RAGはまだ終わらない。これからはエージェント型RAGの時代
2025年11月27日Guanqun @puppyone
要約:これはオープンソースプロジェクトです:https://github.com/puppyone/DeepWideResearch
このプロジェクトは、脆弱なRAGパイプラインをエージェント型ワークフローに置き換え、メンテナンスの悪夢と品質低下の問題を解決します。
トレードオフは現実に存在します: エージェント型RAGは、従来のRAGがクエリあたり約0.01ドル、3秒未満であるのに対し、0.1ドル以上、10秒以上と、高コストで低速です。大規模な環境で1秒未満の応答が必要な場合、この方法は適していません。しかし、正確で保守性の高いナレッジQAが必要な場合は、ぜひこの先をお読みください。
本記事では、私たちが新しいエージェント型RAGアーキテクチャを構築した経験を共有し、なぜエージェント型RAGがエンタープライズ向けナレッジQAにおいて重要な一歩となるのかを探ります。
この1年間で、私は従来のRAGプロジェクトを5件手掛けました。それぞれ100〜1000ページのドキュメントを扱うものでした。技術スタックは、クエリ作成、クエリル-ティング、チャンキング、埋め込み、再ランキングなど、標準的なものでした。当初はすべて順調に進んでいましたが、すぐに罠にはまりました。プロセス全体が極めて硬直的で、維持が困難だったのです。
最も痛感したのは、ドキュメントの変更時でした。わずかな変更でRAG全体のスコアが低下してしまったのです。同じスコアを維持するためには、パイプライン戦略全体をゼロから再構築する必要がありました。新しいデータソースが追加されるたびに、新たな戦いに挑むような感覚でした。複雑なメタデータタグ付けや詳細なチャンキングで場当たり的な対応を試みましたが、それらは壊れたアーキテクチャに対する応急処置に過ぎませんでした。
私たちは自問し始めました:一体、何が間違っているのだろうか?
問題はロジックにありました。従来のRAGは、本質的にはデータセットにカーブフィッティングさせるためにハードコードされたif-elseルールを書いているようなものです。これは静的なコードには有効ですが、真の知能が必要とされる場面では破綻します。
OpenAIのDeep Researchに触発され、私は硬直的なパイプラインを捨てることにしました。
私は**エージェント型 + MCP(Model Context Protocol)**アーキテクチャに移行しました。アイデアは単純です。複雑な検索チェーンの代わりに、エージェントに各データソースを直接検索するためのツールを与えるのです。
システムアーキテクチャは以下の通りです:
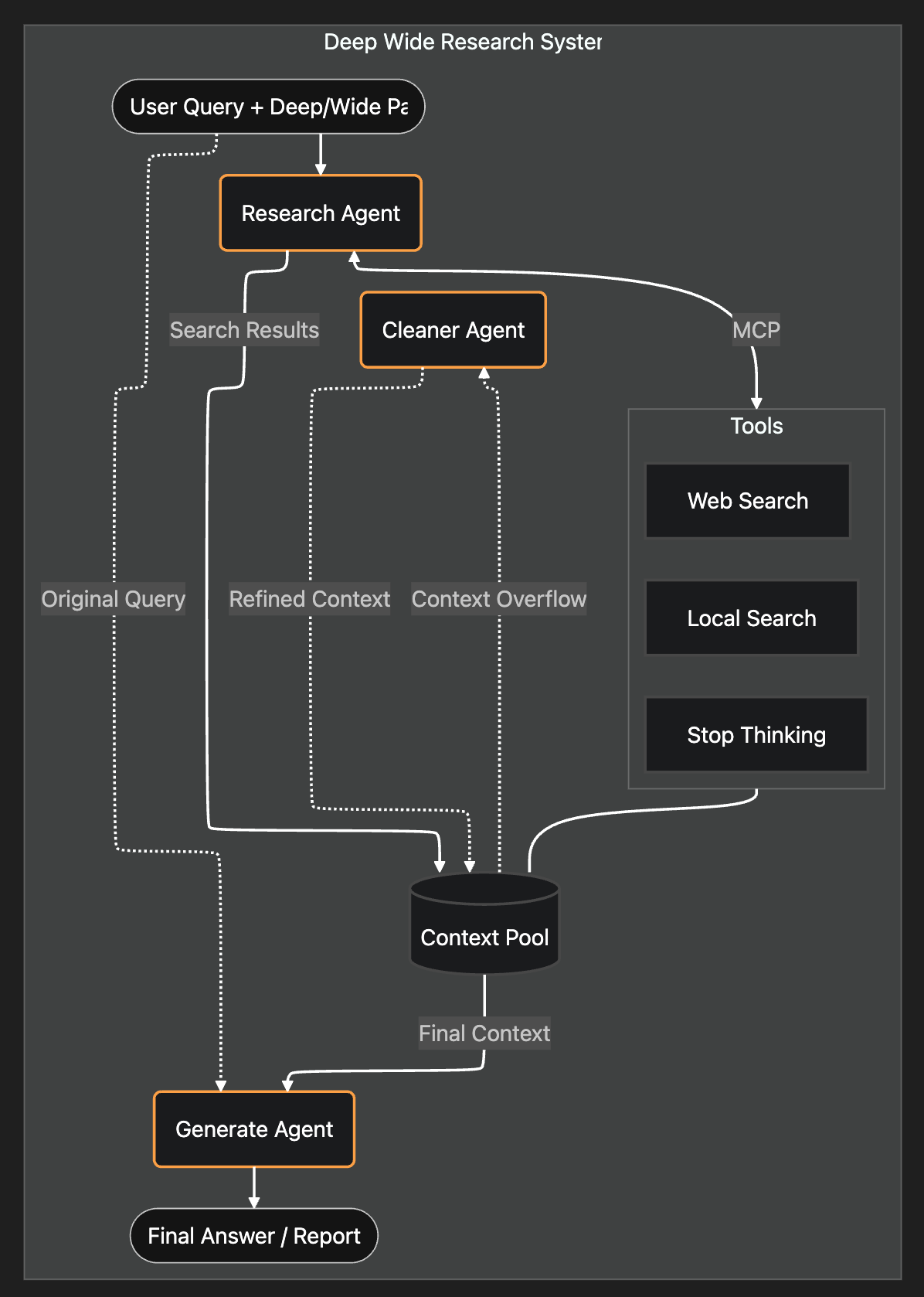
1. リサーチエージェントの構築方法
エージェント型RAGは、検索パイプライン全体を単一の自律的なリサーチエージェントに置き換えます。
書き換えやルーティングのルールをハードコードする代わりに、私はリサーチャーとジェネレーターという2つのエージェントを設定しました。
リサーチャーには、以下の3つのシンプルなツールを与えました:

<Stop_thinking><Web_search><Local_search>
しかし、エージェントにツールを与えるだけでは不十分です。いつ停止すべきかを教える必要があります。
単純なwhileループや固定のステップ数ではなく、エージェントが各アクションの前に自己省察ステップを実行するように強制しました。
私たちは単純なループやイテレーション回数を使いません。その代わり、エージェントが行動を起こす前に、**「記事準備完了チェック」**を用いて自己省察を行うように強制します:
## 記事準備完了チェック:
- 包括的で詳細な回答と記事を「今すぐ」作成できますか? (はい/いいえ)
- もし今書いた場合、どのセクションが弱く、曖昧で、具体的な例やデータが欠けていますか?
- すべての主張を裏付けるのに十分な具体的な事実、数値、例はありますか?
このチェックに合格した場合にのみ、エージェントは<Stop_thinking>を呼び出します。私たちはこのロジックをSOTAモデル(Gemini 3 pro / Claude 4.5 Opus / GPT-5)でテストしましたが、モデルは完璧にロジックに従いました。
すべてのリサーチ結果は、共有のコンテキストプールに保存されます。リサーチャーが「停止」のシグナルを送ると、生成エージェントがコンテキストプールを取得し、最終的な回答を生成します。
その結果は、私たちがこれまでに構築したどのパイプラインよりも優れていました。硬直した構造に知性が打ち勝ったのです。
私たちは、従来のRAGコンポーネントを動的なエージェントの振る舞いに実質的にマッピングしました:
- クエリル-ティング? -> エージェントが適切なツールを選択します。
- クエリ書き換え? -> エージェントが関数の引数を埋めます。
- マルチホップQA? -> エージェントが
<Stop_thinking>をいつ呼び出すか決定します。 - 再ランキング -> エージェントがコンテキストプールに基づいて回答を生成します。
2. コンテキストオーバーフローへの対処
次に私が直面したのは、検索されたコンテキストが長くなりすぎた場合にどうなるか、という2番目の問題でした。
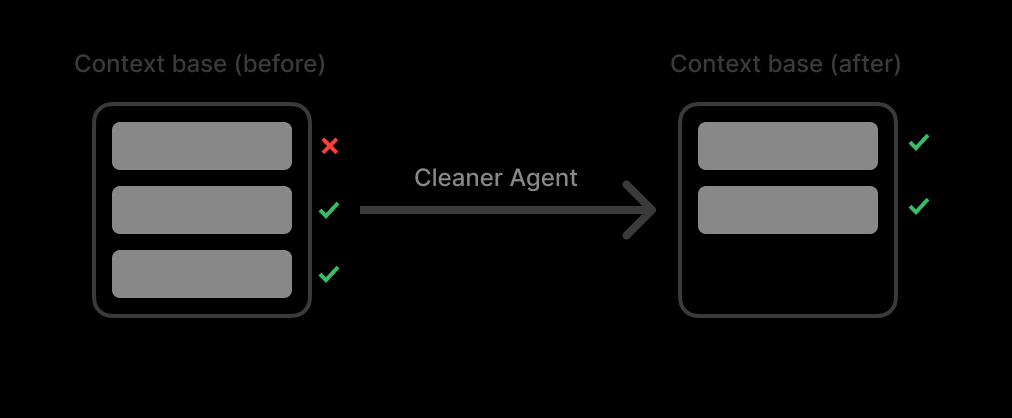
私はコンテキストプールを構築しました。このプールは、すべての検索結果のリストとして機能します。コンテキストプールがしきい値(最大トークンの90%)に達すると、クリーナーエージェントがコンテキストをクリーンアップするようにしました。
**ここでの秘訣は、「要約しない」ことです。**要約は詳細を失わせます。
その代わり、クリーナーエージェントはゴミフィルターのように機能します。関連性のないソースを丸ごと削除し、関連性のあるソースは100%オリジナルのまま、完全に保持します。
最後に、生成エージェントが、コンテキストプール内の洗練されたコンテンツと元のクエリに基づいて最終的な回答を生成します。
3. コストとレイテンシーに対する「Deep-Wide」ソリューション
すぐに私は3番目の課題に直面しました。コストとレイテンシーの壁です。
数字について正直にお話しします:
- レイテンシー: エージェント型RAGには約10秒という越えられない下限があります。推論ループがボトルネックであり、これ以下にすることはできません。従来のRAGは3秒未満で応答できます。
- コスト: GPT-5を使用した場合、クエリあたり約0.05ドルから1ドルかかります。埋め込みを使用する従来のRAGのコストは、約0.005ドルから0.01ドルです。
この下限値以上でトレードオフを制御可能にするために、私は**「Deep-Wide Research」**を導入しました:
- Deep(深さ): 反復的な推論ステップを制御します。範囲は約10秒(最小)から5分以上(包括的なレポートのための最大深度)です。
- Wide(幅): 並列的なクエリ拡張を制御します。幅が広いほど、探索されるソースが増え、トークンコストが高くなります。
DEEP × WIDE ≈ コスト。 これら2つの次元を調整することで、応答時間(10秒〜5分)、品質、コストを制御できますが、10秒の下限を下回ることはできません。
私たちはDEEP WIDE RESEARCHをオープンソース化しました。 プロジェクトURL: https://github.com/puppyone/DeepWideResearch (Apacheライセンス)
このプロジェクトが解決しないこと
このプロジェクトは、エージェント型RAGの問題の半分、つまり「推論と検索」側に取り組んでいます。
残りの半分であるプライベートな企業データの取り扱いは、ここでは未解決のままです:
- 乱雑な企業ドキュメントのクリーニング
- エージェントが利用しやすいように最適化されたインデックスの構築
- 詳細な権限管理
私たちはこれに別途取り組んでいます。もしこれらの問題に直面したり、アイデアをお持ちでしたりする方がいらっしゃいましたら、ぜひご連絡ください:[email protected]