RAG ist nicht tot, Agentic RAG ist einfach besser
27. November 2025Guanqun @puppyone
TL;DR: Dies ist ein Open-Source-Projekt: https://github.com/puppyone/DeepWideResearch
Es ersetzt fragile RAG-Pipelines durch agentenbasierte Workflows und behebt den Wartungsalbtraum und den Qualitätsabfall.
Der Zielkonflikt ist real: Agentic RAG kostet mehr (> 0,10 $/Anfrage gegenüber ~0,01 $ für herkömmliches RAG) und ist langsamer (> 10s+ gegenüber unter 3s). Wenn Sie Antworten im Sub-Sekunden-Bereich in großem Maßstab benötigen, ist dies nichts für Sie. Aber wenn Sie präzise, wartbare Wissens-QA benötigen, lesen Sie weiter.
Ich werde unsere Erfahrungen beim Aufbau der neuen Agentic-RAG-Architektur teilen und untersuchen, warum Agentic RAG der entscheidende Schritt für Wissens-QA in Unternehmen ist.
Im letzten Jahr habe ich 5 traditionelle RAG-Projekte umgesetzt, die jeweils 100 bis 1000 Seiten an Dokumentation umfassten. Der Tech-Stack war Standard: Query-Erstellung, Query-Routing, Chunking, Embedding, Reranking usw. Zuerst lief alles reibungslos, aber wir tappten bald in eine Falle: Der gesamte Prozess war extrem starr und schwer zu warten.
Die schmerzhafteste Erkenntnis kam mit einer Dokumentenänderung. Eine einfache Änderung ließ den gesamten RAG-Score sinken. Um den gleichen Score beizubehalten, mussten wir unsere gesamte Pipeline-Strategie von Grund auf neu aufbauen. Jede neue Datenquelle fühlte sich an, als würde man einen neuen Krieg führen. Wir versuchten, das Problem mit komplexem Metadaten-Tagging und feingranularem Chunking zu beheben, aber das waren nur Notlösungen für eine kaputte Architektur.
Wir begannen, uns zu fragen: Was machen wir falsch?
Das Problem lag in der Logik. Herkömmliches RAG bedeutet im Wesentlichen, hartcodierte if-else-Regeln zu schreiben, um ein Dataset durch Curve-Fitting anzupassen. Das funktioniert für statischen Code, aber es versagt, wenn man echte Intelligenz benötigt.
Inspiriert von OpenAIs Deep Research beschloss ich, die starre Pipeline über Bord zu werfen.
Ich wechselte zu einer Agentic + MCP (Model Context Protocol)-Architektur. Die Idee ist einfach: Anstelle einer komplexen Retrieval-Kette geben wir dem Agenten Werkzeuge, um jede Datenquelle direkt zu durchsuchen.
Hier ist die Systemarchitektur:
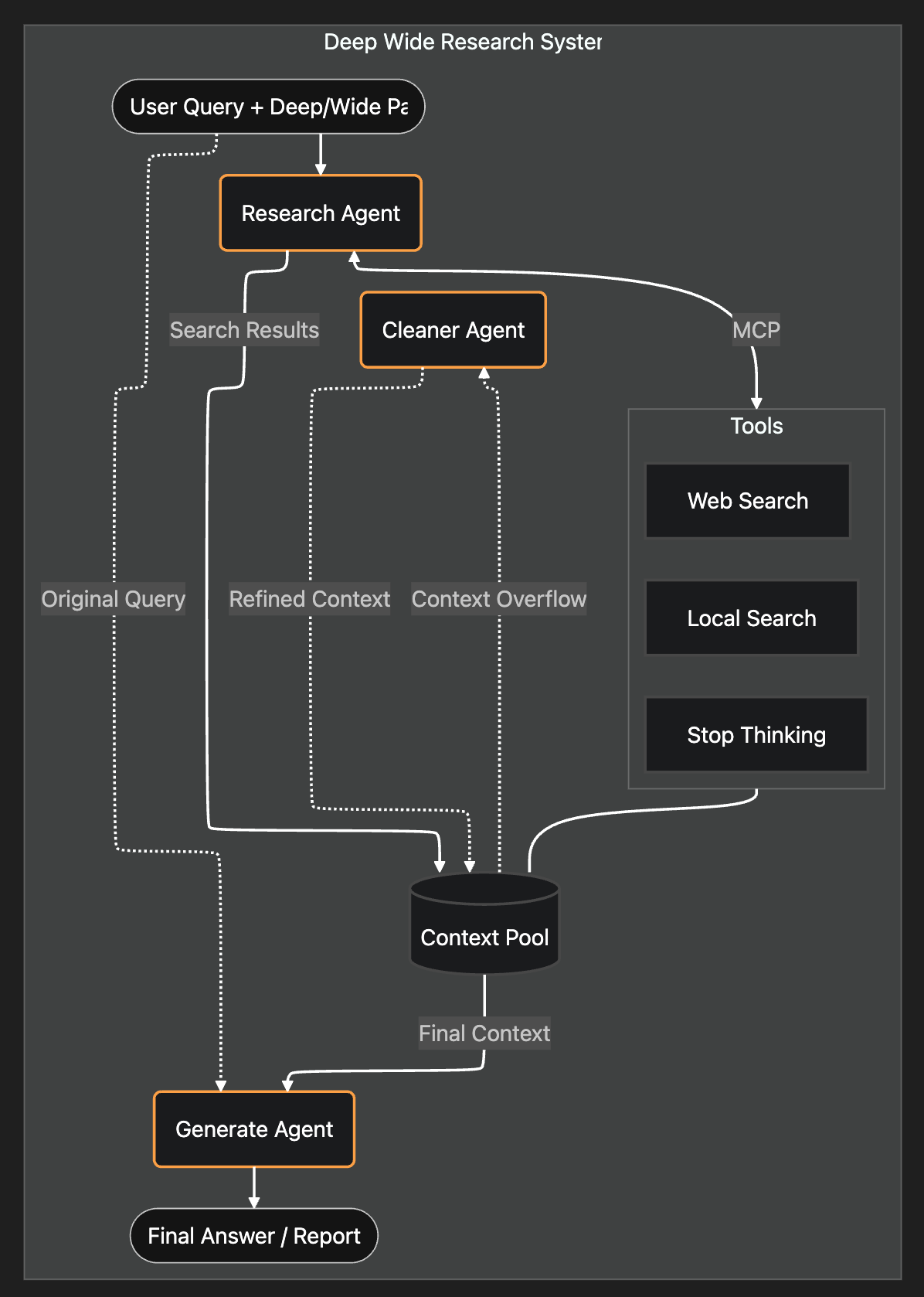
1. Wie baut man den Recherche-Agenten?
Agentic RAG ersetzt die gesamte Retrieval-Pipeline durch einen einzigen, autonomen Recherche-Agenten.
Anstatt Rewrites oder Routing-Regeln fest zu codieren, habe ich zwei Agenten eingerichtet: einen Researcher und einen Generator.
Ich habe dem Researcher drei einfache Werkzeuge gegeben:

<Stop_thinking><Web_search><Local_search>
Aber einem Agenten nur Werkzeuge zu geben, reicht nicht aus. Man muss ihm sagen, wann er aufhören soll.
Anstelle einer simplen while-Schleife oder einer festen Schrittzahl zwang ich den Agenten, vor jeder Aktion einen Selbstreflexionsschritt durchzuführen.
Wir verwenden keine einfache Schleife oder eine feste Anzahl von Iterationen. Stattdessen zwingen wir den Agenten, vor jedem Schritt eine Selbstreflexion durchzuführen, indem wir einen „Artikel-Bereitschafts-Check“ verwenden:
## Artikel-Bereitschafts-Check:
- Könnte ich JETZT SOFORT eine umfassende, detaillierte Antwort und einen Artikel schreiben? (Ja/Nein)
- Wenn ich ihn jetzt schreiben würde, welche Abschnitte wären schwach, vage oder würden keine konkreten Beispiele/Daten enthalten?
- Habe ich genug spezifische Fakten, Zahlen und Beispiele, um jede Behauptung zu untermauern?
Nur wenn dieser Check erfolgreich ist, ruft der Agent <Stop_thinking> auf. Wir haben dies mit SOTA-Modellen (Gemini 3 Pro / Claude 4.5 Opus / GPT-5) getestet, und sie folgten der Logik perfekt.
Alle Rechercheergebnisse werden in einem gemeinsamen Kontext-Pool gespeichert. Sobald der Researcher „Stop“ signalisiert, greift ein Generator-Agent auf den Kontext-Pool zu und schreibt die endgültige Antwort.
Die Ergebnisse übertreffen jede Pipeline, die wir je gebaut haben. Hier siegt Intelligenz über starre Strukturen.
Im Wesentlichen haben wir die Komponenten des traditionellen RAG auf dynamische Verhaltensweisen von Agenten abgebildet:
- Query-Routing? -> Der Agent wählt das richtige Werkzeug.
- Query-Rewriting? -> Der Agent füllt die Funktionsargumente aus.
- Multi-Hop-QA? -> Der Agent entscheidet, wann er
<Stop_thinking>aufruft. - Reranking -> Der Agent generiert die Antwort basierend auf dem Kontext-Pool.
2. Umgang mit Kontext-Überlauf
Ich stieß auf das zweite Problem: Was passiert, wenn der durchsuchte Kontext zu lang wird?
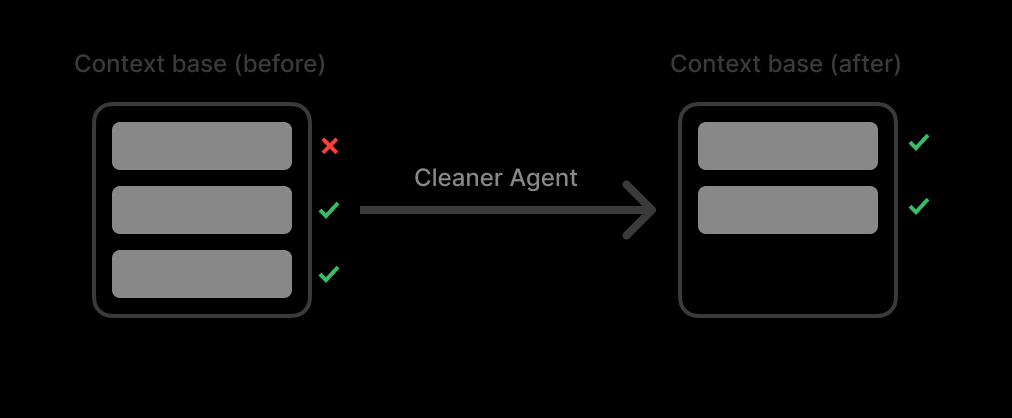
Ich habe einen Kontext-Pool erstellt. Dieser Pool fungiert als Liste aller Suchergebnisse. Ich habe einen Cleaner-Agenten entwickelt, der den Kontext bereinigt, wenn der Kontext-Pool den Schwellenwert erreicht (90 % der maximalen Token).
Der Trick ist: Nicht zusammenfassen. Zusammenfassungen vernichten Details.
Stattdessen arbeitet der Cleaner-Agent wie ein Müllfilter. Er löscht ganze irrelevante Quellen, während die relevanten zu 100 % original und intakt bleiben.
Schließlich erstellt ein Generator-Agent die endgültige Antwort auf der Grundlage des bereinigten Inhalts im Kontext-Pool und der ursprünglichen Anfrage.
3. Die „Deep-Wide“-Lösung für Kosten und Latenz
Bald stand ich vor einer dritten Herausforderung: der Kosten- und Latenzbarriere.
Lassen Sie mich ehrlich sein, was die Zahlen angeht:
- Latenz: Agentic RAG hat eine Untergrenze von ca. 10 Sekunden – die Reasoning-Schleife ist der Engpass, und wir können diesen Wert nicht unterschreiten. Herkömmliches RAG kann in unter 3s antworten.
- Kosten: Mit GPT-5 können Sie mit ~0,05–1 $ pro Anfrage rechnen. Herkömmliches RAG mit Embeddings kostet ~0,005–0,01 $.
Um diesen Kompromiss oberhalb dieser Untergrenze steuerbar zu machen, habe ich „Deep-Wide Research“ eingeführt:
- Deep (Tiefe): Steuert die iterativen Reasoning-Schritte. Die Spanne reicht von ~10s (Minimum) bis zu 5+ Minuten (maximale Tiefe für umfassende Berichte).
- Wide (Breite): Steuert die parallele Query-Erweiterung. Mehr Breite = mehr untersuchte Quellen = höhere Token-Kosten.
TIEFE × BREITE ≈ Kosten. Durch die Anpassung dieser beiden Dimensionen können Sie die Antwortzeit (10s ~ 5min), die Qualität und die Kosten steuern – aber Sie können die 10-Sekunden-Untergrenze nicht unterschreiten.
Wir haben DEEP WIDE RESEARCH als Open Source veröffentlicht. Projekt-URL: https://github.com/puppyone/DeepWideResearch (Apache-Lizenz)
Was dies nicht löst
Dieses Projekt löst die Hälfte des Agentic-RAG-Problems: die Seite „Reasoning & Search“.
Die andere Hälfte, der Umgang mit privaten Unternehmensdaten, bleibt hier ungelöst:
- Bereinigung unstrukturierter Unternehmensdokumente
- Erstellung von Indizes, die für die Nutzung durch Agenten optimiert sind
- Granulare Berechtigungssteuerung
Daran arbeiten wir separat. Wenn Sie auf diese Probleme stoßen oder Ideen haben, würde ich mich freuen, von Ihnen zu hören: [email protected]