Wie man RL-Skalierung mit RAG zur Wissenserweiterung durchführt
27. April 2025Mei @puppyone
 Bildquelle: Pexels
Bildquelle: Pexels
Die Skalierung des Reinforcement Learning (RL) transformiert die KI, indem sie die Modellleistung durch adaptive Lernstrategien optimiert. Durch die Nutzung von Skalierungsgesetzen sagt die RL-Skalierung das Verhalten großer Modelle aus kleineren Experimenten voraus und ermöglicht so eine effiziente Ressourcennutzung. Modelle mit größerer Speicherkapazität zeigen beispielsweise Leistungssteigerungen von bis zu 50 % im Vergleich zu Basismodellen.
Retrieval-Augmented Generation (RAG) verbessert KI-Systeme durch die Kombination von Datenabruf und Textgenerierung. Es ruft kontextbezogene Informationen aus riesigen Daten-Repositories ab und stellt sicher, dass die Ausgaben korrekt und relevant bleiben. Dieser Ansatz verbessert Anwendungen wie Tiefenrecherche und Wissensabruf in Echtzeit erheblich.
Die Integration von RAG und RL schafft eine starke Synergie. Systeme wie DeepResearcher zeigen dies und erreichen bis zu 28,9 Punkte höhere Aufgabenerfüllungsraten im Vergleich zu herkömmlichen Methoden. Durch die Kombination von kontextbezogenem Informationsabruf mit RL-Optimierung liefern KI-Systeme eine verbesserte Leistung in verschiedenen Bereichen.
Wichtige Erkenntnisse
- Reinforcement Learning (RL)-Skalierung hilft der KI, besser und schneller zu lernen.
- Retrieval-Augmented Generation (RAG) kombiniert das Finden von Daten mit der Erstellung von Text. Dies hält die Ergebnisse korrekt und themenbezogen.
- Die Verwendung von RAG mit RL verbessert die Leistung von Modellen erheblich. Es kann Fehler um 69 % reduzieren und die Entscheidungsfindung verbessern.
- Um die RL-Skalierung mit RAG zu verwenden, wählen Sie ein Basismodell aus. Trainieren Sie es dann mit beschrifteten Daten und verwenden Sie Tools wie Pinecone, um Daten schnell zu finden.
- Zusammen verbessern RAG und RL die KI in vielen Bereichen. Sie machen den Kundenservice, Suchmaschinen und Wissenssysteme intelligenter.
Verständnis der Retrieval-Augmented Generation (RAG)
 Bildquelle: Pexels
Bildquelle: Pexels
Was ist Retrieval-Augmented Generation?
Retrieval-Augmented Generation (RAG) stellt einen bahnbrechenden Ansatz in der künstlichen Intelligenz dar. Es kombiniert zwei wesentliche Prozesse: das Abrufen relevanter Daten und das Generieren kontextuell genauer Ausgaben. Im Gegensatz zu herkömmlichen generativen Modellen, die sich ausschließlich auf vorab trainiertes Wissen verlassen, integriert RAG Echtzeitinformationen, um seine Antworten zu verbessern. Dieser duale Mechanismus stellt sicher, dass die Ausgaben nicht nur kohärent, sondern auch auf Fakten basieren.
Das Konzept von RAG gewann durch Forschungsarbeiten wie Lewis et al.'s 2021er Papier, Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, an Bedeutung. Frühere grundlegende Arbeiten von Guu et al. führten die Idee ein, den Wissensabruf während des Vortrainings zu integrieren. Diese Fortschritte haben RAG zu einem Eckpfeiler moderner KI-Anwendungen gemacht und ermöglichen es Systemen, maßgeblichere und zuverlässigere Ergebnisse zu liefern.
Wie RAG Abruf und Generierung kombiniert
RAG integriert nahtlos Abruf und Generierung, indem es externe Informationsabrufsysteme neben großen Sprachmodellen (LLMs) nutzt. Der Prozess beginnt mit einer Abrufphase, in der das System nach relevanten Daten aus externen Quellen wie Datenbanken oder Wissens-Repositories sucht. Diese abgerufenen Informationen dienen dann als Eingabe für die Generierungsphase, in der das Modell Antworten produziert, die sowohl kontextuell genau als auch semantisch reich sind.
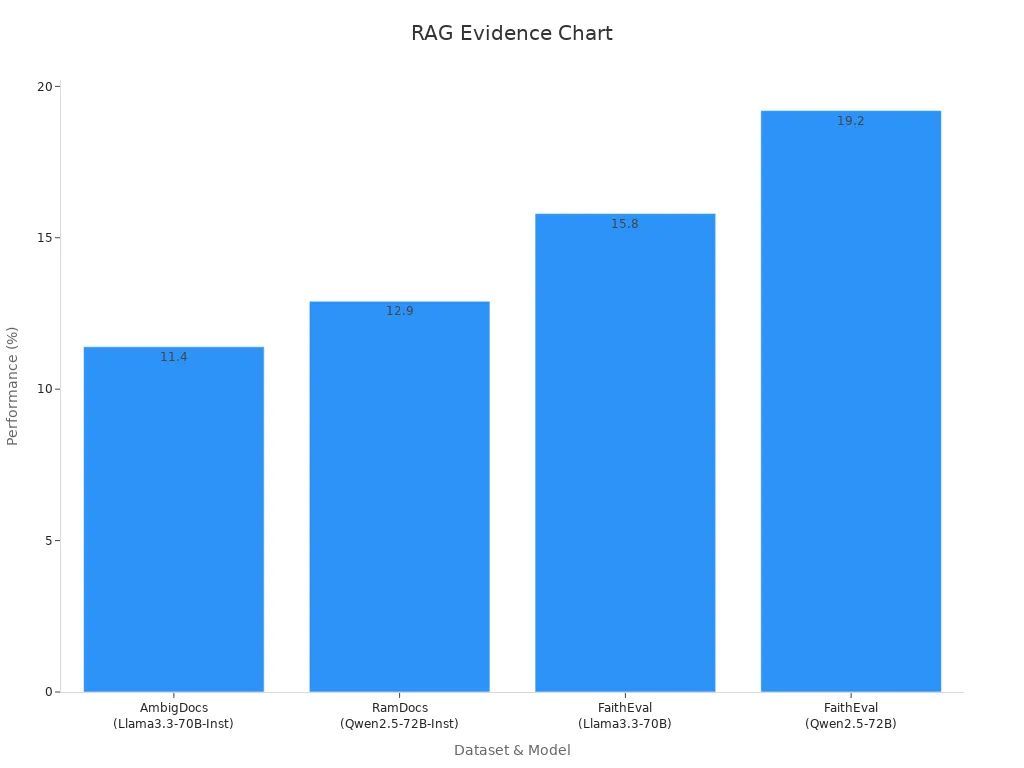
Das Madam-RAG-Modell zeigt beispielsweise, wie diese Kombination die Leistung über verschiedene Datensätze hinweg verbessert:
| Modell | Datensatz | Leistungssteigerung |
|---|---|---|
| Madam-RAG | AmbigDocs | +11,40 % (Llama3.3-70B-Inst) |
| Madam-RAG | RamDocs | +12,90 % (Qwen2.5-72B-Inst) |
| Madam-RAG | FaithEval | +15,80 % (Llama3.3-70B) |
| Madam-RAG | FaithEval | +19,20 % (Qwen2.5-72B) |
 Bildquelle: Pexels
Bildquelle: Pexels
Vorteile der RAG-Pipeline zur Wissenserweiterung
Die RAG-Pipeline bietet zahlreiche Vorteile zur Verbesserung wissensintensiver Aufgaben. Ihre Fähigkeit, Informationen dynamisch abzurufen und zu generieren, macht sie zu einem vielseitigen Werkzeug in allen Branchen. Zu den wichtigsten Vorteilen gehören:
- Verbesserung der Kundenservice-Interaktionen: RAG bietet personalisierte und präzise Antworten und steigert die Kundenzufriedenheit.
- Verbesserung der Inhaltserstellung und des Copywritings: Es generiert ansprechende und kontextrelevante Inhalte, die auf bestimmte Zielgruppen zugeschnitten sind.
- Förderung von E-Learning- und virtuellen Tutoring-Systemen: RAG schafft interaktive Lernumgebungen, indem es geeignete Erklärungen aus Bildungsdatenbanken abruft.
- Revolutionierung der Gesundheitsdiagnose: Es rationalisiert die Diagnose durch den Abruf relevanter Gesundheitsakten und ermöglicht genaue und zeitnahe Konsultationen.
- Analyse des Kundenfeedbacks: RAG beschleunigt die Stimmungsanalyse durch den Zugriff auf verschiedene Feedback-Quellen und hilft Unternehmen, ihre Angebote zu verfeinern.
Die transformative Wirkung von RAG geht über diese Anwendungsfälle hinaus. Durch die Verbindung von dynamischem Wissensabruf mit generativer Genauigkeit gestaltet RAG KI-Anwendungen in allen Branchen neu. Seine Fähigkeit, Echtzeitdaten und spezialisiertes Wissen zu nutzen, verbessert die Leistung und Zuverlässigkeit von KI-Systemen erheblich. Prognosen deuten darauf hin, dass der RAG-Markt bis 2035 auf 40,34 Milliarden US-Dollar wachsen wird, mit einer jährlichen Wachstumsrate von etwa 35 %. Dieses Wachstum unterstreicht seine entscheidende Rolle bei der Bewältigung der Halluzinationsprobleme der KI und der Verbesserung der Inhaltsrelevanz.
RL-Skalierung und ihre Bedeutung in der KI
Was ist RL-Skalierung?
RL-Skalierung bezeichnet den Prozess der Verbesserung von Reinforcement-Learning-Modellen (RL) durch Erhöhung ihrer Fähigkeit, komplexe Aufgaben zu bewältigen. Es umfasst die Skalierung von Rechenressourcen, Dateneingaben und Modellarchitekturen, um die Lerneffizienz und Anpassungsfähigkeit zu verbessern. Im Gegensatz zu herkömmlichen Skalierungsmethoden betont die RL-Skalierung aktives Lernen durch dynamische Interaktionen und Feedback-Mechanismen.
Zu den wichtigsten Prinzipien der RL-Skalierung gehören:
- Self-Play Reinforcement Learning (SPRL): Diese Methode ermöglicht es Agenten, durch Interaktion mit sich selbst zu lernen und fördert so aktives Lernen durch Erfahrung.
- Der Lernzyklus: Agenten beobachten ihre Umgebung, handeln, erhalten Feedback und passen ihr Verhalten in einer kontinuierlichen Schleife an.
- Neudefinition der Skalierbarkeit: Neue Skalierungsgesetze berücksichtigen die Rechenkosten der Exploration und stellen herkömmliche Methoden in Frage.
Diese Prinzipien unterstreichen das transformative Potenzial der RL-Skalierung bei der Weiterentwicklung von KI-Systemen.
Zweck der RL-Skalierung in KI-Modellen
Das Hauptziel der RL-Skalierung besteht darin, die Effizienz und Anpassungsfähigkeit von KI-Modellen zu verbessern. Herkömmliche Skalierungsmethoden haben oft mit instabilen Trainingsdynamiken zu kämpfen, die die Leistung beeinträchtigen können. Die RL-Skalierung begegnet diesen Herausforderungen durch die Einführung von Mechanismen wie Soft Mixtures of Experts (MoEs). Diese Mechanismen optimieren die Ressourcenzuweisung und verbessern die Lernergebnisse in verschiedenen RL-Einstellungen.
Empirische Studien belegen die Wirksamkeit der RL-Skalierung. Beispielsweise erreichte das Modell Open Reasoner Zero Leistungsniveaus, die mit spezialisierten RL-Systemen vergleichbar sind, indem es ein Basismodell nutzte. Dies unterstreicht die Bedeutung der RL-Skalierung bei der Verfeinerung großer Sprachmodelle und der Sicherstellung, dass sie genaue und zuverlässige Ergebnisse liefern.
Vorteile der Kombination von RAG und RL
Die Integration von RAG mit RL schafft ein robustes Framework für wissensintensive Aufgaben. RAG verbessert den Abruf relevanter Daten, während RL den Lernprozess optimiert. Zusammen verbessern sie die Leistung großer Sprachmodelle erheblich. Studien haben eine 69%ige Reduzierung des Modellverlusts gezeigt, der von 0,32 auf 0,1 sank. Diese Verbesserung stellt sicher, dass Benutzer präzise und kontextuell genaue Informationen erhalten.
Die Kombination von RAG und RL unterstützt auch Multi-Agenten-Systeme. Diese Systeme ermöglichen es Agenten, zusammenzuarbeiten und ihre Fähigkeit zu verbessern, tiefgehende Forschung durchzuführen und komplexe Probleme zu lösen. Durch die Einbeziehung von Abrufprozessen in RL-Workflows erreichen KI-Systeme eine größere Stabilität und Skalierbarkeit. Diese Synergie unterstreicht die Bedeutung von RAG bei der Bewältigung der Einschränkungen herkömmlicher RL-Methoden.
Schritt-für-Schritt-Anleitung zur RL-Skalierung nach der Verwendung von RAG
 Bildquelle: Pexels
Bildquelle: Pexels
Voraussetzungen für die RL-Skalierung mit RAG
Vor der Implementierung der RL-Skalierung mit RAG müssen bestimmte Voraussetzungen erfüllt sein, um einen reibungslosen Arbeitsablauf zu gewährleisten. Zu diesen Voraussetzungen gehören:
- Ein Basismodell: Wählen Sie ein grundlegendes großes Sprachmodell (LLM), das in der Lage ist, Abruf- und Generierungsaufgaben zu bewältigen. Modelle wie Llama oder Qwen werden aufgrund ihrer Anpassungsfähigkeit häufig verwendet.
- Wissensabrufsystem: Integrieren Sie ein robustes Abrufsystem wie die Pinecone-Vektordatenbank, um eine effiziente Ähnlichkeitssuche und dynamische Abfragen des Agenten zu ermöglichen. Dies stellt den Abruf relevanter Daten für Generierungsaufgaben sicher.
- Annotierter Datensatz: Bereiten Sie einen abfragespezifischen Datensatz vor, der als Begründungsketten strukturiert ist. Dieser Datensatz dient als Grundlage für überwachtes Feinabstimmen und anschließende RL-Ausrichtung.
- Wissensselektor: Implementieren Sie einen Wissensselektor, um abgerufene Informationen zu filtern. Dies wird entscheidend, wenn mit schwächeren Generatormodellen oder mehrdeutigen Aufgaben gearbeitet wird.
- Multi-Agenten-Kollaboration: Richten Sie ein Multi-Agenten-System ein, um die Skalierbarkeit und die Fähigkeiten zur Tiefenrecherche zu verbessern. Agenten können zusammenarbeiten, um Abruf- und Generierungsprozesse zu verfeinern.
Diese Voraussetzungen bilden die Grundlage für den Aufbau eines RAG-Agenten, der zu einer effizienten RL-Skalierung fähig ist.
Werkzeuge und Frameworks für die RL-Skalierung
Mehrere Werkzeuge und Frameworks unterstützen die RL-Skalierung und ermöglichen eine effiziente Implementierung und Optimierung. Zu den wichtigsten Optionen gehören:
- Pinecone-Vektordatenbank: Dieses Tool ist auf eine effiziente Ähnlichkeitssuche spezialisiert und gewährleistet den schnellen Abruf relevanter Daten. Es spielt eine entscheidende Rolle bei der Abfrage unseres Agenten und der Verbesserung der Abrufgenauigkeit.
- VeRL-Framework: Das VeRL-Framework von ByteDance bietet eine robuste Umgebung für das RL-Training. Es unterstützt die Integration von RAG und RL und ermöglicht eine nahtlose Ausrichtung von Abruf- und Generierungsprozessen.
- Modifizierte PPO-Algorithmen: Proximal Policy Optimization (PPO)-Algorithmen, die für die RL-Skalierung angepasst wurden, verbessern die Lerndynamik und die Konvergenzraten. Diese Modifikationen wurden in Umgebungen wie Atari-Spielen und Box2D verglichen.
- Contrastive Multi-Task Learning (CML): Diese Technik verbessert die Fähigkeit des Modells, während des Trainings zwischen relevanten und irrelevanten Informationen zu unterscheiden. Sie ergänzt die RL-Ausrichtung durch die Verfeinerung des Abrufprozesses.
| Modell | Durchschnittliche Genauigkeit (%) | Verbesserung (%) |
|---|---|---|
| ToRL-1.5B | 48,5 | - |
| Qwen2.5-Math-1.5B-Instruct | 35,9 | - |
| Qwen2.5-Math-1.5B-Instruct-TIR | 41,3 | - |
| ToRL-7B | 62,1 | 14,7 |
Diese Werkzeuge und Frameworks bieten die notwendige Infrastruktur für eine effiziente Skalierung von RL unter Nutzung von RAG.
Implementierungsschritte für die RL-Skalierung
Die Implementierung der RL-Skalierung nach der Anwendung von RAG erfordert einen strukturierten Ansatz. Befolgen Sie diese Schritte, um eine optimale Leistung zu gewährleisten:
- Datenerfassung: Sammeln Sie einen abfragespezifischen annotierten Datensatz, der als Begründungsketten strukturiert ist. Dieser Datensatz bildet die Grundlage für das überwachte Feinabstimmen.
- Überwachtes Feinabstimmen (SFT): Trainieren Sie das Basismodell mit dem gesammelten Datensatz. Dieser Schritt verbessert die Abruf- und Generierungsfähigkeiten des Modells.
- Contrastive Multi-Task Learning (CML): Verfeinern Sie die Fähigkeit des Modells, zwischen relevanten und irrelevanten Informationen zu unterscheiden. Dieser Schritt verbessert die Abrufgenauigkeit und die Generierungsqualität.
- RL-Ausrichtung: Stimmen Sie das Modell mithilfe von Reinforcement-Learning-Techniken ab. Richten Sie seine Ausgaben basierend auf Feedback-Mechanismen an den gewünschten Ergebnissen aus.
- Integration mit Pinecone: Verbinden Sie das Modell mit der Pinecone-Vektordatenbank für eine effiziente Ähnlichkeitssuche. Diese Integration gewährleistet einen schnellen und genauen Abruf während der Generierungsaufgaben.
- Multi-Agenten-Kollaboration: Setzen Sie ein Multi-Agenten-System ein, um die Skalierbarkeit und die Fähigkeiten zur Tiefenrecherche zu verbessern. Agenten arbeiten zusammen, um Abruf- und Generierungsworkflows zu optimieren.
- Leistungsüberwachung: Überwachen Sie kontinuierlich die Leistung des Modells anhand von Metriken wie Knowledge F1 und Abrufgenauigkeit. Passen Sie die Trainingsparameter an, um die Effizienz aufrechtzuerhalten.
Tipp: Das Mischen von Goldwissen mit Ablenkungswissen während des Trainings kann verschiedene Auswahlergebnisse simulieren und die Anpassungsfähigkeit des Modells verbessern.
Durch Befolgen dieser Schritte können Entwickler die RL-Skalierung mit RAG erfolgreich implementieren und eine verbesserte Leistung und Skalierbarkeit in KI-Systemen erzielen.
Feinabstimmung und Optimierung in der RAG-Pipeline
Feinabstimmung und Optimierung spielen eine entscheidende Rolle bei der Verbesserung der Leistung von Modellen innerhalb der RAG-Pipeline. Diese Prozesse verfeinern die Fähigkeit des Modells, genaue, kontextrelevante Ausgaben abzurufen und zu generieren. Das Erreichen optimaler Ergebnisse erfordert jedoch eine sorgfältige Planung und Ausführung, um potenzielle Fallstricke zu vermeiden.
Herausforderungen bei der Feinabstimmung der RAG-Pipeline
Die Feinabstimmung innerhalb der RAG-Pipeline stößt oft auf Herausforderungen, die die Modellleistung beeinträchtigen können. Beispielsweise führt eine Erhöhung der Stichprobengröße während der Feinabstimmung nicht immer zu besseren Ergebnissen. Studien haben gezeigt, dass größere Stichprobengrößen sowohl die Genauigkeit als auch die Vollständigkeit verringern können. In einem Experiment sank die Genauigkeit des Mixtral-Modells von 4,04 auf 3,28, als die Stichprobengröße von 500 auf 1000 erhöht wurde. Dies unterstreicht die Notwendigkeit eines ausgewogenen Ansatzes bei der Feinabstimmung, bei dem die Qualität der Daten Vorrang vor der Quantität hat.
Eine weitere Herausforderung besteht darin, die Fähigkeit des Modells zur Verallgemeinerung auf verschiedene Aufgaben aufrechtzuerhalten. Eine Überanpassung an bestimmte Datensätze während der Feinabstimmung kann die Anpassungsfähigkeit des Modells einschränken. Dies ist besonders problematisch in wissensintensiven Anwendungen, bei denen die RAG-Pipeline eine breite Palette von Abfragen und Kontexten verarbeiten muss.
Strategien für eine effektive Feinabstimmung
Um diesen Herausforderungen zu begegnen, können Entwickler verschiedene Strategien anwenden:
- Selektive Datenstichprobe: Anstatt große Datensätze wahllos zu verwenden, konzentrieren Sie sich auf hochwertige, annotierte Stichproben, die mit den Zielaufgaben des Modells übereinstimmen. Dieser Ansatz minimiert das Risiko einer Leistungsverschlechterung.
- Inkrementelle Feinabstimmung: Stimmen Sie das Modell schrittweise in kleineren Phasen ab, damit es sich anpassen kann, ohne seine Lernkapazität zu überfordern. Diese Methode hilft, ein Gleichgewicht zwischen Spezialisierung und Verallgemeinerung zu wahren.
- Wissensmischung: Integrieren Sie während des Trainings eine Mischung aus Goldstandard-Wissen und Ablenkungsinformationen. Diese Technik verbessert die Fähigkeit des Modells, zwischen relevanten und irrelevanten Daten zu unterscheiden, und verbessert die Abrufgenauigkeit.
Optimierungstechniken für die RAG-Pipeline
Die Optimierung stellt sicher, dass die RAG-Pipeline effizient arbeitet und konsistente Ergebnisse liefert. Zu den wichtigsten Techniken gehören:
- Dynamische Abrufmechanismen: Die Implementierung von Echtzeit-Abrufsystemen ermöglicht es dem Modell, auf aktuelle Informationen zuzugreifen. Dies ist besonders nützlich in Anwendungen wie der Tiefenrecherche, bei denen sich das Wissen schnell entwickelt.
- Multi-Agenten-Kollaboration: Der Einsatz mehrerer Agenten innerhalb der RAG-Pipeline verbessert die Skalierbarkeit und die Aufgabenspezialisierung. Jeder Agent kann sich auf bestimmte Aspekte des Abrufs oder der Generierung konzentrieren und so die Gesamtleistung des Systems verbessern.
- Contrastive Multi-Task Learning (CML): Diese Technik verfeinert die Fähigkeit des Modells, während des Trainings relevante Informationen zu priorisieren. Durch den Kontrast zwischen korrekten und falschen Abrufen schärft CML die Entscheidungsfähigkeiten des Modells.
Tipp: Überwachen Sie regelmäßig Leistungsmetriken wie Abrufgenauigkeit und Knowledge F1-Scores. Passen Sie die Trainingsparameter basierend auf diesen Metriken an, um eine optimale Leistung aufrechtzuerhalten.
Durch die Kombination von Feinabstimmung mit robusten Optimierungsstrategien kann die RAG-Pipeline eine überlegene Leistung bei wissensintensiven Aufgaben erzielen. Diese Methoden stellen sicher, dass die Pipeline anpassungsfähig, genau und effizient bleibt, auch wenn die Komplexität ihrer Anwendungen zunimmt.
Praktische Anwendungen von RAG und RL
Verbesserung von Kundensupport-Chatbots
Kundensupport-Chatbots, die von RAG und RL angetrieben werden, liefern präzise und kontextrelevante Antworten. Durch die Integration von Abrufmechanismen greifen diese Chatbots auf Echtzeitdaten zu, um Benutzeranfragen effektiv zu beantworten. Reinforcement Learning optimiert ihre Leistung weiter, indem es die Antworten an die Vorlieben und das Feedback der Benutzer anpasst. Diese Kombination stellt sicher, dass Chatbots genaue Informationen liefern und gleichzeitig die Benutzerzufriedenheit verbessern.
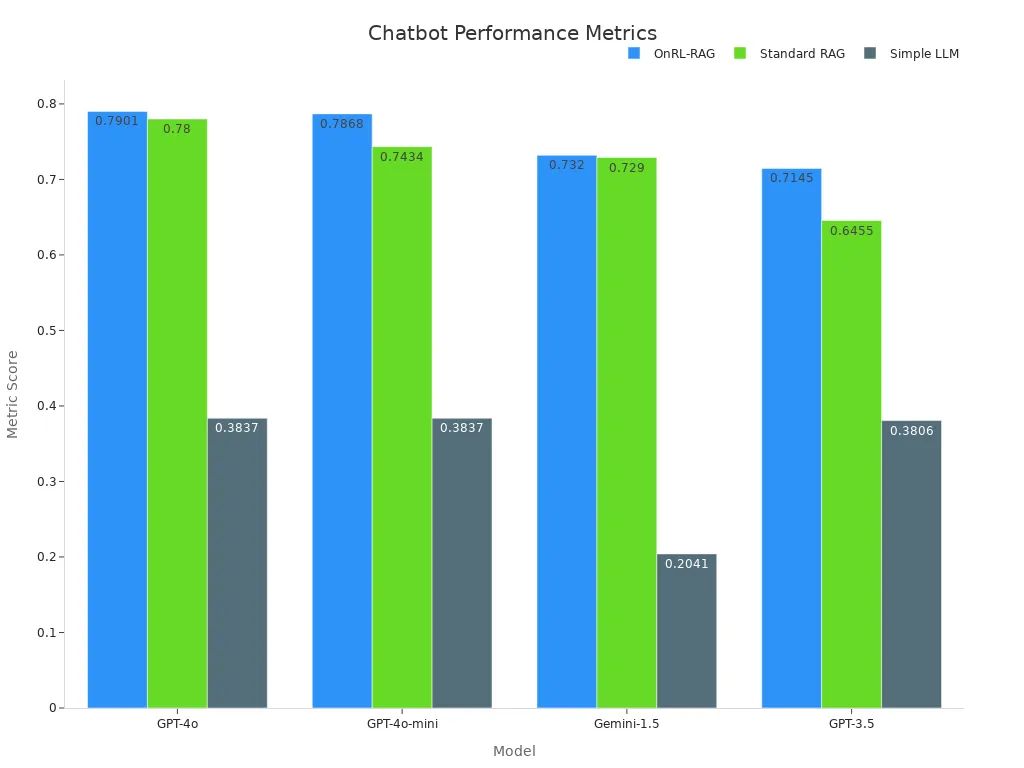
Empirische Studien unterstreichen die Wirksamkeit dieses Ansatzes. Beispielsweise übertrifft das OnRL-RAG-Framework durchweg Standard-RAG und einfache LLMs bei verschiedenen Modellen. Die folgende Tabelle veranschaulicht die Leistungsmetriken:
| Modell | OnRL-RAG | Standard-RAG | Einfaches LLM |
|---|---|---|---|
| GPT-4o | 0,7901 | 0,7800 | 0,3837 |
| GPT-4o-mini | 0,7868 | 0,7434 | 0,3837 |
| Gemini-1.5 | 0,7320 | 0,7290 | 0,2041 |
| GPT-3.5 | 0,7145 | 0,6455 | 0,3806 |
 Bildquelle: Pexels
Bildquelle: Pexels
Einzelhandels-Chatbots, die RAG und RL verwenden, verbessern auch die betriebliche Effizienz, indem sie die Reaktionszeiten verkürzen. Diese Systeme passen sich dynamisch an die Bedürfnisse der Benutzer an und gewährleisten ein nahtloses Kundenerlebnis.
Verbesserung von Suchmaschinen mit RAG und RL
Suchmaschinen profitieren erheblich von der Integration von RAG und RL. RAG verbessert den Abrufprozess durch den Zugriff auf relevante Daten aus riesigen Repositories, während RL Suchalgorithmen optimiert, um die Genauigkeit und Relevanz zu verbessern. Diese Synergie ermöglicht es Suchmaschinen, auch bei komplexen Anfragen präzise Ergebnisse zu liefern.
Das ReZero-Framework veranschaulicht diese Verbesserung. Es belohnt die Beharrlichkeit bei Suchversuchen und erreicht eine Spitzen-Genauigkeit von 46,88 % im Vergleich zu einer Basislinie von 25 %. Die folgende Tabelle hebt diese Leistung hervor:
| Modell | Genauigkeit (%) | Basislinie (%) |
|---|---|---|
| ReZero-Modell | 46,88 | 25,00 |
Durch die Nutzung von RL verfeinern Suchmaschinen ihre Algorithmen, um die Benutzerabsicht zu priorisieren. Dieser Ansatz stellt sicher, dass Benutzer die relevantesten Informationen erhalten und verbessert ihr Gesamterlebnis. Darüber hinaus erleichtern Tools wie Pinecone den effizienten Abruf und ermöglichen es Suchmaschinen, große Datenabfragen problemlos zu bewältigen.
Wissensmanagementsysteme in Unternehmen
Unternehmen verlassen sich auf Wissensmanagementsysteme, um Abläufe zu rationalisieren und die Entscheidungsfindung zu verbessern. RAG und RL verbessern diese Systeme, indem sie den dynamischen Abruf und die Generierung von Informationen ermöglichen. RAG ruft relevante Daten aus internen und externen Quellen ab, während RL die Ausgaben an den Unternehmenszielen ausrichtet.
Beispielsweise verwendet der digitale Assistent einer großen Bank RAG, um regulatorische Informationen abzurufen, die Einhaltung von Vorschriften sicherzustellen und die Kundeninteraktionen zu verbessern. In ähnlicher Weise nutzen Gesundheitsorganisationen RAG-Systeme, um auf medizinische Richtlinien und Forschungsergebnisse zuzugreifen und die klinische Entscheidungsunterstützung zu verbessern. Pinecone spielt in diesen Anwendungen eine entscheidende Rolle, indem es eine effiziente Ähnlichkeitssuche und einen effizienten Abruf ermöglicht.
Die Zusammenarbeit von Multi-Agenten verbessert die Skalierbarkeit in Unternehmenssystemen weiter. Agenten arbeiten zusammen, um Abruf- und Generierungsprozesse zu verfeinern und sicherzustellen, dass Benutzer genaue und umsetzbare Erkenntnisse erhalten. Dieser Ansatz transformiert das Wissensmanagement und macht es anpassungsfähiger und effizienter.
Die Integration der RL-Skalierung mit RAG transformiert KI-Systeme, indem sie ihre Genauigkeit, Robustheit und Anpassungsfähigkeit verbessert. Diese Synergie ermöglicht es Modellen, Echtzeitwissen abzurufen und die Entscheidungsfindung und Leistung bei verschiedenen Aufgaben zu verbessern. Zum Beispiel:
| Hauptvorteil | Beschreibung |
|---|---|
| Verbesserte Genauigkeit | Verbesserte Präzision beim Datenabruf und bei der Antwortgenerierung. |
| Robustheit | Erhöhte Widerstandsfähigkeit von KI-Systemen in dynamischen Umgebungen. |
| Generalisierungsfähigkeiten | Bessere Leistung bei verschiedenen Datensätzen und komplexen Aufgaben. |
Tipp: Erkunden Sie die RL-Skalierung, um das volle Potenzial Ihrer KI-Modelle auszuschöpfen. Die Kombination von RAG mit RL bietet ein leistungsstarkes Framework für wissensintensive Anwendungen.
FAQ
Was ist der Unterschied zwischen RAG und RL-Skalierung?
RAG ruft relevante Daten ab und generiert kontextuell genaue Ausgaben. Die RL-Skalierung optimiert KI-Modelle, indem sie ihre Lerneffizienz und Anpassungsfähigkeit verbessert. Zusammen verbessern sie die Leistung, indem sie den Echtzeit-Wissensabruf mit Reinforcement Learning für eine bessere Entscheidungsfindung kombinieren.
Kann RAG mit jedem Basismodell verwendet werden?
Ja, RAG funktioniert mit den meisten großen Sprachmodellen (LLMs). Beliebte Optionen sind Llama und Qwen aufgrund ihrer Anpassungsfähigkeit. Entwickler müssen sicherstellen, dass das Basismodell Abruf- und Generierungsaufgaben für eine nahtlose Integration unterstützt.
Wie verbessert die RL-Skalierung KI-Systeme?
Die RL-Skalierung verbessert KI-Systeme, indem sie ihren Lernprozess verfeinert. Sie verwendet dynamische Feedback-Mechanismen, um die Ausgaben an den gewünschten Zielen auszurichten. Dieser Ansatz verbessert die Genauigkeit, Stabilität und Skalierbarkeit, insbesondere in komplexen Umgebungen.
Welche Tools sind für die Implementierung von RAG und RL unerlässlich?
Zu den wichtigsten Tools gehören Pinecone für den effizienten Datenabruf, VeRL für das RL-Training und modifizierte PPO-Algorithmen zur Optimierung. Diese Tools optimieren die Arbeitsabläufe und gewährleisten eine hohe Leistung bei der Skalierung.
Sind Multi-Agenten-Systeme für die RL-Skalierung notwendig?
Multi-Agenten-Systeme sind nicht zwingend erforderlich, aber sehr vorteilhaft. Sie verbessern die Skalierbarkeit und die Aufgabenspezialisierung. Agenten arbeiten zusammen, um Abruf- und Generierungsprozesse zu verfeinern und die Gesamteffizienz des Systems zu verbessern.