Hybrid Indexing & Structured Know‑How for Dev Velocity
20 mars 2026Ollie @puppyone
Indexation hybride et Know‑How structuré : Le RAG pour les développeurs qui accélère les fusions de PR
La vélocité des développeurs ne s'arrête pas parce que les gens ont oublié comment coder. Elle stagne lorsque les équipes ne peuvent pas trouver, faire confiance ou réutiliser les connaissances déjà présentes dans leurs dépôts et leur documentation. C'est l'entropie de la connaissance : des ADR dispersés sur des wikis, des contrats d'API enfouis dans des PDF, une perte de propriété due à la rotation des effectifs. La génération augmentée par récupération (RAG) peut aider, mais seulement si elle repose sur une architecture de récupération à la fois sémantique et déterministe. C'est là que l'indexation hybride sur un Know‑How structuré change la donne pour les fusions de PR et les refactorisations plus sûres.
Points clés à retenir
- L'indexation hybride + le Know‑How structuré réduisent les hallucinations et produisent des citations précises et vérifiables qui accélèrent les revues de PR.
- Traitez le RAG pour les développeurs comme un système d'ingénierie : mesurez la precision@k, l'exactitude des citations, le temps de fusion (time‑to‑merge) et le taux de réversion (revert rate).
- Utilisez un récupérateur hybride (lexical sparse + vecteurs denses + clés structurelles/graphes) pour répondre aux questions sur la base de code avec des chemins de fichiers exacts et des identifiants ADR.
- Commencez par des micro-workflows : un assistant de description de PR avec citations et un conseiller en refactorisation basé sur les ADR et la propriété (ownership).
- Privilégiez les déploiements privés/locaux, la suppression des secrets avant l'embedding, et des points de contrôle avec intervention humaine pour toute suggestion d'écriture.
RAG pour les développeurs — ce qui fonctionne et ce qui échoue
Le RAG associe un LLM à un récupérateur qui extrait des preuves de votre code, de votre documentation et de l'historique de conception. Quand cela fonctionne, les développeurs obtiennent des résumés étayés et des brouillons de textes de PR avec des sources. Quand cela échoue, vous obtenez des réponses erronées affirmées avec assurance et la confiance s'effondre.
Modèles d'échec à surveiller :
- Les vecteurs textuels seuls manquent les identifiants exacts (ADR-1234, noms de fonctions), renvoyant des fragments plausibles mais erronés.
- La sur-récupération inonde les prompts ; les relecteurs voient du bruit, pas du signal.
- L'absence de citations signifie une absence de confiance ; les relecteurs doivent refaire la recherche eux-mêmes.
Les correctifs basés sur les meilleures pratiques s'appuient sur des conseils bien documentés : chunking sémantique, récupération hybride et reranking. Pour un aperçu architectural concis, consultez les modèles orientés production dans l'article d'InfoQ sur les pipelines RAG, qui met l'accent sur la composition et l'évaluation de la récupération, et non sur les prompts magiques (InfoQ — Effective Practices for Architecting a RAG Pipeline). Et pour les workflows d'agents développeurs au moment de la CI, la discussion de GitHub sur l'IA continue montre comment les assistants peuvent rédiger et vérifier des artefacts dans la boucle (GitHub Blog — Continuous AI in practice: agentic CI for developers).
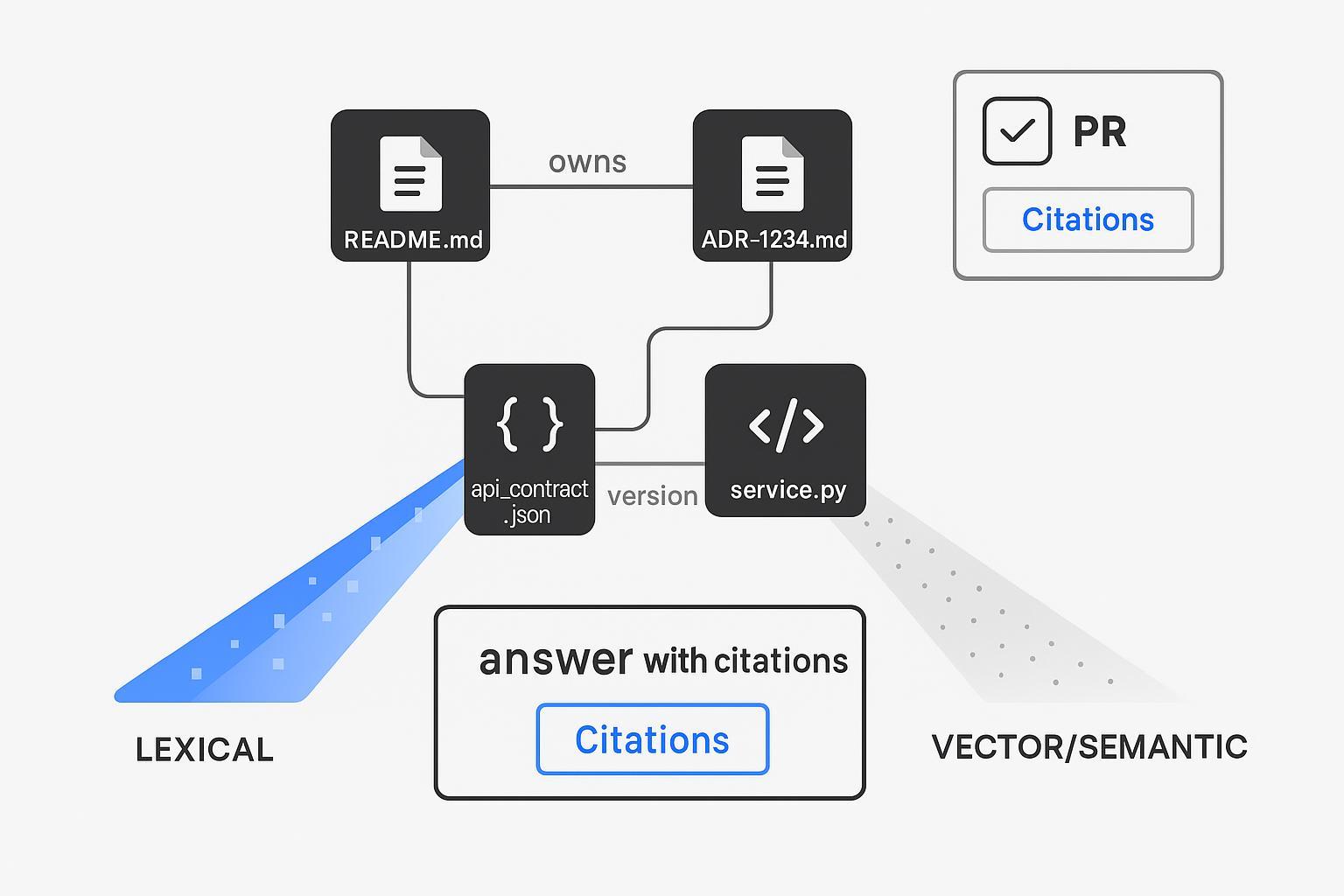
Know‑How structuré + indexation hybride comme colonne vertébrale de récupération
Le texte seul ne peut pas porter vos workflows de développement. Modélisez explicitement le Know‑How de l'entreprise et effectuez des récupérations sur le texte et la structure.
Un schéma minimal de Know‑How (illustratif) :
{
"type": "adr",
"adr_id": "ADR-1234",
"title": "Deprecate legacy payment gateway",
"status": "accepted",
"decision": "Move to PayFast v3",
"owners": ["@payments-core"],
"links": {"repo_paths": ["/services/payments"], "docs": ["/docs/payments/adr-1234.md"]},
"supersedes": ["ADR-0899"],
"date": "2025-11-06",
"version": "1.2"
}
Conception du récupérateur hybride (en un coup d'œil) :
- Lexical : filtres exacts (repo_path:/services/payments, file:*.md), BM25 pour les identifiants.
- Dense : embeddings de code/doc pour les paraphrases et l'intention.
- Structurel : jointures déterministes par clés (adr_id, owner, module) pour extraire les bons fichiers/propriétaires.
- Optionnel : rerank avec un cross‑encoder pour la fidélité.
Ce modèle reflète les conseils des fournisseurs et de la communauté sur la recherche hybride — fusion dense + sparse avec reranking optionnel, comme documenté par les ressources d'ingénierie de recherche hybride de Qdrant (Qdrant — Hybrid Search Revamped ; Qdrant Docs — Hybrid Queries). Le résultat est une couche de récupération capable de citer des chemins de fichiers exacts et des identifiants ADR, et non pas juste "quelque chose qui y ressemble". C'est le levier de confiance dont les relecteurs ont besoin.
Micro-workflows qui accélèrent les PR
- Assistant de description de PR avec citations
Objectif : Rédiger un corps de PR étayé à partir du diff et du Know‑How local.
Étapes clés :
- Développer le titre de la branche/PR en variantes de requêtes.
- Récupérer le top‑k parmi : (a) les chemins modifiés (filtres lexicaux), (b) les documents/fragments sémantiquement similaires, (c) les clés structurelles (ADRs/propriétaires).
- Générer un corps de PR qui inclut toujours un bloc Citations avec des permaliens.
Exemple de modèle de corps de PR :
#### Summary
- Implements PayFast v3 retry policy in /services/payments/retry.go
#### Rationale
- Aligns with ADR-1234 (Deprecate legacy payment gateway). See details below.
#### Impact
- Touches retry.go; no public API changes. Adds metric payments.retry.backoff_ms.
#### Citations
- ADR-1234 — /docs/payments/adr-1234.md#decision
- Code — /services/payments/retry.go#L120-L168
- Runbook — /ops/runbooks/payments-retries.md#rollback
- Conseiller en refactorisation alimenté par les ADR et la propriété
Objectif : Sécuriser les grandes refactorisations en faisant remonter automatiquement l'intention de conception et les propriétaires.
Étapes clés :
- Étant donné un plan de refactorisation proposé, récupérer les ADR remplacés et les propriétaires de modules affectés.
- Générer une checklist : "notifier @payments-core", "mettre à jour les tests de contrat", "confirmer la fenêtre de dépréciation selon l'ADR‑0899".
- Émettre des citations vers chaque source afin que les relecteurs puissent vérifier rapidement.
Mesurer la vélocité des développeurs et la qualité de la récupération
Traitez le RAG comme un système d'ingénierie avec des résultats auditables.
Métriques à suivre :
- Vélocité : temps médian de fusion (TTM), taux de fusion (fusionnés/ouverts), itérations de revue par PR.
- Qualité : taux de réversion, taux d'échec CI, défauts post-fusion pour les refactorisations.
- Récupération : precision@k, exactitude des citations (la source citée soutient-elle l'affirmation ?), taux d'hallucination.
Plan A/B (8–12 semaines) :
- Contrôle : workflow standard.
- Traitement : activer l'assistant de description de PR + le conseiller en refactorisation (suggestions en lecture seule) avec citations.
- Instrumenter les événements à chaque étape : récupération → suggestion → acceptation/remplacement par le relecteur → fusion.
Pour un contexte industriel plus large sur la mesure et l'amélioration de la fidélité du RAG et du comportement des citations, voir les récents travaux d'enquête et d'évaluation qui formalisent les métriques de pertinence/fidélité et l'audit par LLM-as-judge (arXiv — Evaluation of Retrieval‑Augmented Generation: A Survey ; arXiv — Comprehensive and Practical Evaluation of RAG).
De la démo à la production
Vous n'avez pas besoin d'un monolithe ; vous avez besoin d'une boucle fiable.
- Ingestion : chunking sensible au langage pour le code (fonctions/classes) et les docs (en-têtes/sémantique). Attacher des métadonnées (repo_path, module, owner, version). Viser 500–1500 tokens pour le code ; 400–1000 pour les docs.
- Cadence d'indexation : ré-embedder lors des changements ; lot nocturne pour les dépôts actifs ; hebdomadaire pour les moins actifs. Versionnez votre index pour les rollbacks.
- Gouvernance : privilégier les déploiements privés/locaux ; aligner les ACL de récupération sur les permissions des dépôts ; caviarder les secrets avant l'embedding.
- Service : limiter k pour contrôler les tokens ; mettre en cache les requêtes fréquentes ; envisager le reranking par cross-encoder pour les espaces de noms complexes.
- Surveillance : suivre la precision@k, l'exactitude des citations, la latence et le coût par requête. Alerter en cas de dérive (baisse de précision ou d'exactitude des citations).
Les signaux du monde réel montrent pourquoi cela en vaut la peine. Amazon a rapporté qu'Amazon Q Developer a réduit les mises à niveau Java à grande échelle de plusieurs jours à quelques minutes sur des dizaines de milliers d'applications, économisant environ 4 500 années-développeurs et contribuant à un impact annuel de 260 millions de dollars (AWS DevOps & Developer Productivity Blog, 2024) — la preuve que les assistants développeurs intégrés peuvent débloquer des changements majeurs de débit lorsqu'ils sont intégrés au SDLC (AWS DevOps Blog — Amazon Q Developer milestone). Et l'étude de cas de GitHub sur Mercado Libre souligne une adoption à l'échelle de l'organisation avec environ 50 % de temps en moins passé à écrire du code et un débit de PR extraordinaire, suggérant que le potentiel est immense lorsque les assistants sont sur le chemin critique (GitHub Customer Stories — Mercado Libre).
Notes sur l'outillage — des stacks qui fonctionnent bien ensemble
- Vecteur + sparse : Qdrant, Pinecone, Weaviate supportent tous les modèles hybrides ; choisissez en fonction du contrôle sur la fusion des scores, de la maturité opérationnelle et du coût.
- Orchestration : LangChain/LlamaIndex pour une composition rapide ; Dagster/Airflow pour les opérations d'ingestion.
- Embeddings : choisissez des modèles optimisés pour le code pour les dépôts ; surveillez la dérive et ré-embeddez sélectivement.
- Graphe/structure : Neo4j/TigerGraph pour des graphes de Know‑How explicites ou JSON/kv léger pour les petites équipes.
- Agent CI : intégrez les assistants dans les hooks de PR et les commentaires de CI selon les conseils de GitHub sur la CI agentique.
Exemple pratique : utiliser le Know‑How structuré et l'indexation hybride de puppyone
L'indexation hybride ne brille que lorsque vos connaissances sont modélisées pour les machines. Une façon neutre d'implémenter cela est de stocker les connaissances de l'entreprise sous forme de Know‑How structuré (JSON/graphe) et de fusionner les recherches lexicales, vectorielles et structurelles dans un seul récupérateur.
Exemple de workflow (illustratif, neutre) :
- Modéliser les ADR, la propriété et les contrats d'API comme des nœuds de Know‑How de premier ordre (ex: adr_id, status, decision, owners, repo_paths, version).
- Ingérer des fragments de code/doc avec des métadonnées (repo_path, symbols, owners). Construire un index hybride où les filtres lexicaux (ex: chemin du dépôt), les vecteurs (similarité sémantique) et les jointures structurelles (adr_id → fichiers/propriétaires liés) sont combinés.
- Dans l'assistant de PR, exiger un bloc Citations avec des permaliens vers les ADR et les plages de lignes de fichiers afin que les relecteurs puissent vérifier rapidement.
Ce modèle est soutenu par les documents conceptuels publics de puppyone, qui se positionne autour du Know‑How structuré et de l'indexation hybride pour une récupération déterministe et des citations précises. Pour un aperçu de cette approche, consultez l'article de l'entreprise sur l'indexation hybride, qui résume comment le texte et la structure peuvent être combinés pour un ancrage fiable dans les workflows d'agents (voir l'aperçu dans le "Ultimate Guide to Agent Context Base: Hybrid Indexing") (puppyone’s hybrid indexing guide). Utilisez cela comme référence conceptuelle lors de la conception de votre propre schéma et récupérateur ; adaptez-le à votre stack et à vos contraintes de gouvernance.
Conclusion et prochaines étapes
Si votre objectif est d'obtenir des PR plus rapides et plus sûres, investissez d'abord dans un Know‑How structuré et un récupérateur hybride capable de prouver chaque affirmation par une citation. Pilotez un assistant de description de PR et un conseiller en refactorisation, mesurez le TTM et l'exactitude des citations, puis passez à l'échelle ce qui fonctionne. Si vous explorez le Know‑How structuré et l'indexation hybride, vous pouvez évaluer puppyone dans le cadre d'un petit pilote privé et le comparer à votre stack existante.