RAG no ha muerto, el RAG agéntico es simplemente superior
27 de noviembre de 2025Guanqun @puppyone
TL;DR: Este es un proyecto de código abierto: https://github.com/puppyone/DeepWideResearch
Reemplaza los frágiles pipelines de RAG con flujos de trabajo agénticos, solucionando la pesadilla del mantenimiento y la caída de la calidad.
La contrapartida es real: el RAG agéntico cuesta más (>0,10 $/consulta frente a ~0,01 $ para el RAG tradicional) y es más lento (>10 s frente a menos de 3 s). Si necesitas respuestas en menos de un segundo a gran escala, esto no es para ti. Pero si necesitas un sistema de preguntas y respuestas (QA) sobre conocimiento que sea preciso y mantenible, sigue leyendo.
Compartiré nuestra experiencia construyendo la nueva arquitectura de RAG agéntico y exploraré por qué el RAG agéntico es el paso fundamental para los sistemas de QA de conocimiento empresarial.
Durante el último año, he entregado 5 proyectos de RAG tradicional, cada uno con entre 100 y 1000 páginas de documentación. El stack tecnológico era el estándar: escritura de consultas (Query Writing), enrutamiento de consultas (Query Routing), fragmentación (Chunking), embeddings, reclasificación (Reranking), etc. Al principio, todo iba bien, pero pronto caímos en una trampa: todo el proceso era extremadamente rígido y difícil de mantener.
La revelación más dolorosa llegó con un cambio en un documento. Un simple cambio provocó que la puntuación general del RAG cayera. Para mantener la misma puntuación, tuvimos que reconstruir toda nuestra estrategia de pipeline desde cero. Cada nueva fuente de datos se sentía como librar una nueva batalla. Intentamos solucionarlo con un etiquetado de metadatos complejo y una fragmentación más detallada, pero solo eran parches para una arquitectura rota.
Empezamos a preguntarnos: ¿Qué estamos haciendo mal?
El problema era la lógica. El RAG tradicional consiste esencialmente en escribir reglas if-else codificadas para ajustarse a un conjunto de datos. Eso funciona para código estático, pero falla cuando se necesita inteligencia real.
Inspirado por el Deep Research de OpenAI, decidí deshacerme del pipeline rígido.
Cambié a una arquitectura agéntica + MCP (Protocolo de Contexto del Modelo). La idea es simple: en lugar de una cadena de recuperación compleja, le damos al agente herramientas para buscar directamente en cada fuente de datos.
Esta es la arquitectura del sistema:
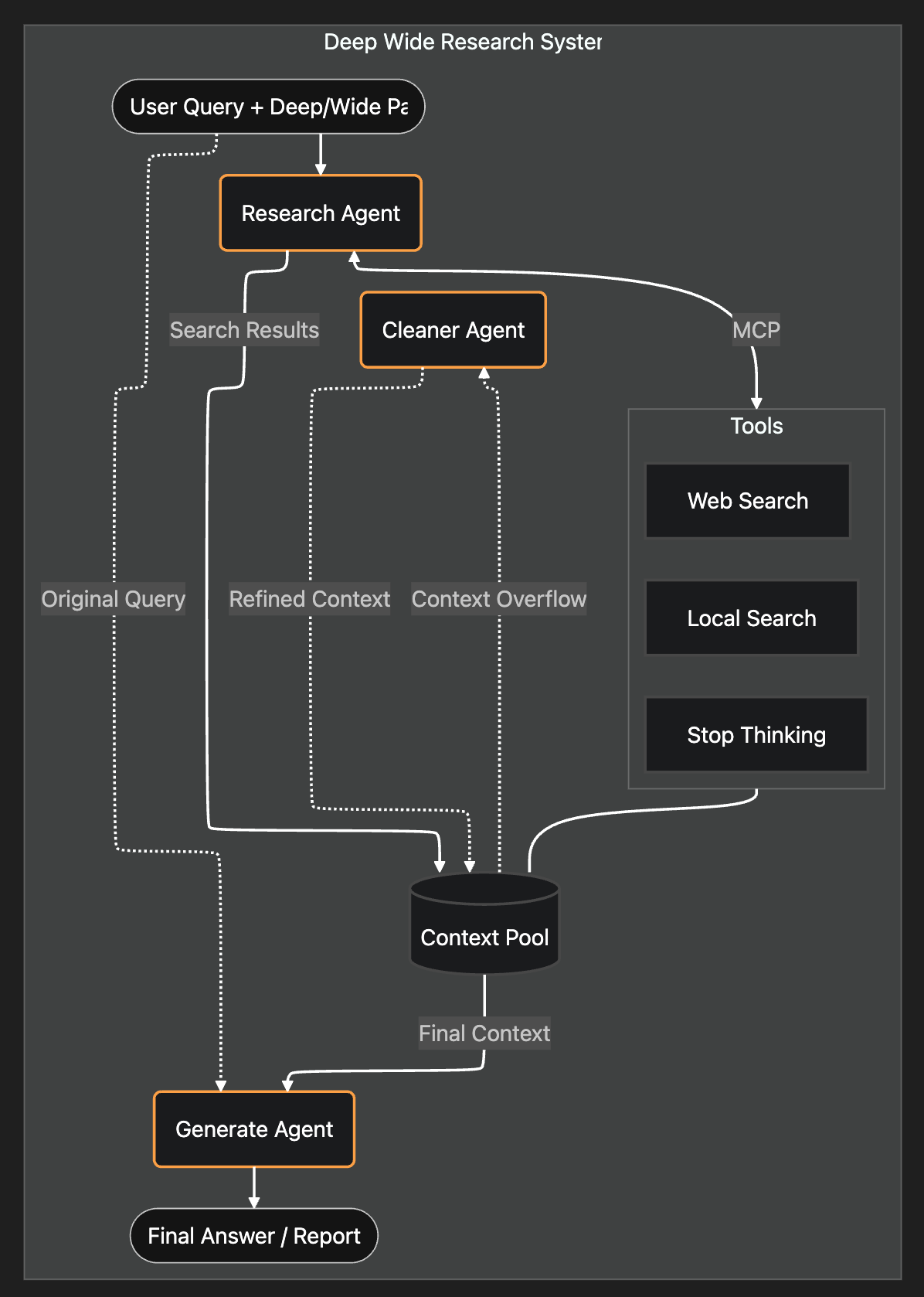
1. ¿Cómo construir el agente de investigación?
El RAG agéntico reemplaza todo el pipeline de recuperación con un único y autónomo agente de investigación.
En lugar de codificar reescrituras o reglas de enrutamiento, configuré dos agentes: un investigador (Researcher) y un generador (Generator).
Le di al investigador tres herramientas simples:

<Stop_thinking><Web_search><Local_search>
Pero darle herramientas a un agente no es suficiente. Necesitas decirle cuándo detenerse.
En lugar de un bucle while simple o un número fijo de pasos, obligué al agente a ejecutar un paso de autorreflexión antes de cada acción.
No usamos un bucle simple ni un contador de iteraciones. En su lugar, forzamos al agente a autorreflexionar antes de cada movimiento usando una "Verificación de preparación del artículo":
## Verificación de preparación del artículo:
- ¿Podría escribir una respuesta y un artículo completos y detallados AHORA MISMO? (Sí/No)
- Si lo escribiera ahora, ¿qué secciones serían débiles, vagas o carecerían de ejemplos/datos concretos?
- ¿Tengo suficientes hechos, cifras y ejemplos específicos para respaldar cada afirmación?
Solo cuando esta verificación se supera, el agente llama a <Stop_thinking>. Probamos esto con modelos de última generación (SOTA) (Gemini 3 pro / Claude 4.5 Opus / GPT-5), y siguieron la lógica a la perfección.
Todos los hallazgos de la investigación se almacenan en un grupo de contexto (Context Pool) compartido. Una vez que el investigador señala "Stop", un agente generador (Generate Agent) toma el grupo de contexto y escribe la respuesta final.
Los resultados superan a cualquier pipeline que hayamos construido. Es la inteligencia ganando a la estructura rígida.
Básicamente, mapeamos los componentes del RAG tradicional a comportamientos dinámicos del agente:
- ¿Enrutamiento de consultas? -> El agente elige la herramienta correcta.
- ¿Reescritura de consultas? -> El agente completa los argumentos de la función.
- ¿QA de múltiples saltos (Multi-hop)? -> El agente decide cuándo llamar a
<Stop_thinking>. - ¿Reclasificación (Reranking)? -> El agente genera la respuesta basándose en el grupo de contexto.
2. Manejo del desbordamiento de contexto
Me encontré con el segundo problema: ¿qué sucede cuando el contexto buscado se vuelve demasiado largo?
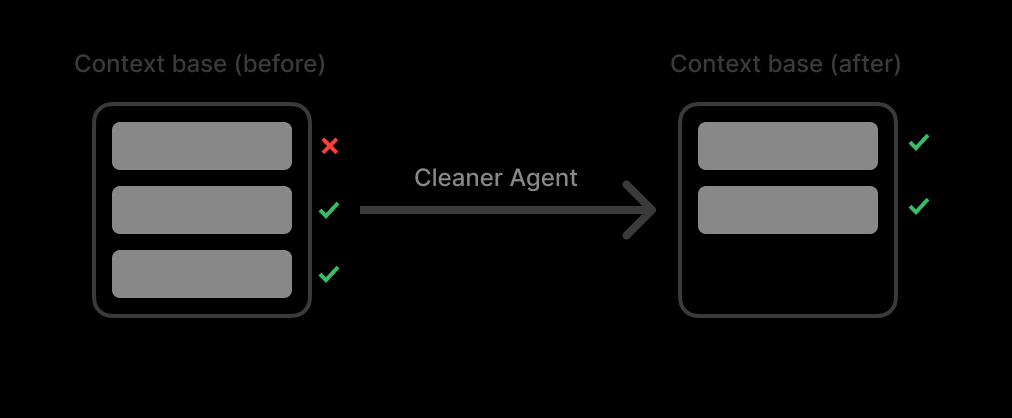
Construí un grupo de contexto (Context Pool). Este grupo funciona como una lista de todos los resultados de búsqueda. Creé un agente limpiador (Cleaner Agent) para limpiar el contexto cuando el grupo de contexto alcanza el umbral (90 % del máximo de tokens).
El truco es: no resumir. La sumarización mata los detalles.
En cambio, el agente limpiador funciona como un filtro de basura. Elimina fuentes irrelevantes por completo mientras mantiene las relevantes 100 % originales e intactas.
Finalmente, un agente generador (Generate Agent) produce la respuesta final basándose en el contenido refinado del grupo de contexto y la consulta original.
3. La solución "Deep-Wide" para el coste y la latencia
Pronto me enfrenté a un tercer desafío: la barrera del coste y la latencia.
Permítanme ser honesto con las cifras:
- Latencia: El RAG agéntico tiene un límite mínimo de ~10 segundos; el bucle de razonamiento es el cuello de botella y no podemos bajar de ahí. El RAG tradicional puede responder en menos de 3 s.
- Coste: Con GPT-5, espera un coste de ~0,05-1 $ por consulta. El RAG tradicional con embeddings cuesta ~0,005-0,01 $.
Para que esta contrapartida sea controlable por encima de este mínimo, introduje la "investigación profunda y amplia (Deep-Wide Research)":
- Profunda (Deep): Controla los pasos de razonamiento iterativo. Varía desde ~10 s (mínimo) hasta más de 5 minutos (profundidad máxima para informes exhaustivos).
- Amplia (Wide): Controla la expansión de consultas en paralelo. Más amplitud = más fuentes exploradas = mayor coste de tokens.
PROFUNDIDAD × AMPLITUD ≈ Coste. Al ajustar estas dos dimensiones, puedes controlar el tiempo de respuesta (10 s ~ 5 min), la calidad y el coste, pero no puedes bajar del mínimo de 10 s.
Hemos publicado DEEP WIDE RESEARCH como código abierto. URL del proyecto: https://github.com/puppyone/DeepWideResearch (Licencia Apache)
Lo que esto no resuelve
Este proyecto aborda la mitad del problema del RAG agéntico: el lado del "razonamiento y la búsqueda".
La otra mitad, el manejo de datos empresariales privados, sigue sin resolverse aquí:
- Limpiar documentos empresariales desordenados
- Construir índices optimizados para el consumo del agente
- Control de permisos granular
Estamos trabajando en esto por separado. Si te encuentras con estos problemas o tienes ideas, me encantaría saber de ti: [email protected]