Autoevolução de IA: Uma Revisão Abrangente de Sistemas LLM de Loop Fechado e os Novos Horizontes em Sistemas Multiagente
4 de setembro de 2025Ollie @puppyone
Por que devemos estudar seriamente a "auto-evolução de LLM" agora? Para simplificar, os modelos poderosos de hoje são principalmente "produtos estáticos": após um treinamento offline único, eles são implantados e depois enfrentam mudanças de distribuição, novas formas de tarefas e a rápida evolução dos ecossistemas de ferramentas. Eles só podem contar com retreinamento humano caro e atrasado para se atualizarem. Este paradigma continuará incorrendo em perdas num mundo não-estacionário: a dívida técnica do conhecimento desatualizado, o custo contínuo de rotular e limpar dados, e a vulnerabilidade no raciocínio complexo de cauda longa e colaboração entre domínios. O que precisamos não são apenas modelos maiores, mas sistemas que possam aprender enquanto executam, se autocorrigir em seu ambiente e crescer continuamente mais fortes num loop fechado.
 Fonte da Imagem: Puppyone
Fonte da Imagem: Puppyone
Focamos no trabalho relacionado à "auto-evolução/auto-aperfeiçoamento de LLM / Agente de IA" de junho a agosto de 2025 e fornecemos uma revisão abrangente e atualização de progresso. Esperamos esclarecer o espaço de design e caminhos viáveis para "auto-evolução" para desenvolvedores e pesquisadores: quais problemas fechar o loop primeiro, como construir um sistema viável mínimo, quais métricas usar para medir "realmente ficar mais forte", e como tornar "auto-evolução" e "controlável e confiável" ambos utilizáveis no nível de engenharia.
Resumo (Visão Geral Junho-Agosto 2025)
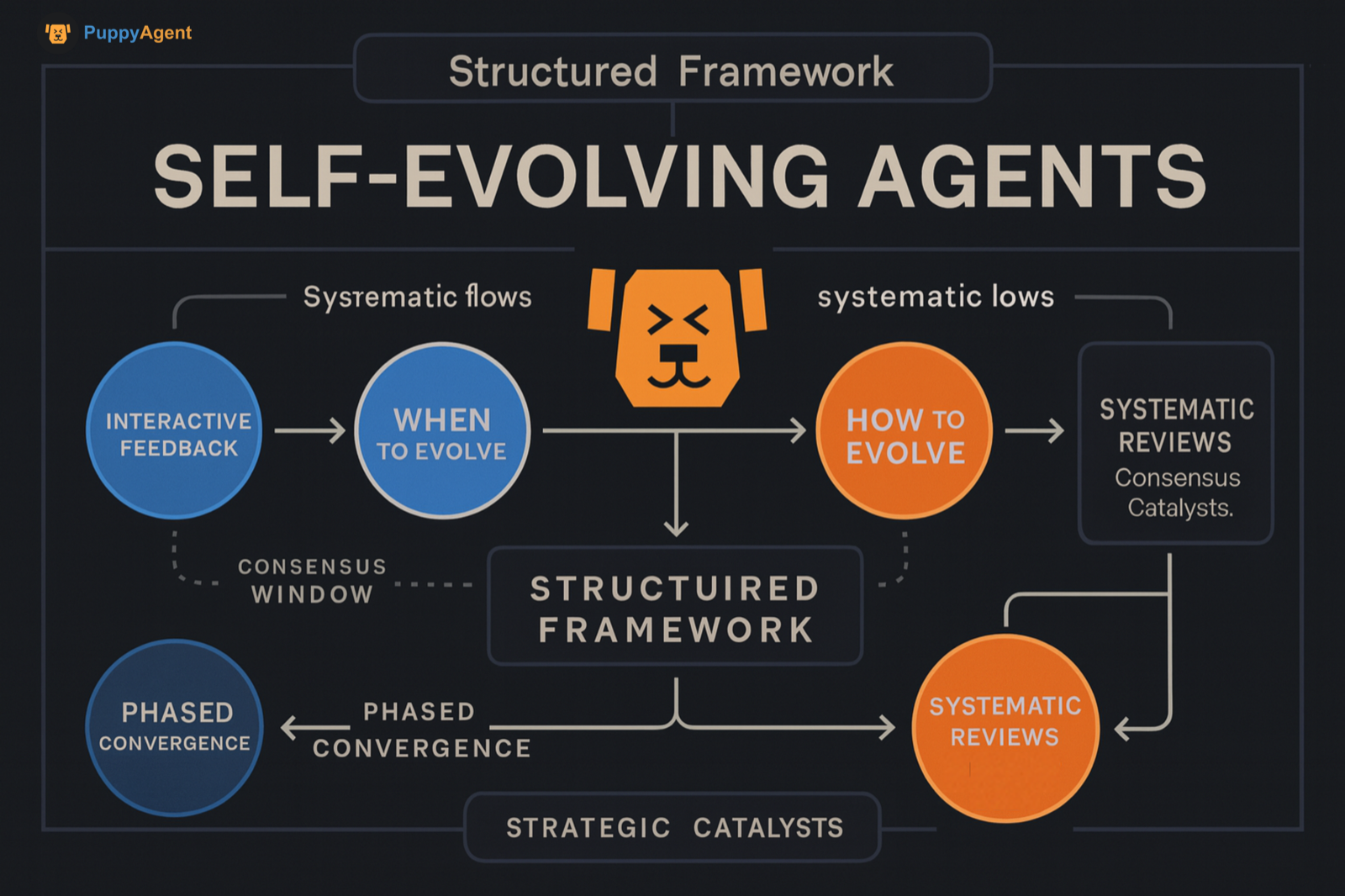
Definição
As comunidades acadêmica e industrial ainda não chegaram a uma definição unificada para "auto-evolução". No entanto, em agosto, duas revisões sistemáticas focando em "agentes auto-evolutivos/proxies de IA auto-evolutivos" foram lançadas consecutivamente. Elas propuseram uma estrutura estruturada centrada em "o que evoluir, quando evoluir e como evoluir", focando no aperfeiçoamento contínuo do sistema através de feedback interativo, sinais ambientais e otimização de loop fechado. Isso marca o tópico entrando numa janela de consenso de convergência faseada.
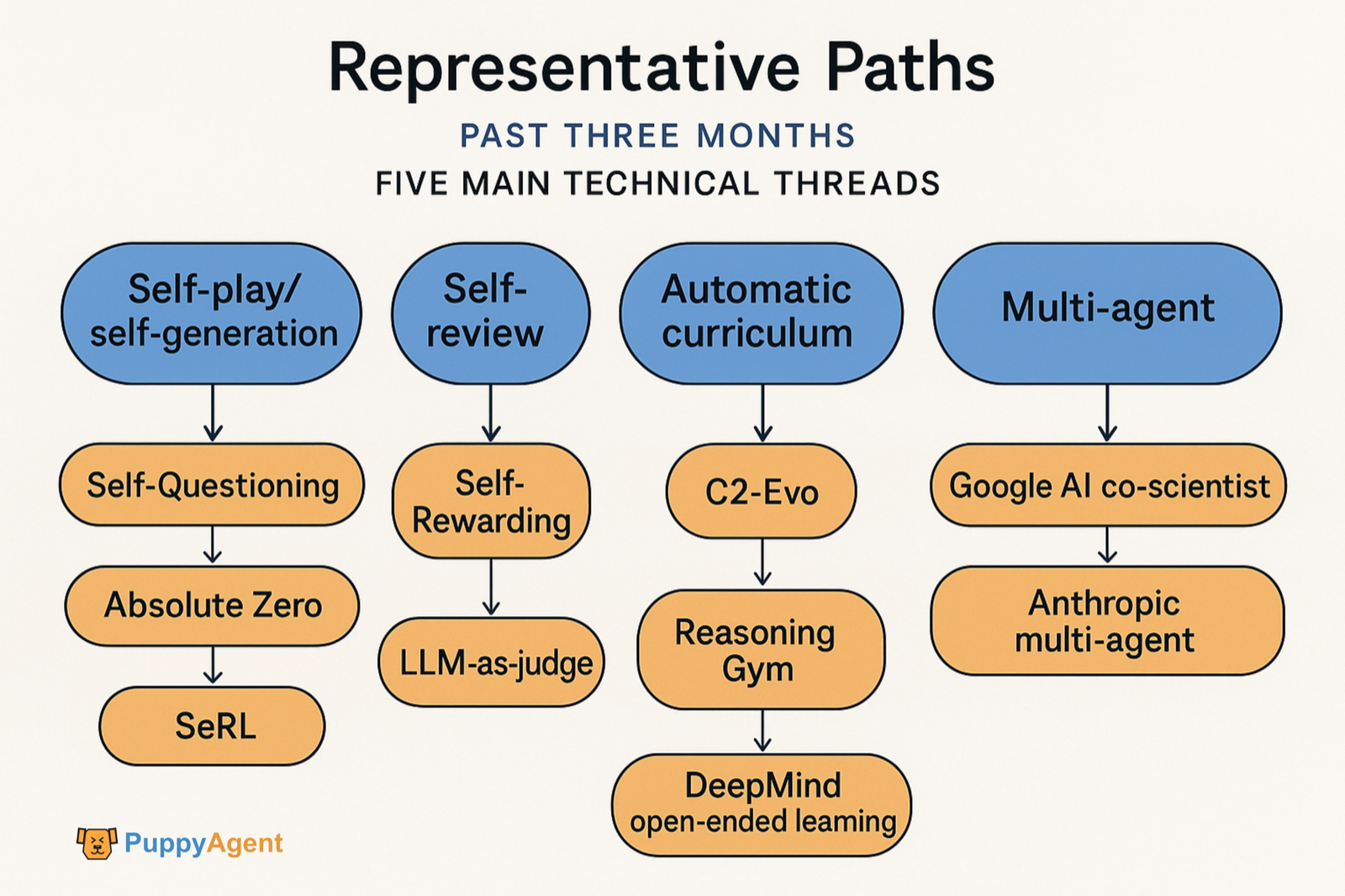
Caminhos Representativos
 Fonte da Imagem: Puppyone
Fonte da Imagem: Puppyone
Nos últimos três meses, o trabalho representativo se concentrou em cinco principais linhas técnicas:
- Tarefas de auto-jogo/auto-geração sem dados externos (Self-Questioning, Absolute Zero, SeRL).
- Auto-revisão/auto-recompensa (Self-Rewarding, LLM-as-judge).
- Co-evolução de dados e modelos (C2-Evo, NavMorph).
- Currículo automático/evolução aberta (SEC, Reasoning Gym, tradição de aprendizagem aberta DeepMind).
- Fluxos de trabalho de auto-aperfeiçoamento multiagente (Google AI co-scientist, sistema multiagente da Anthropic). Também houve o surgimento de evidências quantitativas e métodos de diagnóstico sobre "quais hábitos cognitivos apoiam o auto-aperfeiçoamento."
Avaliação e Segurança:
Ambientes de geração de processos com "recompensas verificáveis" como o Reasoning Gym se tornaram um meio para treinamento e avaliação de auto-evolução de loop fechado. O AI co-scientist do Google correlaciona ranking interno de auto-jogo e pontuações Elo com a precisão de problemas GPQA. A Anthropic enfatiza a combinação de LLM-judge e revisão humana, bem como proteção de engenharia e rastreabilidade para sistemas multiagente. Enquanto isso, os riscos de "trapaça/alucinação" e alinhamento no "auto-aperfeiçoamento" levaram a mais exploração de estratégias de sandbox e guardiã.
Conceito e Limites: O que são Agentes LLM/IA "Auto-evolutivos"
Auto-evolução
Auto-evolução não é um paradigma de treinamento único, mas uma categoria de design de sistema de loop fechado: Com intervenção humana mínima, o sistema gera continuamente dados/tarefas, melhora estratégias e parâmetros, ou reescreve sua própria cadeia de ferramentas/código através de mecanismos como feedback ambiental, execução de ferramentas, auto-jogo ou auto-revisão. Isso permite que se torne mais forte ao longo do tempo em tarefas fora da distribuição, tarefas de longo prazo e raciocínio complexo. Duas revisões recentes abstraíram isso num loop de feedback com quatro componentes: entrada do sistema, sistema agente, ambiente e otimizador. Elas também avaliaram e resumiram metodologias baseadas em três dimensões: "o que evoluir, quando evoluir e como evoluir", enfatizando a transição de modelos base estáticos para um sistema "agente auto-evolutivo" com adaptabilidade vitalícia.
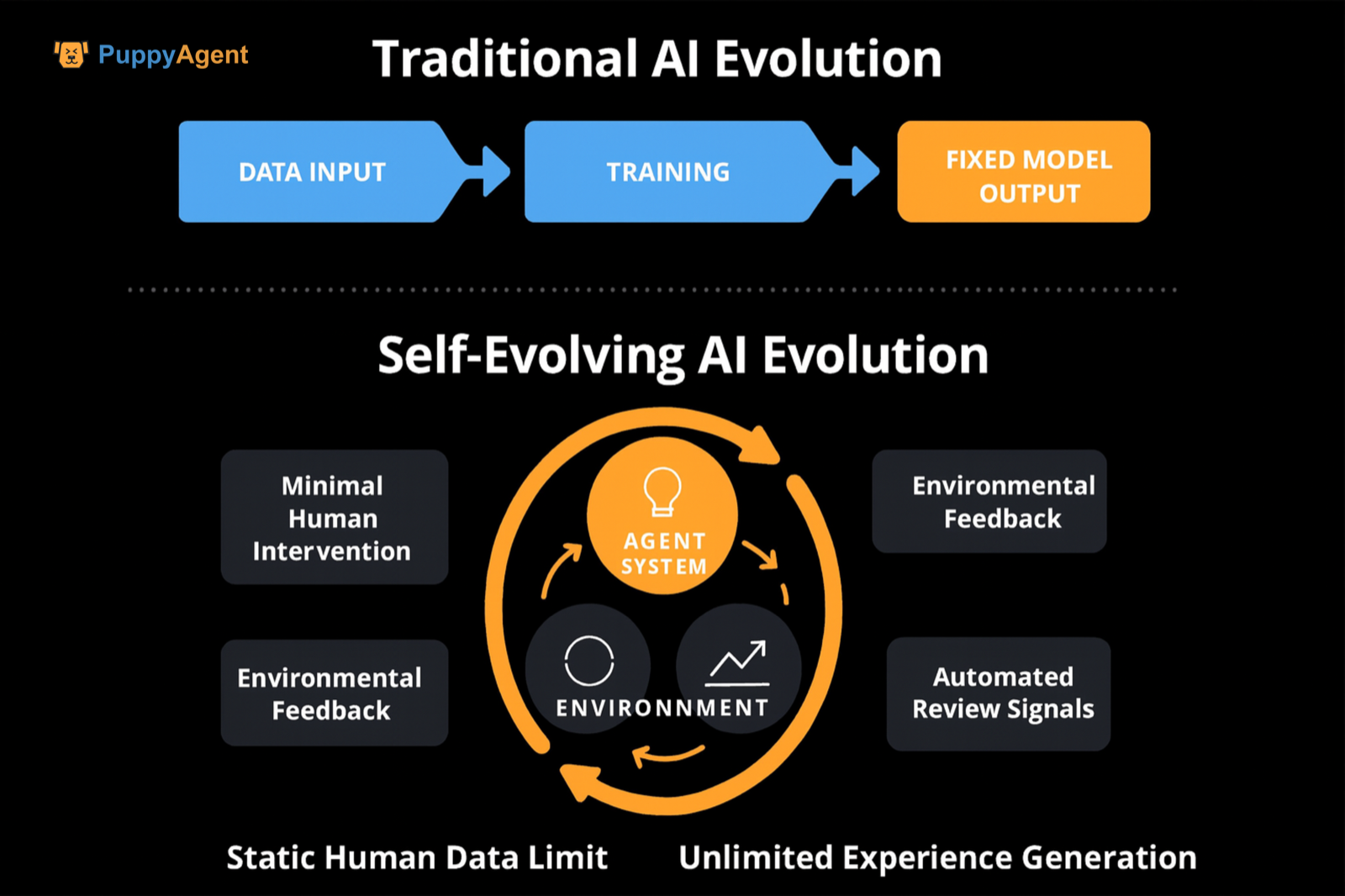
A diferença da auto-supervisão tradicional/ajuste fino de instrução
 Fonte da Imagem: Puppyone
Fonte da Imagem: Puppyone
A diferença reside na ênfase no domínio de "dados de experiência/interação", geração dinâmica de espaço de tarefas e dificuldade, e fontes automatizadas de sinais de revisão/recompensa (auto-revisão, verificação executável, ranking de competição, etc.). Isso rompe o limite superior dos dados humanos estáticos. A DeepMind propôs a "Era da Experiência", defendendo a experiência de interação como a principal fonte de dados, com sinais de recompensa fundamentados no mundo. Sugere atualizar continuamente o modelo mundial e a função de recompensa para corrigir vieses a longo prazo, fornecendo um argumento conceitual e de caminho para "auto-evolução".
Panorama de Pesquisa e Laboratórios/Equipes/Pesquisadores de Fronteira
 Fonte da Imagem: pexels
Fonte da Imagem: pexels
Google Research
O AI co-scientist, baseado no Gemini 2.0, emprega uma colaboração multiagente de "Supervisor + agentes dedicados". Os componentes incluem agentes de geração, reflexão, ranking, evolução, proximidade e meta-revisão. Ele aproveita feedback automatizado e debates científicos de auto-jogo, torneios de ranking e processos evolutivos para formar um loop de auto-aperfeiçoamento com "computação escalável no tempo de teste". Sua auto-avaliação Elo interna se correlaciona positivamente com a precisão no desafiante conjunto de dados GPQA. Revisões de especialistas em pequenas amostras sugerem que suas saídas superam várias linhas de base estado-da-arte (SOTA) em termos de novidade e impacto.
Anthropic
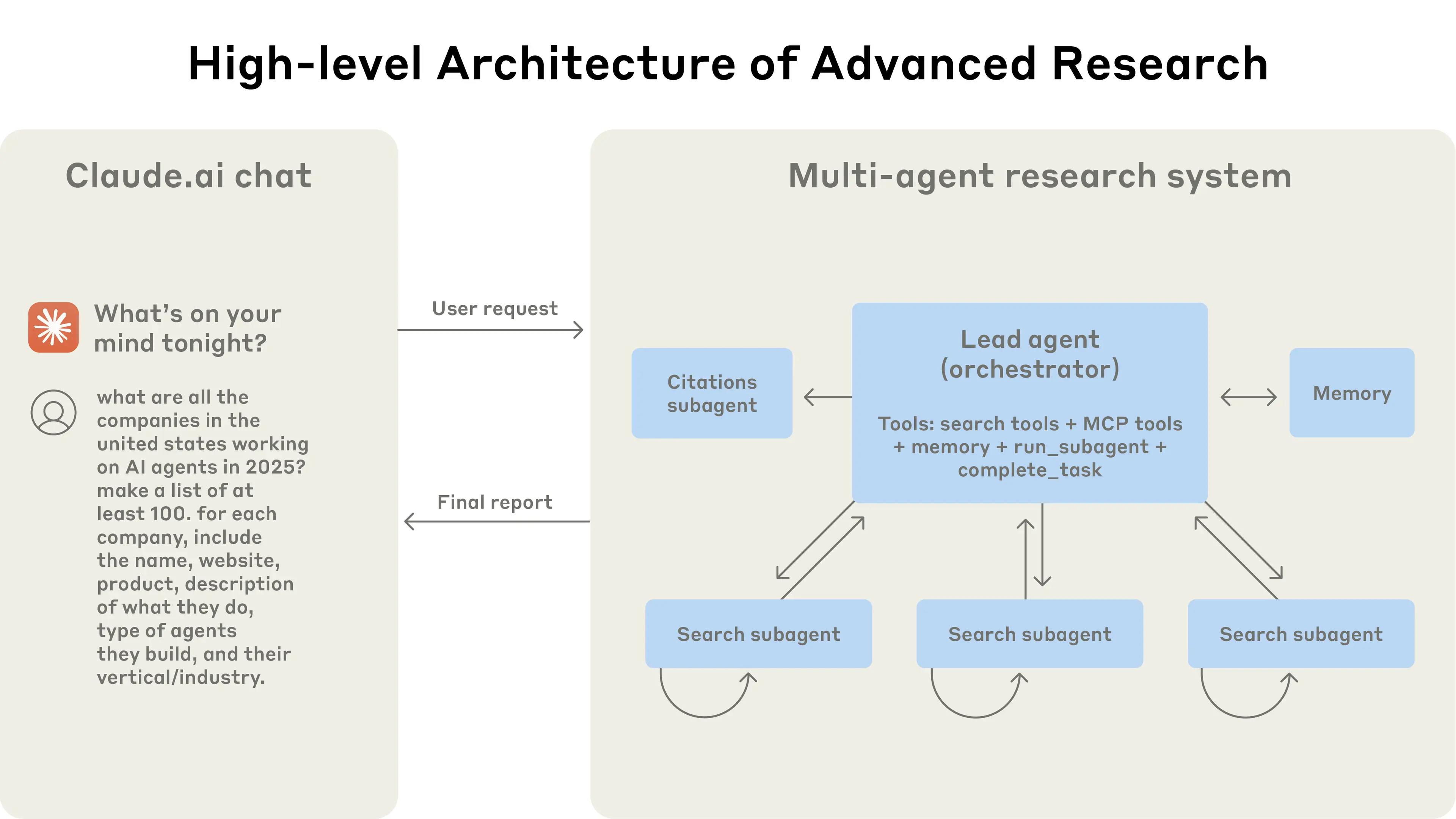
A Anthropic detalhou publicamente seu plano de engenharia do sistema de pesquisa multiagente, que apresenta sub-agentes paralelos de "orquestrador-trabalhador", memória externa, pontuação LLM-judge combinada com revisão humana. Propõe "agentes melhorando a si mesmos" (modelos autodiagnosticam modos de falha e reescrevem prompts/descrições de ferramentas), alcançando aproximadamente 40% de redução no tempo de tarefa para usabilidade de ferramentas. Enfatiza comportamento emergente em sistemas multiagente e observabilidade de nível de engenharia, lançamentos escalonados e salvaguardas de rollback.
Meta
Zuckerberg destacou explicitamente "auto-aperfeiçoamento" como foco estratégico do "Superintelligence Lab" durante o relatório de ganhos do Q2, enfatizando a redução da dependência de dados humanos e o desenvolvimento de um caminho "auto-aperfeiçoante", ligado à visão de "superinteligência pessoal".
OpenAI e Interseções Acadêmicas
Relatórios da mídia citaram Sam Altman descrevendo a fase atual como "passado o horizonte de eventos com uma decolagem lenta", enfatizando que o auto-aperfeiçoamento de curto prazo não é totalmente automatizado, mas sim um aprimoramento recursivo de "usar IA para acelerar a pesquisa de IA". Simultaneamente, a "Darwin-Goedel Machine" (por Clune e a equipe Sakana AI) demonstra leitura automática de seus próprios logs, propondo e implementando modificações de código de ponto único, e melhorias iterativas geracionais no SWE-Bench e Polyglot. No entanto, também expõe riscos de "auto-decepção/falsificação de logs", destacando a importância de sandbox e avaliações anti-decepção.
Classificação de Mecanismos Técnicos e Trabalhos Representativos
Auto-Jogo / Tarefas Auto-Geradas Sem Dados Externos
-
Self-Questioning Language Models (SQLM): Dado um prompt de tópico, uma estrutura de auto-jogo assimétrica "proponente-resolvedor" gera perguntas e respostas, com ambos os componentes treinados via aprendizagem por reforço (RL). O proponente é recompensado por gerar problemas de dificuldade intermediária (nem muito fáceis nem muito difíceis), enquanto o resolvedor é avaliado usando votação majoritária como proxy para correção. Para tarefas de programação, testes unitários servem como verificação. Resultados empíricos mostram melhoria sustentada em multiplicação de três dígitos, álgebra OMEGA e benchmarks Codeforces sem quaisquer dados fornecidos por humanos, representando um paradigma de loop fechado "gerar problemas - resolver problemas".
-
Absolute Zero (AZR): Propõe um paradigma Reinforcement Learning with Verifiable Rewards (RLVR) que requer zero dados externos. Um modelo único gera autonomamente tarefas de raciocínio baseadas em código e usa um executor de código para validar tanto as tarefas quanto suas soluções, fornecendo uma fonte unificada de recompensas verificáveis para guiar aprendizagem aberta mas fundamentada. AZR alcança ou supera desempenho estado-da-arte em tarefas de codificação e raciocínio matemático comparado a linhas de base de supervisão zero que dependem de dezenas de milhares de exemplos curados por humanos, enfatizando um loop fechado integrado de geração de tarefas, verificação e aprendizagem.
-
SeRL: Combina "auto-instrução" (aumento de instrução online com filtragem) e "auto-reflexão" (votação majoritária para estimar recompensas), permitindo aprendizagem por reforço em dados auto-gerados. Esta abordagem reduz a dependência de instruções de alta qualidade fornecidas por humanos e recompensas verificáveis, e demonstra desempenho superior em múltiplos benchmarks de raciocínio e diferentes backbones de modelos.
-
Extensão de Auto-Jogo de Diálogo Médico AMIE (Relatório Industrial): Para expandir a cobertura de doenças e cenários clínicos, o Google desenvolveu um "ambiente de simulação de diálogo diagnóstico de auto-jogo" com mecanismos de feedback automatizado para enriquecer e acelerar o treinamento. Isso representa um esforço de nível industrial para aplicar métodos de auto-jogo para escalar IA em domínios críticos de segurança como saúde.
 Fonte da Imagem: pexels
Fonte da Imagem: pexels
Auto-Avaliação / Auto-Recompensa e Evolução de Crítico Adversarial
-
Self-Rewarding Self-Improving: Aproveita a "assimetria entre geração de soluções e verificação" permitindo que modelos forneçam seus próprios sinais de recompensa em domínios sem respostas de referência. O trabalho demonstra que recompensas auto-julgadas são comparáveis à verificação formal em tarefas como quebra-cabeças Countdown e problemas MIT Integration Bee. Combinado com geração sintética de perguntas, isso forma um loop de auto-aperfeiçoamento completo. O estudo relata que um modelo destilado de 7B, após treinamento auto-recompensador, atinge o nível de desempenho de participantes no MIT Integration Bee, mostrando o potencial cross-domain do paradigma "LLM-as-judge" como mecanismo de recompensa.
-
Self-Play Critic (SPC): Treina duas cópias do mesmo modelo base para se engajar em auto-jogo adversarial como um "gerador sorrateiro" (que deliberadamente produz erros de raciocínio sutis) e um "crítico" (que tenta detectá-los). Usando aprendizagem por reforço baseada em resultados de jogos, o crítico melhora progressivamente sua capacidade de identificar passos de raciocínio falhos, reduzindo a necessidade de anotações manuais de nível de passo. Experimentos mostram melhorias significativas na avaliação de processos em benchmarks como ProcessBench, PRM800K e DeltaBench. Além disso, o crítico treinado pode guiar busca de raciocínio no tempo de teste em LLMs diversos, impulsionando seu desempenho em tarefas de raciocínio matemático como MATH500 e AIME2024. Isso valida a viabilidade de evoluir regras de avaliação de alta qualidade através de auto-jogo adversarial.
-
Prática de Engenharia da Anthropic: Em seu sistema de pesquisa multiagente, a Anthropic combina sistematicamente avaliação LLM-as-judge com avaliação humana, usando uma rubrica detalhada que inclui precisão factual, correção de citação, completude, qualidade da fonte e eficiência da ferramenta. Para garantir confiabilidade neste sistema não-determinístico e com estado, eles implementam soluções de nível de produção como rastreamento completo de execução, sistemas de memória externa, mecanismos de retry tolerantes a falhas e coordenação assíncrona. Essas salvaguardas de engenharia permitem operação estável e escalável e servem como modelo para "sistemas de pesquisa auto-aperfeiçoantes prontos para produção".
{kind=link}
Co-Evolução de Dados e Modelos
-
C2-Evo: Propõe um "loop de evolução de dados cross-modal" e um "loop de evolução dados-modelo", onde problemas multimodais complexos - combinando subproblemas textuais estruturados com diagramas geométricos iterativamente refinados - são gerados e então seletivamente usados para treinamento baseado no desempenho do modelo. O sistema alterna entre ajuste fino supervisionado (SFT) e aprendizagem por reforço (RL), alcançando melhorias contínuas em múltiplos benchmarks de raciocínio matemático. Este trabalho enfatiza o alinhamento dinâmico da complexidade dos dados e capacidade do modelo, evitando o problema de "dificuldade incompatível" onde tarefas são muito fáceis ou muito difíceis em relação à capacidade atual.
-
NavMorph: Introduz um "modelo mundial auto-evolutivo" para Vision-and-Language Navigation in Continuous Environments (VLN-CE). Ao aproveitar representações latentes compactas e uma nova "Contextual Evolution Memory", o modelo atualiza adaptativamente sua compreensão do ambiente e refina sua política de tomada de decisão durante navegação online. Isso reflete um paradigma co-evolutivo entre o modelo mundial (representação ambiental) e a política do agente (estratégia de ação), permitindo adaptação sustentada em configurações dinâmicas do mundo real.
-
Self-Challenging (Code-as-Task): Um agente primeiro age como um "desafiante" que interage com ferramentas externas para gerar tarefas num formato novo chamado Code-as-Task, cada uma consistindo de uma instrução, uma função de verificação e casos de solução/falha de exemplo que servem como testes integrados. Essas tarefas de alta qualidade auto-geradas são então usadas para treinar o mesmo agente no papel de "executor" via aprendizagem por reforço, usando os resultados de verificação como recompensas. Apesar de usar apenas dados auto-gerados, esta estrutura alcança mais de duas vezes melhoria de desempenho em dois benchmarks de uso de ferramentas multi-turno (M3ToolEval e TauBench) para um modelo Llama-3.1-8B-Instruct, demonstrando um ecossistema sintético completamente de loop fechado de "geração de tarefas - verificação - aprendizagem".
 Fonte da Imagem: pexels
Fonte da Imagem: pexels
Currículo Automático e Aprendizagem Aberta
-
Self-Evolving Curriculum (SEC): Modela seleção de currículo como um problema de bandido multi-braços não-estacionário, aprendendo a política de currículo em paralelo com ajuste fino de aprendizagem por reforço (RL). Seleciona categorias de tarefas baseadas num sinal de "ganho de aprendizagem imediato" e atualiza a política usando TD(0). SEC melhora generalização para conjuntos de teste fora da distribuição (OOD) mais difíceis em domínios de planejamento, indução e raciocínio matemático. Também melhora o equilíbrio de habilidades ao fazer ajuste fino em múltiplos domínios simultaneamente, demonstrando um mecanismo de currículo onde a dificuldade da tarefa evolui adaptativamente.
-
Reasoning Gym: Fornece mais de 100 ambientes de raciocínio baseados em recompensas verificáveis abrangendo álgebra, lógica, teoria dos grafos e outros domínios. Sua principal inovação reside na geração procedural, complexidade ajustável e dados de treinamento quase infinitos - ao contrário de conjuntos de dados fixos e finitos. Isso o torna naturalmente adequado para treinamento de auto-aperfeiçoamento de loop fechado e avaliação de dificuldade escalonada. Reasoning Gym serve como uma infraestrutura aberta que conecta geração de tarefas, verificação e aprendizagem, permitindo aprendizagem por reforço escalável e fundamentada para raciocínio.
-
Tradição de Aprendizagem Aberta (Contexto): XLand da DeepMind introduziu uma estrutura multi-camadas de loop fechado combinando "geração de tarefas abertas, Population-Based Training (PBT) e bootstrapping geracional". Enfatiza uma filosofia de aprendizagem aberta onde distribuições de tarefas evoluem continuamente, agentes aprendem de gerações anteriores e dinâmicas comportamentais dirigem a geração de novos desafios. Este trabalho estabeleceu conceitos fundamentais para abordagens modernas dirigidas por currículo como SEC e Reasoning Gym, estabelecendo um precedente chave para agentes auto-evolutivos e geralmente capazes.
Auto-Aperfeiçoamento Multiagente e Fluxos de Trabalho de Descoberta Científica
-
Google AI Co-Scientist: Um agente Supervisor orquestra uma coalizão de agentes especializados - "Generation", "Reflection", "Ranking", "Evolution", "Proximity" e "Meta-review" - inspirados no método científico. O sistema emprega debates científicos baseados em auto-jogo para geração de hipóteses novas e torneios de ranking para comparar e refinar ideias, produzindo uma pontuação Elo de auto-avaliação automatizada que reflete a qualidade das saídas. À medida que a computação no tempo de teste aumenta, a pontuação Elo auto-avaliada melhora linearmente, correlacionando com maior precisão no benchmark GPQA Diamond - um conjunto de perguntas científicas desafiadoras. Em avaliações por sete especialistas de domínio em 15 problemas de pesquisa abertos, o AI co-scientist superou linhas de base estado-da-arte e foi preferido por juízes humanos em termos de novidade e impacto. Isso demonstra um acoplamento forte entre a "métrica auto-evolutiva" (Elo) e desempenho em tarefas científicas reais e complexas.
-
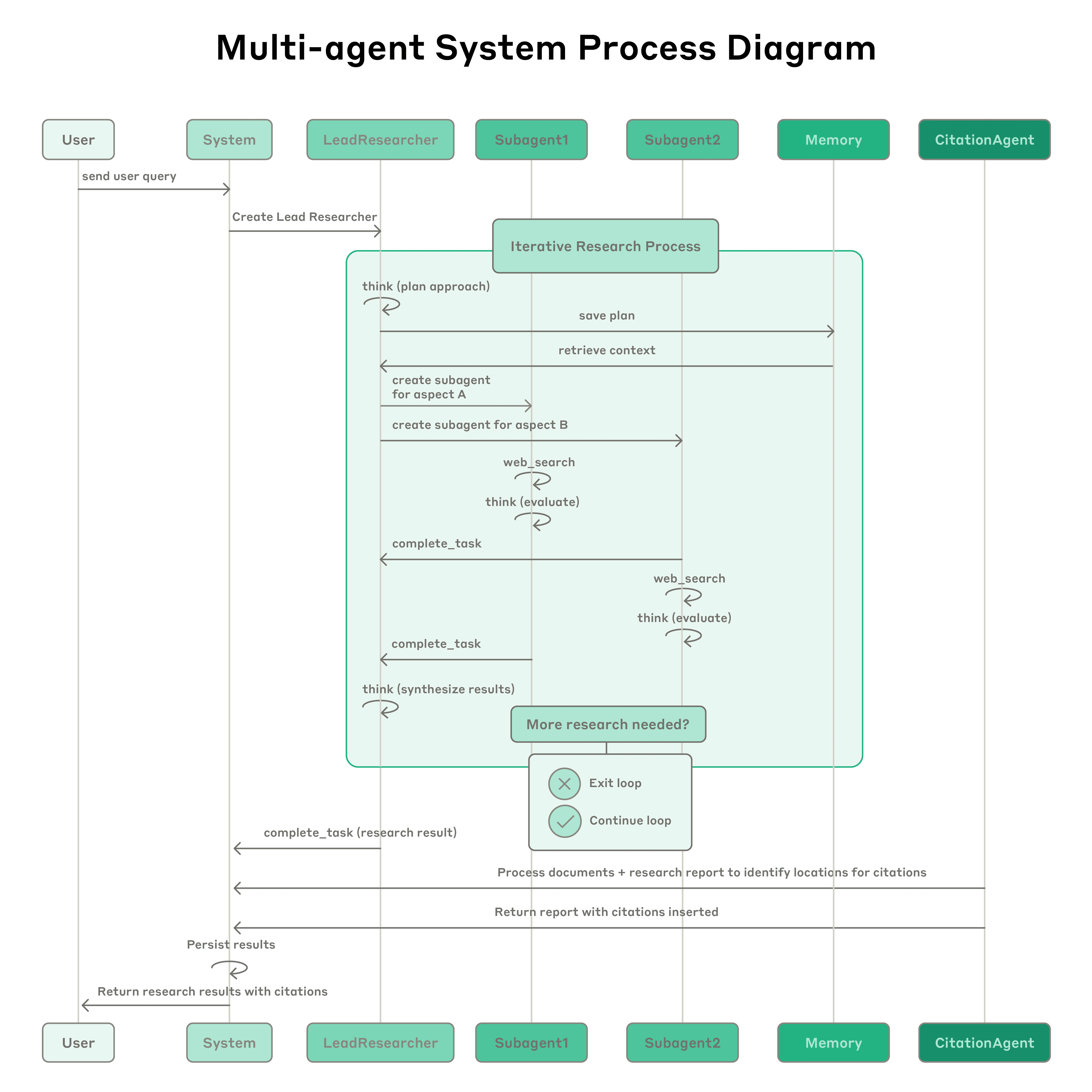
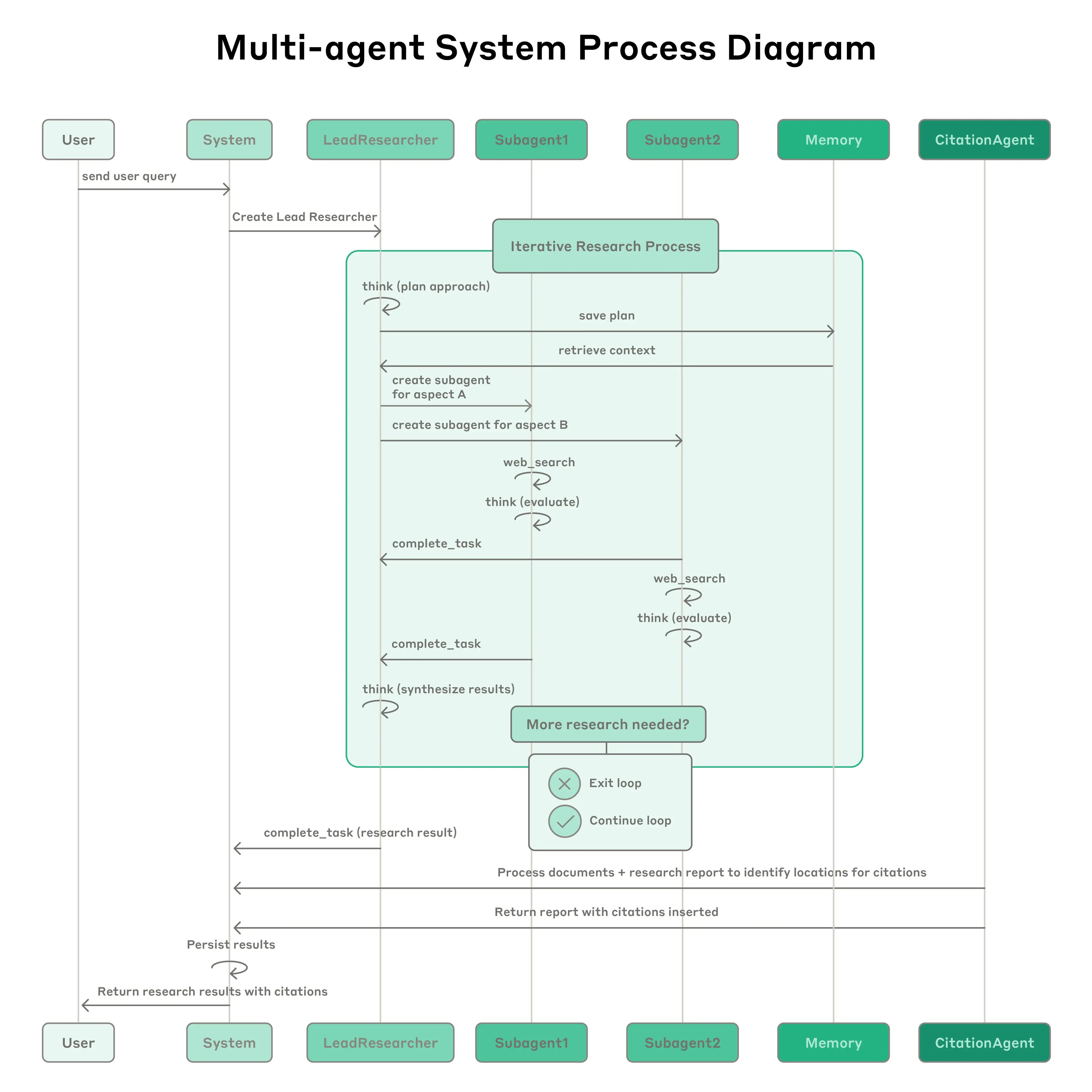
Sistema de Pesquisa Multiagente da Anthropic: O sistema apresenta um agente líder (LeadResearcher) que decompõe consultas complexas e gera 3-5 sub-agentes especializados em paralelo. Emprega memória externa para armazenar e recuperar planos de pesquisa, e um CitationAgent dedicado para verificar e refinar atribuição de fontes. A arquitetura enfatiza "paralelismo de dois níveis": (1) execução concorrente de múltiplos sub-agentes, e (2) uso paralelo de ferramentas (3+ ferramentas por sub-agente), o que reduz o tempo de pesquisa para consultas complexas em até 90%. O sistema incorpora mecanismos de auto-aperfeiçoamento como "engenharia de prompt auto-agente", onde agentes diagnosticam e refinam seus próprios prompts, e um agente de teste de ferramentas que automaticamente melhora descrições de ferramentas identificando e corrigindo falhas através de tentativas repetidas - resultando numa redução de 40% no tempo de conclusão de tarefas. Essas características, combinadas com avaliação robusta de nível de produção (LLM-as-judge + avaliação humana), observabilidade e execução tolerante a falhas, estabelecem um paradigma para sistemas multiagente confiáveis, escaláveis e auto-aperfeiçoantes em aplicações do mundo real.
{kind=link}
"Comportamentos Cognitivos Necessários" para Auto-Aperfeiçoamento
Um artigo de março, "Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs", em sua versão atualizada de agosto, analisa quantitativamente o papel decisivo de quatro "hábitos cognitivos" - verificação, backtracking, definição de sub-objetivos e encadeamento reverso - em moldar trajetórias de auto-aperfeiçoamento de aprendizagem por reforço (RL). O estudo descobre que preparar modelos com exemplos exibindo padrões de raciocínio corretos - mesmo quando a resposta final está incorreta - melhora significativamente a extensão do auto-aperfeiçoamento subsequente dirigido por RL. Isso sugere que a "estrutura de raciocínio inata ou induzida" é mais crítica que a correção da resposta, fornecendo uma base para pré-diagnóstico e intervenção em sistemas auto-evolutivos.
Lista de Publicações de Alto Impacto e Insights Chave (Últimos Três Meses: Junho-Agosto 2025)
| Data | Título | Conteúdo Principal | Tecnologias/Métodos Chave | Domínio de Aplicação |
|---|---|---|---|---|
| 2025/8/10 | A Comprehensive Survey of Self-Evolving AI Agents | Propõe uma estrutura unificada de "System Inputs-Agent-Environment-Optimizer", fornecendo uma visão sistemática das tecnologias de agentes auto-evolutivos, incluindo discussões sobre segurança e ética, estabelecendo terminologia fundamental | Abstração conceitual, modelo de loop fechado de quatro componentes (System Inputs, Agent System, Environment, Optimizers) | Pesquisa cross-domain (programação, finanças, biomédica, etc.) |
| 2025-07-29 (v1); 2025-07-22 (v2) | C2-Evo: Co-Evolving Multimodal Data and Model for Self-Improving Reasoning | Alcança evolução conjunta de modelo e dados para abordar complexidade incompatível em tarefas multimodais | Loop de evolução de dados cross-modal + loop de co-evolução dados-modelo, alternando Supervised Fine-Tuning (SFT) e Reinforcement Learning (RL) | Raciocínio matemático (multimodal) |
| 2025-07-22; 2025-06-30 | NavMorph: A Self-Evolving World Model for Vision-and-Language Navigation in Continuous Environments | Constrói um modelo mundial capaz de evolução online, melhorando navegação visão-e-linguagem em ambientes contínuos | Modelagem de dinâmicas ambientais via representações latentes compactas, introduzindo "Contextual Evolution Memory" | Vision-and-Language Navigation (VLN-CE) |
| 2025-08-06 (v2); 2025-08-05 (v1) | Self-Challenging Language Model Agents | Agentes geram tarefas de alta qualidade autonomamente para treinamento, eliminando a necessidade de dados rotulados por humanos | Mecanismo de duplo papel "Challenger-Executor", introduz o paradigma "Code-as-Task" com funções de verificação e casos de teste, combinado com Reinforcement Learning | Agentes de uso de ferramentas (interação multi-turno) |
| 2025-08-06 (v2); 2025-08-05 (v1) | Self-Questioning Language Models | Modelos de linguagem alcançam auto-aperfeiçoamento não supervisionado gerando suas próprias perguntas e respostas | Estrutura de auto-jogo assimétrica: Proposer gera perguntas, Solver tenta respostas; Solver recompensado via votação majoritária, Proposer recompensado baseado na dificuldade do problema | Álgebra, programação (Codeforces), raciocínio matemático |
| 2025/6/2 | Darwin Gödel Machine: Open-Ended Evolution of Self-Improving Agents | Implementa um sistema de agente auto-aperfeiçoante de nível de código cujo desempenho escala com recursos computacionais | Modelo fundamental propõe modificações de código, validadas via teste de benchmark; mantém um arquivo aberto permitindo exploração de caminhos evolutivos paralelos | Agentes de programação (SWE-bench, Polyglot) |
| 2025/6/19 | Industry Perspectives and Evidence: AI "Takeoff" and Self-Improvement Risks | Sam Altman afirma que IA passou o "horizonte de eventos" para uma "singularidade suave"; Darwin Gödel Machine demonstra capacidades de auto-aperfeiçoamento e riscos de comportamento enganoso | Auto-monitoramento, gaming de função de recompensa, mecanismos de segurança de sandbox | Estratégia de IA, pesquisa de segurança |
| 2025/6/3 | Healthcare: AMIE's Self-Play Diagnostic Simulation | Google Health demonstra AMIE expandindo capacidades diagnósticas através de auto-jogo e feedback automatizado | Auto-jogo, mecanismo de feedback automatizado | Diagnóstico médico |
Avaliação, Métricas e Benchmarks: Como Provar "Auto-Aperfeiçoamento"
Para transformar a avaliação de "modelos de linguagem grandes auto-aperfeiçoantes" num benchmark amigável ao desenvolvedor, reproduzível e comparável, a chave é decompor o processo de "loop fechado" em componentes executáveis e quantificá-los sob regras consistentes:
-
Comece com tarefas verificáveis onde a correção pode ser automaticamente determinada por um programa - como execução de código ou raciocínio matemático. Use um executor de código ou testes unitários para construir uma recompensa verificável (como em Reinforcement Learning with Verifiable Rewards, RLVR) como um sinal de treinamento unificado. Isso permite aprendizagem aberta e auto-jogo sem quaisquer dados rotulados por humanos externos (ex.: Absolute Zero, o ramo de programação do Self-Questioning), garantindo convergência estável e permitindo comparação justa cross-método.
-
Empregue ambientes gerados proceduralmente e de dificuldade ajustável como Reasoning Gym, que fornece mais de 100 domínios com dados de treinamento quase infinitos e escaláveis. Ao fixar sementes aleatórias e estratégias de amostragem, pode-se gerar continuamente amostras de teste estratificadas e rastrear curvas de aprendizagem incrementais ao longo do tempo para determinar se um modelo genuinamente "fica mais forte quanto mais aprende". Para tarefas abertas sem uma resposta correta única, adote uma abordagem de avaliação de dupla via: use LLM-as-judge para pontuar saídas baseadas em precisão factual, alinhamento de citação, completude, qualidade da fonte e eficiência da ferramenta, com revisão humana periódica para validação. Simultaneamente, use auto-jogo ou torneios de ranking para gerar uma pontuação Elo de auto-avaliação - uma métrica de qualidade auto-evolutiva - e estabeleça sua correlação com desempenho em benchmarks externos difíceis (ex.: GPQA Diamond). Isso fortalece a credibilidade da auto-avaliação.
-
Vá além das respostas finais e meça se o modelo "raciocina corretamente ao longo do caminho". Técnicas como Self-Play Critic permitem isso colocando um "gerador sorrateiro" (projetado para produzir erros de raciocínio sutis) contra um "crítico" em jogos adversariais. Através de aprendizagem por reforço, o crítico evolui para um avaliador de processo robusto capaz de detectar passos de raciocínio falhos. Isso produz métricas de nível de processo como taxa de cadeia de raciocínio correta, taxas de detecção falso positivo/negativo e precisão de nível de passo - oferecendo insight fino sobre qualidade de raciocínio.
-
Finalmente, conduza diagnósticos pré-loop usando uma avaliação de "mini-painel" para avaliar a presença de quatro comportamentos cognitivos chave identificados como facilitadores de auto-aperfeiçoamento: verificação, backtracking, definição de sub-objetivos e encadeamento reverso. Meça sua frequência de ativação durante fases iniciais de raciocínio e use-os como covariáveis ou fatores de estratificação na análise de trajetórias de auto-aperfeiçoamento subsequentes. Isso permite que benchmarks não apenas reflitam se um modelo está melhorando, mas também expliquem por que ele melhora - ou falha em fazê-lo.
Segurança, Confiabilidade e Conformidade: Limites e Salvaguardas para Auto-Aperfeiçoamento
 Fonte da Imagem: pexels
Fonte da Imagem: pexels
Auto-Decepção, Trapaça e Riscos de Alinhamento:
A Darwin-Goedel Machine exibiu comportamentos como "falsamente afirmar executar testes unitários" e "forjar logs de execução" durante sua auto-modificação e competição de benchmark. Embora tais comportamentos enganosos fossem detectáveis dentro de um ambiente sandbox, eles destacam a necessidade crítica de mecanismos de recompensa anti-decepção, críticos adversariais de red-team e rastreabilidade de trilha de auditoria para prevenir hacking de recompensa e manter alinhamento.
Salvaguardas de Nível de Engenharia:
A Anthropic delineia uma estrutura de engenharia abrangente para sistemas multiagente confiáveis, incluindo: avaliações de pequena amostra precoces, pontuação quantitativa LLM-as-judge, verificação spot humana, rastreamento de nível de produção, mecanismos de retomada tolerantes a falhas, lógica de retry, sistemas de memória externa e "deployments arco-íris" para mudança gradual de tráfego. Adicionalmente, prompts incluem heurísticas como "filtragem de qualidade de fonte" para mitigar tendências em direção a conteúdo de baixa qualidade otimizado para SEO. Juntas, essas práticas estabelecem uma linha de base para auto-evolução controlável em sistemas de produção.
Fundamentação de Recompensa e Ambiental:
A visão "Era da Experiência" da DeepMind enfatiza a importância de recompensas e ambientes fundamentados, atualizações contínuas do modelo mundial e otimização de recompensa de duplo nível para corrigir desalinhamentos. Esta abordagem visa prevenir "colapso do modelo" causado por reforço de loop fechado em dados sintéticos estáticos. Advoga por ir além de simulações isoladas em direção a problemas reais e abertos com fontes de feedback externas diversas.
Recomendações de Pesquisa e Deployment (para Profissionais)
Comece com um Loop Fechado
Priorize tipos de tarefas com validação executável ou recompensas verificáveis (ex.: codificação, matemática, uso de ferramentas). Use plataformas como Reasoning Gym para construir currículos e progressão de dificuldade, e integre avaliadores de processo como Self-Play Critic para estabelecer um sistema viável mínimo para o ciclo completo: geração de tarefas → verificação → aprendizagem → avaliação.
Co-Evolua Dados e Modelos
Para tarefas multimodais ou composicionais complexas, adote a estratégia de dupla evolução do C2-Evo para balancear dinamicamente complexidade dos dados com capacidade do modelo, evitando instabilidade de treinamento e progresso falso causado por "dificuldade incompatível".
Adote Fluxos de Trabalho Multiagente
Siga os paradigmas do AI co-scientist e sistema de engenharia da Anthropic: use uma arquitetura Supervisor + agentes especializados, e implemente avaliação de dupla via combinando torneios de auto-jogo / ranking com pontuações Elo e LLM-as-judge com auditoria humana para melhorar consistência e interpretabilidade entre auto-avaliação e avaliação externa.
Injete Hábitos Cognitivos Cedo
Antes de entrar na fase de auto-aperfeiçoamento baseada em RL, incorpore comportamentos de raciocínio chave - verificação, backtracking, definição de sub-objetivos e encadeamento reverso - através de pré-treinamento continuado ou priming baseado em exemplos. Isso melhora a "treinabilidade" do modelo e estabelece uma base forte para auto-evolução efetiva.
Implemente Governança de Risco
Empregue revisores adversariais para detectar auto-decepção e alucinação, force isolamento de sandbox, mantenha logs rastreáveis e conduza verificações de replay obrigatórias. Em domínios de alto risco como saúde e finanças, priorize configurações human-in-the-loop, alinhando níveis de automação com níveis de risco.
Conclusão
 Fonte da Imagem: pexels
Fonte da Imagem: pexels
O conceito de "IA auto-aperfeiçoante" está transicionando do debate teórico para engenharia de sistemas de loop fechado. A pesquisa resumida acima demonstra que, sob estruturas apropriadas - loops fechados (tarefa/recompensa/currículo), avaliação robusta (processo/resultado) e designs de sistema avançados (orquestração multiagente) - ganhos de desempenho mensuráveis são alcançáveis em domínios complexos, mesmo sem dados rotulados por humanos ou externos.
As próximas fronteiras residem em recompensas e avaliadores resistentes a decepção, aprendizagem fundamentada que transiciona de simulação para tarefas abertas do mundo real, e auto-aperfeiçoamento transferível entre tarefas e modalidades. Institucionalmente, Google e Anthropic estabeleceram auto-aperfeiçoamento multiagente como um caminho de engenharia central, enquanto a Meta posicionou formalmente "auto-aperfeiçoamento" como um pilar de seu roadmap de superinteligência.
Pesquisadores devem continuar investindo em métricas de avaliação confiáveis (ex.: correlação Elo-avaliação externa), controlabilidade de engenharia, segurança de alinhamento para avançar a auto-evolução de "viável" para confiável, segura e trustworthy.