Probleme |
| Stufe 3: Kontextuelle Zuverlässigkeit | 75-90% | Standard-Kundenservice-Chatbots, Markttrendanalysen, F&A-Systeme | Schlechte Benutzererfahrung, betriebliche Ineffizienz |
| Stufe 4: Kreativ & Explorativ | 0-75% | Inhaltserstellung, Brainstorming, persönliche Assistenten | Geringwertige oder unbrauchbare Ausgabe |
Die Geschäftskosten der KI-Ungenauigkeit: Quantifizierung des Risikos
KI-Ungenauigkeit ist nicht mehr nur ein technisches Problem; sie ist ein großes systemisches Risiko, das eine Überwachung durch die Geschäftsführung erfordert. Um ihre tiefgreifenden geschäftlichen Auswirkungen zu verstehen, müssen wir die Kosten quantifizieren.
Finanzielle Auswirkungen
- 67,4 Milliarden US-Dollar - Globale Verluste, die 2024 auf KI-"Halluzinationen" zurückzuführen sind (Studie von AllAboutAI 2025)
- Fast 50 % der Unternehmens-KI-Benutzer gaben zu, wichtige Geschäftsentscheidungen auf der Grundlage potenziell ungenauer KI-generierter Inhalte getroffen zu haben
Betriebskosten
- 22 % durchschnittlicher Rückgang der Teameffizienz aufgrund der manuellen Überprüfung von KI-Ausgaben (Boston Consulting Group 2025)
- 14.200 US-Dollar pro Mitarbeiter jährlich - Kosten für die Minderung von Halluzinationen (Forrester Research)
Strategische Technologieentscheidung: RAG vs. Feinabstimmung
Um Anwendungsfälle der Stufen 1 und 2 zu ermöglichen, muss ein KI-Agent über eine unbestreitbar zuverlässige Wissensquelle verfügen. Retrieval-Augmented Generation (RAG) und Feinabstimmung sind die beiden primären Methoden, um dies zu erreichen.
| Entscheidungsfaktor | Retrieval-Augmented Generation (RAG) | Feinabstimmung |
|---|---|---|
| Anpassungsmethode | Injiziert Prompts mit abgerufenen externen Dokumenten | Aktualisiert die Modellgewichte, um Wissen zu internalisieren |
| Datenaktualität | Echtzeit; passt sich sofort an neue Informationen an | Statisch; Wissen zum Trainingszeitpunkt eingefroren |
| Bereitstellungsgeschwindigkeit | Extrem schnell (Stunden bis Tage) | Langsam (Wochen bis Monate) |
| Erklärbarkeit/Auditierbarkeit | Hoch; kann Quellen zitieren und eine Beweiskette bereitstellen | Gering; operiert als "Black Box" |
| Datensicherheit | Hoch; sensible Daten bleiben isoliert | Geringer; potenzielle Datenleck-Vektoren |
| Geschäftsauswirkungen | Schnelle Time-to-Value, ideal für schnelle Pilotprojekte | Hohe Anfangsinvestition, lange Bereitstellungszyklen |
Der Kernmechanismus von RAG
Ein RAG-System kombiniert leistungsstark Informationsabruf mit Generierung. Sein Arbeitsablauf folgt typischerweise diesen Schritten:
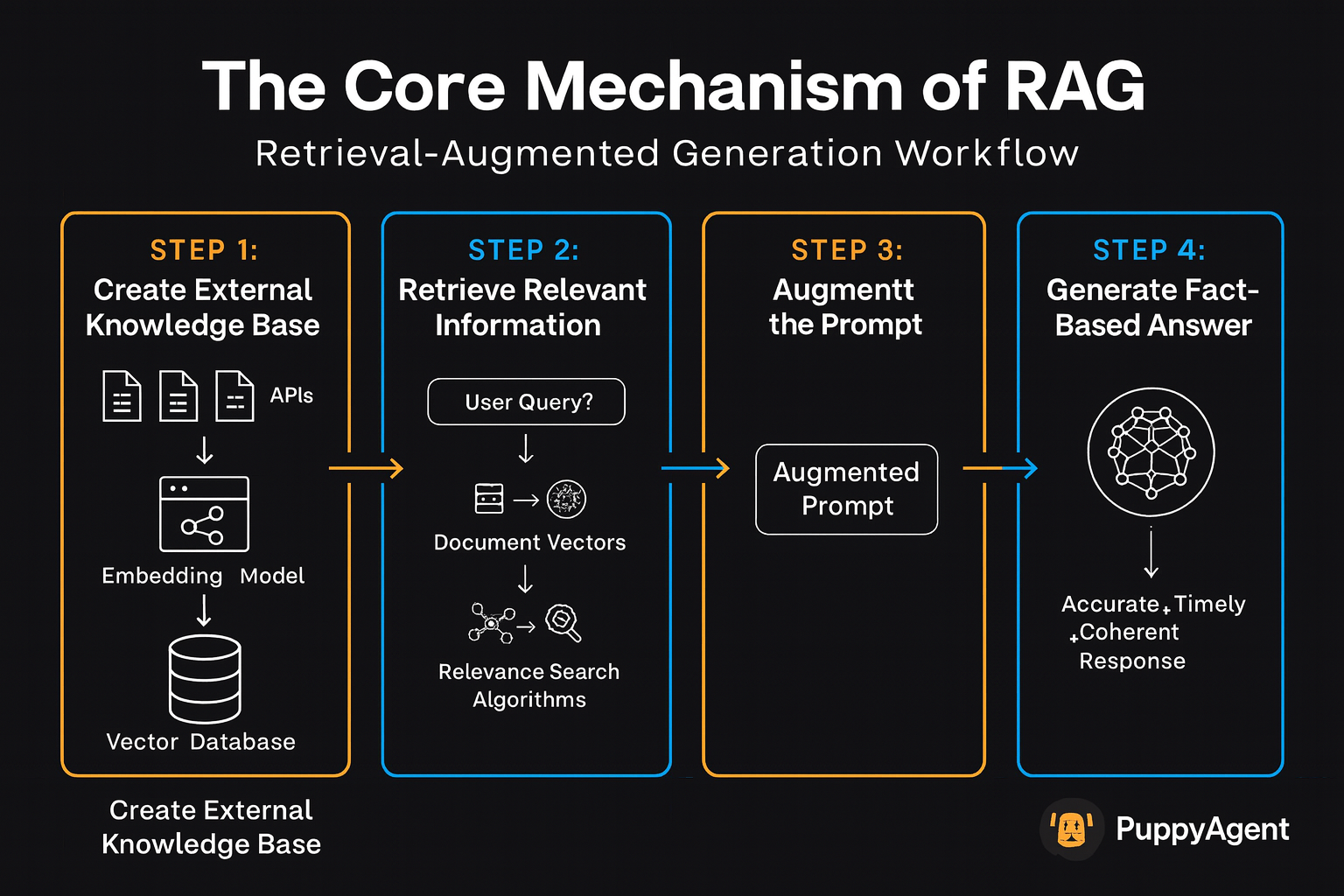
RAG-Arbeitsablaufschritte:
- Erstellen einer externen Wissensdatenbank - Konvertieren Sie proprietäre Daten in durchsuchbare Vektoren
- Relevante Informationen abrufen - Gleichen Sie Benutzeranfragen mit der Wissensdatenbank ab
- Den Prompt erweitern - Integrieren Sie abgerufene Informationen in die ursprüngliche Anfrage
- Eine faktenbasierte Antwort generieren - LLM produziert genaue, zeitnahe Antworten
Aufbau einer unternehmenstauglichen RAG-Architektur
Im Unternehmenskontext wird der Erfolg durch die rigorose Entwicklung von Daten- und Abrufpipelines bestimmt.
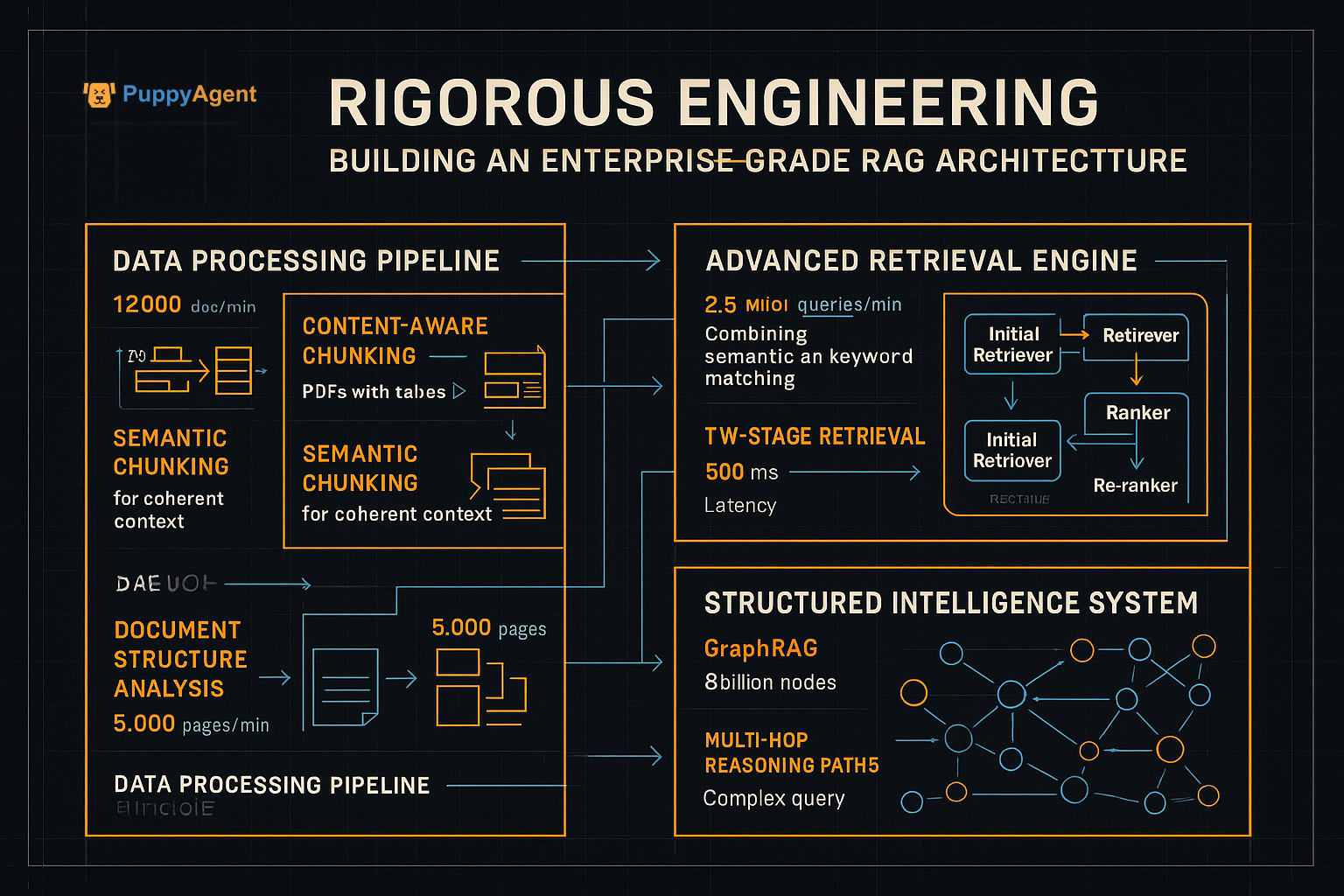
Wichtige technische Überlegungen:
Datenzentrierte Grundlage
- 80 % des RAG-Erfolgs hängen von der Datenqualität ab
- Inhaltsbasiertes Chunking für komplexe Dokumente
- Semantisches Chunking zur kohärenten Kontexterhaltung
Fortgeschrittene Abrufstrategien
- Hybride Suche, die Stichwort- und Vektoransätze kombiniert
- Zweistufiger Abruf mit Re-Ranker-Optimierung
- GraphRAG für strukturierte Daten und mehrstufiges Schlussfolgern
Quantifizierbarer Geschäftswert: Praxisnahe Fallstudien
Betriebliche Effizienz & Produktivität
- Fortune-500-Hersteller: Reduzierte die Antwortzeiten im Kundenservice von über 5 Minuten auf 10-30 Sekunden
- 90 % 5-Sterne-Bewertung von Servicemitarbeitern
- Tier-1-Automobilhersteller: 25 % Steigerung der Erstlösungsrate für Techniker
Erfolg in regulierten Branchen
- Precina Health: Diabetespatienten senkten ihre A1c-Werte um 1 % pro Monat (12x schneller als die Standardversorgung)
- HIPAA-konforme medizinische KI-Bereitstellung
Wissensmanagement
- Bell Telekommunikation: Sicherstellung des Zugriffs auf die neuesten Richtlinien für Mitarbeiter
- LinkedIn: 28,6 % Reduzierung der durchschnittlichen Problemlösungszeit
puppyone: Unternehmenswissensplattform für KI-Agenten
puppyone wurde speziell entwickelt, um unternehmenstaugliche RAG-Pipelines zu erstellen und komplexe technische Herausforderungen zu abstrahieren.
Kernwertversprechen:
Schnelles Prototyping
- Intuitive Benutzeroberfläche für die Datenvorbereitung
- Löst die Komplexität des "Selbermachens"
Flexible Bereitstellung
- Unterstützt Chatbots, APIs und Website-Widgets
- Nahtlose Integration in die IT-Architektur
Fortgeschrittene Technologie
- Integrierte, hochmoderne RAG-Techniken
- Bewältigt Herausforderungen fortgeschrittener Anwendungsfälle
Sicherheit & Compliance
- Sicherheit auf Unternehmensebene
- Transparente Beweiskette für Audits
Fazit: Überbrückung der Lücke zwischen Wahrscheinlichkeit und Gewissheit
Es besteht eine große Kluft zwischen der probabilistischen Natur von Allzweck-LLMs und den deterministischen Anforderungen von Hochrisikobranchen. RAG überbrückt diese Kluft, indem es LLMs überprüfbare, externe Wahrheitsquellen zur Verfügung stellt.
Der zukünftige Wert von KI-Agenten wird durch Zuverlässigkeit, Überprüfbarkeit und Sicherheit bestimmt - nicht nur durch die Modellleistung. puppyone bietet Unternehmen eine vertrauenswürdige Plattform zum Aufbau sicherer, intelligenter KI-Systeme, die echten Geschäftswert liefern und gleichzeitig kritische Risiken managen.