コンテキストエンジニアリング:RAGだけでは不十分な場合
2026年2月10日Ollie @puppyone
要点
- コーパスが小さく、質問がローカルで、ガバナンスが軽い場合は基本RAGで十分。それを超えると専用のコンテキストレイヤーが必要。
- コンテキストレイヤーは知識を構造化Know‑How(JSON/グラフ)に再形成し、ハイブリッド索引(dense + sparse + graph)と組み合わせ、出所、ACL、バージョン管理で統制する。
- グラフ・ツリー強化検索は、ベクトルのみのRAGが横断ドキュメント・グローバルクエリで苦戦する穴を埋める。Microsoft ResearchのGraphRAG(2024)を参照。
- サブエージェントオーケストレーションと厳格な要約バジェットで、コンテキストを高シグナルでテスト可能に保つ。Anthropicの効果的コンテキストエンジニアリングに関するガイダンスと一致。
- ガバナンスはオプションではない。NISTのAI RMFは、信頼できるシステムの中心に出所とライフサイクル制御を据える。
逆説的判断基準:RAGで十分か vs. コンテキストレイヤーが必要か
シンプルに始め、時期尚早なインフラに抵抗する。次の場合はコンテキストレイヤーは不要の可能性が高い:
- コーパスが小さく、ほぼ静的に一〜二システムに存在する。
- 質問がローカルで単一ホップ(例:「製品Xの保証は?」)。
- レイテンシSLOが柔軟で、 occasionalな見逃しを許容できる。
- ガバナンスが軽く、監査可能なトレースや厳格なACLが不要。
専用のコンテキストレイヤーが必要になるのは:
- データがDocs、Slack、Notion、DB、外部SaaSに分散し、頻繁に変動する。検索企業もコネクターに投資。PerplexityによるCarbon買収2024参照:Perplexity welcoming Carbon。
- エージェントがグローバルや横断ドキュメントの質問に答え、マルチステップワークフローを計画する必要がある。ベクトルのみの検索はここで破綻。MicrosoftチームがarXiv 2024でグラフ強化戦略を概説:A Graph RAG approach to query‑focused summarization。
- 出所、アクセス制御、バージョン管理、ロールバックが必要。 NIST AI Risk Management FrameworkのGOVERN関数に合致。
- 決定論とテスト可能性が重要:再現可能なコンテキストアセンブリ、説明可能な検索トレース、コンテキスト更新のCI。Anthropicのサブエージェントと厳格なコンテキスト衛生の指針を参照:Effective context engineering for AI agents。
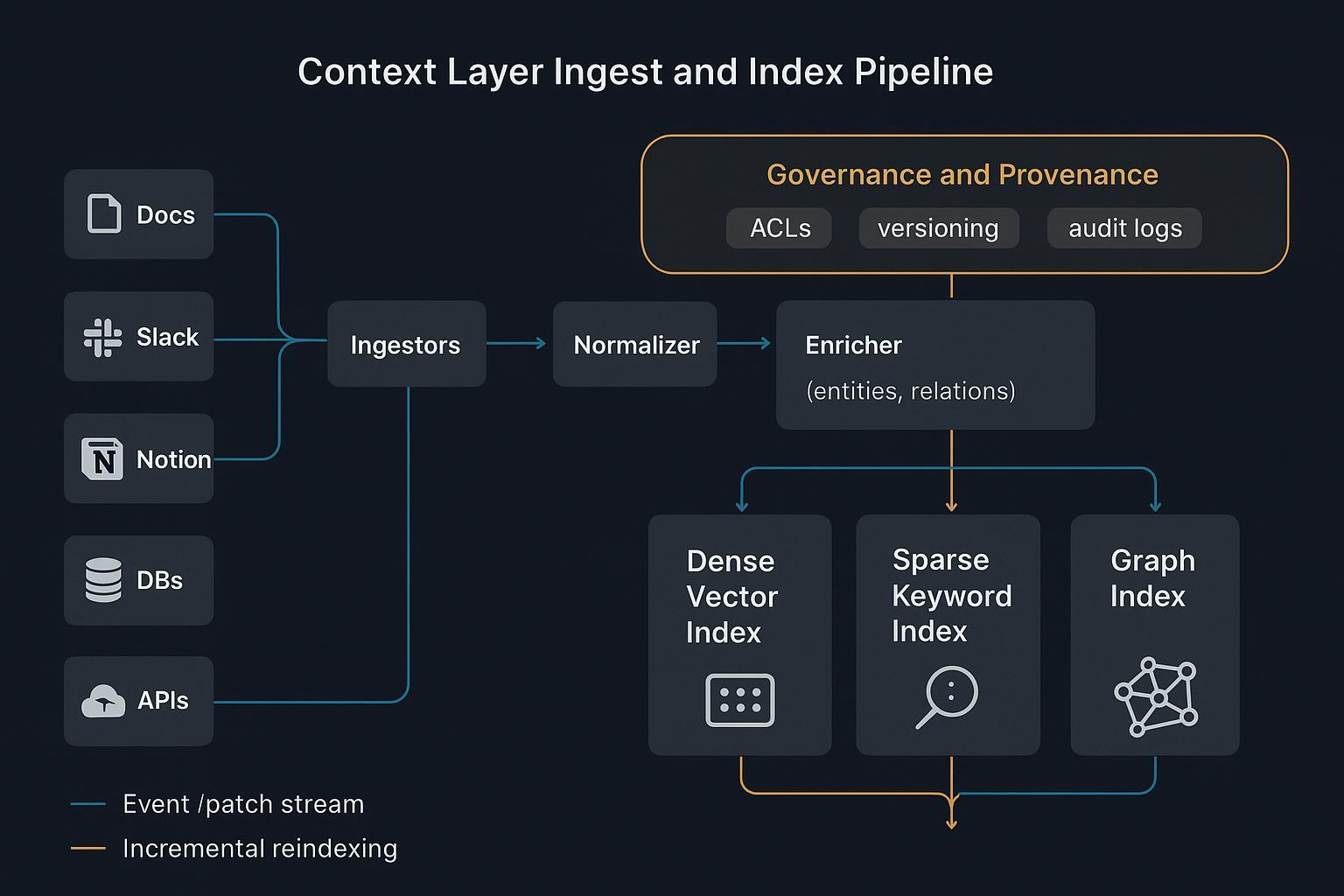
RAGを超えるコンテキストエンジニアリングアーキテクチャ
構造化Know‑Howとスキーマ
非構造化HTMLはマシンにとってノイズ。コンテキストレイヤーは手順、エンティティ、制約、ビジネスルールを構造化Know‑Howに変換する:明確なスキーマを持つJSONドキュメントとグラフ:
{
"entity": "PurchaseOrder",
"id": "PO-2026-1783",
"vendor": {"name": "Acme", "id": "V-882"},
"line_items": [
{"sku": "X12", "qty": 5, "unit_price": 49.00}
],
"approval_policy": {
"threshold": 10000,
"requires_dual_signoff": true,
"exceptions": ["emergency"]
},
"provenance": {"source": "ERP", "version": "v14.2", "ingested_at": "2026-02-06"}
}
このスキーマ化されたコンテキストにより、エージェントはもろいテキストスパンに依存せず、マシン可読なロジックと監査可能性のための出所を得る。
ハイブリッド索引とルーティング
- 密な意味検索でトピック類似性を素早く発見。
- 疎な語彙索引で正確な用語、ID、ポリシー言語を保持。
- グラフ/ツリー構造でマルチホップ推論のための関係と階層を符号化。
合わせて決定論的検索を可能にする:クラスタやグラフ近傍でルーティングし、最小・関連コンテキストを stitch。Weaviate best practices for hybrid search参照。
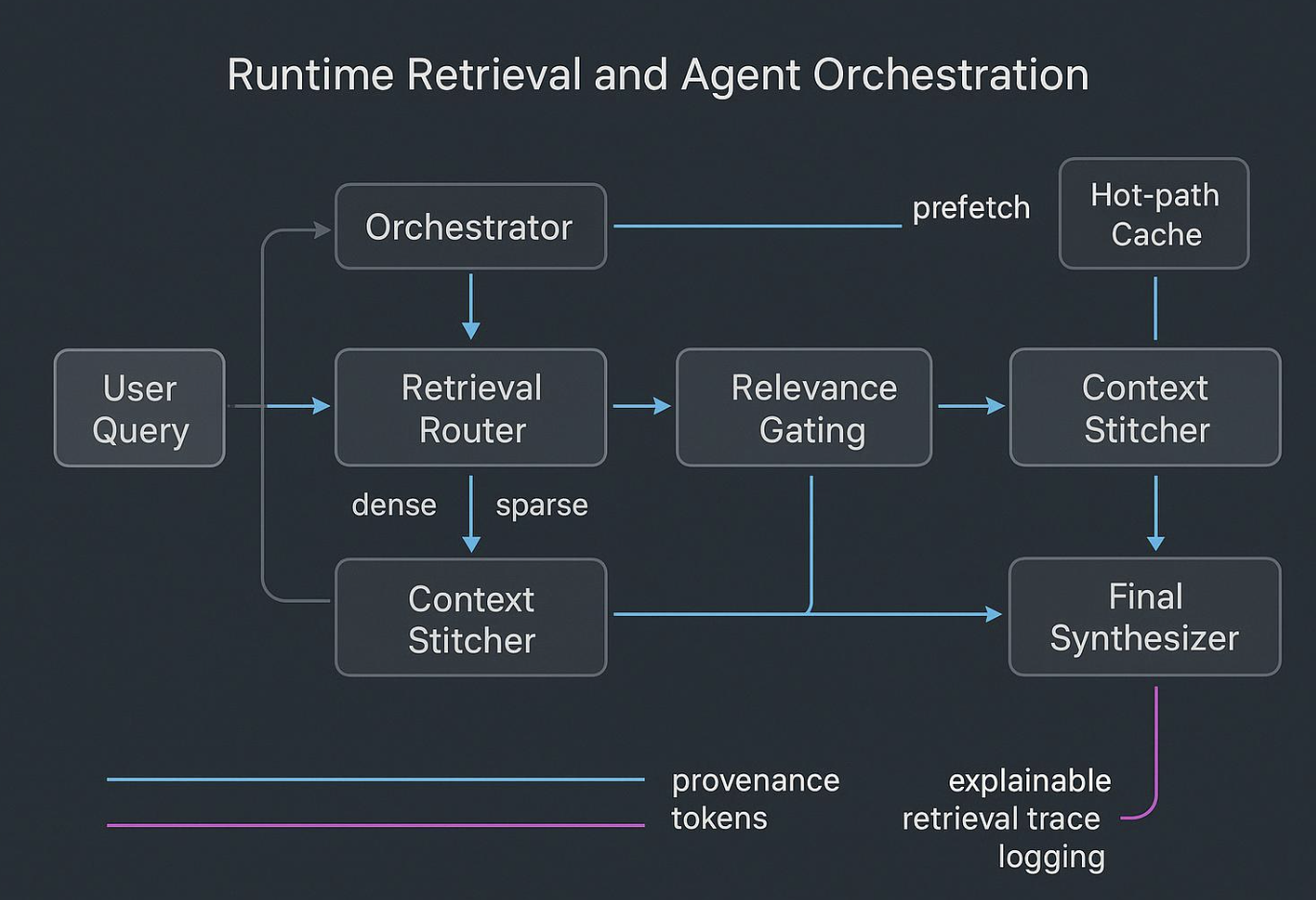
ランタイムステッチングとオーケストレーション
エージェントは生のノイズだらけのダンプを「考え」ようとすると失敗する。ランタイムは次のようであるべき:
- プランナーが必要な証拠とツールを仮説化。
- ルーターがクエリをdense、sparse、graphインデックスに分散。
- ゲートが出所とポリシーでフィルタ;ステッチャーがコンパクトで明確な境界のバンドルを構成。
- サブエージェントが狭いタスクを実行し、シンセサイザーに厳格な要約を返す。
# ハイブリッド検索+ステッチの疑似コード
plan = planner.make_plan(user_query)
results = []
for hop in plan.hops:
dense = dense_index.search(hop.query, k=10)
sparse = sparse_index.search(hop.query, k=10, filter=plan.filters)
graph_ctx = graph.walk(hop.entities, depth=2)
gated = gate.by_provenance(dense + sparse + graph_ctx)
stitched = stitch.compact(gated, budget_tokens=1200)
results.append(stitched)
final = synthesize(results, tools=plan.tools)
return final
コンテキストパイプラインチェックリスト
- ソースをインジェスト → 正規化 → スキーマにマップ。
- エンティティと関係でエンリッチ → 構造化Know‑Howとして格納。
- 出所メタデータ付きでハイブリッド索引(dense、sparse、graph)を構築。
- ACL、バージョン管理、監査ログでゲート。
- デプロイ前に検索忠実度とタスクレベルの成果を評価。
- ホットパスキャッシュとプリフェッチでデプロイ。
- レイテンシ、適合率/再現率、ドリフト、監査トレースを監視。
軽量マイクロベンチマーク:レイテンシ vs. 回答品質
この設計で3つの検索パターンを比較できる。小さく再現可能に保つ。
前提:5万ドキュメント(ポリシー、チケット、製品仕様);75の評価クエリ、うち40にground truth;同一LLM;ハードウェア同等;該当箇所でreranker。p50/p90中央値レイテンシとEM/F1または文書化LLMジャッジで品質を報告。
| パターン | 検索スタック | 期待特性 |
|---|---|---|
| ナイーブRAG | Denseのみ | 高速、グローバル一貫性は低め;横断ドキュメントで苦戦 |
| チューニングRAG | Dense + sparse + reranker | 中程度レイテンシ、ID・ポリシー用語で精度向上 |
| コンテキストレイヤー | Hybrid + graph + stitch + summaries | p50レイテンシはやや高めだがp90は絞れる;より安定したグローバル回答 |
解釈:チューニングRAGは多くの簡単な見逃しを修正;コンテキストレイヤーは横断ドキュメント・マルチステップタスクで光り、ルーティングとキャッシュでテイルレイテンシがより予測可能になる。
障害モードと緩和
- ドキュメント間の断片化:エンティティ/関係グラフを構築し、局所/グローバルトラバーサルで一貫バンドルを収集;長いナラティブに階層的アンカーを追加。
- 陳腐化とドリフト:イベントソースインジェスト、増分再索引、TTL;スキーマアップグレード時に changelog をリプレイ。
- 負荷時のレイテンシスパイク:段階的ホットパスキャッシュ、クラスタルーティング、よくあるサブクエリのプリフェッチ;シャードサイズ調整、可能な箇所で量子化。
- ノイズコンテキストによる幻覚:スキーマと出所フィルタを強制;サブエージェントスコープを狭く;生ダンプよりコンパクト要約を優先。
- ガバナンスギャップ:検索トレースとツール呼び出しをログ;説明可能な証拠ラインを要求;評価閾値とロールバック計画でデプロイをゲート。
実践マイクロ例:構造化Know‑Howとハイブリッド索引の実践
購入エージェントを構築し、ベンダー見積もりを集めながら承認ポリシーを適用する想定。ERPエクスポート、契約PDF、Slack承認、メール要約をインジェスト。インジェストパイプラインは共通スキーマ(PurchaseOrder、Vendor、Policy、Exception)にマップ。エンティティリンクでエンリッチし、各PurchaseOrderがVendorと該当Policyノードを把握。次にdense索引で意味的リコール、sparse索引でIDと法的用語、graph索引でPolicy→Exception→Approver経路をナビゲート。
このセットアップで、オーケストレーションループは「PO‑2026‑1783を本日承認可能か?」のクエリを:PO IDのsparseルックアップ、そのPOからPolicyと例外へのグラフウォーク、直近承認者ノートのdense検索でルート。ステッチャーは1.2Kトークンバンドルに圧縮し、エージェントは承認決定と出所リンク付きの簡潔な引用回答を生成。
Puppyoneのようなプラットフォームは、知識を構造化Know‑How(JSON/グラフ)として格納し、テキストと構造のハイブリッド索引をサポートするため役立つ。その組み合わせで、もろいテキストスクレイピングに依存せず、決定論的検索パターンと監査可能なトレースが可能になる。
コンテキストのガバナンスとCI
コンテキストをコードのように扱う。変更ごとに出所、レビュー、テストを。バージョン管理されたスキーマ、アクセスポリシー、評価スイートを維持。ロールアウト前に検索忠実度チェックとタスクレベルテストを実行;説明可能トレースをキャプチャしロールバックを準備。エージェントが規制・機密データに触れる場合、NIST AI Risk Management FrameworkのGOVERNに合わせる。相互運用:Model Context Protocol。
次のステップ
問題がローカルで低リスクなら、チューニングRAGから始める。横断ドキュメントの質問、ガバナンスニーズ、変動コーパスが見えたら、1ワークフローに焦点を当てたコンテキストレイヤーパイロットを計画。まず構造化Know‑Howを構築;スキーマが安定すればハイブリッド索引とオーケストレーションは大幅に簡素化。評価を厳格かつ人間的に:実タスクをテスト、トレースをログ、改善をビジネスSLOに結びつける。
FAQs
Q1: すぐにグラフが必要か?
A: いいえ。まずdense + sparse;横断ドキュメント推論やグローバル要約のギャップが出たらグラフを追加。
Q2: チャンクのサイズは?
A: スキーマに紐づく意味単位(エンティティ、手順)でチャンク。固定トークン数ではなく。リランカーと要約に残りを任せる。
Q3: ガバナンスは後回しにできるか?
A: できるが、代償を払う。評価とロールバックを可能にするため、初日から軽い出所とアクセス制御を追加。