Context Engineering: When RAG Isn’t Enough
February 10, 2026Ollie @puppyone
Key takeaways
- Basic RAG is enough when your corpus is small, questions are local, and governance is light; anything beyond that calls for a dedicated context layer.
- A context layer reshapes knowledge into structured Know‑How (JSON/graph), pairs it with hybrid indexing (dense + sparse + graph), and governs it with provenance, ACLs, and versioning.
- Graph‑ and tree‑enhanced retrieval close gaps where vector‑only RAG struggles on cross‑document and global queries, as shown in the Microsoft Research work on GraphRAG (2024).
- Sub‑agent orchestration and strict summarization budgets keep context high‑signal and testable, aligning with guidance in Anthropic’s engineering notes on effective context.
- Governance isn’t optional; NIST’s AI RMF places provenance and lifecycle controls at the center of trustworthy systems.
The contrarian decision rubric: when RAG is enough vs. when you need a context layer
Start simple and resist premature infrastructure. You likely don’t need a context layer if:
- Your corpus is small, mostly static, and lives in one or two systems.
- Questions are local and single‑hop (e.g., “What’s the warranty on Product X?”).
- Latency SLOs are flexible and you can tolerate occasional misses.
- Governance is light; you don’t need auditable traces or rigorous ACLs.
You do need a dedicated context layer when one or more of these become true:
- Your data lives across Docs, Slack, Notion, databases, and external SaaS, and it changes frequently. Even search companies are investing in connectors; see the Perplexity acquisition of Carbon described in the company’s own note on connecting work files in 2024: Perplexity welcoming Carbon to connect to your work files.
- Your agents must answer global or cross‑document questions and plan multi‑step workflows. Vector‑only retrieval buckles here; the Microsoft team outlines graph‑enhanced strategies in the 2024 arXiv paper: A Graph RAG approach to query‑focused summarization.
- You need provenance, access control, versioning, and rollback. This aligns with the GOVERN function in NIST’s AI Risk Management Framework.
- Determinism and testability matter: you want repeatable context assembly, explainable retrieval traces, and CI for context updates. Anthropic’s guidance on compartmentalized sub‑agents and strict context hygiene supports this direction; see the engineering article Effective context engineering for AI agents.
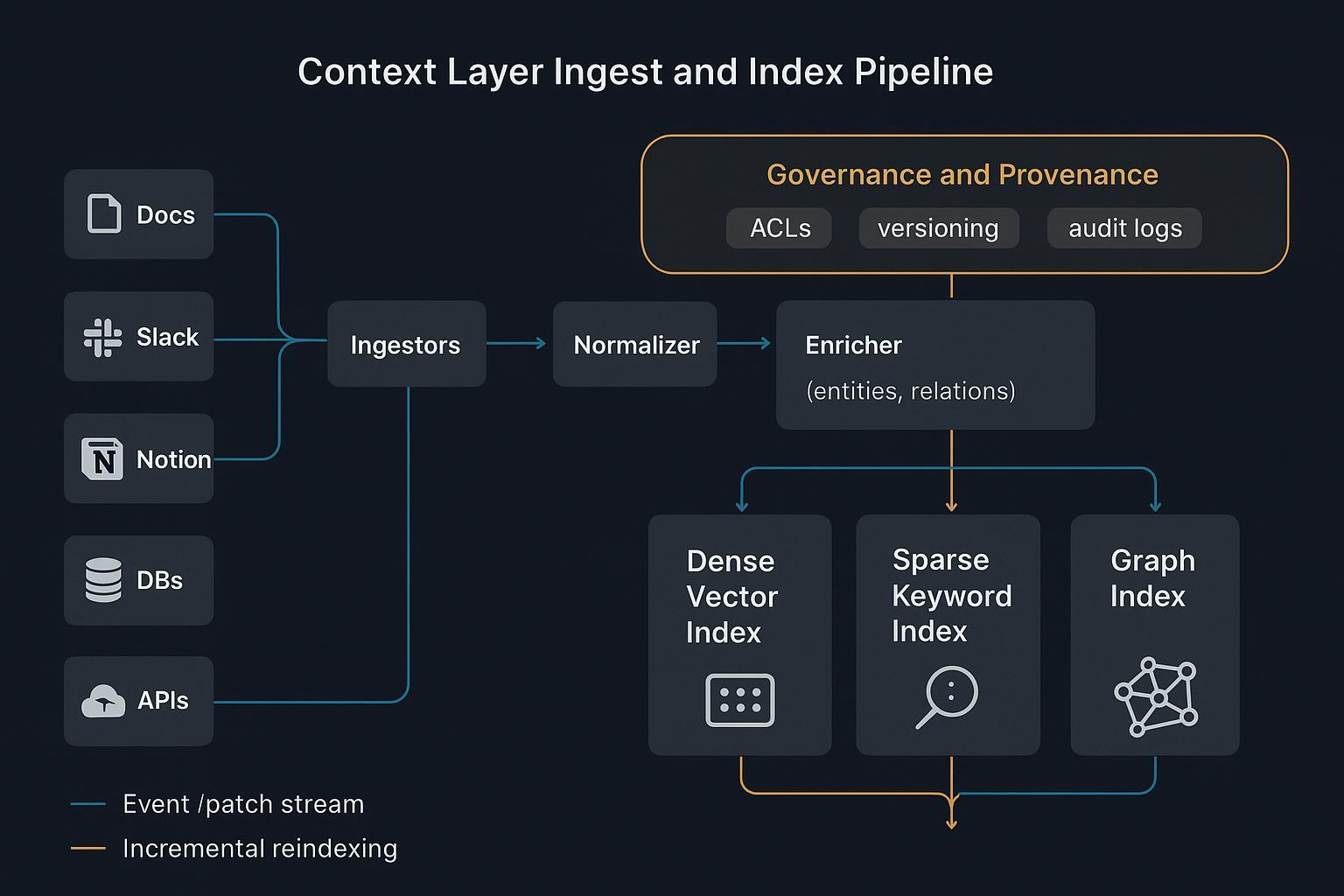
Context engineering architecture beyond RAG
Structured Know‑How and schemas
Unstructured HTML is noise for machines. A context layer turns procedures, entities, constraints, and business rules into structured Know‑How: JSON documents and graphs with clear schemas:
{
"entity": "PurchaseOrder",
"id": "PO-2026-1783",
"vendor": {"name": "Acme", "id": "V-882"},
"line_items": [
{"sku": "X12", "qty": 5, "unit_price": 49.00}
],
"approval_policy": {
"threshold": 10000,
"requires_dual_signoff": true,
"exceptions": ["emergency"]
},
"provenance": {"source": "ERP", "version": "v14.2", "ingested_at": "2026-02-06"}
}
This schemaed context gives agents machine‑readable logic and provenance for auditability, instead of relying on brittle text spans.
Hybrid indexing and routing
- Dense semantic search finds topical similarity quickly.
- Sparse lexical indexes preserve exact terms, IDs, and policy language.
- Graph/tree structures encode relationships and hierarchy for multi‑hop reasoning.
Together, they enable deterministic retrieval: route by cluster or graph neighborhood, then stitch a minimal, relevant context. Operational patterns for hybrid and sharding are discussed in vendor guidance like the Weaviate best practices for hybrid search and operations.
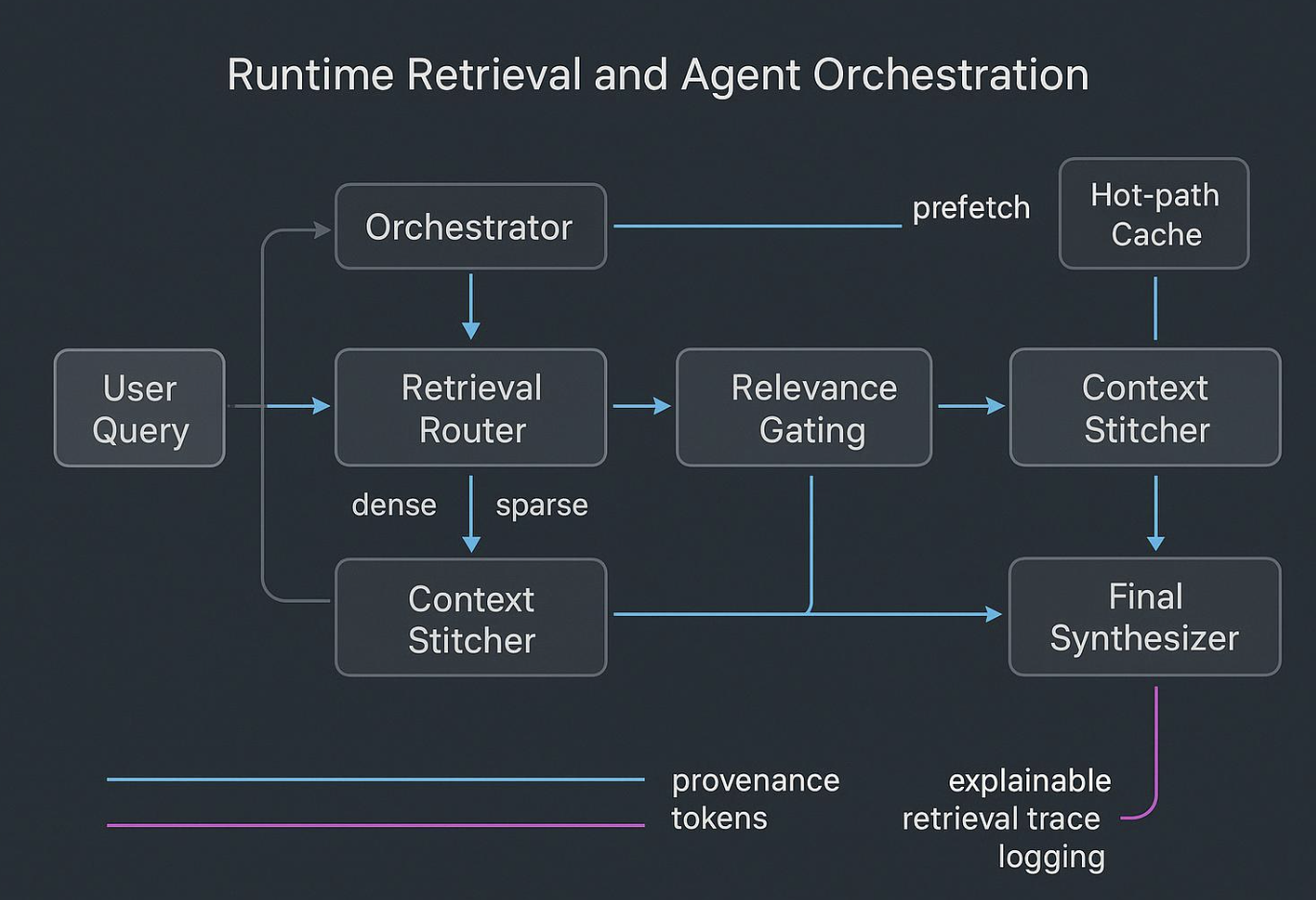
Runtime stitching and orchestration
Agents fail when they try to “think” over raw, noisy dumps. Runtime should look like this:
- A planner hypothesizes what evidence and tools are needed.
- A router fans queries across dense, sparse, and graph indices.
- A gate filters for provenance and policy; a stitcher composes a compact, well‑scoped bundle.
- Sub‑agents perform narrow tasks and return strict summaries to a synthesizer.
# Pseudocode for hybrid retrieval + stitching
plan = planner.make_plan(user_query)
results = []
for hop in plan.hops:
dense = dense_index.search(hop.query, k=10)
sparse = sparse_index.search(hop.query, k=10, filter=plan.filters)
graph_ctx = graph.walk(hop.entities, depth=2)
gated = gate.by_provenance(dense + sparse + graph_ctx)
stitched = stitch.compact(gated, budget_tokens=1200)
results.append(stitched)
final = synthesize(results, tools=plan.tools)
return final
Context pipeline checklist
- Ingest sources → normalize → map to schema.
- Enrich with entities and relations → store as structured Know‑How.
- Build hybrid indexes (dense, sparse, graph) with provenance metadata.
- Gate with ACLs, versioning, and audit logs.
- Evaluate retrieval fidelity and task‑level outcomes before deploy.
- Deploy with hot‑path caches and prefetch.
- Monitor latency, precision/recall, drift, and audit traces.
A lightweight micro‑benchmark: latency vs. answer quality
This design helps you compare three retrieval patterns. Keep it small and reproducible.
Assumptions: 50K documents across policies, tickets, and product specs; 75 evaluation queries with ground truth for 40 of them; same LLM across runs; hardware parity; reranker enabled where applicable. Report median latency p50/p90 and answer quality using EM/F1 or a documented LLM‑judge with disclosures.
| Pattern | Retrieval stack | Expected characteristics |
|---|---|---|
| Naive RAG | Dense only | Fast, lower global coherence; struggles on cross‑doc questions |
| Tuned RAG | Dense + sparse + reranker | Moderate latency, better precision on IDs and policy terms |
| Context layer | Hybrid + graph + stitching + summaries | Slightly higher latency p50 but tighter p90; more stable global answers |
Interpretation: expect tuned RAG to fix many easy misses; the context layer should shine on cross‑document and multi‑step tasks with more predictable tail latency due to routing and caches. Don’t extrapolate beyond your corpus and SLOs.
Failure modes and how to mitigate them
- Fragmentation across documents: build entity/relationship graphs and use local/global traversals to gather coherent bundles; add hierarchical anchors to long narratives.
- Staleness and drift: adopt event‑sourced ingestion, incremental re‑indexing, and TTLs; replay changelogs on schema upgrades.
- Latency spikes under load: use tiered hot‑path caches, cluster routing, and prefetch for common sub‑queries; right‑size shards and enable quantization where available.
- Hallucination from noisy context: enforce schemas and provenance filters; narrow sub‑agent scopes; prefer compact summaries over raw dumps.
- Governance gaps: log retrieval traces and tool calls; require explainable evidence lines; gate deployments with evaluation thresholds and rollback plans.
Practical micro‑example: structured Know‑How and hybrid indexing in action
Suppose you’re building a purchasing agent that must apply approval policies while assembling vendor quotes. You ingest ERP exports, contract PDFs, Slack approvals, and email summaries. The ingestion pipeline maps them to a common schema: PurchaseOrder, Vendor, Policy, Exception. You enrich with entity linking so each PurchaseOrder knows its Vendor and applicable Policy nodes. You then build a dense index for semantic recall, a sparse index to catch IDs and legal terms, and a graph index to navigate Policy → Exception → Approver paths.
In this setup, an orchestration loop routes a “Can we approve PO‑2026‑1783 today?” query by: sparse lookup of the PO ID, graph walk from that PO to its Policy and any Exceptions, and dense retrieval for the latest approver notes. The stitcher compacts these into a 1.2K‑token bundle and the agent produces a short, cited answer with an approval decision and links to provenance.
A platform like puppyone can help here because it stores knowledge as structured Know‑How (JSON/graph) and supports hybrid indexing across text and structure. That combination enables deterministic retrieval patterns and auditable traces without depending on brittle text scraping. Use it as one of several viable ways to operationalize the pattern above.
Governance and CI for context
Treat context like code. Every context change should have provenance, review, and tests. Maintain versioned schemas, access policies, and evaluation suites. Before rollouts, run retrieval fidelity checks and task‑level tests; capture explainable traces and keep rollback ready. If your agents touch regulated or sensitive data, align your processes with frameworks like the GOVERN function described in NIST’s AI Risk Management Framework. For interop and tooling, consider standardizing interfaces via the Model Context Protocol, which is being advanced in the open with community governance.
Next steps
Start with tuned RAG if your problem is local and low‑risk. If you see cross‑doc questions, governance needs, or volatile corpora, plan a context layer pilot focused on one workflow. Build structured Know‑How first; hybrid indexing and orchestration become far simpler once your schemas are stable. Keep evaluation tight and humane: test real tasks, log traces, and tie improvements to business SLOs.
If you’re exploring structured context and hybrid indexing, pilot a single workflow and write down the SLOs before you scale.
FAQs
Q1: Do I need a graph right away?
A: No. Start with dense + sparse; add a graph when you hit cross‑document reasoning or global summarization gaps.
Q2: How big should my chunks be?
A: Chunk by semantic units tied to your schema (entities, procedures), not fixed token counts. Let rerankers and summaries do the rest.
Q3: Can I skip governance until later?
A: You can, but you’ll pay for it. Add light provenance and access controls from day one so evaluation and rollbacks are possible.