Implementar Agentic RAG para la automatización del servicio al cliente
8 de abril de 2026Lin Ivan
El servicio al cliente es un entorno duro para los LLMs: preguntas ambiguas, documentación desactualizada, datos sensibles y fallos que los usuarios ven de inmediato.
Si quieres automatización de soporte que sobreviva tráfico real, no basta con un demo de RAG. Necesitas un sistema agentic que enrute solicitudes, recupere evidencia, use herramientas con seguridad y escale cuando no esté seguro.
Este artículo es un playbook de despliegue para equipos de producción.
Define qué significa "automatización" antes de desplegar
Muchos equipos saltan directamente al chatbot. Es mejor empezar definiendo qué workflows quieres automatizar y qué significa "hecho" en cada uno.
Elige un modo de despliegue
Puedes empezar con uno de estos modos:
- Agent-assist: el sistema redacta y reúne evidencia; una persona envía.
- Automatización parcial: se resuelven automáticamente intents acotados y de bajo riesgo.
- Automatización ampliada: la mayoría de intents se automatizan, pero solo después de ganar el derecho a hacerlo.
Crea una lista de "nunca automatizar"
Incluye al menos:
- acciones financieras por encima de un umbral
- cambios de propiedad de cuenta
- exportaciones de datos
- cualquier flujo regulado o de alto riesgo
Estos casos deben escalar de inmediato.
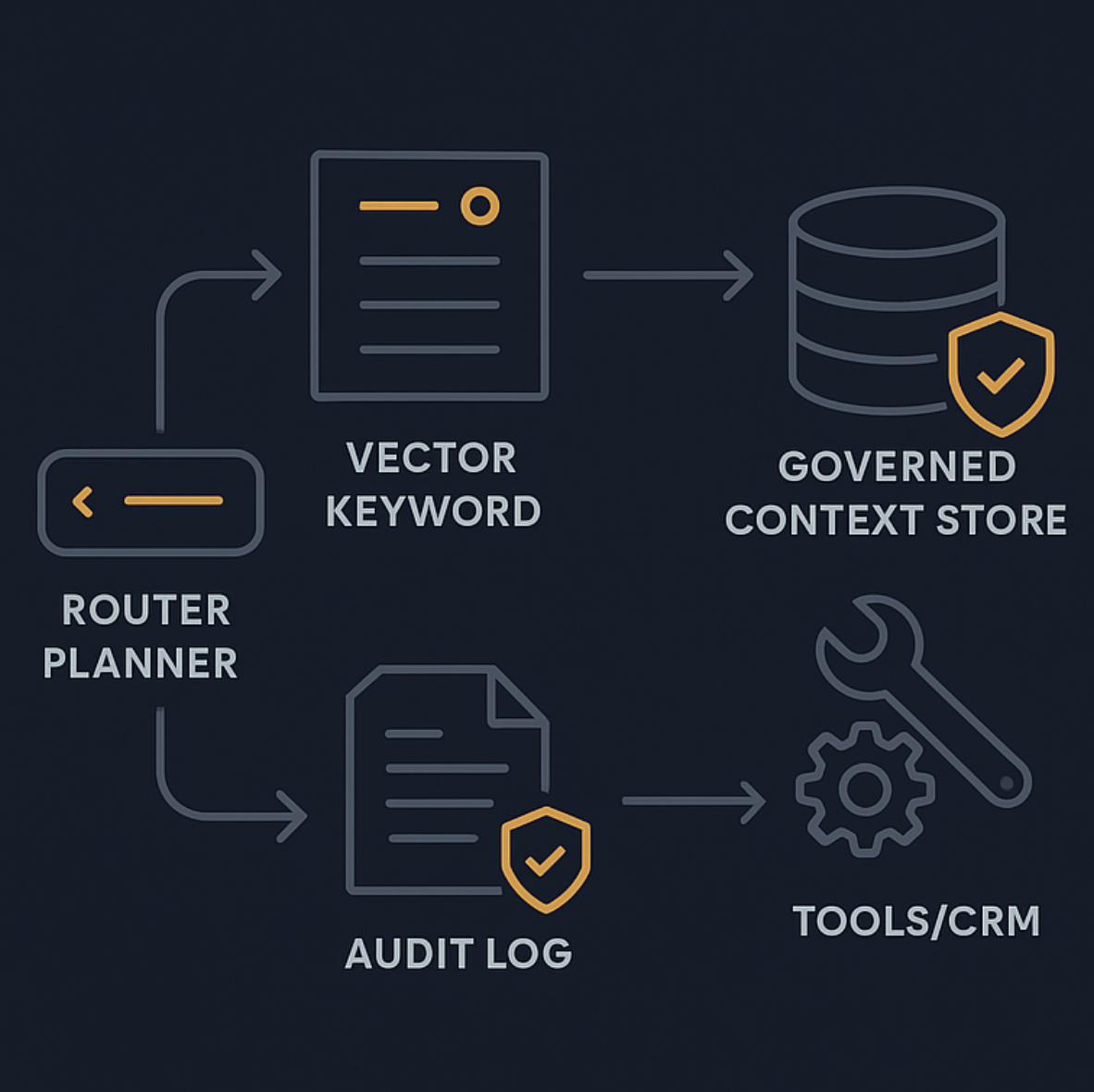
Arquitectura de referencia: agentic RAG para soporte
Un sistema de producción no es una única pipeline. Es un sistema de decisiones con guardrails.
Una forma útil de pensarlo es en tres capas: orquestación, ejecución e infraestructura, como sugiere Adaline Labs en production-ready agentic RAG architecture and observability.
Orquestación: router más motor de políticas
Esta capa decide qué hacer después.
Responsabilidades típicas:
- clasificar intents como FAQ, billing, account access u outage
- decidir si realmente hace falta retrieval
- elegir tools como CRM, sistema de pedidos o ticketing
- aplicar reglas de escalado y límites de "nunca automatizar"
Ejecución: retrieval, tool calls y síntesis de respuesta
Aquí ocurre el trabajo operativo:
- construir la consulta de retrieval
- recuperar evidencia con híbrido y reranking
- llamar tools con least privilege
- generar una respuesta apoyada en evidencia
Trata los resultados de retrieval como entrada no confiable.
Infraestructura: observabilidad, evaluación y confiabilidad
Necesitas:
- trazas para routing, retrieval y tool calls
- señales de evaluación para saber si la respuesta se mantuvo grounded
- retries, timeouts y fallbacks
Si no puedes explicar qué evidencia usaste y por qué tomaste una acción, el sistema aún no está listo para producción.
Requisitos de datos y retrieval
Si la documentación es desordenada, el modelo se equivocará con mucha confianza.
1. Construye un corpus listo para soporte
Normalmente incluye:
- help center público
- runbooks internos bien acotados
- políticas de reembolso, cancelación y SLA
- changelogs de producto
2. Haz chunking preservando contexto
Muchos proyectos de RAG fallan en silencio aquí.
Conviene respetar límites semánticos y añadir encabezados o resúmenes contextuales a cada chunk. Orkes resume esto en best practices for chunking and hybrid retrieval in production RAG.
3. Usa retrieval híbrido más reranking
El soporte mezcla cadenas exactas como códigos de error con intención difusa.
Por eso suele funcionar bien:
- búsqueda keyword para identificadores exactos
- búsqueda vectorial para paráfrasis
- reranking para afinar el conjunto final
4. Añade metadatos de frescura y ownership
Al menos guarda:
- tipo de fuente
- timestamp de última actualización
- owner o equipo responsable
- etiquetas de producto o versión
- clasificación de sensibilidad
Cómo desplegar Agentic RAG para automatización de soporte
Cada paso necesita un propósito, un output y un criterio de cierre.
Paso 1: añade un intent router y recupera solo cuando haga falta
Acción: clasifica solicitudes en pocos workflows.
Hecho cuando:
- registras el intent elegido por request
- puedes medir qué porcentaje activó retrieval
Paso 2: delimita herramientas con least privilege
Acción: separa tool access por intent y riesgo.
Ejemplos:
- billing puede leer facturas pero no iniciar reembolsos
- account access puede enviar reset links pero no cambiar ownership
- ningún workflow debería tener lectura sensible y escritura amplia sin gate humano
Paso 3: aplica autorización en tiempo de retrieval
En entornos multi-tenant, un fallo aquí es crítico.
El patrón robusto es aplicar permisos en la fuente autoritativa y propagar identidad hasta retrieval. AWS lo explica en retrieval-time authorization and identity propagation for RAG.
Paso 4: trata el texto recuperado como no confiable
La base de conocimiento es una cadena de suministro.
Si el texto recuperado incluye instrucciones maliciosas, el modelo puede seguirlas. AWS propone defensa en profundidad en indirect prompt injection.
Medidas útiles:
- sanitizar entradas y outputs
- separar instrucciones del sistema y contenido recuperado
- exigir confirmación para acciones con efecto real
- registrar todo
Paso 5: define un contrato de grounding
El modelo debe:
- responder preguntas de conocimiento solo con evidencia recuperada
- citar fuentes
- rechazar o escalar si la cobertura es insuficiente
Paso 6: añade verificación y escalado
Un verificador debería comprobar:
- si la respuesta contradice políticas
- si el intent no encaja con la evidencia
- si se está intentando una acción prohibida
Gobernanza: contexto versionado, auditoría y colaboración segura
Tratar el contexto como una simple bolsa de embeddings es arriesgado en soporte.
En producción necesitas controlar:
- quién puede editar conocimiento
- qué cambió
- cuándo cambió
- qué decisiones se tomaron con qué versión
Un enfoque útil es un context layer gobernado con archivos legibles por agentes, permisos, versionado y audit logs.
Evaluación y observabilidad antes de escalar
No puedes mejorar lo que no mides.
Mide al menos:
- retrieval quality
- faithfulness
- escalation rate
- latencias p50/p95
- coste por intent
Además, crea un eval set con tickets reales, edge cases y preguntas sensibles a políticas.
Rollout: de shadow mode a automatización real
Stage 0: shadow mode
- el sistema corre en paralelo
- registra intents, retrieval, drafts y triggers de escalado
Stage 1: agent-assist
- humanos siguen enviando
- el sistema propone borrador y evidencia
Stage 2: automatización parcial
- automatiza intents estrechos y de bajo riesgo
- mantén los flujos críticos con intervención humana
Stage 3: automatización ampliada
Solo cuando puedas trazar cada acción a su evidencia, revertir cambios de conocimiento y cortar tool execution rápidamente.
Troubleshooting: fallos comunes
Respuesta segura sin evidencia
- obliga a rechazar con baja confianza
- exige citas
- ajusta mejor el routing
Se recupera la versión incorrecta de una policy
- usa freshness metadata
- añade reglas de precedencia
- detecta drift y permite rollback
Prompt injection desde contenido recuperado
- trata el texto como untrusted
- añade gates para tools
- separa con claridad las instrucciones del sistema
Picos de latencia
- no hagas retrieval en todas las solicitudes
- cachea intents frecuentes
- rerankea solo donde importa
Key takeaways
- Agentic RAG para soporte es un sistema de workflow: router, retrieval, tools, verificación y escalado.
- Lo difícil es lo operativo: autorización, defensa contra inyecciones, evaluación y rollout por etapas.
- La gobernanza importa porque contexto y decisiones deben ser auditables y reversibles.
Next steps
Si hoy estás uniendo RAG y tools y ya notas problemas de permisos, auditoría o rollback, revisa: