Déployer un Agentic RAG pour l'automatisation du service client
8 avril 2026Lin Ivan
Le service client est un environnement exigeant pour les LLM : questions ambiguës, documentation périmée, données sensibles et erreurs visibles immédiatement par les utilisateurs.
Si vous voulez une automatisation du support qui tienne en production, un simple démo RAG ne suffit pas. Il vous faut un système agentic capable de router les demandes, récupérer les bonnes preuves, appeler des outils de façon sûre et escalader quand il n'est pas sûr de lui.
Ce billet est un playbook de déploiement pour les équipes de production.
Définir ce que signifie "automatiser" avant de déployer
Beaucoup d'équipes commencent par le chatbot. Il vaut mieux commencer par choisir les workflows à automatiser et la définition concrète de "done".
Choisir un mode de déploiement
Point de départ recommandé :
- Agent-assist : le système prépare la réponse et l'evidence bundle, un humain envoie.
- Automatisation partielle : quelques intents étroits et peu risqués sont auto-résolus.
- Automatisation étendue : la majorité des intents est automatisée, mais seulement après validation progressive.
Définir une liste "ne jamais automatiser"
Elle devrait inclure :
- actions financières au-dessus d'un seuil
- changements de propriété de compte
- exportations de données
- tout flux réglementé ou fortement risqué
Ces cas doivent escalader immédiatement.
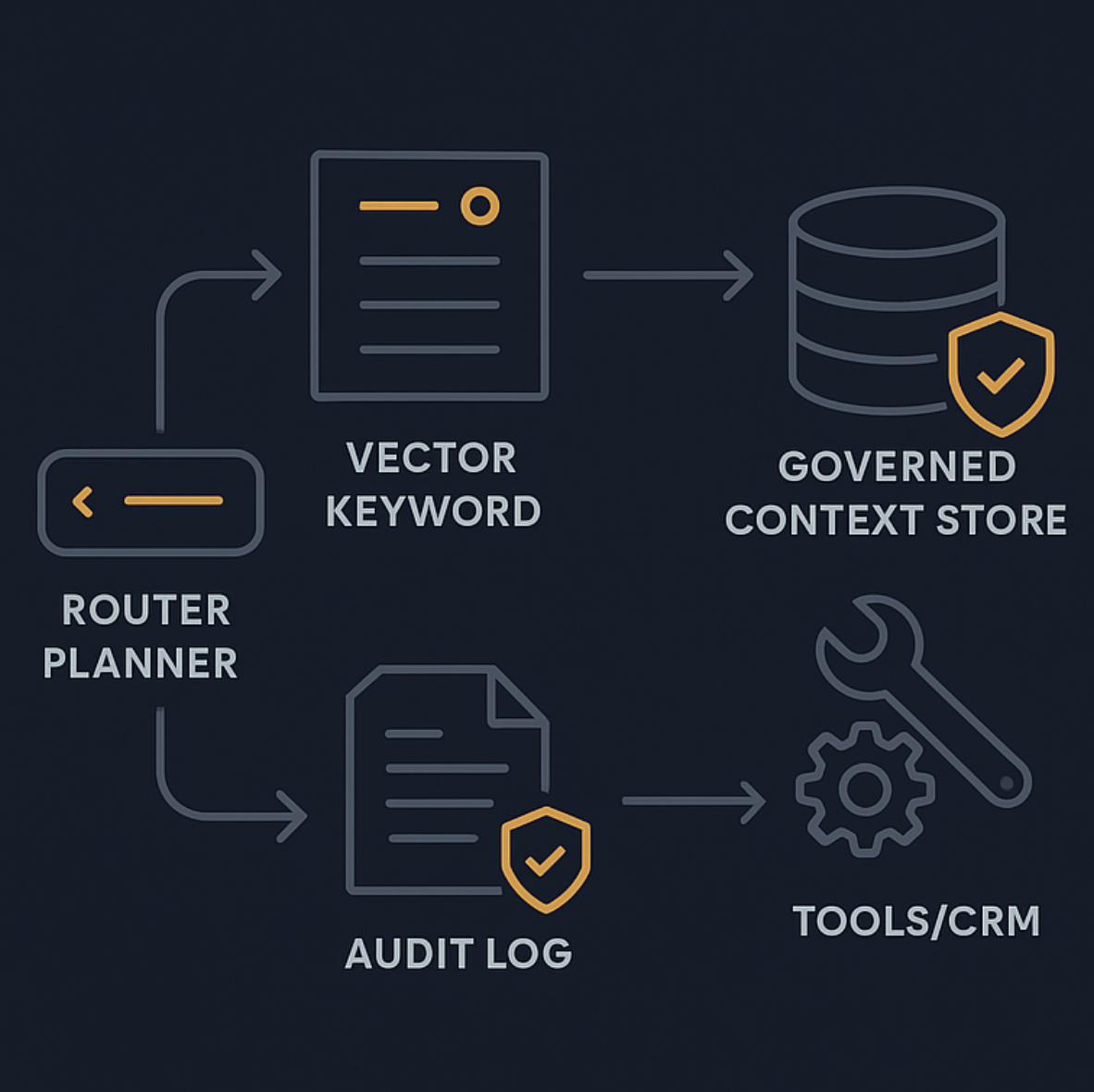
Architecture de référence : Agentic RAG pour le support
Un système de production n'est pas une simple pipeline. C'est un système de décision avec garde-fous.
Une grille utile est la séparation en orchestration, execution et infrastructure, comme dans l'article d'Adaline Labs sur production-ready agentic RAG architecture and observability.
Orchestration : routeur plus moteur de politiques
Cette couche décide de la suite.
Tâches typiques :
- classer l'intent
- décider si retrieval est nécessaire
- choisir les outils utiles
- appliquer les règles d'escalade et les limites "ne jamais automatiser"
Execution : retrieval, outils, synthèse
Ici se fait le travail :
- construire la requête de retrieval
- récupérer des preuves via hybride et reranking
- appeler les tools avec least privilege
- rédiger une réponse ancrée dans les preuves
Les résultats de retrieval doivent être traités comme non fiables par défaut.
Infrastructure : observabilité, évaluation, fiabilité
Il faut :
- des traces par étape
- des signaux d'évaluation sur le grounding
- retries, timeouts et fallbacks
Si vous ne pouvez pas expliquer quelles preuves ont été utilisées et pourquoi une action a été prise, le système n'est pas prêt pour la production.
Prérequis côté données et retrieval
Si votre documentation est confuse, le modèle répondra faux avec assurance.
1. Constituer un corpus prêt pour le support
Il comprend souvent :
- centre d'aide public
- runbooks internes bien scoppés
- politiques de remboursement, résiliation, SLA
- changelogs produit
2. Choisir un chunking qui préserve le contexte
Beaucoup de projets RAG échouent silencieusement ici.
Mieux vaut respecter les frontières sémantiques et ajouter titres ou résumés contextuels aux chunks. Voir aussi best practices for chunking and hybrid retrieval in production RAG.
3. Utiliser retrieval hybride plus reranking
Le support mélange identifiants exacts et formulations floues.
Donc, en pratique :
- keyword search pour les IDs et termes précis
- vector search pour les reformulations
- reranking pour affiner le lot final
4. Ajouter des métadonnées de fraîcheur et d'ownership
Au minimum :
- type de source
- date de mise à jour
- owner ou équipe
- tags produit/version
- classe de sensibilité
Déployer Agentic RAG pour le service client
Chaque étape doit avoir un but, un output et un critère de fin.
Étape 1 : router les intents et ne récupérer que si nécessaire
Action : classer les demandes dans quelques workflows.
Done when :
- l'intent choisi est loggé
- vous mesurez la part de requêtes qui ont réellement eu besoin de retrieval
Étape 2 : définir les limites d'outils avec least privilege
Action : séparer l'accès aux tools selon l'intent et le risque.
Étape 3 : appliquer l'autorisation au moment du retrieval
Dans un contexte multi-tenant, une erreur ici est critique.
Le pattern robuste consiste à faire respecter les permissions à la source autoritative et à propager l'identité jusqu'au retrieval. AWS le décrit dans retrieval-time authorization and identity propagation for RAG.
Étape 4 : traiter le texte récupéré comme non fiable
La base de connaissance est une chaîne d'approvisionnement.
Pour se défendre contre l'injection indirecte, il faut :
- sanitiser inputs et outputs
- séparer strictement consignes système et contenu récupéré
- exiger une confirmation avant toute action à effet réel
- conserver des logs complets
Étape 5 : imposer un contrat de grounding
Le modèle doit :
- répondre aux questions de connaissance uniquement à partir des preuves récupérées
- citer ses sources
- refuser ou escalader si la couverture est insuffisante
Étape 6 : ajouter vérification et escalade
Un vérificateur doit vérifier :
- contradiction avec les policies
- incohérence entre intent et preuves
- tentative d'action interdite
Gouvernance : contexte versionné, auditabilité et collaboration sûre
Traiter le contexte comme un simple sac d'embeddings est risqué.
En production, il faut savoir :
- qui modifie la connaissance
- ce qui a changé
- quand cela a changé
- quelle version a soutenu quelle décision
Un context layer gouverné avec fichiers lisibles par agents, permissions, versioning et audit logs est souvent la bonne direction.
Évaluation et observabilité avant de passer à l'échelle
Sans mesure, pas d'amélioration.
Indicateurs minimaux :
- retrieval quality
- faithfulness
- escalation rate
- latences p50/p95
- coût par intent
Complétez cela avec un jeu d'évaluation issu de tickets réels.
Rollout progressif
Stage 0 : shadow mode
- le système fonctionne en parallèle
- il logge intents, retrieval, drafts et triggers d'escalade
Stage 1 : agent-assist
- les humains continuent d'envoyer
- le système propose draft et preuves
Stage 2 : automatisation partielle
- quelques intents étroits sont auto-résolus
- les flux sensibles restent human-gated
Stage 3 : automatisation étendue
Uniquement quand chaque action est traçable jusqu'à ses preuves et qu'un rollback rapide existe.
Dépannage : pannes fréquentes
Réponse sûre sans preuve
- imposer le refus sous un seuil de confiance
- exiger des citations
- affiner le routing
Mauvaise version de policy récupérée
- utiliser fraîcheur et filtres
- ajouter des règles de priorité
- détecter le drift
Prompt injection via contenu récupéré
- traiter le texte récupéré comme untrusted
- ajouter du tool gating
- séparer strictement les consignes système
Pics de latence
- retrieval conditionnel
- cache sur intents fréquents
- reranking ciblé
Key takeaways
- Agentic RAG pour le support est un système de workflow : router, retrieval, tools, vérification et escalade.
- Les difficultés sont surtout opérationnelles : autorisation, défense contre l'injection, évaluation et rollout progressif.
- La gouvernance est indispensable pour versionner et auditer contexte comme décisions.
Next steps
Si vous assemblez aujourd'hui RAG et tools et que vous butez sur permissions, audit trails ou rollback, regardez :