Agentic RAG für die Automatisierung des Kundenservice bereitstellen
8. April 2026Lin Ivan
Kundenservice ist ein hartes Umfeld für LLMs: mehrdeutige Fragen, veraltete Dokumentation, sensible Daten und Fehlverhalten, das sofort bei echten Nutzerinnen und Nutzern sichtbar wird.
Wenn Ihre Automatisierung im Support Produktionslast aushalten soll, reicht ein einfaches RAG-Demo nicht. Sie brauchen ein agentisches System, das Anfragen routet, passende Belege findet, Tools sicher nutzt und bei Unsicherheit eskaliert.
Dieser Beitrag ist ein Deployment-Playbook für produktive Teams.
Definieren Sie zuerst, was "Automatisierung" überhaupt bedeutet
Viele Teams springen direkt zum Chatbot. Das ist verkehrt. Legen Sie zuerst fest, welche Workflows Sie automatisieren wollen und was "fertig" in diesem Kontext bedeutet.
Wählen Sie einen Einsatzmodus
Ein sinnvoller Startpunkt ist einer dieser Modi:
- Agent-Assist: Das System entwirft Antworten und sammelt Belege, ein Mensch sendet.
- Teilautomatisierung: Niedrigrisiko-Intents wie Passwort-Reset oder Rechnungsstatus werden automatisch gelöst.
- Erweiterte Automatisierung: Die meisten Intents werden automatisiert, aber erst nachdem Sicherheit und Qualität nachgewiesen sind.
Definieren Sie eine "niemals automatisieren"-Liste
Kurze Denylists sollten mindestens umfassen:
- finanzielle Aktionen über einem Grenzwert
- Änderungen der Kontoinhaberschaft
- Datenexporte
- alles Regulierte oder geschäftskritisch Riskante
Solche Fälle sollten sofort eskalieren.
Kernaussage: Support-Automatisierung ist kein einzelnes Feature, sondern ein Bündel von Workflows mit expliziten Risikogrenzen.
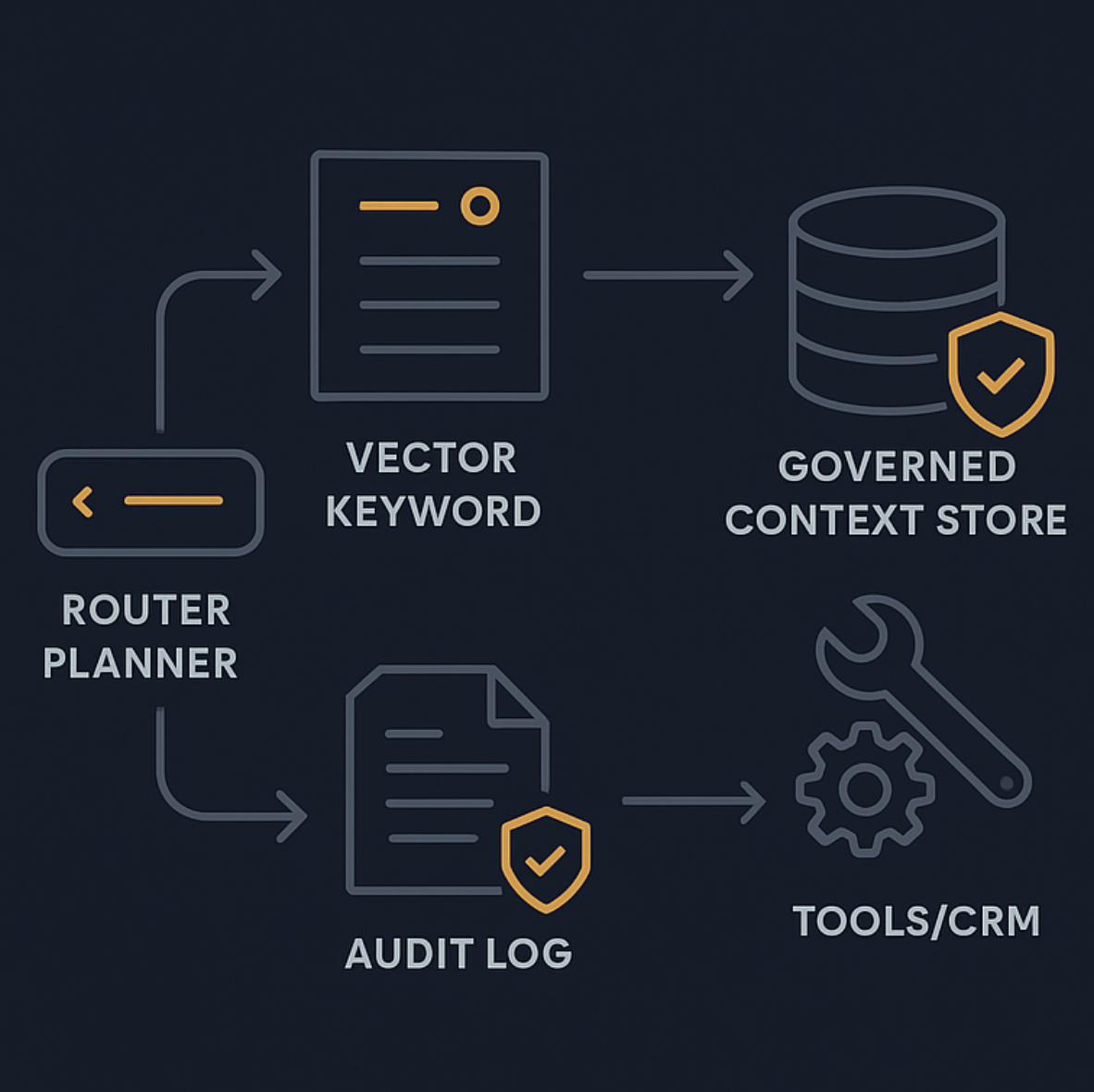
Referenzarchitektur: Agentic RAG im Kundensupport
Ein produktiver Aufbau ist keine einzelne Pipeline, sondern ein Entscheidungssystem mit Guardrails.
Ein hilfreiches Modell ist die Dreiteilung in Orchestration, Execution und Infrastructure, wie sie auch in Adaline Labs' Beitrag zu production-ready agentic RAG architecture and observability beschrieben wird.
Orchestration: Router plus Policy Engine
Diese Schicht entscheidet, was als Nächstes passiert.
Typische Aufgaben:
- Intent-Klassifikation wie FAQ, Billing, Account Access oder Outage
- entscheiden, ob Retrieval überhaupt nötig ist
- Tools auswählen, etwa CRM, Order-System oder Ticketing
- Eskalationsregeln und "niemals automatisieren"-Grenzen durchsetzen
In der Praxis landet man oft bei einer State Machine oder einem Graphen mit expliziten Knoten für Routing, Retrieval, Tool Calls, Verifikation und Eskalation.
Execution: Retrieval, Tool Calls, Antwortsynthese
Diese Schicht erledigt die eigentliche Arbeit:
- Retrieval-Query bauen
- Belege über Hybrid Retrieval und Reranking holen
- Tools mit Least Privilege aufrufen
- eine auf Belegen basierende Antwort erzeugen
Wichtig: Retrieval-Ergebnisse sind untrusted input. Das Modell kann nicht zuverlässig unterscheiden, ob ein Text nur Dokumentation ist oder ob darin Anweisungen stecken, die das System umlenken sollen.
Infrastructure: Observability, Evaluation, Reliability
Für produktiven Betrieb brauchen Sie:
- Traces für Routing, Retrieval und Tool Calls
- Evaluationssignale zur Groundedness
- Retries, Timeouts und Fallbacks
Wenn Sie nicht beantworten können, welche Belege genutzt wurden und warum eine Aktion ausgelöst wurde, ist das System nicht produktionsreif.
Voraussetzungen bei Daten und Retrieval
Wenn Ihre Dokumentation unordentlich ist, wird das Modell selbstbewusst falsch liegen.
1. Ein supportfähiges Wissenskorpus aufbauen
Ein Mindestkorpus enthält meist:
- öffentliche Help-Center-Artikel
- interne Runbooks mit sauberem Scope
- Richtlinien zu Refunds, Kündigungen und SLAs
- Changelogs, bei denen Freshness entscheidend ist
Historische Tickets sollten Sie nur mit strengen Datenschutzregeln einbeziehen.
2. Chunking so wählen, dass Kontext erhalten bleibt
Viele RAG-Projekte scheitern leise beim Chunking.
Praktisch bewährt hat sich, semantische Grenzen zu bevorzugen und jedem Chunk Kontextmarker wie Titel oder Abschnittsüberschriften mitzugeben. Orkes fasst das in seinen best practices for chunking and hybrid retrieval in production RAG gut zusammen.
3. Hybrid Retrieval plus Reranking nutzen
Support-Anfragen mischen exakte Zeichenketten wie Fehlercodes oder Rechnungsnummern mit unscharfer Absicht.
Darum ist in Produktion oft sinnvoll:
- Keyword Search für IDs und exakte Begriffe
- Vector Search für Paraphrasen
- Reranking für das finale Evidence-Set
4. Freshness- und Ownership-Metadaten ergänzen
Mindestens diese Felder sollten vorhanden sein:
- Quelltyp
- letzter Aktualisierungszeitpunkt
- zuständiges Team
- Produkt- oder Versionstags
- Sensitivitätsklasse
Freshness ist im Support kein Nice-to-have. Wer nicht beantworten kann, ob eine Policy aktuell ist, liefert irgendwann die falsche Antwort aus.
So rollen Sie Agentic RAG im Support aus
Jeder Schritt braucht Zweck, Output und einen klaren "done when"-Punkt.
Schritt 1: Intent-Router einführen und nur bei Bedarf Retrieval starten
Aktion: Implementieren Sie eine Intent-Klassifikation, die Anfragen in wenige Workflows aufteilt.
Ein einfacher Start:
- Regeln für offensichtliche Intents
- ein leichtgewichtiges Modell für den Rest
Done when:
- der gewählte Intent wird pro Request geloggt
- Sie können messen, welche Requests Retrieval brauchten
Schritt 2: Tool-Grenzen mit Least Privilege definieren
Aktion: Trennen Sie Tool-Zugriff nach Intent und Risiko.
Beispiele:
- Billing-Status darf Rechnungen lesen, aber keine Refunds auslösen
- Account-Access darf Reset-Links senden, aber keine Ownership ändern
- kein Workflow erhält gleichzeitig sensible Leserechte und unkontrollierten Schreibzugriff
Done when:
- jeder Tool Call hat einen Scope
- Logs zeigen Intent und Tool-Berechtigung
Schritt 3: Retrieval-Time Authorization umsetzen
Wenn Sie mehrere Mandanten bedienen, sind Autorisierungsfehler existenziell.
Das robusteste Muster ist, Berechtigungen an der autoritativen Datenquelle durchzusetzen und Identität bis ins Retrieval weiterzugeben. AWS beschreibt das in retrieval-time authorization and identity propagation for RAG.
Übertragen auf Ihr System bedeutet das:
- Nutzer- oder Session-Identität authentifizieren
- Mandant und Identität in den Retrieval-Pfad propagieren
- Kandidaten vor dem Modell nach Access Scope filtern
- Allow- und Deny-Entscheidungen auditierbar loggen
Schritt 4: Retrieved Text als untrusted behandeln und gegen indirekte Prompt Injection schützen
Im Kundensupport ist die Wissensbasis eine Lieferkette.
Wenn ein abgerufener Text schädliche Anweisungen enthält, kann das Modell ihnen folgen, solange das System keine Architekturgrenzen setzt. AWS beschreibt dazu Defense-in-Depth in indirect prompt injection.
Praktische Maßnahmen:
- Inputs und Tool-Outputs sanitizen
- Systeminstruktionen und Retrieval-Inhalte strikt trennen
- zustandsändernde Aktionen nur mit Bestätigung ausführen
- alles für Forensik protokollieren
Schritt 5: Einen Grounding-Vertrag einführen
Aktion: Das Modell muss:
- Wissensantworten nur auf Basis der gefundenen Belege formulieren
- Quellen referenzieren
- ablehnen oder eskalieren, wenn die Evidenz nicht reicht
Schritt 6: Verifikation und Eskalation ergänzen
Aktion: Bauen Sie einen Verifier ein, der prüft:
- widerspricht die Antwort den Policies?
- passt der Intent zu den Belegen?
- wird eine Aktion ausgelöst, die auf der Denylist steht?
Schlägt diese Prüfung fehl, muss das System nachfragen oder an Menschen übergeben.
Get Started with puppyone for governed customer service automationGet startedGovernance: versionierter Kontext, Auditability und sichere Zusammenarbeit
Viele RAG-Setups behandeln Kontext nur als Embedding-Beutel. Für Demos mag das reichen, für Support ist es riskant.
In Produktion müssen Sie kontrollieren:
- wer Wissen ändern darf
- was sich geändert hat
- wann es sich geändert hat
- welche Entscheidungen auf welcher Version basierten
Ein praktikabler Ansatz ist ein governter Kontext-Layer mit agent-lesbaren Dateien, Access Scope, Versionierung und Audit Logs. puppyone verfolgt genau diese Richtung.
Evaluation und Observability vor dem Skalieren
Sie können nicht verbessern, was Sie nicht messen.
Wichtige Kennzahlen:
- Retrieval Quality
- Faithfulness
- Escalation Rate und Action-Deny Rate
- p50/p95-Latenzen
- Kosten pro Intent-Klasse
Ebenso wichtig ist ein Eval-Set aus echten Tickets mit häufigen Fällen, Randfällen, policy-sensitiven Fragen und mehrdeutigen Formulierungen.
Rollout: von Shadow Mode zu echter Automatisierung
Ein sicherer Rollout verläuft in Stufen:
Stage 0: Shadow Mode
- System läuft parallel, antwortet aber nicht direkt an Kundschaft
- Intents, Retrieval, Drafts und Escalation Triggers werden geloggt
Stage 1: Agent-Assist
- Menschen senden weiterhin selbst
- System liefert Evidence Bundle plus Draft
Stage 2: Teilautomatisierung
- enge, risikoarme Intents werden automatisch gelöst
- riskante Flows bleiben human-gated
Stage 3: Erweiterte Automatisierung
Erst wenn Aktionen lückenlos auf Belege zurückgeführt, Knowledge Changes zurückgerollt und Tool Execution per Kill Switch gestoppt werden können.
Troubleshooting: häufige Fehlerbilder
Das Modell antwortet selbstbewusst ohne Beleg
Gegenmaßnahmen:
- Ablehnung bei zu niedriger Retrieval Confidence
- Quellenpflicht
- Routing schärfer trennen
Retrieval findet die falsche Policy-Version
Gegenmaßnahmen:
- Freshness-Filter
- Prioritätsregeln für Policies
- Drift Detection und Rollback
Prompt Injection aus retrieved content
Gegenmaßnahmen:
- retrieved text als untrusted behandeln
- Tool Gating und Bestätigungspflichten
- Sanitization und harte Prompt-Grenzen
Latenzspitzen in Produktion
Gegenmaßnahmen:
- nur bei Bedarf Retrieval
- Caching für häufige Anfragen
- Reranking nur dort, wo es wirklich zählt
Key takeaways
- Agentic RAG im Support ist ein Workflow-System aus Router, Retrieval, Tools, Verifikation und Eskalation.
- Die schwierigen Teile sind operativ: Autorisierung, Injection-Abwehr, Evaluation und ein gestufter Rollout.
- Governance ist unverzichtbar, weil sowohl Kontext als auch Entscheidungen versionierbar und auditierbar sein müssen.
Next steps
Wenn Sie heute RAG und Tools zusammenkleben und an Berechtigungen, Audit Trails oder Rollback scheitern, lohnt sich ein Blick auf: