Mise à l'Échelle de RAG et RL pour l'Optimisation IA
27 avril 2025Mei @puppyone
 Source de l'image : Pexels
Source de l'image : Pexels
La mise à l'échelle de l'Apprentissage par Renforcement (RL) transforme l'IA en optimisant les performances du modèle grâce à des stratégies d'apprentissage adaptatif. En exploitant les lois d'échelle, la mise à l'échelle RL prédit le comportement de grands modèles à partir d'expériences à plus petite échelle, permettant une utilisation efficace des ressources. Par exemple, les modèles avec des longueurs de mémoire plus importantes démontrent des améliorations de performance jusqu'à 50% comparé aux modèles de référence.
La Génération Augmentée par Récupération (RAG) améliore les systèmes IA en combinant la récupération de données avec la génération de texte. Elle récupère des informations contextuelles de vastes dépôts de données, garantissant que les sorties restent précises et pertinentes. Cette approche améliore significativement les applications comme la recherche approfondie et la récupération de connaissances en temps réel.
L'intégration de RAG et RL crée une synergie puissante. Des systèmes comme DeepResearcher le démontrent, atteignant jusqu'à 28,9 points de taux de complétion de tâches plus élevés comparé aux méthodes traditionnelles. En combinant la récupération d'informations contextuelles avec l'optimisation RL, les systèmes IA livrent des performances améliorées à travers divers domaines.
Points Clés à Retenir
- La mise à l'échelle de l'Apprentissage par Renforcement (RL) aide l'IA à apprendre mieux et plus vite.
- La Génération Augmentée par Récupération (RAG) mélange la recherche de données avec la création de texte. Cela maintient les résultats corrects et pertinents.
- Utiliser RAG avec RL fait fonctionner les modèles beaucoup mieux. Cela peut réduire les erreurs de 69% et améliorer la prise de décision.
- Pour utiliser la mise à l'échelle RL avec RAG, choisissez un modèle de base. Puis, entraînez-le avec des données étiquetées et utilisez des outils comme Pinecone pour trouver des données rapidement.
- Ensemble, RAG et RL améliorent l'IA dans de nombreux domaines. Ils rendent le service client, les moteurs de recherche et les systèmes de connaissances plus intelligents.
Comprendre la Génération Augmentée par Récupération (RAG)
 Source de l'image : Pexels
Source de l'image : Pexels
Qu'est-ce que la Génération Augmentée par Récupération ?
Retrieval-Augmented Generation (RAG) represents a groundbreaking approach in artificial intelligence. It combines two essential processes: retrieving relevant data and generating contextually accurate outputs. Unlike traditional generative models, which rely solely on pre-trained knowledge, RAG integrates real-time information retrieval to enhance its responses. This dual mechanism ensures that outputs are not only coherent but also grounded in factual data.
The concept of RAG gained prominence through research efforts like Lewis et al.'s 2021 paper, Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Earlier foundational work by Guu et al. introduced the idea of integrating knowledge retrieval during pre-training. These advancements have made RAG a cornerstone in modern AI applications, enabling systems to deliver more authoritative and reliable results.
Comment RAG Combine Récupération et Génération
RAG seamlessly integrates retrieval and generation by leveraging external information retrieval systems alongside large language models (LLMs). The process begins with a retrieval phase, where the system searches for relevant data from external sources, such as databases or knowledge repositories. This retrieved information then serves as input for the generation phase, where the model produces responses that are both contextually accurate and semantically rich.
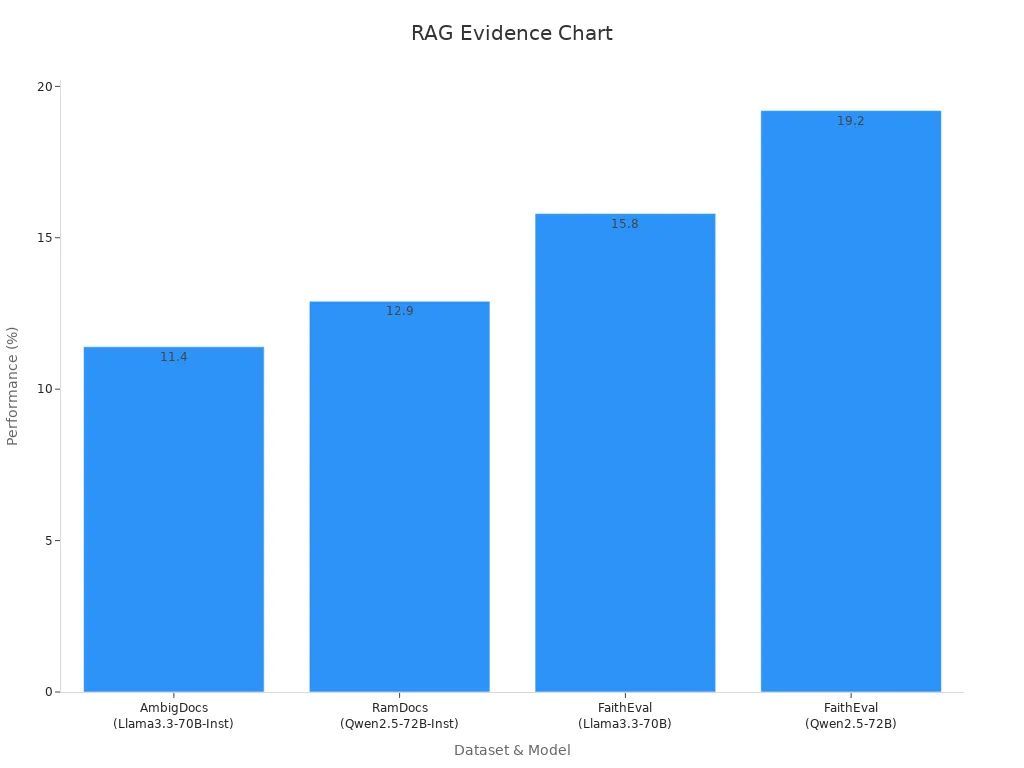
For instance, the Madam-RAG model demonstrates how this combination enhances performance across various datasets:
| Model | Dataset | Performance Improvement |
|---|---|---|
| Madam-RAG | AmbigDocs | +11.40% (Llama3.3-70B-Inst) |
| Madam-RAG | RamDocs | +12.90% (Qwen2.5-72B-Inst) |
| Madam-RAG | FaithEval | +15.80% (Llama3.3-70B) |
| Madam-RAG | FaithEval | +19.20% (Qwen2.5-72B) |
 Source de l'image : Pexels
Source de l'image : Pexels
Avantages du Pipeline RAG pour l'Amélioration des Connaissances
The RAG pipeline offers numerous advantages for enhancing knowledge-intensive tasks. Its ability to retrieve and generate information dynamically makes it a versatile tool across industries. Key benefits include:
- Improving Customer Service Interactions: RAG provides personalized and precise responses, boosting customer satisfaction.
- Enhancing Content Creation and Copywriting: It generates engaging and contextually relevant content tailored to specific audiences.
- Boosting E-learning & Virtual Tutoring Systems: RAG creates interactive learning environments by retrieving suitable explanations from educational databases.
- Revolutionizing Healthcare Diagnosis: It streamlines diagnosis by retrieving relevant health records, enabling accurate and timely consultations.
- Customer Feedback Analysis: RAG accelerates sentiment analysis by accessing diverse sources of feedback, helping businesses refine their offerings.
The transformative impact of RAG extends beyond these use cases. By merging dynamic knowledge retrieval with generative accuracy, RAG reshapes AI applications across industries. Its ability to utilize real-time data and specialized knowledge significantly enhances the performance and reliability of AI systems. Projections indicate that the RAG market will grow to $40.34 billion by 2035, with an annual growth rate of approximately 35%. This growth underscores its critical role in addressing AI's hallucination issues and improving content relevance.
Mise à l'Échelle RL et Son Importance en IA
Qu'est-ce que la Mise à l'Échelle RL ?
RL scaling refers to the process of enhancing reinforcement learning (RL) models by increasing their capacity to handle complex tasks. It involves scaling the computational resources, data inputs, and model architectures to improve learning efficiency and adaptability. Unlike traditional scaling methods, RL scaling emphasizes active learning through dynamic interactions and feedback mechanisms.
Key principles of RL scaling include:
- Self-Play Reinforcement Learning (SPRL): This method enables agents to learn by interacting with themselves, fostering active learning through experience.
- The Learning Cycle: Agents observe their environment, act, receive feedback, and adjust their behavior in a continuous loop.
- Redefining Scalability: New scaling laws incorporate the computational cost of exploration, challenging conventional methods.
These principles highlight the transformative potential of RL scaling in advancing AI systems.
Objectif de la Mise à l'Échelle RL dans les Modèles IA
The primary goal of RL scaling is to enhance the efficiency and adaptability of AI models. Traditional scaling methods often struggle with unstable training dynamics, which can hinder performance. RL scaling addresses these challenges by introducing mechanisms like Soft Mixtures of Experts (MoEs). These mechanisms optimize resource allocation and improve learning outcomes across diverse RL settings.
Empirical studies demonstrate the effectiveness of RL scaling. For instance, the Open Reasoner Zero model achieved performance levels comparable to specialized RL systems by leveraging a base model. This underscores the importance of RL scaling in refining large language models and ensuring they deliver accurate and reliable results.
Avantages de Combiner RAG et RL
Integrating RAG with RL creates a robust framework for knowledge-intensive tasks. RAG enhances the retrieval of relevant data, while RL optimizes the learning process. Together, they significantly improve the performance of large language models. Trials have shown a 69% reduction in model loss, decreasing from 0.32 to 0.1. This improvement ensures that users receive precise and contextually accurate information.
The combination of RAG and RL also supports multi-agent systems. These systems enable agents to collaborate, enhancing their ability to perform deep research and solve complex problems. By incorporating retrieval processes into RL workflows, AI systems achieve greater stability and scalability. This synergy highlights the importance of RAG in addressing the limitations of traditional RL methods.
Guide Étape par Étape pour la Mise à l'Échelle RL Après Utilisation de RAG
 Source de l'image : Pexels
Source de l'image : Pexels
Prérequis pour la Mise à l'Échelle RL avec RAG
Before implementing RL scaling with RAG, certain prerequisites must be met to ensure a smooth workflow. These prerequisites include:
- A Base Model: Select a foundational large language model (LLM) capable of handling retrieval and generation tasks. Models like Llama or Qwen are commonly used due to their adaptability.
- Knowledge Retrieval System: Integrate a robust retrieval system, such as the Pinecone vector database, to facilitate efficient similarity search and dynamic querying of the agent. This ensures the retrieval of relevant data for generation tasks.
- Annotated Dataset: Prepare a query-specific dataset structured as rationale chains. This dataset serves as the foundation for supervised fine-tuning and subsequent RL alignment.
- Knowledge Selector: Implement a knowledge selector to filter retrieved information. This becomes critical when working with weaker generator models or ambiguous tasks.
- Multi-Agent Collaboration: Establish a multi-agent system to enhance scalability and deep research capabilities. Agents can collaborate to refine retrieval and generation processes.
These prerequisites lay the groundwork for building a RAG agent capable of efficient RL scaling.
Outils et Frameworks pour la Mise à l'Échelle RL
Several tools and frameworks support RL scaling, enabling efficient implementation and optimization. Key options include:
- Pinecone Vector Database: This tool specializes in efficient similarity search, ensuring rapid retrieval of relevant data. It plays a pivotal role in querying our agent and enhancing retrieval accuracy.
- VeRL Framework: ByteDance's VeRL framework provides a robust environment for RL training. It supports the integration of RAG and RL, enabling seamless alignment of retrieval and generation processes.
- Modified PPO Algorithms: Proximal Policy Optimization (PPO) algorithms, adapted for RL scaling, improve learning dynamics and convergence rates. These modifications have been benchmarked across environments like Atari games and Box2D.
- Contrastive Multi-Task Learning (CML): This technique enhances the model's ability to differentiate between relevant and irrelevant information during training. It complements RL alignment by refining the retrieval process.
| Model | Average Accuracy (%) | Improvement (%) |
|---|---|---|
| ToRL-1.5B | 48.5 | - |
| Qwen2.5-Math-1.5B-Instruct | 35.9 | - |
| Qwen2.5-Math-1.5B-Instruct-TIR | 41.3 | - |
| ToRL-7B | 62.1 | 14.7 |
These tools and frameworks provide the necessary infrastructure for scaling RL efficiently while leveraging RAG.
Étapes d'Implémentation pour la Mise à l'Échelle RL
Implementing RL scaling after applying RAG involves a structured approach. Follow these steps to ensure optimal performance:
- Data Collection: Gather a query-specific annotated dataset structured as rationale chains. This dataset forms the basis for supervised fine-tuning.
- Supervised Fine-Tuning (SFT): Train the base model using the collected dataset. This step enhances the model's retrieval and generation capabilities.
- Contrastive Multi-Task Learning (CML): Refine the model's ability to distinguish between relevant and irrelevant information. This step improves retrieval accuracy and generation quality.
- RL Alignment: Fine-tune the model using reinforcement learning techniques. Align its outputs with desired outcomes based on feedback mechanisms.
- Integration with Pinecone: Connect the model to the Pinecone vector database for efficient similarity search. This integration ensures rapid and accurate retrieval during generation tasks.
- Multi-Agent Collaboration: Deploy a multi-agent system to enhance scalability and deep research capabilities. Agents collaborate to optimize retrieval and generation workflows.
- Performance Monitoring: Continuously monitor the model's performance using metrics like Knowledge F1 and retrieval accuracy. Adjust training parameters to maintain efficiency.
Tip: Blending gold knowledge with distractor knowledge during training can simulate diverse selection outcomes, improving the model's adaptability.
By following these steps, developers can successfully implement RL scaling with RAG, achieving enhanced performance and scalability in AI systems.
Ajustement Fin et Optimisation dans le Pipeline RAG
Fine-tuning and optimization play a critical role in enhancing the performance of models within the RAG pipeline. These processes refine the model's ability to retrieve and generate accurate, contextually relevant outputs. However, achieving optimal results requires careful planning and execution to avoid potential pitfalls.
Défis dans l'Ajustement Fin du Pipeline RAG
Fine-tuning within the RAG pipeline often encounters challenges that can impact model performance. For instance, increasing the sample size during fine-tuning does not always lead to better outcomes. Studies have shown that larger sample sizes can reduce both accuracy and completeness. In one experiment, the Mixtral model's accuracy dropped from 4.04 to 3.28 when the sample size increased from 500 to 1000. This highlights the need for a balanced approach to fine-tuning, where the quality of data takes precedence over quantity.
Another challenge involves maintaining the model's ability to generalize across diverse tasks. Overfitting to specific datasets during fine-tuning can limit the model's adaptability. This is particularly problematic in knowledge-intensive applications, where the RAG pipeline must handle a wide range of queries and contexts.
Stratégies pour un Ajustement Fin Efficace
To address these challenges, developers can adopt several strategies:
- Selective Data Sampling: Instead of using large datasets indiscriminately, focus on high-quality, annotated samples that align with the model's target tasks. This approach minimizes the risk of performance degradation.
- Incremental Fine-Tuning: Gradually fine-tune the model in smaller stages, allowing it to adapt without overwhelming its learning capacity. This method helps maintain a balance between specialization and generalization.
- Knowledge Blending: Incorporate a mix of gold-standard knowledge and distractor information during training. This technique enhances the model's ability to differentiate between relevant and irrelevant data, improving retrieval accuracy.
Techniques d'Optimisation pour le Pipeline RAG
Optimization ensures that the RAG pipeline operates efficiently and delivers consistent results. Key techniques include:
- Dynamic Retrieval Mechanisms: Implementing real-time retrieval systems allows the model to access up-to-date information. This is particularly useful in applications like deep research, where knowledge evolves rapidly.
- Multi-Agent Collaboration: Deploying multiple agents within the RAG pipeline enhances scalability and task specialization. Each agent can focus on specific aspects of retrieval or generation, improving overall system performance.
- Contrastive Multi-Task Learning (CML): This technique refines the model's ability to prioritize relevant information during training. By contrasting correct and incorrect retrievals, CML sharpens the model's decision-making capabilities.
Tip: Regularly monitor performance metrics such as retrieval accuracy and Knowledge F1 scores. Adjust training parameters based on these metrics to maintain optimal performance.
By combining fine-tuning with robust optimization strategies, the RAG pipeline can achieve superior performance in knowledge-intensive tasks. These methods ensure that the pipeline remains adaptable, accurate, and efficient, even as the complexity of its applications increases.
Applications Pratiques de RAG et RL
Améliorer les Chatbots de Support Client
Customer support chatbots powered by RAG and RL deliver precise and contextually relevant responses. By integrating retrieval mechanisms, these chatbots access real-time data to address user queries effectively. Reinforcement learning further optimizes their performance by aligning responses with user preferences and feedback. This combination ensures that chatbots provide accurate information while improving user satisfaction.
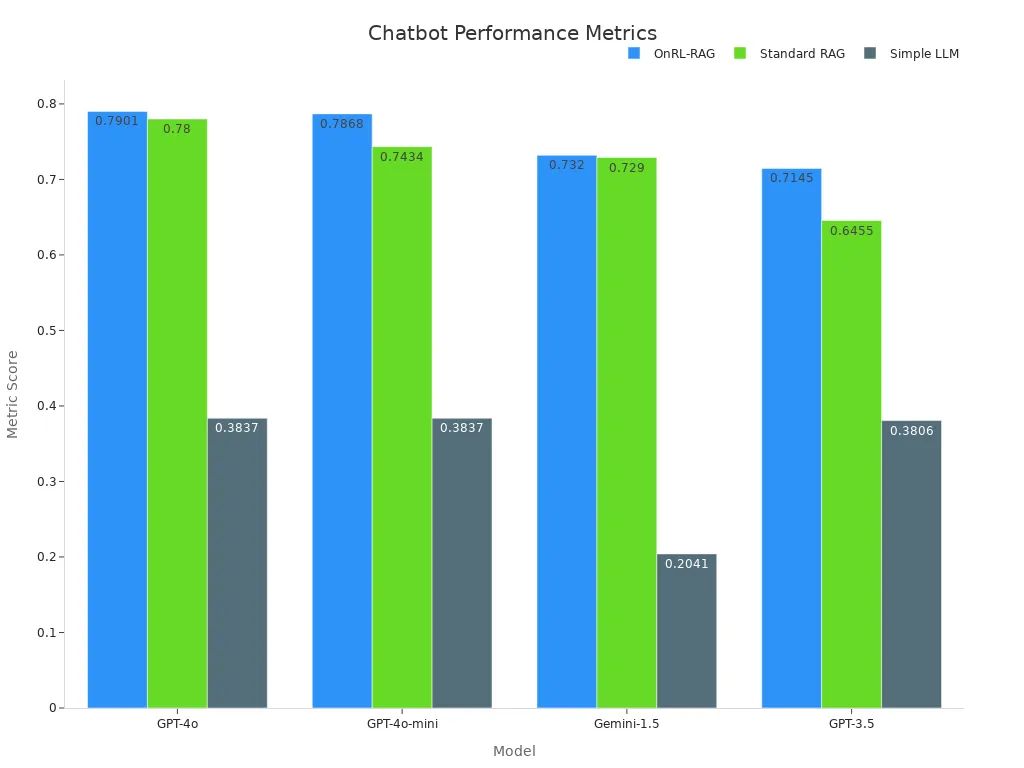
Empirical studies highlight the effectiveness of this approach. For instance, the OnRL-RAG framework consistently outperforms standard RAG and simple LLMs across various models. The table below illustrates the performance metrics:
| Model | OnRL-RAG | Standard RAG | Simple LLM |
|---|---|---|---|
| GPT-4o | 0.7901 | 0.7800 | 0.3837 |
| GPT-4o-mini | 0.7868 | 0.7434 | 0.3837 |
| Gemini-1.5 | 0.7320 | 0.7290 | 0.2041 |
| GPT-3.5 | 0.7145 | 0.6455 | 0.3806 |
 Source de l'image : Pexels
Source de l'image : Pexels
Retail chatbots using RAG and RL also enhance operational efficiency by reducing response times. These systems adapt dynamically to user needs, ensuring a seamless customer experience.
Améliorer les Moteurs de Recherche avec RAG et RL
Search engines benefit significantly from the integration of RAG and RL. RAG enhances the retrieval process by accessing relevant data from vast repositories, while RL optimizes search algorithms to improve accuracy and relevance. This synergy enables search engines to deliver precise results, even for complex queries.
The ReZero framework exemplifies this improvement. It rewards persistence in search attempts, achieving a peak accuracy of 46.88%, compared to a baseline of 25%. The table below highlights this performance:
| Model | Accuracy (%) | Baseline (%) |
|---|---|---|
| ReZero Model | 46.88 | 25.00 |
By leveraging RL, search engines refine their algorithms to prioritize user intent. This approach ensures that users receive the most relevant information, enhancing their overall experience. Additionally, tools like Pinecone facilitate efficient retrieval, enabling search engines to handle large-scale data queries with ease.
Systèmes de Gestion des Connaissances en Entreprise
Enterprises rely on knowledge management systems to streamline operations and improve decision-making. RAG and RL enhance these systems by enabling dynamic retrieval and generation of information. RAG retrieves relevant data from internal and external sources, while RL aligns outputs with organizational goals.
For example, a major bank's digital assistant uses RAG to fetch regulatory information, ensuring compliance and improving customer interactions. Similarly, healthcare organizations utilize RAG systems to access medical guidelines and research, enhancing clinical decision support. Pinecone plays a crucial role in these applications by enabling efficient similarity search and retrieval.
Multi-agent collaboration further enhances scalability in enterprise systems. Agents work together to refine retrieval and generation processes, ensuring that users receive accurate and actionable insights. This approach transforms knowledge management, making it more adaptive and efficient.
Integrating RL scaling with RAG transforms AI systems by enhancing their accuracy, robustness, and adaptability. This synergy allows models to retrieve real-time knowledge, improving decision-making and performance across diverse tasks. For example:
| Key Benefit | Description |
|---|---|
| Improved Accuracy | Enhanced precision in data retrieval and response generation. |
| Robustness | Increased resilience of AI systems in dynamic environments. |
| Generalization Capabilities | Better performance across diverse datasets and complex tasks. |
Tip: Explore RL scaling to unlock the full potential of your AI models. Combining RAG with RL offers a powerful framework for knowledge-intensive applications.
FAQ
Quelle est la différence entre RAG et la mise à l'échelle RL ?
RAG récupère des données pertinentes et génère des sorties contextuellement précises. La mise à l'échelle RL optimise les modèles IA en améliorant leur efficacité d'apprentissage et adaptabilité. Ensemble, ils améliorent les performances en combinant la récupération de connaissances en temps réel avec l'apprentissage par renforcement pour une meilleure prise de décision.
RAG peut-il être utilisé avec n'importe quel modèle de base ?
Oui, RAG fonctionne avec la plupart des grands modèles de langage (LLM). Les choix populaires incluent Llama et Qwen en raison de leur adaptabilité. Les développeurs doivent s'assurer que le modèle de base supporte les tâches de récupération et génération pour une intégration transparente.
Comment la mise à l'échelle RL améliore-t-elle les systèmes IA ?
La mise à l'échelle RL améliore les systèmes IA en raffinant leur processus d'apprentissage. Elle utilise des mécanismes de rétroaction dynamiques pour aligner les sorties avec les objectifs désirés. Cette approche améliore la précision, la stabilité et l'évolutivité, surtout dans des environnements complexes.
Quels outils sont essentiels pour implémenter RAG et RL ?
Les outils clés incluent Pinecone pour la récupération efficace de données, VeRL pour l'entraînement RL, et des algorithmes PPO modifiés pour l'optimisation. Ces outils rationalisent les flux de travail et garantissent de hautes performances pendant la mise à l'échelle.
Les systèmes multi-agents sont-ils nécessaires pour la mise à l'échelle RL ?
Les systèmes multi-agents ne sont pas obligatoires mais hautement bénéfiques. Ils améliorent l'évolutivité et la spécialisation des tâches. Les agents collaborent pour raffiner les processus de récupération et génération, améliorant l'efficacité globale du système.