Ingeniería de contexto: cuando RAG no basta
10 de febrero de 2026Ollie @puppyone
Conclusiones clave
- El RAG básico basta cuando tu corpus es pequeño, las preguntas son locales y la gobernanza es ligera; más allá de eso, hace falta una capa de contexto dedicada.
- Una capa de contexto transforma el conocimiento en Know‑How estructurado (JSON/grafo), lo combina con indexación híbrida (dense + sparse + graph) y lo gobierna con proveniencia, ACLs y versionado.
- La recuperación mejorada con grafos y árboles cierra las brechas donde el RAG solo vectorial falla en consultas cruzadas y globales; véase el trabajo de Microsoft Research sobre GraphRAG (2024).
- La orquestración de subagentes y presupuestos estrictos de resumen mantienen el contexto con alta señal y testeable, alineado con las guías de Anthropic sobre context engineering efectivo.
- La gobernanza no es opcional; el AI RMF de NIST sitúa la proveniencia y los controles de ciclo de vida en el centro de sistemas confiables.
La rúbrica contraria: cuándo basta RAG vs. cuándo necesitas una capa de contexto
Empieza simple y resiste la infraestructura prematura. Probablemente no necesites una capa de contexto si:
- Tu corpus es pequeño, mayormente estático y vive en uno o dos sistemas.
- Las preguntas son locales y de un solo salto (p. ej. «¿Cuál es la garantía del producto X?»).
- Los SLO de latencia son flexibles y toleras fallos ocasionales.
- La gobernanza es ligera; no necesitas trazas audivables ni ACLs rigurosas.
Sí necesitas una capa de contexto dedicada cuando:
- Tus datos viven en Docs, Slack, Notion, bases de datos y SaaS externos y cambian con frecuencia. Las empresas de búsqueda también invierten en conectores; véase la adquisición de Carbon por Perplexity en 2024: Perplexity welcoming Carbon.
- Tus agentes deben responder preguntas globales o cruzadas y planificar flujos multietapa. El recuperación solo vectorial falla aquí; el equipo de Microsoft describe estrategias con grafos en arXiv 2024: A Graph RAG approach to query‑focused summarization.
- Necesitas proveniencia, control de acceso, versionado y rollback. Esto se alinea con GOVERN del NIST AI Risk Management Framework.
- Importan el determinismo y la testabilidad: quieres ensamblado de contexto repetible, trazas de recuperación explicables y CI para actualizaciones de contexto. La guía de Anthropic sobre subagentes y higiene de contexto lo respalda; véase Effective context engineering for AI agents.
Arquitectura de context engineering más allá del RAG
Know‑How estructurado y esquemas
HTML no estructurado es ruido para las máquinas. Una capa de contexto convierte procedimientos, entidades, restricciones y reglas de negocio en Know‑How estructurado: documentos JSON y grafos con esquemas claros:
{
"entity": "PurchaseOrder",
"id": "PO-2026-1783",
"vendor": {"name": "Acme", "id": "V-882"},
"line_items": [
{"sku": "X12", "qty": 5, "unit_price": 49.00}
],
"approval_policy": {
"threshold": 10000,
"requires_dual_signoff": true,
"exceptions": ["emergency"]
},
"provenance": {"source": "ERP", "version": "v14.2", "ingested_at": "2026-02-06"}
}
Este contexto esquematizado da a los agentes lógica legible por máquina y proveniencia para auditoría, en lugar de depender de fragmentos de texto frágiles.
Indexación híbrida y enrutamiento
- La búsqueda semántica densa encuentra similitud temática rápido.
- Los índices léxicos dispersos preservan términos exactos, IDs y lenguaje de políticas.
- Las estructuras grafo/árbol codifican relaciones y jerarquía para razonamiento multietapa.
Juntos permiten recuperación determinista: enrutar por cluster o vecindad de grafo, luego compilar un contexto mínimo y relevante. Patrones operativos en Weaviate best practices for hybrid search.
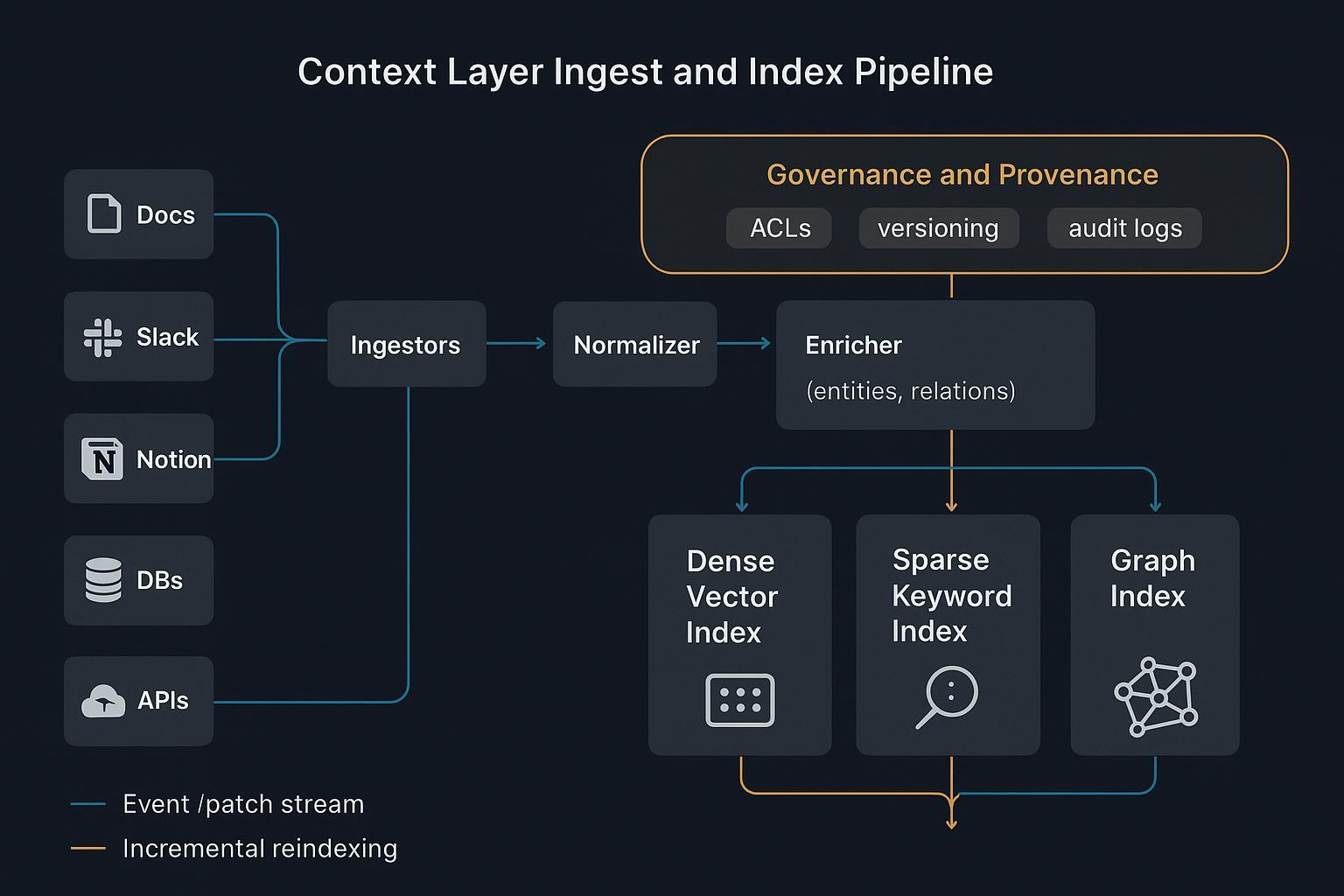
Cosido y orquestración en tiempo de ejecución
Los agentes fallan cuando intentan «pensar» sobre volcados crudos y ruidosos. El runtime debe verse así:
- Un planner hipotetiza qué evidencia y herramientas hacen falta.
- Un router distribuye consultas entre índices dense, sparse y graph.
- Un gate filtra por proveniencia y política; un stitcher compone un bundle compacto y bien acotado.
- Subagentes realizan tareas estrechas y devuelven resúmenes estrictos a un sintetizador.
# Pseudocódigo para recuperación híbrida + cosido
plan = planner.make_plan(user_query)
results = []
for hop in plan.hops:
dense = dense_index.search(hop.query, k=10)
sparse = sparse_index.search(hop.query, k=10, filter=plan.filters)
graph_ctx = graph.walk(hop.entities, depth=2)
gated = gate.by_provenance(dense + sparse + graph_ctx)
stitched = stitch.compact(gated, budget_tokens=1200)
results.append(stitched)
final = synthesize(results, tools=plan.tools)
return final
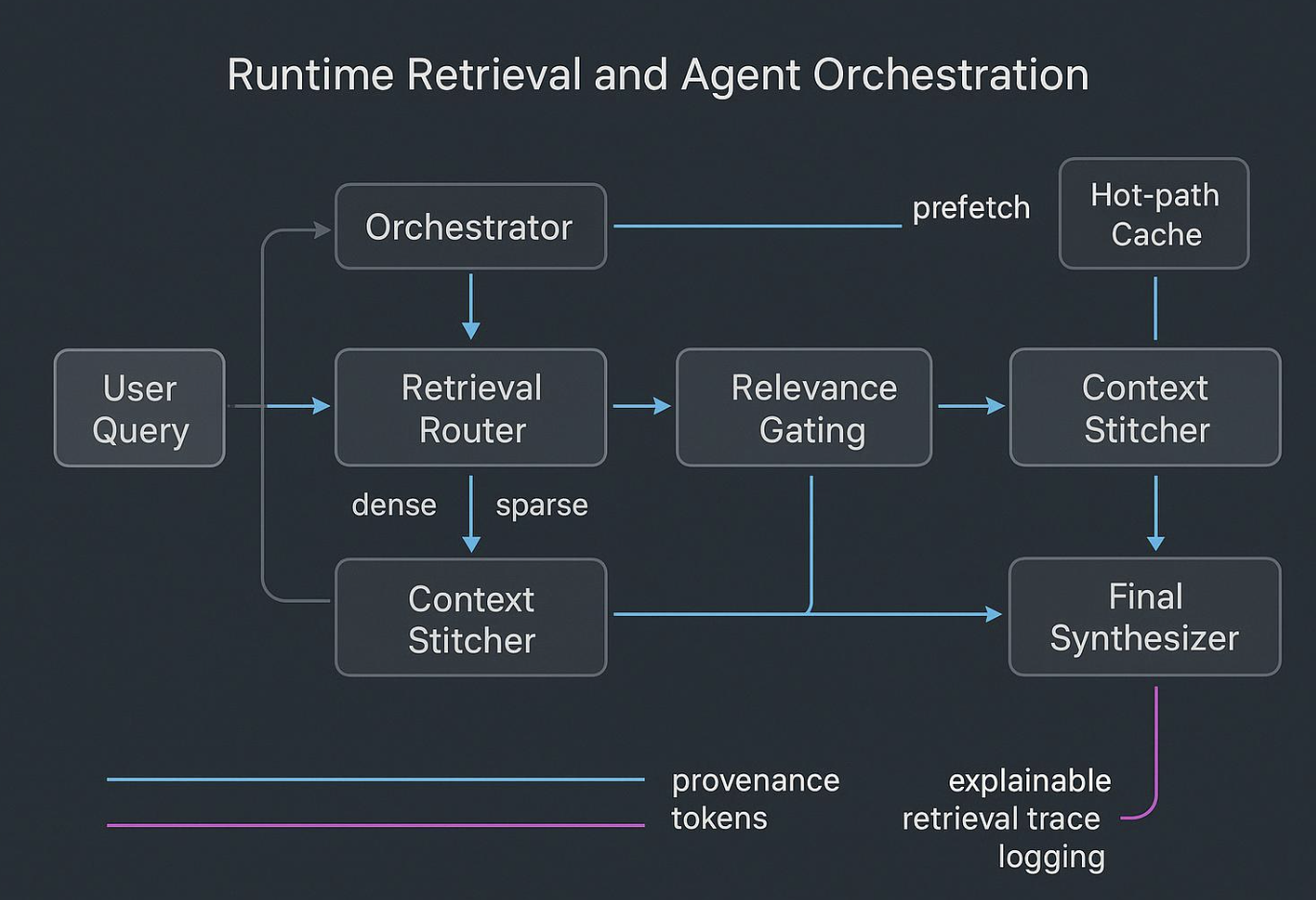
Checklist de pipeline de contexto
- Ingerir fuentes → normalizar → mapear a esquema.
- Enriquecer con entidades y relaciones → almacenar como Know‑How estructurado.
- Construir índices híbridos (dense, sparse, graph) con metadatos de proveniencia.
- Aplicar gates con ACLs, versionado y logs de auditoría.
- Evaluar fidelidad de recuperación y resultados a nivel de tarea antes del deploy.
- Desplegar con cachés de hot-path y prefetch.
- Monitorizar latencia, precisión/recall, drift y trazas de auditoría.
Microbenchmark ligero: latencia vs. calidad de respuesta
Este diseño permite comparar tres patrones de recuperación. Mantenerlo pequeño y reproducible.
Supuestos: 50K documentos (políticas, tickets, especificaciones); 75 consultas de evaluación con ground truth en 40; mismo LLM; paridad de hardware; reranker cuando aplique. Reportar latencia mediana p50/p90 y calidad mediante EM/F1 o un LLM-juez documentado.
| Patrón | Stack de recuperación | Características esperadas |
|---|---|---|
| RAG naivo | Solo dense | Rápido, menor coherencia global; dificultades en preguntas cross-doc |
| RAG afinado | Dense + sparse + reranker | Latencia moderada, mejor precisión en IDs y términos de política |
| Capa de contexto | Hybrid + graph + stitching + summaries | Latencia p50 algo mayor pero p90 más estable; respuestas globales más predecibles |
Interpretación: el RAG afinado corrige muchos fallos fáciles; la capa de contexto destaca en tareas cross-document y multietapa con latencia de cola más predecible por enrutamiento y cachés.
Modos de fallo y mitigación
- Fragmentación entre documentos: construir grafos de entidad/relación y recorridos locales/globales; añadir anclas jerárquicas en narrativas largas.
- Obsolescencia y drift: ingesta event-sourced, reindexación incremental, TTLs; reproducir changelogs en upgrades de esquema.
- Picos de latencia: cachés de hot-path por niveles, enrutamiento por cluster, prefetch para subconsultas comunes; dimensionar shards y activar cuantización.
- Alucinación por contexto ruidoso: forzar esquemas y filtros de proveniencia; acotar ámbitos de subagentes; preferir resúmenes compactos sobre volcados crudos.
- Brechas de gobernanza: registrar trazas de recuperación y llamadas a tools; exigir líneas de evidencia explicables; condicionar deploys a umbrales de evaluación y planes de rollback.
Microejemplo práctico: Know‑How estructurado e indexación híbrida en acción
Supón que construyes un agente de compras que debe aplicar políticas de aprobación al reunir cotizaciones de proveedores. Ingeres exportaciones ERP, PDFs de contratos, aprobaciones en Slack y resúmenes por email. El pipeline mapea todo a un esquema común: PurchaseOrder, Vendor, Policy, Exception. Enriqueces con entity linking para que cada PurchaseOrder conozca su Vendor y nodos Policy aplicables. Luego construyes un índice denso para recall semántico, uno disperso para IDs y términos legales, y uno de grafo para rutas Policy → Exception → Approver.
En este setup, un bucle de orquestación enruta una consulta «¿Podemos aprobar PO‑2026‑1783 hoy?» mediante: búsqueda dispersa del ID de PO, recorrido de grafo desde esa PO a su Policy y excepciones, y recuperación densa de notas recientes de aprobadores. El stitcher compacta todo en un bundle de 1.2K tokens y el agente produce una respuesta corta citada con decisión de aprobación y enlaces a proveniencia.
Una plataforma como puppyone puede ayudar porque almacena conocimiento como Know‑How estructurado (JSON/grafo) y soporta indexación híbrida sobre texto y estructura, permitiendo patrones de recuperación deterministas y trazas audivables sin depender de scraping de texto frágil.
Gobernanza y CI para contexto
Trata el contexto como código. Cada cambio debe tener proveniencia, revisión y pruebas. Mantener esquemas versionados, políticas de acceso y suites de evaluación. Antes de rollouts, ejecutar verificaciones de fidelidad de recuperación y tests a nivel de tarea; capturar trazas explicables y tener rollback preparado. Si tus agentes manejan datos regulados o sensibles, alinea procesos con el NIST AI Risk Management Framework. Para interoperabilidad: Model Context Protocol.
Próximos pasos
Empieza con RAG afinado si tu problema es local y de bajo riesgo. Si aparecen preguntas cross-doc, necesidades de gobernanza o corpus volátiles, planifica un piloto de capa de contexto centrado en un workflow. Construye Know‑How estructurado primero; la indexación híbrida y orquestación se simplifican cuando los esquemas están estables. Mantén la evaluación estrecha y humana: probar tareas reales, registrar trazas y vincular mejoras a los SLO de negocio.
FAQs
Q1: ¿Necesito un grafo de inmediato?
R: No. Empieza con dense + sparse; añade grafo cuando surjan brechas de razonamiento cross-document o de resumen global.
Q2: ¿Qué tamaño deberían tener mis chunks?
R: Fragmenta por unidades semánticas ligadas a tu esquema (entidades, procedimientos), no por conteos fijos de tokens. Deja el resto a rerankers y resúmenes.
Q3: ¿Puedo dejar la gobernanza para más tarde?
R: Puedes, pero lo pagarás. Añade proveniencia ligera y controles de acceso desde el día uno para poder evaluar y hacer rollbacks.