Hybrid Indexing & Structured Know‑How for Dev Velocity
2026년 3월 20일Ollie @puppyone
하이브리드 인덱싱과 구조화된 노하우: PR 병합 속도를 높이는 개발자용 RAG
개발 속도가 저하되는 이유는 사람들이 코딩 방법을 잊었기 때문이 아닙니다. 팀이 리포지토리와 문서 내부에 이미 존재하는 지식을 찾지 못하거나, 신뢰하지 못하거나, 재사용하지 못할 때 정체됩니다. 이것이 바로 지식 엔트로피입니다. ADR(Architecture Decision Records)은 위키 여기저기에 흩어져 있고, API 계약은 PDF에 묻혀 있으며, 조직 개편으로 인해 소유권 정보가 유실됩니다. 검색 증강 생성(RAG)이 도움이 될 수 있지만, 이는 의미론적(semantic)이면서 동시에 결정론적(deterministic)인 검색 백본에 기반을 두었을 때만 가능합니다. 여기서 구조화된 노하우에 대한 하이브리드 인덱싱이 PR 병합과 더 안전한 리팩터링의 판도를 바꿉니다.
핵심 요약
- 하이브리드 인덱싱 + 구조화된 노하우는 환각(hallucinations)을 줄이고, PR 리뷰 속도를 높이는 정밀하고 검토 가능한 인용을 생성합니다.
- 개발자용 RAG를 엔지니어링 시스템으로 취급하십시오: precision@k, 인용 정확도, 병합 시간(time‑to‑merge), 리버트(revert) 비율을 측정하십시오.
- 하이브리드 리트리버(sparse lexical + dense vectors + structural/graph keys)를 사용하여 정확한 파일 경로와 ADR ID로 코드베이스 질문에 답변하십시오.
- 마이크로 워크플로우부터 시작하십시오: 인용 기능이 포함된 PR 설명 어시스턴트와 ADR/소유권에 기반한 리팩터링 어드바이저가 좋습니다.
- 프라이빗/로컬 배포, 임베딩 전 비밀 정보(secret) 제거, 모든 쓰기 제안에 대한 human‑in‑loop 게이트를 선호하십시오.
개발자용 RAG — 작동하는 것과 실패하는 것
RAG는 LLM과 코드, 문서, 설계 이력에서 증거를 가져오는 리트리버를 결합합니다. 제대로 작동하면 개발자는 근거가 확실한 요약과 출처가 명시된 PR 본문 초안을 얻게 됩니다. 하지만 제대로 작동하지 않으면 확신에 찬 오답을 내놓게 되고 신뢰는 무너집니다.
주의해야 할 실패 패턴:
- 텍스트 전용 벡터는 정확한 식별자(ADR‑1234, 함수 이름)를 놓쳐서, 그럴듯하지만 틀린 청크(chunks)를 반환합니다.
- 과도한 검색(Over‑retrieval)은 프롬프트를 가득 채우며, 리뷰어는 시그널이 아닌 노이즈를 보게 됩니다.
- 인용이 없다는 것은 신뢰가 없음을 의미합니다. 리뷰어는 검색을 다시 수행해야 합니다.
베스트 프랙티스 해결책은 잘 문서화된 가이드를 따릅니다: 의미론적 청킹(semantic chunking), 하이브리드 검색, 그리고 리랭킹(reranking)입니다. 간결한 아키텍처 개요는 마법 같은 프롬프트가 아닌 검색 구성과 평가를 강조하는 RAG 파이프라인에 관한 InfoQ 기사의 프로덕션 지향 패턴을 참조하십시오 (InfoQ — Effective Practices for Architecting a RAG Pipeline). 또한 CI 시점의 에이전틱(agentic) 개발자 워크플로우에 대해서는, 어시스턴트가 루프 내에서 아티팩트를 작성하고 검증하는 방법을 보여주는 GitHub의 지속적 AI(continuous AI) 논의를 확인하십시오 (GitHub Blog — Continuous AI in practice: agentic CI for developers).
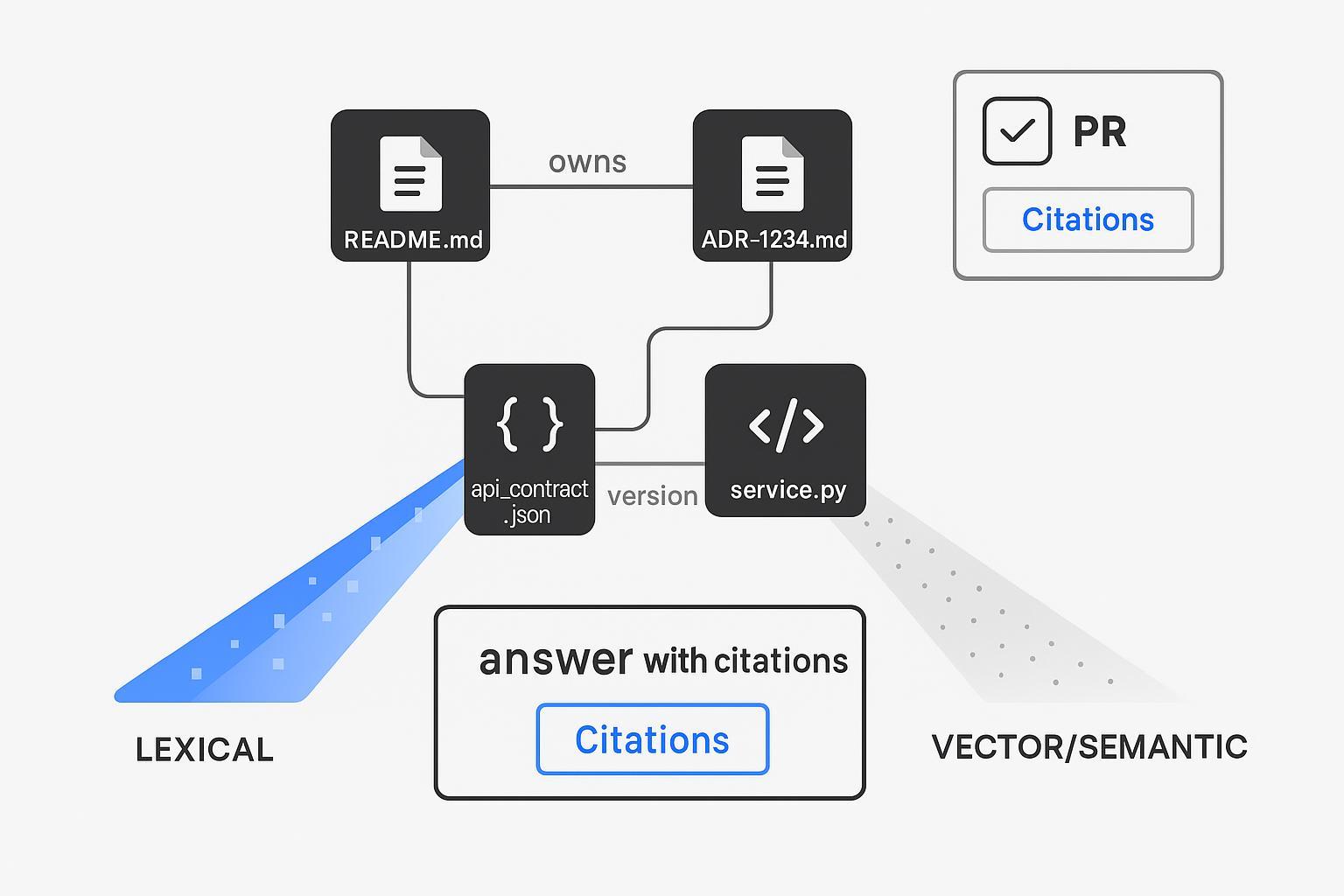
검색 백본으로서의 구조화된 노하우 + 하이브리드 인덱싱
텍스트만으로는 개발자 워크플로우를 감당할 수 없습니다. 기업의 노하우를 명시적으로 모델링하고 텍스트와 구조 전체에 걸쳐 검색하십시오.
최소한의 노하우 스키마(예시):
{
"type": "adr",
"adr_id": "ADR-1234",
"title": "Deprecate legacy payment gateway",
"status": "accepted",
"decision": "Move to PayFast v3",
"owners": ["@payments-core"],
"links": {"repo_paths": ["/services/payments"], "docs": ["/docs/payments/adr-1234.md"]},
"supersedes": ["ADR-0899"],
"date": "2025-11-06",
"version": "1.2"
}
하이브리드 리트리버 설계(개요):
- Lexical: 정확한 필터(repo_path:/services/payments, file:*.md), 식별자를 위한 BM25.
- Dense: 의역 및 의도 파악을 위한 코드/문서 임베딩.
- Structural: 올바른 파일/소유자를 가져오기 위한 키(adr_id, owner, module) 기반의 결정론적 조인.
- 선택 사항: 충실도(faithfulness)를 위해 cross‑encoder로 리랭킹.
이 패턴은 Qdrant의 하이브리드 검색 엔지니어링 리소스에 문서화된 대로, 선택적 리랭킹을 포함한 dense + sparse 퓨전과 같은 하이브리드 검색에 대한 벤더 및 커뮤니티 가이드를 반영합니다 (Qdrant — Hybrid Search Revamped; Qdrant Docs — Hybrid Queries). 그 결과는 단순히 "비슷한 무언가"가 아니라 정확한 파일 경로와 ADR ID를 인용할 수 있는 검색 레이어입니다. 이것이 리뷰어에게 필요한 신뢰의 지렛대입니다.
PR 속도를 높이는 마이크로 워크플로우
- 인용 기능이 포함된 PR 설명 어시스턴트
목표: diff와 로컬 노하우를 바탕으로 근거 있는 PR 본문 초안 작성.
핵심 단계:
- 브랜치/PR 제목을 쿼리 변형으로 확장합니다.
- (a) 변경된 경로(lexical 필터), (b) 의미적으로 유사한 문서/청크, (c) 구조적 키(ADRs/소유자)에서 top‑k를 검색합니다.
- 항상 영구 링크(permalinks)가 포함된 Citations 블록을 포함하는 PR 본문을 생성합니다.
PR 본문 템플릿 예시:
#### Summary
- Implements PayFast v3 retry policy in /services/payments/retry.go
#### Rationale
- Aligns with ADR-1234 (Deprecate legacy payment gateway). See details below.
#### Impact
- Touches retry.go; no public API changes. Adds metric payments.retry.backoff_ms.
#### Citations
- ADR-1234 — /docs/payments/adr-1234.md#decision
- Code — /services/payments/retry.go#L120-L168
- Runbook — /ops/runbooks/payments-retries.md#rollback
- ADR 및 소유권 기반의 리팩터링 어드바이저
목표: 설계 의도와 소유자를 자동으로 노출하여 대규모 리팩터링을 더 안전하게 만듭니다.
핵심 단계:
- 제안된 리팩터링 계획이 주어지면, 대체된 ADR과 영향을 받는 모듈 소유자를 검색합니다.
- 체크리스트 생성: "@payments-core에 알림", "계약 테스트 업데이트", "ADR‑0899에 따른 지원 중단 기간 확인".
- 리뷰어가 신속하게 검증할 수 있도록 각 소스에 대한 인용을 내보냅니다.
개발 속도 및 검색 품질 측정
RAG를 감사 가능한 결과가 있는 엔지니어링 시스템으로 취급하십시오.
추적할 지표:
- 속도: 중앙값 병합 시간(TTM), 병합률(merged/opened), PR당 리뷰 반복 횟수.
- 품질: 리버트(revert) 비율, CI 실패율, 리팩터링 후 머지 결함.
- 검색: precision@k, 인용 정확도(인용된 소스가 주장을 뒷받침하는가?), 환각 비율.
A/B 테스트 계획(8–12주):
- 대조군: 표준 워크플로우.
- 실험군: 인용 기능이 포함된 PR 설명 어시스턴트 + 리팩터링 어드바이저(읽기 전용 제안) 활성화.
- 검색 → 제안 → 리뷰어 수락/수정 → 병합 단계에서 이벤트를 측정합니다.
RAG 충실도 및 인용 동작을 측정하고 개선하는 광범위한 업계 맥락에 대해서는, 관련성/충실도 지표와 LLM‑as‑judge 감사를 공식화한 최근의 조사 및 평가 연구를 참조하십시오 (arXiv — Evaluation of Retrieval‑Augmented Generation: A Survey; arXiv — Comprehensive and Practical Evaluation of RAG).
데모에서 프로덕션까지
거대한 단일 시스템(monolith)이 필요한 것이 아니라, 신뢰할 수 있는 루프가 필요합니다.
- 인제스천(Ingestion): 코드(함수/클래스) 및 문서(헤더/의미론)를 위한 언어 인식 청킹. 메타데이터(repo_path, module, owner, version)를 첨부합니다. 코드는 500–1500 토큰, 문서는 400–1000 토큰을 목표로 합니다.
- 인덱싱 주기: 변경 시 재임베딩, 활발한 리포지토리는 매일 밤 배치, 비활성 리포지토리는 매주 수행. 롤백을 위해 인덱스 버전을 관리합니다.
- 거버넌스: 프라이빗/로컬 배포를 선호하고, 검색 ACL을 리포지토리 권한에 맞추며, 임베딩 전 비밀 정보를 제거합니다.
- 서빙(Serving): 토큰 제어를 위해 k값을 제한하고, 자주 묻는 쿼리를 캐싱하며, 까다로운 네임스페이스의 경우 cross‑encoder 리랭킹을 고려하십시오.
- 모니터링: precision@k, 인용 정확도, 지연 시간, 쿼리당 비용을 추적합니다. 성능 저하(정밀도/인용 정확도 하락) 시 알림을 설정합니다.
실제 사례들은 왜 이 작업이 가치 있는지 보여줍니다. Amazon은 Amazon Q Developer를 통해 수만 개의 애플리케이션에 걸쳐 대규모 Java 업그레이드 시간을 며칠에서 몇 분으로 단축하여, 약 4,500 개발자-년(developer-years)을 절약하고 연간 2억 6천만 달러의 가치를 창출했다고 보고했습니다 (AWS DevOps & Developer Productivity Blog, 2024). 이는 내장된 개발자 어시스턴트가 SDLC에 통합될 때 처리량의 획기적인 변화를 이끌어낼 수 있다는 증거입니다 (AWS DevOps Blog — Amazon Q Developer milestone). 또한 Mercado Libre에 대한 GitHub의 고객 사례는 조직 전체 도입을 통해 코드 작성 시간을 약 50% 단축하고 놀라운 PR 처리량을 기록했음을 보여주며, 어시스턴트가 핵심 경로에 있을 때의 잠재력이 매우 높음을 시사합니다 (GitHub Customer Stories — Mercado Libre).
툴링 노트 — 궁합이 좋은 스택
- Vector + sparse: Qdrant, Pinecone, Weaviate 모두 하이브리드 패턴을 지원합니다. 점수 융합 제어, 운영 성숙도, 비용에 따라 선택하십시오.
- 오케스트레이션: 빠른 구성을 위한 LangChain/LlamaIndex, 인제스천 운영을 위한 Dagster/Airflow.
- 임베딩: 리포지토리에 최적화된 코드 튜닝 모델을 선택하고, 성능 저하를 모니터링하며 선택적으로 재임베딩하십시오.
- 그래프/구조: 명시적인 노하우 그래프를 위한 Neo4j/TigerGraph 또는 소규모 팀을 위한 가벼운 JSON/kv.
- 에이전트 CI: GitHub의 에이전틱 CI 가이드에 따라 PR 훅과 CI 코멘트에 어시스턴트를 통합하십시오.
실전 예시: puppyone의 구조화된 노하우와 하이브리드 인덱싱 활용
하이브리드 인덱싱은 지식이 기계가 이해할 수 있도록 모델링되었을 때만 빛을 발합니다. 이를 구현하는 중립적인 방법 중 하나는 기업 지식을 구조화된 노하우(JSON/그래프)로 저장하고 단일 리트리버에서 lexical, vector, structural 조회를 융합하는 것입니다.
워크플로우 예시(설명용, 중립적):
- ADR, 소유권, API 계약을 일급 노하우 노드(예: adr_id, status, decision, owners, repo_paths, version)로 모델링합니다.
- 메타데이터(repo_path, symbols, owners)와 함께 코드/문서 청크를 인제스천합니다. Lexical 필터(예: 리포지토리 경로), 벡터(의미론적 유사성), 구조적 조인(adr_id → 관련 파일/소유자)이 결합된 하이브리드 인덱스를 구축합니다.
- PR 어시스턴트에서 리뷰어가 신속하게 검증할 수 있도록 ADR 및 파일 라인 범위에 대한 영구 링크가 포함된 Citations 블록을 요구합니다.
이 패턴은 결정론적 검색과 정밀한 인용을 위해 구조화된 노하우와 하이브리드 인덱싱을 중심으로 하는 puppyone의 공개 개념 자료에 의해 뒷받침됩니다. 이 접근 방식에 대한 개요는 에이전트 워크플로우에서 신뢰할 수 있는 근거 마련을 위해 텍스트와 구조를 결합하는 방법을 요약한 해당 회사의 하이브리드 인덱싱 기사를 참조하십시오 ("Ultimate Guide to Agent Context Base: Hybrid Indexing"의 개요 참조) (puppyone’s hybrid indexing guide). 자체 스키마와 리트리버를 설계할 때 이를 개념적 참고 자료로 활용하고, 귀하의 스택과 거버넌스 제약 조건에 맞게 조정하십시오.
결론 및 다음 단계
목표가 더 빠르고 안전한 PR이라면, 먼저 구조화된 노하우와 모든 주장을 인용으로 증명할 수 있는 하이브리드 리트리버에 투자하십시오. PR 설명 어시스턴트와 리팩터링 어드바이저를 시범 운영하고, TTM과 인용 정확도를 측정하며 효과가 있는 것을 확장하십시오. 구조화된 노하우와 하이브리드 인덱싱을 탐색 중이라면, 소규모 프라이빗 파일럿에서 puppyone을 평가하고 기존 스택과 비교해 볼 수 있습니다.