Le RAG n'est pas mort, le RAG agentique est tout simplement meilleur
27 novembre 2025Guanqun @puppyone
TL;DR : Voici un projet open source : https://github.com/puppyone/DeepWideResearch
Il remplace les pipelines RAG fragiles par des flux de travail agentiques, résolvant le cauchemar de la maintenance et la chute de qualité.
Le compromis est réel : le RAG agentique coûte plus cher (> 0,1 $/requête contre ~0,01 $ pour le RAG traditionnel) et est plus lent (> 10 s+ contre moins de 3 s). Si vous avez besoin de réponses en moins d'une seconde à grande échelle, cette solution n'est pas pour vous. Mais si vous cherchez un système de questions-réponses (QA) sur une base de connaissances qui soit précis et maintenable, continuez votre lecture.
Je vais partager notre expérience dans la construction de la nouvelle architecture de RAG agentique et expliquer pourquoi le RAG agentique est l'étape cruciale pour les systèmes de QA sur les connaissances d'entreprise.
Au cours de l'année écoulée, j'ai mené à bien 5 projets de RAG traditionnel, chacun portant sur 100 à 1000 pages de documentation. La stack technique était standard : réécriture de requête, routage de requête, segmentation, plongement, reclassement, etc. Au début, tout se passait bien, mais nous sommes vite tombés dans un piège : l'ensemble du processus était extrêmement rigide et difficile à maintenir.
La prise de conscience la plus douloureuse est venue d'une modification de document. Un simple changement a fait chuter le score global du RAG. Pour maintenir le même score, nous avons dû reconstruire toute notre stratégie de pipeline à partir de zéro. Chaque nouvelle source de données donnait l'impression de mener une nouvelle bataille. Nous avons essayé de corriger le tir avec un étiquetage complexe des métadonnées et une segmentation affinée, mais ce n'étaient que des pansements sur une architecture défaillante.
Nous avons commencé à nous demander : Qu'est-ce qu'on fait de mal ?
Le problème venait de la logique. Le RAG traditionnel consiste essentiellement à écrire des règles if-else en dur pour s'adapter à un jeu de données. Cela fonctionne pour du code statique, mais ça casse dès qu'on a besoin d'une véritable intelligence.
Inspiré par le projet Deep Research d'OpenAI, j'ai décidé d'abandonner le pipeline rigide.
Je suis passé à une architecture agentique + MCP (Model Context Protocol). L'idée est simple : au lieu d'une chaîne de récupération complexe, nous donnons à l'agent des outils pour interroger directement chaque source de données.
Voici l'architecture du système :
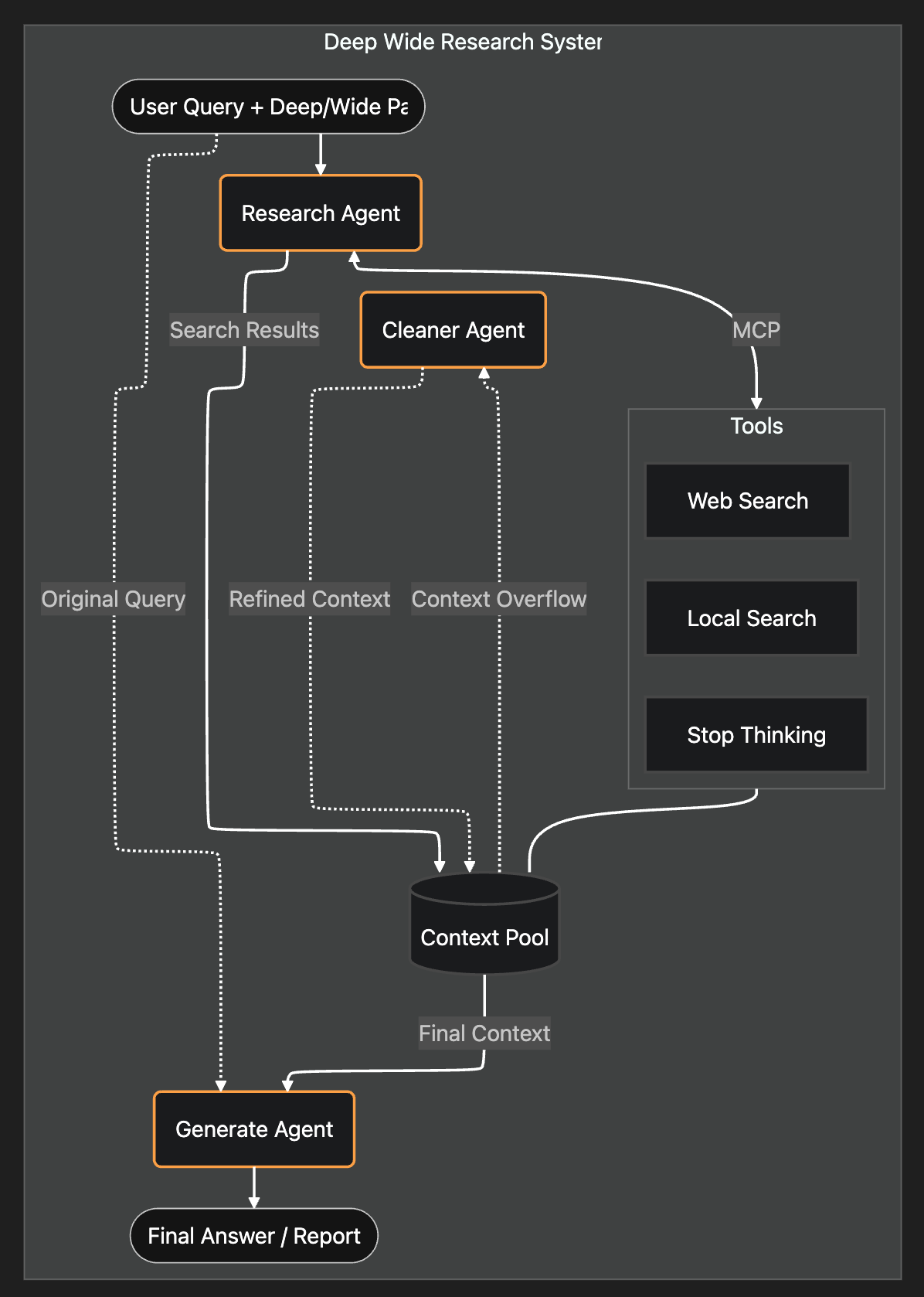
1. Comment construire l'agent de recherche ?
Le RAG agentique remplace l'intégralité du pipeline de récupération par un unique agent de recherche autonome.
Au lieu de coder en dur des règles de réécriture ou de routage, j'ai mis en place deux agents : un Chercheur (Researcher) et un Générateur (Generator).
J'ai donné au Chercheur trois outils simples :

<Stop_thinking><Web_search><Local_search>
Mais donner des outils à un agent ne suffit pas. Il faut lui dire quand s'arrêter.
Au lieu d'une bête boucle while ou d'un nombre d'étapes fixe, j'ai forcé l'agent à exécuter une étape d'auto-réflexion avant chaque action.
Nous n'utilisons pas une simple boucle ou un compteur d'itérations. À la place, nous forçons l'agent à s'auto-évaluer avant chaque action à l'aide d'une « Vérification de la préparation de l'article » :
## Vérification de la préparation de l'article :
- Pourrais-je écrire une réponse et un article complets et détaillés MAINTENANT ? (Oui/Non)
- Si je l'écrivais maintenant, quelles sections seraient faibles, vagues ou manqueraient d'exemples/données concrètes ?
- Ai-je assez de faits, de chiffres, d'exemples spécifiques pour étayer chaque affirmation ?
Ce n'est que lorsque cette vérification est réussie que l'agent appelle <Stop_thinking>. Nous avons testé cela avec les modèles SOTA (Gemini 3 pro / Claude 4.5 Opus / GPT-5), et ils ont suivi la logique à la perfection.
Tous les résultats de recherche sont stockés dans un pool de contexte partagé. Une fois que le Chercheur signale « Stop », un agent Générateur récupère le pool de contexte et rédige la réponse finale.
Les résultats dépassent tous les pipelines que nous avons construits jusqu'à présent. C'est l'intelligence qui l'emporte sur la structure rigide.
Nous avons essentiellement fait correspondre les composants traditionnels du RAG à des comportements d'agent dynamiques :
- Routage de requête ? -> L'agent choisit le bon outil.
- Réécriture de requête ? -> L'agent remplit les arguments de la fonction.
- QA multi-sauts ? -> L'agent décide quand appeler
<Stop_thinking>.` - Reclassement -> L'agent génère la réponse en se basant sur le pool de contexte.
2. Gérer le débordement de contexte
J'ai rencontré un deuxième problème : que se passe-t-il lorsque le contexte recherché devient trop long ?
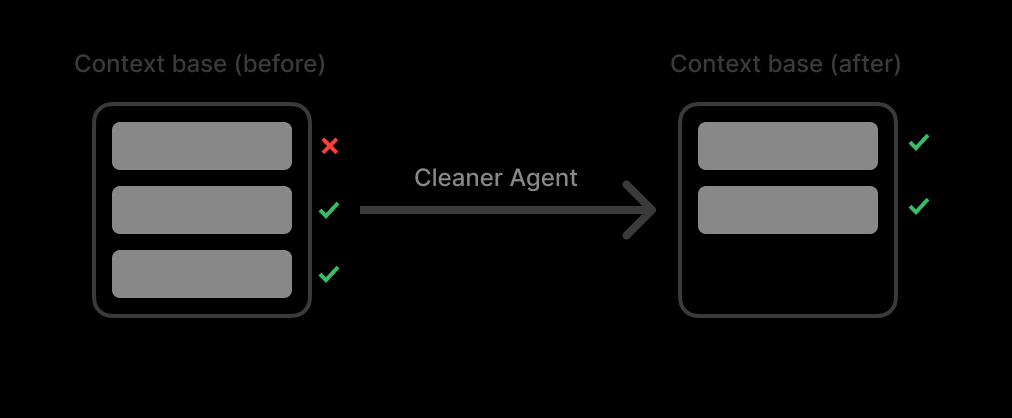
J'ai créé un pool de contexte. Ce pool fonctionne comme une liste de tous les résultats de recherche. J'ai conçu un agent Nettoyeur pour nettoyer le contexte lorsque le pool de contexte atteint le seuil (90 % du nombre maximum de tokens).
L'astuce est la suivante : ne pas résumer. La synthèse tue les détails.
Au lieu de cela, l'agent Nettoyeur fonctionne comme un filtre à déchets. Il supprime entièrement les sources non pertinentes tout en gardant les sources pertinentes 100 % originales et intactes.
Enfin, un agent Générateur produit la réponse finale en se basant sur le contenu affiné du pool de contexte et la requête d'origine.
3. La solution « Deep-Wide » pour le coût et la latence
J'ai rapidement fait face à un troisième défi : la barrière du coût et de la latence.
Soyons honnêtes sur les chiffres :
- Latence : Le RAG agentique a un plancher incompressible d'environ 10 secondes — la boucle de raisonnement est le goulot d'étranglement, et nous ne pouvons pas descendre en dessous. Le RAG traditionnel peut répondre en moins de 3 s.
- Coût : Avec GPT-5, attendez-vous à environ 0,05 $-1 $ par requête. Le RAG traditionnel avec des embeddings coûte environ 0,005 $-0,01 $.
Pour rendre ce compromis contrôlable au-dessus de ce plancher, j'ai introduit la « Recherche Deep-Wide » (en profondeur et en largeur) :
- Deep (Profondeur) : Contrôle les étapes de raisonnement itératif. Varie d'environ 10 s (minimum) à plus de 5 minutes (profondeur maximale pour des rapports complets).
- Wide (Largeur) : Contrôle l'expansion parallèle des requêtes. Plus de largeur = plus de sources explorées = coût en tokens plus élevé.
PROFONDEUR × LARGEUR ≈ Coût. En ajustant ces deux dimensions, vous pouvez contrôler le temps de réponse (10 s ~ 5 min), la qualité et le coût — mais vous ne pouvez pas descendre sous le plancher des 10 s.
Nous avons mis en open source DEEP WIDE RESEARCH. URL du projet : https://github.com/puppyone/DeepWideResearch (Licence Apache)
Ce que cela ne résout pas
Ce projet s'attaque à la moitié du problème du RAG agentique : le côté « Raisonnement et Recherche ».
L'autre moitié, la gestion des données privées d'entreprise, n'est pas résolue ici :
- Nettoyer les documents d'entreprise désordonnés
- Construire des index optimisés pour la consommation par l'agent
- Contrôle granulaire des permissions
Nous travaillons sur ce point séparément. Si vous rencontrez ces problèmes ou si vous avez des idées, j'adorerais en discuter avec vous : [email protected]