カスタマーサービス自動化のための Agentic RAG 導入ガイド
2026年4月8日Lin Ivan
カスタマーサービスは LLM にとって厳しい環境です。曖昧な質問、古いドキュメント、機密データ、そして誤答がそのままユーザーに見えてしまうからです。
本番負荷に耐えるサポート自動化を作りたいなら、単なる RAG デモでは足りません。必要なのは、問い合わせをルーティングし、正しい証拠を集め、安全にツールを使い、確信が持てないときは適切にエスカレーションする agentic なシステムです。
まず「自動化」とは何かを定義する
多くのチームは最初に chatbot を作ろうとします。先にやるべきなのは、どの workflow を自動化するのか、そして各 workflow における「完了」をどう定義するのかを決めることです。
導入モードを選ぶ
現実的な出発点は次のいずれかです。
- Agent-assist: システムは回答案と evidence bundle を用意し、人間が送信する。
- 部分自動化: パスワード再発行や請求状況確認など、低リスクな intent を自動処理する。
- 拡張自動化: 大半の intent を自動化するが、それは十分な検証後に限る。
「絶対に自動化しない」境界を決める
少なくとも次は denylist に入れるべきです。
- しきい値を超える金銭処理
- アカウント所有権の変更
- データエクスポート
- 規制対象または高リスクな業務
これらは 即エスカレーション でよいケースです。
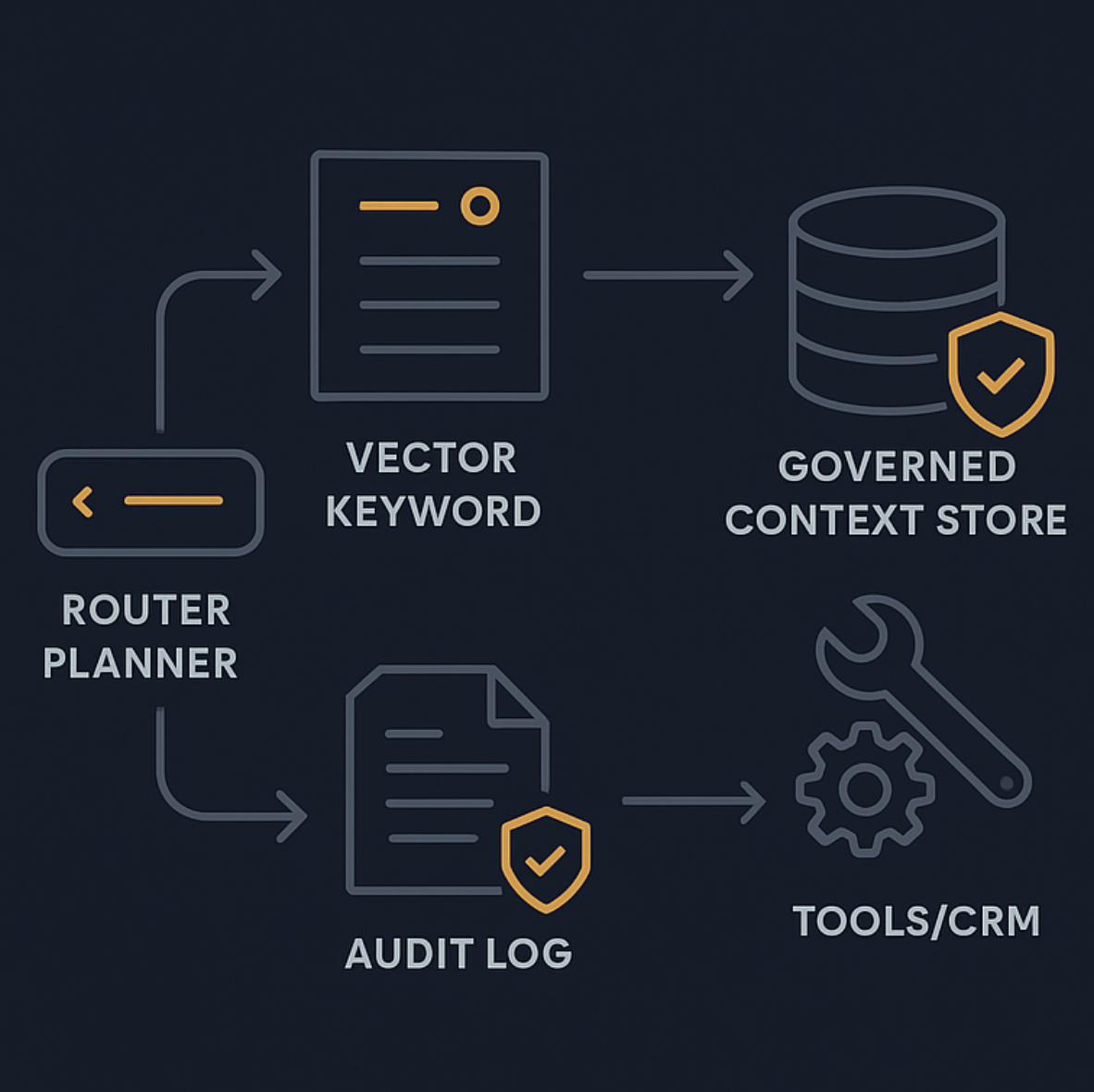
参照アーキテクチャ: サポート向け Agentic RAG
本番構成は一本の pipeline ではありません。guardrail を持つ decision system です。
考え方としては、Adaline Labs の production-ready agentic RAG architecture and observability でも触れられているように、orchestration、execution、infrastructure の三層で考えると整理しやすくなります。
Orchestration: router と policy engine
この層は次に何をするかを決めます。
- FAQ、billing、account access、outage などの intent classification
- retrieval が本当に必要かの判断
- CRM や order system、ticketing などの tool 選択
- エスカレーションルールや「絶対に自動化しない」境界の適用
Execution: retrieval、tool call、response synthesis
この層で実作業を行います。
- retrieval query を作る
- hybrid retrieval と reranking で証拠を集める
- least privilege で tools を呼ぶ
- 取得した証拠に基づいて回答を作る
retrieval 結果は untrusted input として扱うべきです。
Infrastructure: observability、evaluation、reliability
本番には少なくとも次が必要です。
- routing、retrieval、tool call ごとの trace
- grounding を評価する signal
- retries、timeouts、fallbacks
どの証拠を使い、なぜその判断や操作に至ったのかを説明できないなら、本番運用にはまだ早いです。
データと retrieval の前提条件
ドキュメントが散らかっていれば、モデルは自信満々に間違えます。
1. サポート向け知識コーパスを作る
最小でも次のようなソースが必要です。
- 公開ヘルプセンター
- 範囲を絞った内部 runbook
- refund、cancel、SLA に関する policy
- product changelog
2. コンテキストを壊さない chunking を選ぶ
多くの RAG 実装は chunking で静かに失敗します。
セマンティックな区切りを優先し、各 chunk に見出しや要約などの contextual header を付けるのが実務的です。参考として best practices for chunking and hybrid retrieval in production RAG があります。
3. Hybrid retrieval と reranking を使う
サポート問い合わせは、エラーコードのような正確な文字列と、ぼんやりした意図を混ぜて投げてきます。
そのため一般に有効なのは次の組み合わせです。
- keyword search で ID や exact term を拾う
- vector search で言い換えを拾う
- reranking で最終候補を整える
4. freshness と ownership のメタデータを付ける
最低限ほしい項目は次の通りです。
- source type
- 最終更新時刻
- owner または担当 team
- product / version tag
- sensitivity classification
カスタマーサービス自動化に Agentic RAG を導入する手順
各ステップには目的、出力、done 条件が必要です。
Step 1: intent router を入れ、必要なときだけ retrieval する
Action: 問い合わせを少数の workflow に分類する intent classifier を作る。
Done when:
- request ごとに選ばれた intent を記録できる
- retrieval が発火した割合を測定できる
Step 2: least privilege で tool boundary を切る
Action: intent と risk ごとに tool access を分ける。
例:
- billing status workflow は invoice を読めるが refund はできない
- account access workflow は reset link を送れるが ownership は変えられない
- 機密 read と広い write を同じ workflow に無制限で与えない
Step 3: retrieval-time authorization を実装する
multi-tenant 環境では、ここを間違えると致命的です。
最も堅いパターンは、権限を authoritative data source 側で判定し、その identity を retrieval まで伝播させることです。AWS の retrieval-time authorization and identity propagation for RAG が参考になります。
Step 4: retrieved text を untrusted として扱い、間接 prompt injection を防ぐ
knowledge base は一種の supply chain です。
retrieved content に悪意ある指示が含まれていると、システム境界が弱ければモデルはそれに従います。対策としては:
- input と output の sanitization
- system instruction と retrieved content の明確な分離
- 実操作前の確認ステップ
- 監査用ログの保持
Step 5: grounding contract を導入する
モデルには次を要求します。
- 知識質問には retrieved evidence からのみ答える
- source を引用する
- 根拠不足なら拒否またはエスカレーションする
Step 6: verification と escalation を追加する
verifier は少なくとも次を確認します。
- policy と矛盾していないか
- intent と evidence がずれていないか
- denylist に触れる action をしようとしていないか
Governance: versioned context、auditability、安全な協調
context を単なる embeddings の袋として扱うのは、サポートでは危険です。
本番では次を管理できる必要があります。
- 誰が知識を編集したか
- 何が変わったか
- いつ変わったか
- どの version を使ってどの判断が行われたか
agent-readable file、permission scope、versioning、audit log を持つ governed context layer が実務的です。
Evaluation と observability を整えてから広げる
測れないものは改善できません。
最低限見たい指標:
- retrieval quality
- faithfulness
- escalation rate
- p50 / p95 latency
- intent 別コスト
加えて、実際の ticket から eval set を作るべきです。
Rollout: shadow mode から自動化へ
Stage 0: shadow mode
- システムは並行実行するが顧客には返さない
- intents、retrieval、draft、escalation trigger を記録する
Stage 1: agent-assist
- 人間が送信を継続する
- システムは draft と evidence を提示する
Stage 2: 部分自動化
- 狭くて低リスクな intent だけ自動化する
- 高リスクフローは human-gated のままにする
Stage 3: 拡張自動化
各 action を証拠に結びつけて説明でき、knowledge change を rollback でき、tool execution を kill-switch で止められる場合にのみ進めます。
Troubleshooting: よくある失敗
根拠なしで自信満々に答える
- confidence が低いときは拒否させる
- citation を必須にする
- routing を絞る
間違った policy version を拾う
- freshness metadata を使う
- priority rule を入れる
- drift detection と rollback を用意する
retrieved content 由来の prompt injection
- untrusted として扱う
- tool gating を入れる
- system と content を厳密に分ける
生产 latency spike
- 何でも retrieval しない
- 頻出 intent を cache する
- reranking は必要箇所に限定する
Key takeaways
- サポート向け Agentic RAG は router、retrieval、tools、verification、escalation からなる workflow system です。
- 難しいのは authorization、injection defense、evaluation、staged rollout などの運用面です。
- context と decision の両方を versioning・audit できる governance が不可欠です。
Next steps
すでに RAG と tools をつなぎ始めていて、permissions、audit trails、rollback にぶつかっているなら、次を確認してみてください。