AI最適化のためのRAGとRLスケーリング
2025年4月27日Mei @puppyone
 画像出典: Pexels
画像出典: Pexels
強化学習(RL)スケーリングは、適応学習戦略を通じてモデルのパフォーマンスを最適化することでAIを変革します。スケーリング則を活用することで、RLスケーリングは小規模な実験から大規模モデルの振る舞いを予測し、効率的なリソース活用を可能にします。例えば、より長いメモリ長を持つモデルは、ベースラインモデルと比較して最大50%のパフォーマンス向上を示します。
Retrieval-Augmented Generation(RAG)は、データ検索とテキスト生成を組み合わせることでAIシステムを強化します。広大なデータリポジトリから文脈情報を取得し、出力が正確で関連性の高いものであり続けることを保証します。このアプローチは、ディープリサーチやリアルタイムの知識検索などのアプリケーションを大幅に改善します。
RAGとRLの統合は、強力な相乗効果を生み出します。DeepResearcherのようなシステムはこれを示しており、従来の方法と比較して最大28.9ポイント高いタスク完了率を達成しています。文脈情報の検索とRLの最適化を組み合わせることで、AIシステムは多様なドメインで強化されたパフォーマンスを提供します。
主要なポイント
- 強化学習(RL)スケーリングは、AIがより良く、より速く学習するのに役立ちます。
- Retrieval-Augmented Generation(RAG)は、データ検索とテキスト生成を組み合わせます。これにより、結果が正確でトピックに沿ったものになります。
- RAGをRLと併用すると、モデルの動作が大幅に向上します。間違いを69%削減し、意思決定を改善できます。
- RAGでRLスケーリングを使用するには、ベースモデルを選択します。次に、ラベル付きデータでトレーニングし、Pineconeのようなツールを使用してデータを迅速に見つけます。
- RAGとRLを組み合わせることで、多くの分野でAIが向上します。顧客サービス、検索エンジン、知識システムをよりスマートにします。
Retrieval-Augmented Generation (RAG)を理解する
 画像出典: Pexels
画像出典: Pexels
Retrieval-Augmented Generationとは?
Retrieval-Augmented Generation(RAG)は、人工知識における画期的なアプローチです。関連データの検索と文脈的に正確な出力の生成という2つの不可欠なプロセスを組み合わせています。事前学習された知識のみに依存する従来の生成モデルとは異なり、RAGはリアルタイムの情報検索を統合して応答を強化します。この二重のメカニズムにより、出力は一貫性があるだけでなく、事実データに基づいていることが保証されます。
RAGの概念は、Lewisらによる2021年の論文「Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks」などの研究努力を通じて注目を集めました。Guuらによる初期の基礎研究では、事前学習中に知識検索を統合するというアイデアが導入されました。これらの進歩により、RAGは現代のAIアプリケーションの礎となり、システムがより権威があり信頼性の高い結果を提供できるようになりました。
RAGが検索と生成を組み合わせる方法
RAGは、外部情報検索システムを大規模言語モデル(LLM)と並行して活用することで、検索と生成をシームレスに統合します。プロセスは検索フェーズから始まり、システムはデータベースや知識リポジトリなどの外部ソースから関連データを検索します。この検索された情報は、生成フェーズの入力として機能し、モデルは文脈的に正確で意味的に豊かな応答を生成します。
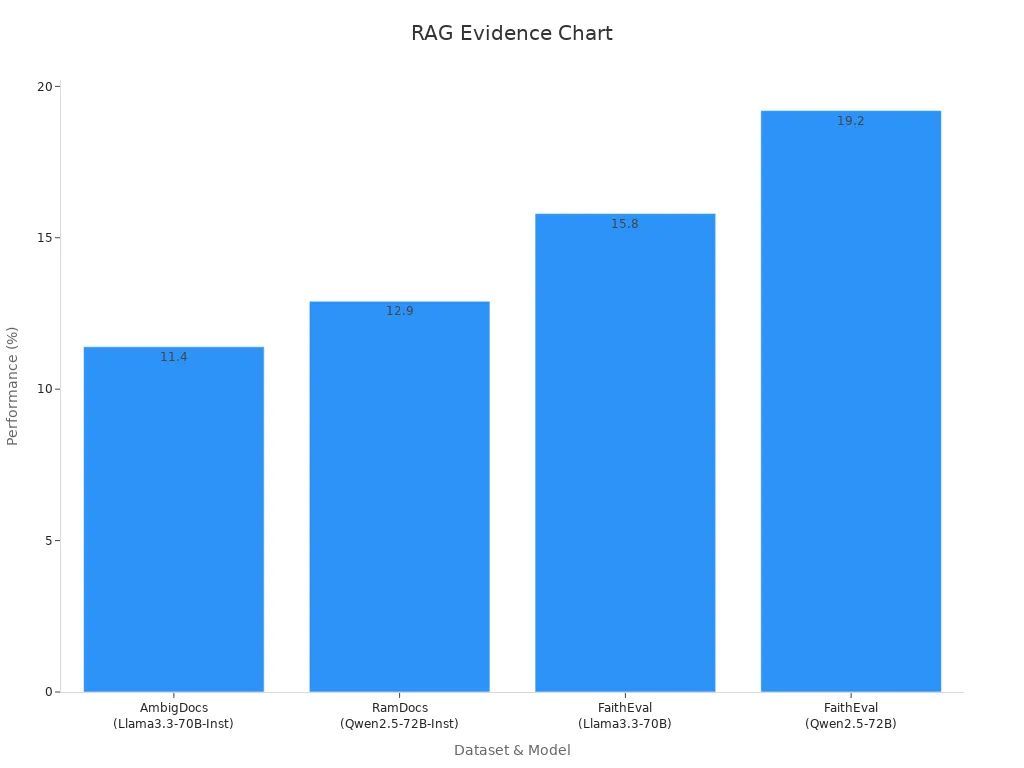
例えば、Madam-RAGモデルは、この組み合わせがさまざまなデータセットでどのようにパフォーマンスを向上させるかを示しています。
| モデル | データセット | パフォーマンス向上 |
|---|---|---|
| Madam-RAG | AmbigDocs | +11.40% (Llama3.3-70B-Inst) |
| Madam-RAG | RamDocs | +12.90% (Qwen2.5-72B-Inst) |
| Madam-RAG | FaithEval | +15.80% (Llama3.3-70B) |
| Madam-RAG | FaithEval | +19.20% (Qwen2.5-72B) |
 画像出典: Pexels
画像出典: Pexels
知識強化のためのRAGパイプラインの利点
RAGパイプラインは、知識集約型タスクを強化するために多くの利点を提供します。情報を動的に検索および生成するその能力により、業界全体で多目的なツールとなっています。主な利点は次のとおりです。
- 顧客サービスインタラクションの改善: RAGはパーソナライズされた正確な応答を提供し、顧客満足度を向上させます。
- コンテンツ作成とコピーライティングの強化: 特定のオーディエンスに合わせた、魅力的で文脈に関連したコンテンツを生成します。
- Eラーニングとバーチャルチュータリングシステムの強化: RAGは教育データベースから適切な説明を取得することで、インタラクティブな学習環境を作成します。
- ヘルスケア診断の革命: 関連する健康記録を取得することで診断を合理化し、正確でタイムリーな診察を可能にします。
- 顧客フィードバック分析: RAGはさまざまなフィードバックソースにアクセスすることでセンチメント分析を加速し、企業が提供内容を改善するのに役立ちます。
RAGの変革的な影響は、これらのユースケースを超えて広がっています。動的な知識検索と生成的精度を融合することで、RAGは業界全体のAIアプリケーションを再構築します。リアルタイムデータと専門知識を活用するその能力は、AIシステムのパフォーマンスと信頼性を大幅に向上させます。予測によると、RAG市場は2035年までに403億4000万ドルに成長し、年間成長率は約35%になるとされています。この成長は、AIの幻覚問題に対処し、コンテンツの関連性を向上させる上でのその重要な役割を強調しています。
RLスケーリングとAIにおけるその重要性
What is RL Scaling?
RL scaling refers to the process of enhancing reinforcement learning (RL) models by increasing their capacity to handle complex tasks. It involves scaling the computational resources, data inputs, and model architectures to improve learning efficiency and adaptability. Unlike traditional scaling methods, RL scaling emphasizes active learning through dynamic interactions and feedback mechanisms.
Key principles of RL scaling include:
- Self-Play Reinforcement Learning (SPRL): This method enables agents to learn by interacting with themselves, fostering active learning through experience.
- The Learning Cycle: Agents observe their environment, act, receive feedback, and adjust their behavior in a continuous loop.
- Redefining Scalability: New scaling laws incorporate the computational cost of exploration, challenging conventional methods.
These principles highlight the transformative potential of RL scaling in advancing AI systems.
Purpose of RL Scaling in AI Models
The primary goal of RL scaling is to enhance the efficiency and adaptability of AI models. Traditional scaling methods often struggle with unstable training dynamics, which can hinder performance. RL scaling addresses these challenges by introducing mechanisms like Soft Mixtures of Experts (MoEs). These mechanisms optimize resource allocation and improve learning outcomes across diverse RL settings.
Empirical studies demonstrate the effectiveness of RL scaling. For instance, the Open Reasoner Zero model achieved performance levels comparable to specialized RL systems by leveraging a base model. This underscores the importance of RL scaling in refining large language models and ensuring they deliver accurate and reliable results.
Benefits of Combining RAG and RL
Integrating RAG with RL creates a robust framework for knowledge-intensive tasks. RAG enhances the retrieval of relevant data, while RL optimizes the learning process. Together, they significantly improve the performance of large language models. Trials have shown a 69% reduction in model loss, decreasing from 0.32 to 0.1. This improvement ensures that users receive precise and contextually accurate information.
The combination of RAG and RL also supports multi-agent systems. These systems enable agents to collaborate, enhancing their ability to perform deep research and solve complex problems. By incorporating retrieval processes into RL workflows, AI systems achieve greater stability and scalability. This synergy highlights the importance of RAG in addressing the limitations of traditional RL methods.
RAGを使用した後のRLスケーリングへのステップバイステップガイド
 画像出典: Pexels
画像出典: Pexels
RAGによるRLスケーリングの前提条件
RAGによるRLスケーリングを実装する前に、スムーズなワークフローを確保するために特定の前提条件を満たす必要があります。これらの前提条件には、以下が含まれます。
- ベースモデル: 検索および生成タスクを処理できる基礎となる大規模言語モデル(LLM)を選択します。LlamaやQwenのようなモデルは、その適応性から一般的に使用されます。
- 知識検索システム: Pineconeベクターデータベースなどの堅牢な検索システムを統合して、エージェントの効率的な類似性検索と動的クエリを容易にします。これにより、生成タスクに関連するデータの取得が保証されます。
- 注釈付きデータセット: 根拠チェーンとして構造化されたクエリ固有のデータセットを準備します。このデータセットは、教師ありファインチューニングとその後のRLアライメントの基盤として機能します。
- 知識セレクター: 取得した情報をフィルタリングするための知識セレクターを実装します。これは、性能の低いジェネレーターモデルや曖昧なタスクで作業する場合に重要になります。
- マルチエージェントコラボレーション: マルチエージェントシステムを確立して、スケーラビリティとディープリサーチ能力を強化します。エージェントは協力して、検索および生成プロセスを改良できます。
これらの前提条件は、効率的なRLスケーリングが可能なRAGエージェントを構築するための基礎を築きます。
RLスケーリングのためのツールとフレームワーク
いくつかのツールとフレームワークがRLスケーリングをサポートし、効率的な実装と最適化を可能にします。主な選択肢は次のとおりです。
- Pineconeベクターデータベース: このツールは効率的な類似性検索に特化しており、関連データの迅速な取得を保証します。エージェントへのクエリ実行と検索精度の向上において極めて重要な役割を果たします。
- VeRLフレームワーク: ByteDanceのVeRLフレームワークは、RLトレーニングのための堅牢な環境を提供します。RAGとRLの統合をサポートし、検索と生成プロセスのシームレスなアライメントを可能にします。
- 修正PPOアルゴリズム: RLスケーリング用に適応された近接ポリシー最適化(PPO)アルゴリズムは、学習ダイナミクスと収束率を改善します。これらの修正は、AtariゲームやBox2Dなどの環境でベンチマークされています。
- 対照的多タスク学習(CML): この手法は、トレーニング中に関連情報と無関係な情報を区別するモデルの能力を強化します。検索プロセスを改良することで、RLアライメントを補完します。
| モデル | 平均精度(%) | 改善(%) |
|---|---|---|
| ToRL-1.5B | 48.5 | - |
| Qwen2.5-Math-1.5B-Instruct | 35.9 | - |
| Qwen2.5-Math-1.5B-Instruct-TIR | 41.3 | - |
| ToRL-7B | 62.1 | 14.7 |
これらのツールとフレームワークは、RAGを活用しながらRLを効率的にスケーリングするために必要なインフラストラクチャを提供します。
RLスケーリングの実装手順
RAGを適用した後のRLスケーリングの実装には、構造化されたアプローチが必要です。最適なパフォーマンスを確保するために、次の手順に従ってください。
- データ収集: 根拠チェーンとして構造化されたクエリ固有の注釈付きデータセットを収集します。このデータセットは、教師ありファインチューニングの基礎を形成します。
- 教師ありファインチューニング(SFT): 収集したデータセットを使用してベースモデルをトレーニングします。このステップにより、モデルの検索および生成能力が向上します。
- 対照的多タスク学習(CML): 関連情報と無関係な情報を区別するモデルの能力を改良します。このステップにより、検索精度と生成品質が向上します。
- RLアライメント: 強化学習技術を使用してモデルをファインチューニングします。フィードバックメカニズムに基づいて、その出力を望ましい結果に合わせます。
- Pineconeとの統合: 効率的な類似性検索のために、モデルをPineconeベクターデータベースに接続します。この統合により、生成タスク中の迅速かつ正確な検索が保証されます。
- マルチエージェントコラボレーション: スケーラビリティとディープリサーチ能力を強化するために、マルチエージェントシステムを導入します。エージェントは協力して、検索および生成ワークフローを最適化します。
- パフォーマンス監視: ナレッジF1や検索精度などのメトリックを使用して、モデルのパフォーマンスを継続的に監視します。効率を維持するために、トレーニングパラメータを調整します。
ヒント:トレーニング中にゴールドナレッジとディストラクタナレッジをブレンドすると、多様な選択結果をシミュレートでき、モデルの適応性が向上します。
これらの手順に従うことで、開発者はRAGによるRLスケーリングを正常に実装し、AIシステムのパフォーマンスとスケーラビリティを向上させることができます。
RAGパイプラインにおけるファインチューニングと最適化
ファインチューニングと最適化は、RAGパイプライン内のモデルのパフォーマンスを向上させる上で重要な役割を果たします。これらのプロセスは、正確で文脈に関連した出力を検索・生成するモデルの能力を洗練させます。しかし、最適な結果を得るには、潜在的な落とし穴を避けるための慎重な計画と実行が必要です。
RAGパイプラインのファインチューニングにおける課題
RAGパイプライン内でのファインチューニングは、モデルのパフォーマンスに影響を与える可能性のある課題にしばしば直面します。例えば、ファインチューニング中にサンプルサイズを増やしても、常により良い結果につながるとは限りません。研究によると、サンプルサイズが大きいと、精度と完全性の両方が低下する可能性があることが示されています。ある実験では、Mixtralモデルの精度が、サンプルサイズが500から1000に増加したときに4.04から3.28に低下しました。これは、ファインチューニングへのバランスの取れたアプローチの必要性を浮き彫りにし、そこではデータの量が質よりも優先されます。
もう1つの課題は、多様なタスクにわたってモデルの汎化能力を維持することです。ファインチューニング中に特定のデータセットに過剰適合すると、モデルの適応性が制限される可能性があります。これは、RAGパイプラインが広範囲のクエリとコンテキストを処理する必要がある知識集約型アプリケーションで特に問題となります。
効果的なファインチューニングのための戦略
これらの課題に対処するために、開発者はいくつかの戦略を採用できます。
- 選択的データサンプリング: 大規模なデータセットを無差別に利用するのではなく、モデルのターゲットタスクに沿った高品質の注釈付きサンプルに焦点を当てます。このアプローチは、パフォーマンス低下のリスクを最小限に抑えます。
- 段階的ファインチューニング: モデルをより小さな段階で徐々にファインチューニングし、学習能力を圧倒することなく適応させます。この方法は、特化と汎化のバランスを維持するのに役立ちます。
- 知識のブレンド: トレーニング中に、ゴールドスタンダードの知識とディストラクタ情報を混ぜ合わせます。このテクニックは、関連データと無関係なデータを区別するモデルの能力を高め、検索精度を向上させます。
RAGパイプラインの最適化技術
最適化により、RAGパイプラインが効率的に動作し、一貫した結果を提供することが保証されます。主なテクニックは次のとおりです。
- 動的検索メカニズム: リアルタイム検索システムを実装することで、モデルは最新情報にアクセスできます。これは、知識が急速に進化するディープリサーチなどのアプリケーションで特に役立ちます。
- マルチエージェントコラボレーション: RAGパイプライン内に複数のエージェントを配置することで、スケーラビリティとタスクの専門性が向上します。各エージェントは、検索または生成の特定の側面に集中でき、システム全体のパフォーマンスが向上します。
- 対照的多タスク学習(CML): このテクニックは、トレーニング中に関連情報を優先するモデルの能力を洗練させます。正解と不正解の検索を対比させることで、CMLはモデルの意思決定能力を鋭敏にします。
ヒント:検索精度やナレッジF1スコアなどのパフォーマンスメトリックを定期的に監視します。これらのメトリックに基づいてトレーニングパラメータを調整し、最適なパフォーマンスを維持します。
ファインチューニングと堅牢な最適化戦略を組み合わせることで、RAGパイプラインは知識集約型タスクで優れたパフォーマンスを達成できます。これらの方法により、アプリケーションの複雑さが増しても、パイプラインは適応性、正確性、効率性を維持できます。
RAGとRLの実用的な応用
カスタマーサポートチャットボットの強化
RAGとRLを搭載したカスタマーサポートチャットボットは、正確で文脈に関連した応答を提供します。検索メカニズムを統合することで、これらのチャットボットはリアルタイムデータにアクセスし、ユーザーのクエリに効果的に対処します。強化学習は、応答をユーザーの好みやフィードバックに合わせることで、そのパフォーマンスをさらに最適化します。この組み合わせにより、チャットボットは正確な情報を提供し、ユーザー満足度を向上させることが保証されます。
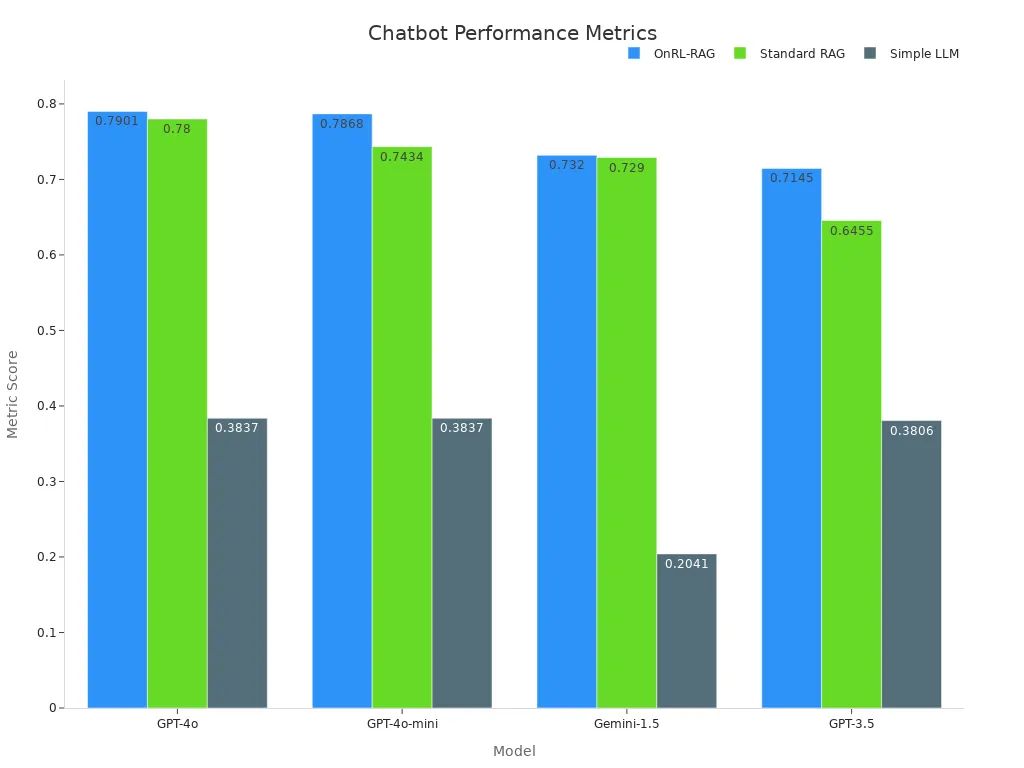
実証研究は、このアプローチの有効性を浮き彫りにしています。例えば、OnRL-RAGフレームワークは、さまざまなモデルで標準的なRAGや単純なLLMを一貫して上回っています。以下の表は、パフォーマンスメトリックを示しています。
| モデル | OnRL-RAG | 標準RAG | 単純LLM |
|---|---|---|---|
| GPT-4o | 0.7901 | 0.7800 | 0.3837 |
| GPT-4o-mini | 0.7868 | 0.7434 | 0.3837 |
| Gemini-1.5 | 0.7320 | 0.7290 | 0.2041 |
| GPT-3.5 | 0.7145 | 0.6455 | 0.3806 |
 画像出典: Pexels
画像出典: Pexels
RAGとRLを使用する小売チャットボットは、応答時間を短縮することで運用効率も向上させます。これらのシステムは、ユーザーのニーズに動的に適応し、シームレスな顧客体験を保証します。
RAGとRLによる検索エンジンの改善
検索エンジンは、RAGとRLの統合から大きな恩恵を受けます。RAGは広大なリポジトリから関連データにアクセスすることで検索プロセスを強化し、RLは検索アルゴリズムを最適化して精度と関連性を向上させます。この相乗効果により、検索エンジンは複雑なクエリに対しても正確な結果を提供できます。
ReZeroフレームワークは、この改善を実証しています。検索試行の持続性を報奨し、ベースラインの25%と比較して、ピーク精度46.88%を達成します。以下の表は、このパフォーマンスを示しています。
| モデル | 精度(%) | ベースライン(%) |
|---|---|---|
| ReZeroモデル | 46.88 | 25.00 |
RLを活用することで、検索エンジンはユーザーの意図を優先するようにアルゴリズムを改良します。このアプローチにより、ユーザーは最も関連性の高い情報を受け取り、全体的な体験が向上します。さらに、Pineconeのようなツールは効率的な検索を容易にし、検索エンジンが大規模なデータクエリを容易に処理できるようにします。
企業におけるナレッジマネジメントシステム
企業は、業務を合理化し、意思決定を改善するためにナレッジマネジメントシステムに依存しています。RAGとRLは、情報の動的な検索と生成を可能にすることで、これらのシステムを強化します。RAGは内部および外部ソースから関連データを取得し、RLは組織の目標に出力を合わせます。
例えば、ある大手銀行のデジタルアシスタントは、RAGを使用して規制情報を取得し、コンプライアンスを確保し、顧客との対話を改善しています。同様に、医療機関はRAGシステムを利用して医療ガイドラインや研究にアクセスし、臨床意思決定支援を強化しています。Pineconeは、効率的な類似性検索と取得を可能にすることで、これらのアプリケーションで重要な役割を果たします。
マルチエージェントコラボレーションは、エンタープライズシステムのスケーラビリティをさらに強化します。エージェントは協力して検索および生成プロセスを改良し、ユーザーが正確で実用的な洞察を確実に受け取れるようにします。このアプローチは、ナレッジマネジメントを変革し、より適応性が高く効率的にします。
RLスケーリングとRAGを統合することで、AIシステムは精度、堅牢性、適応性を向上させることで変革します。この相乗効果により、モデルはリアルタイムの知識を取得し、多様なタスクにわたる意思決定とパフォーマンスを向上させることができます。例:
| 主な利点 | 説明 |
|---|---|
| 精度の向上 | データ検索と応答生成の精度が向上。 |
| 堅牢性 | 動的な環境におけるAIシステムの回復力が向上。 |
| 汎化能力 | 多様なデータセットと複雑なタスクにわたるパフォーマンスが向上。 |
ヒント:AIモデルの潜在能力を最大限に引き出すために、RLスケーリングを探求してください。RAGとRLを組み合わせることは、知識集約型アプリケーションのための強力なフレームワークを提供します。
FAQ
RAGとRLスケーリングの違いは何ですか?
RAGは関連データを取得し、文脈的に正確な出力を生成します。RLスケーリングは、学習効率と適応性を向上させることでAIモデルを最適化します。これらを組み合わせることで、リアルタイムの知識検索と強化学習を組み合わせて、より良い意思決定を行うことでパフォーマンスが向上します。
RAGはどのベースモデルでも使用できますか?
はい、RAGはほとんどの大規模言語モデル(LLM)で動作します。人気のある選択肢には、適応性があるためLlamaやQwenが含まれます。開発者は、シームレスな統合のために、ベースモデルが検索および生成タスクをサポートしていることを確認する必要があります。
RLスケーリングはどのようにAIシステムを改善しますか?
RLスケーリングは、学習プロセスを改良することでAIシステムを強化します。動的なフィードバックメカニズムを使用して、出力を望ましい目標に合わせます。このアプローチは、特に複雑な環境で、精度、安定性、スケーラビリティを向上させます。
RAGとRLを実装するために不可欠なツールは何ですか?
主なツールには、効率的なデータ検索のためのPinecone、RLトレーニングのためのVeRL、最適化のための修正PPOアルゴリズムなどがあります。これらのツールは、ワークフローを合理化し、スケーリング中の高性能を保証します。
RLスケーリングにはマルチエージェントシステムが必要ですか?
マルチエージェントシステムは必須ではありませんが、非常に有益です。スケーラビリティとタスクの専門性を向上させます。エージェントは協力して検索および生成プロセスを改良し、システム全体の効率を向上させます。