Ultimativer Leitfaden zu Hybrid-Indexierung für Context Learning
7. Februar 2026Ollie @puppyone
Wichtigste Erkenntnisse
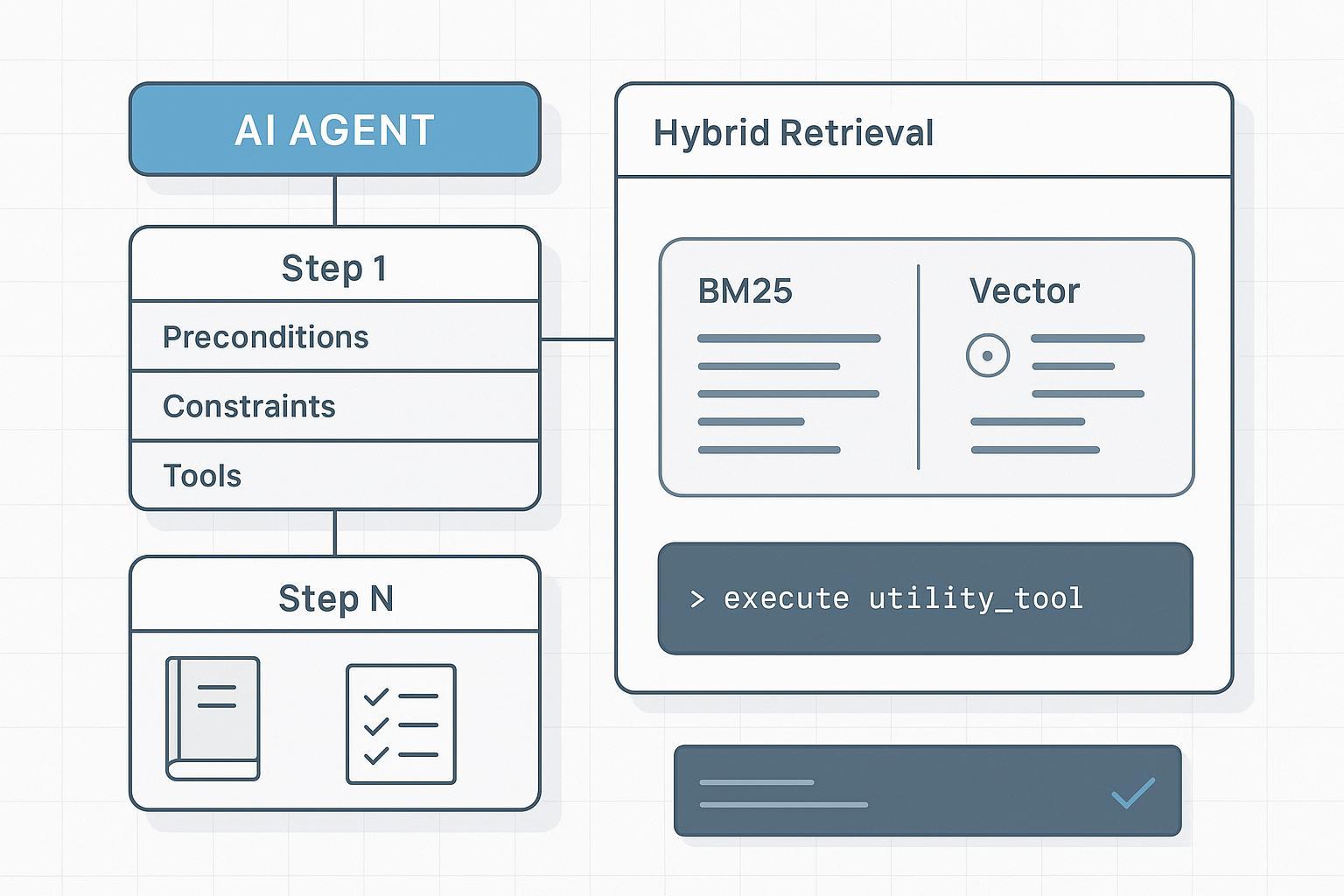
- Hybrides, feldbewusstes Retrieval schlägt „einfach Kontext verlängern“. Sie brauchen deterministische Slices pro Schritt, keine Textwand.
- Modellgrenzen sind real: Benchmarks zeigen hohe Raten ignorierten/falsch genutzten Kontexts; gestalten Sie Ihren Stack so, dass solche Fehler verhindert, erkannt und korrigiert werden.
- Für Operations/Support: Kombinieren Sie ein Know-How-JSON/Graph mit Hybrid-Indexierung und einer agentischen Planner→Executor→Verifier-Schleife für Schritt-Treue und Auditability.
Warum Modelle Kontext bei SOPs ignorieren und falsch nutzen
Ein neuer Benchmark (CL-bench: 500 Kontexte, 1.899 Aufgaben, 31.607 Bewertungsrubriken) zeigt, wie fragil heutige Modelle beim Lernen aus vorgegebenem Kontext sind: zehn Frontier-Modelle lösten im Schnitt nur etwa 17,2 % der Aufgaben; das beste erreichte grob 23,7 % selbst im Reasoning-Modus. Dominierender Fehler: den gegebenen Kontext nicht korrekt nutzen—Schlüsseldetails übersehen oder falsche Regel anwenden. Siehe CL-bench paper (arXiv) und Tencent Hunyuan research blog. Langer Kontext allein behebt das nicht; LongBench v2 u. a. zeigen, dass bessere Fensterbehandlung Lücken in Reasoning und Aggregation über Multi-Dokument-Inputs lässt (LongBench v2 ACL). Bei mehrstufigen SOPs äußert sich das als Schritt-Überspringen, Instruction Drift oder unsichere Aktionen.
Typische Fehlermoden naiven RAG bei SOP-Ausführung
RAG-Stacks scheitern oft an Operations-Workflows, weil die Retrieval-Einheit nicht zur Aktions-Einheit passt: zu breite Chunks → Retrieval-Drift; ungewichtete Felder vergraben kritische Tokens (Schritt-IDs, Bedingungen, Warnungen). Monolithische Prompts fördern Improvisation. Abhilfe: deterministisches Retrieval und verifizierbare Ausführung designen.
Grundlagen: SOPs als Know-How-JSON/Graph modellieren
Agenten brauchen strukturiertes, gefeldetes Wissen. Ein praktisches Schema kodiert Schritte, Abhängigkeiten, Constraints und Verifikationsmethoden. Beispiel (kompakt):
{
"id": "sop.router.reset.v3",
"title": "Router Safe Reset",
"version": "3.2",
"steps": [
{
"step_number": 7,
"description": "Apply staged configuration from backup",
"preconditions": ["Backup verified within 24h", "Device in maintenance mode"],
"constraints": ["Do not overwrite ACL table A unless delta<5 rules", "Max outage 90s"],
"tools_allowed": [
{
"name": "net.push_config",
"params_schema": {"backup_id": "string", "dry_run": "boolean"}
}
],
"checkpoints": [
{"name": "acl_delta_check", "type": "query", "expected": "<5"},
{"name": "latency_budget", "type": "timer", "expected": "<=90s"}
],
"verification_method": "Compare running-config hash to backup; confirm ACL delta and outage time"
}
],
"dependencies": [{"from": 6, "to": 7, "condition": "backup_verified==true"}],
"owners": ["netops"],
"permissions": {"roles": ["netops", "sre"], "min_clearance": "internal"}
}
So kann ein Retriever Titel, step_number, preconditions und constraints stärker gewichten als Fließtext. Kontext-Base-Überblick: puppyone About.
Hybrid-Indexierung für Context Learning in langen, dichten Handbüchern
Kern ist nicht „längerer Kontext“, sondern „bessere Retrieval-Einheiten, bessere Ranking-Signale“. In der Praxis: Hybrid-Indexierung mit Feldbewusstsein und optionalem Rerank.
- Sparse lexikalische Signale (BM25/BM25F) mit Dense-Vektoren kombinieren. Lexikalisch: exakte IDs, Warnungen, Constraints; Dense: besseres Recall bei semantisch formulierten Schritten. Einführungen: Elastic — What is hybrid search, Elastic retrievers and RRF, Weaviate — Hybrid search explained.
- Feldbewusste Boosts: Titel, step_number, preconditions, constraints, tools_allowed vor Narrativ.
- Pro Schritt minimale, deterministische Slices abrufen; nicht jedes Mal die ganze SOP füttern.
- Optional: Top-k mit Cross-Encoder oder strukturbewusstem Reranker nach Constraints/Checkpoints priorisieren.
Agentic RAG für SOPs: Planner → Retriever → Executor → Verifier
Der Planner zerlegt die Aufgabe in schrittweise Intents und formuliert zielgerichtete Retrieval-Queries (z. B. step_number, benötigte Tools). Der Retriever liefert minimale, gefeldete Slices (preconditions, constraints, Parameter, checkpoints) mit IDs. Der Executor ruft nur enumerierte Tools mit schema-validierten Parametern auf und zitiert Slice-IDs. Der Verifier prüft Checkpoints und Constraints vor dem Weiterschalten; bei Abweichung Re-Plan oder Human Review. Siehe Anthropic — Multi-agent research system.
Praxisbeispiel: Ein Schritt End-to-End
Hinweis: puppyone ist unser Produkt; hier neutral als eine mögliche Context Base erwähnt. Mehr auf puppyone.
Ziel: Schritt 7 von „Router Safe Reset“ mit Hybrid-Retrieval und Agentic-Loop ausführen. Query-Plan: intent apply staged configuration; constraints_required; fields step_number=7, preconditions, constraints, tools_allowed, checkpoints, verification_method. Pseudocode (Python-Stil) wie im englischen Artikel: hybrid_search mit field_boosts, rerank_and_select_minimal, Assert vor Ausführung, tool_call mit Schema, Verifier prüft ACL-Delta und Outage, bei Erfolg mark_step_complete sonst escalate_or_replan. State-Log-Beispiel: used_slice, preconditions_ok, constraints_ok, executor, verifier. Dieselbe Schleife ist mit Elastic/OpenSearch/Vespa/Weaviate oder RDBMS+pgvector+BM25 umsetzbar.
Evaluations-Playbook: Zuverlässigkeit nachweisen, dann skalieren
Retrieval-Qualität: Recall@k, MRR/nDCG pro Schritt, Context Precision, Context Sufficiency. Ausführung: Step Adherence %, Action Success Rate, Instruction Drift Rate, Incidents pro 1.000 Ausführungen, Time-to-Resolution. Pro SOP-Schritt Ground-Truth-Slice-IDs und erwartete Tool/Result-Muster speichern; assert, dass der Executor die genutzte Slice zitiert und Checkpoints vor Fortschritt bestehen. Übersicht: RAG evaluation survey (2024).
Alternativen und Parität
| Stack | Hybrid-Fusion | Feldbewusste Boosts | On-Prem/VPC | Notizen |
|---|---|---|---|---|
| Elasticsearch | RRF, gewichtetes Blending | BM25F, Multi-Field | Ausgereift self-host | Retriever-APIs, Cross-Encoder-Reranker |
| OpenSearch | Weighted + Rerank | Field Boosts via Analyzer | Self-Host first-class | Vektor-Perf |
| Vespa | Lexical + ANN + Rerank | Per-Field-Features | Self-Host, Scale-out | Ranking/ML-Pipeline |
| Weaviate | RRF/weighted hybrid | Property Weights/Filters | Managed + self-host | Klare Hybrid-Docs |
Für den „Agent Context Base“-Ansatz (Prozeduren als strukturiertes, versioniertes Know-How, deterministische Slices): z. B. puppyone. Kriterien: feldbewusstes Scoring, deterministische Slicing-Garantien, Audit-Logs, Evaluations-Harness.
Wie „gut“ in der Praxis aussieht
Piloten zeigen: Wechsel von Ganzdokument-Prompts zu pro-Schritt-gefeldeten Slices reduziert Instruction Drift und erhöht Step Adherence. Hybrid-Indexierung für Context Learning bringt die exakte Constraint-Oberfläche in die Hand des Agenten und verlangt Verifikation vor dem Weiterschalten.
Nächste Schritte
Wenn Sie einen produktionsreifen Ansatz für SOP-Automatisierung evaluieren—strukturiertes Know-How, Hybrid-Indexierung, Agentic Planner→Executor→Verifier—lassen Sie uns gemeinsam Korpus und Constraints prüfen. Buchen Sie eine technische Demo zu Hybrid-Indexierung + Agentic RAG für Ihre Umgebung.