Context Engineering: Wenn RAG nicht reicht
10. Februar 2026Ollie @puppyone
Wichtigste Erkenntnisse
- Einfaches RAG reicht, wenn Ihr Korpus klein ist, Fragen lokal sind und Governance leicht; alles darüber hinaus erfordert eine dedizierte Context-Schicht.
- Eine Context-Schicht formt Wissen in strukturiertes Know‑How (JSON/Graph) um, kombiniert es mit Hybrid-Indexierung (dense + sparse + graph) und verwaltet es mit Provenance, ACLs und Versionierung.
- Graph- und Tree-gestütztes Retrieval schließt Lücken, wo vektor-only RAG bei Cross-Document- und globalen Abfragen strikt; vgl. Microsoft Research zu GraphRAG (2024).
- Sub-Agent-Orchestrierung und strenge Summarization-Budgets halten den Kontext signalstark und testbar, im Einklang mit Anthropics Engineering Notes zu effektivem Kontext.
- Governance ist nicht optional; NISTs AI RMF stellt Provenance und Lifecycle-Kontrollen ins Zentrum vertrauenswürdiger Systeme.
Die konträre Entscheidungsmatrix: Wann RAG reicht vs. wann Sie eine Context-Schicht brauchen
Start einfach und widerstehen Sie vorzeitiger Infrastruktur. Sie brauchen wahrscheinlich keine Context-Schicht, wenn:
- Ihr Korpus klein ist, meist statisch und in ein bis zwei Systemen lebt.
- Fragen lokal und einstufig sind (z.B. „Wie lautet die Garantie für Produkt X?“).
- Latenz-SLOs flexibel sind und gelegentliche Treffer fehlen dürfen.
- Governance leicht ist; Sie brauchen keine auditierbaren Traces oder strenge ACLs.
Sie brauchen eine dedizierte Context-Schicht, wenn eines oder mehrere zutreffen:
- Ihre Daten leben in Docs, Slack, Notion, Datenbanken und externen SaaS, und ändern sich häufig. Sogar Suchunternehmen investieren in Connectors; siehe Perplexitys Übernahme von Carbon 2024: Perplexity welcoming Carbon to connect to your work files.
- Ihre Agents müssen globale oder Cross-Document-Fragen beantworten und mehrstufige Workflows planen. Vektor-only Retrieval versagt hier; das Microsoft-Team skizziert Graph-gestützte Strategien im arXiv 2024: A Graph RAG approach to query‑focused summarization.
- Sie brauchen Provenance, Zugriffskontrolle, Versionierung und Rollback. Entspricht der GOVERN-Funktion im NIST AI Risk Management Framework.
- Determinisierung und Testbarkeit zählen: Sie wollen wiederholbare Context-Assembly, erklärbare Retrieval-Traces und CI für Context-Updates. Anthropics Leitlinie zu Sub-Agents und strenger Context-Hygiene unterstützt dies; siehe Effective context engineering for AI agents.
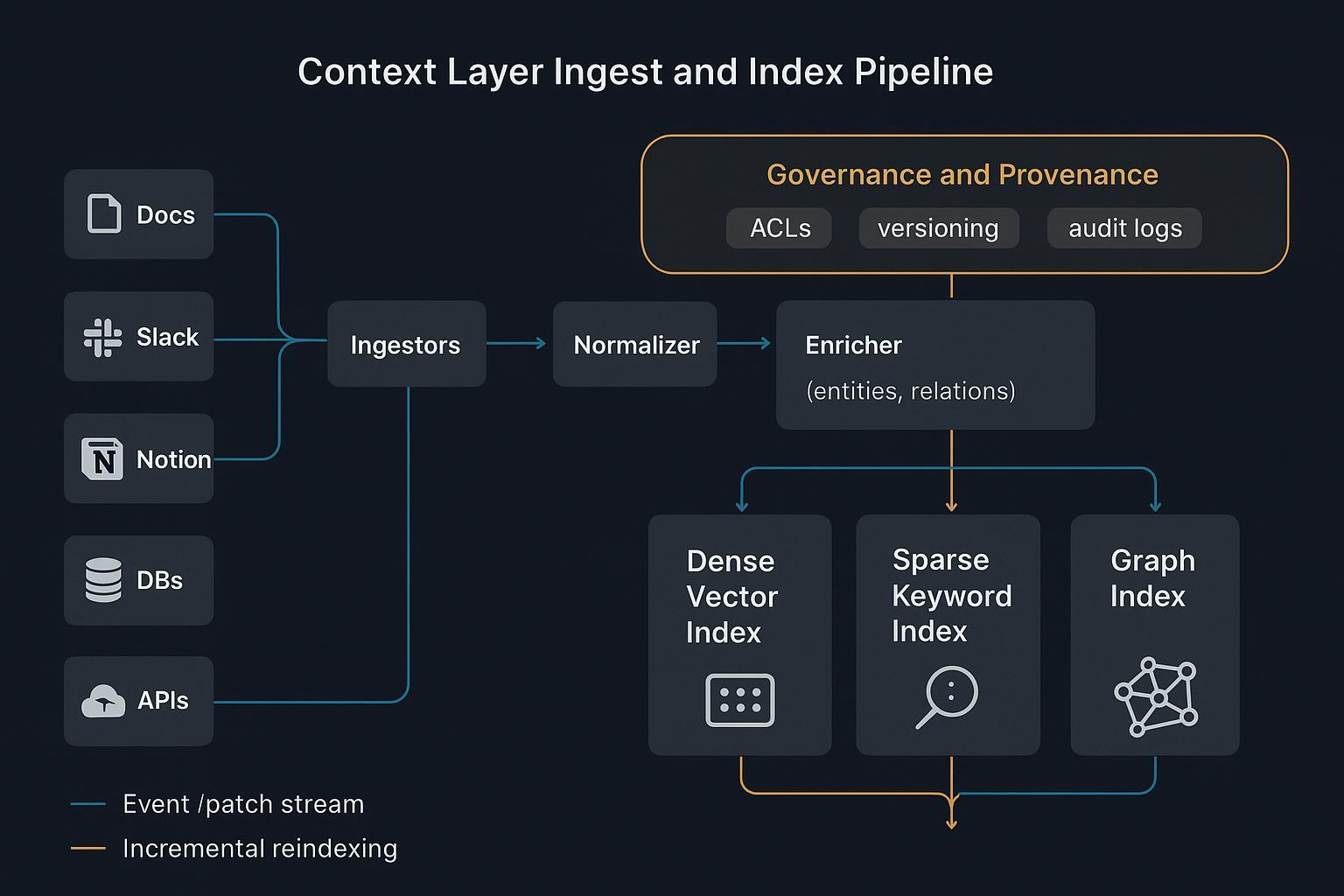
Context Engineering Architektur jenseits von RAG
Strukturiertes Know‑How und Schemas
Unstrukturiertes HTML ist Rauschen für Maschinen. Eine Context-Schicht wandelt Prozeduren, Entitäten, Constraints und Geschäftsregeln in strukturiertes Know‑How: JSON-Dokumente und Graphen mit klaren Schemas:
{
"entity": "PurchaseOrder",
"id": "PO-2026-1783",
"vendor": {"name": "Acme", "id": "V-882"},
"line_items": [
{"sku": "X12", "qty": 5, "unit_price": 49.00}
],
"approval_policy": {
"threshold": 10000,
"requires_dual_signoff": true,
"exceptions": ["emergency"]
},
"provenance": {"source": "ERP", "version": "v14.2", "ingested_at": "2026-02-06"}
}
Dieser schematisierte Kontext gibt Agents maschinenlesbare Logik und Provenance für Auditability, anstatt sich auf fragile Textspannen zu verlassen.
Hybrid Indexierung und Routing
- Dense semantische Suche findet topische Ähnlichkeit schnell.
- Sparse lexikalische Indizes bewahren exakte Begriffe, IDs und Policy-Sprache.
- Graph-/Tree-Strukturen kodieren Beziehungen und Hierarchie für Multi-Hop-Reasoning.
Gemeinsam ermöglichen sie deterministisches Retrieval: Routing nach Cluster oder Graph-Nachbarschaft, dann Zusammennähen eines minimalen, relevanten Kontexts. Operative Muster für Hybrid und Sharding in Weaviate best practices for hybrid search and operations.
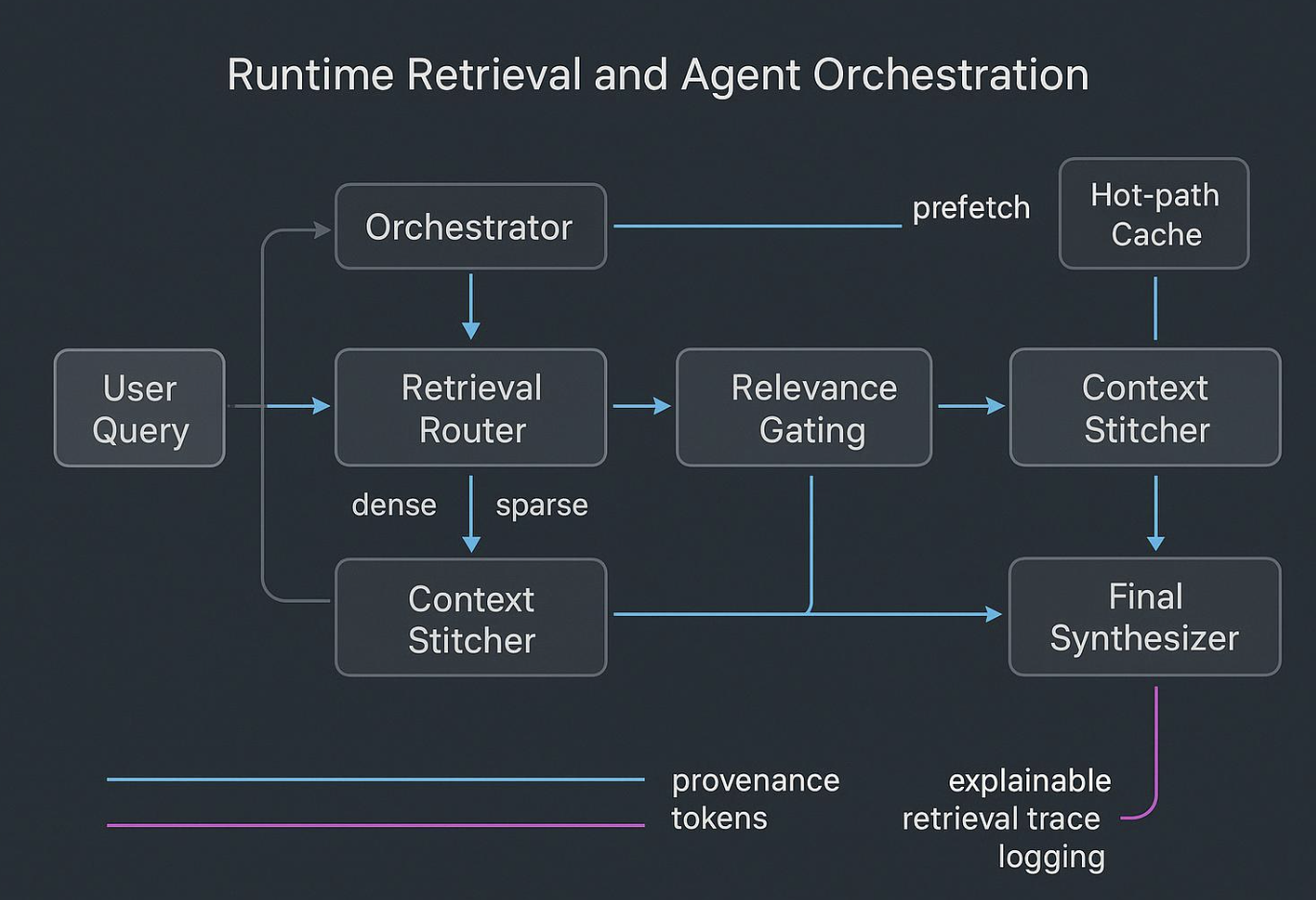
Runtime Stitching und Orchestrierung
Agents scheitern, wenn sie über rohe, verrauschte Dumps „nachdenken“. Runtime sollte so aussehen:
- Ein Planner hypothetisiert, welche Evidenz und Tools nötig sind.
- Ein Router verteilt Queries über Dense-, Sparse- und Graph-Indizes.
- Ein Gate filtert nach Provenance und Policy; ein Stitcher komponiert ein kompaktes, gut abgegrenztes Bundle.
- Sub-Agents führen eng definierte Tasks aus und liefern strikte Summaries an einen Synthesizer.
# Pseudocode für Hybrid Retrieval + Stitching
plan = planner.make_plan(user_query)
results = []
for hop in plan.hops:
dense = dense_index.search(hop.query, k=10)
sparse = sparse_index.search(hop.query, k=10, filter=plan.filters)
graph_ctx = graph.walk(hop.entities, depth=2)
gated = gate.by_provenance(dense + sparse + graph_ctx)
stitched = stitch.compact(gated, budget_tokens=1200)
results.append(stitched)
final = synthesize(results, tools=plan.tools)
return final
Context Pipeline Checkliste
- Ingest Quellen → normalisieren → auf Schema mappen.
- Mit Entitäten und Relationen anreichern → als strukturiertes Know‑How speichern.
- Hybrid-Indizes (dense, sparse, graph) mit Provenance-Metadaten bauen.
- Mit ACLs, Versionierung und Audit-Logs gaten.
- Retrieval-Fidelity und Task-Level Outcomes vor Deploy evaluieren.
- Mit Hot-Path-Caches und Prefetch deployen.
- Latenz, Precision/Recall, Drift und Audit-Traces monitoren.
Leichtgewichtiger Micro-Benchmark: Latenz vs. Antwortqualität
Dieser Aufbau hilft, drei Retrieval-Muster zu vergleichen. Klein und reproduzierbar halten.
Annahmen: 50K Dokumente über Policies, Tickets, Produktspecs; 75 Evaluierungs-Queries mit Ground Truth für 40; gleiches LLM; Hardware-Parität; Reranker wo anwendbar. Berichte Median-Latenz p50/p90 und Antwortqualität über EM/F1 oder dokumentierten LLM-Judge.
| Muster | Retrieval-Stack | Erwartete Eigenschaften |
|---|---|---|
| Naives RAG | Nur Dense | Schnell, geringere globale Kohärenz; Probleme bei Cross-Doc-Fragen |
| Tuned RAG | Dense + Sparse + Reranker | Moderate Latenz, bessere Precision bei IDs und Policy-Begriffen |
| Context Layer | Hybrid + Graph + Stitching + Summaries | Etwas höhere p50-Latenz, engere p90; stabilere globale Antworten |
Interpretation: Tuned RAG behebt viele einfache Lücken; die Context-Schicht sollte bei Cross-Document- und Multi-Step-Tasks glänzen, mit vorhersagbarerer Tail-Latenz durch Routing und Caches.
Fehlermoden und Abschwächung
- Fragmentierung über Dokumente: Entity/Relationship-Graphen bauen, lokale/globale Traversals für kohärente Bundles; hierarchische Anker für lange Narrative.
- Veraltung und Drift: Event-sourced Ingestion, inkrementelles Re-Indexing, TTLs; Changelogs bei Schema-Upgrades abspielen.
- Latenzspitzen unter Last: Tiered Hot-Path-Caches, Cluster-Routing, Prefetch für häufige Sub-Queries; Shard-Größe und Quantisierung optimieren.
- Halluzination durch verrauschten Kontext: Schemas und Provenance-Filter erzwingen; Sub-Agent-Scopes einengen; kompakte Summaries statt rohen Dumps.
- Governance-Lücken: Retrieval-Traces und Tool-Aufrufe loggen; erklärbare Evidenz-Linien verlangen; Deploys mit Eval-Thresholds und Rollback-Plänen gaten.
Praktisches Micro-Beispiel: Strukturiertes Know‑How und Hybrid-Indexierung in Aktion
Angenommen, Sie bauen einen Purchasing-Agent, der Approval-Policies anwenden muss, während er Vendor-Quotes zusammenstellt. Sie ingestern ERP-Exports, Vertrags-PDFs, Slack-Genehmigungen und E-Mail-Summaries. Die Ingestion-Pipeline mappt sie auf ein gemeinsames Schema: PurchaseOrder, Vendor, Policy, Exception. Sie reichern mit Entity Linking an, sodass jede PurchaseOrder ihren Vendor und zutreffende Policy-Knoten kennt. Dann bauen Sie einen Dense-Index für semantisches Recall, einen Sparse-Index für IDs und rechtliche Begriffe, einen Graph-Index für Policy → Exception → Approver-Pfade.
In diesem Setup routet eine Orchestrierungs-Schleife die Abfrage „Können wir PO‑2026‑1783 heute genehmigen?“ durch: Sparse-Lookup der PO-ID, Graph-Walk von der PO zu Policy und Exceptions, Dense Retrieval für aktuelle Approver-Notes. Der Stitcher komprimiert das in ein 1.2K-Token-Bundle und der Agent liefert eine kurze, zitierte Antwort mit Approval-Entscheidung und Provenance-Links.
Eine Plattform wie puppyone kann hier helfen, weil sie Wissen als strukturiertes Know‑How (JSON/Graph) speichert und Hybrid-Indexierung über Text und Struktur unterstützt. Diese Kombination ermöglicht deterministisches Retrieval und auditierbare Traces ohne fragiles Text-Scraping.
Governance und CI für Kontext
Behandeln Sie Kontext wie Code. Jede Kontextänderung braucht Provenance, Review und Tests. Versionierte Schemas, Access Policies und Evaluierungs-Suites pflegen. Vor Rollouts Retrieval-Fidelity-Checks und Task-Level-Tests laufen; erklärbare Traces erfassen und Rollback bereithalten. Wenn Ihre Agents regulierte oder sensible Daten berühren, richten Sie Ihre Prozesse am NIST AI Risk Management Framework (GOVERN) aus. Für Interop: Model Context Protocol.
Nächste Schritte
Start mit Tuned RAG, wenn Ihr Problem lokal und risikoarm ist. Bei Cross-Doc-Fragen, Governance-Bedarf oder volatilen Korpora: Context-Layer-Pilot für einen Workflow planen. Zuerst strukturiertes Know‑How bauen; Hybrid-Indexierung und Orchestrierung werden einfacher, sobald Schemas stabil sind. Evaluation eng und menschlich halten: echte Tasks testen, Traces loggen, Verbesserungen an Business-SLOs binden.
FAQs
Q1: Brauche ich sofort einen Graph?
A: Nein. Start mit Dense + Sparse; Graph hinzufügen, wenn Cross-Document-Reasoning oder globale Summarization-Lücken auftreten.
Q2: Wie groß sollten meine Chunks sein?
A: Chunk nach semantischen Einheiten an Ihrem Schema (Entitäten, Prozeduren), nicht nach festen Token-Anzahlen. Reranker und Summaries übernehmen den Rest.
Q3: Kann ich Governance auf später verschieben?
A: Sie können, zahlen aber dafür. Leichte Provenance und Access Controls von Anfang an, damit Evaluation und Rollbacks möglich sind.