Engenharia de contexto: quando o RAG não basta
10 de fevereiro de 2026Ollie @puppyone
Principais conclusões
- O RAG básico basta quando o corpus é pequeno, as perguntas são locais e a governança é leve; além disso, uma camada de contexto dedicada é necessária.
- Uma camada de contexto transforma o conhecimento em Know‑How estruturado (JSON/grafo), combina com indexação híbrida (dense + sparse + graph) e governa com proveniência, ACLs e versionamento.
- A recuperação aprimorada por grafo e árvore fecha brechas onde o RAG apenas vetorial falha em consultas entre documentos e globais; veja o trabalho da Microsoft Research sobre GraphRAG (2024).
- Orquestração de subagentes e orçamentos rígidos de resumo mantêm o contexto de alto sinal e testável, alinhado com as notas da Anthropic sobre engenharia efetiva de contexto.
- Governança não é opcional; o AI RMF da NIST coloca proveniência e controles de ciclo de vida no centro de sistemas confiáveis.
A rúbrica decisória contrarian: quando RAG basta vs. quando você precisa de uma camada de contexto
Comece simples e resista à infraestrutura prematura. Você provavelmente não precisa de uma camada de contexto se:
- Seu corpus é pequeno, em boa parte estático e vive em um ou dois sistemas.
- As perguntas são locais e de um único salto (ex.: "Qual a garantia do Produto X?").
- Os SLOs de latência são flexíveis e você tolera falhas ocasionais.
- A governança é leve; você não precisa de traços auditáveis ou ACLs rigorosas.
Você precisa de uma camada de contexto dedicada quando:
- Os dados vivem em Docs, Slack, Notion, bancos de dados e SaaS externos e mudam com frequência. Até empresas de busca investem em conectores; veja a aquisição da Carbon pela Perplexity em 2024: Perplexity welcoming Carbon.
- Os agentes devem responder perguntas globais ou entre documentos e planejar fluxos de trabalho multietapa. A recuperação apenas vetorial falha aqui; a equipe Microsoft descreve estratégias com grafos no arXiv 2024: A Graph RAG approach to query‑focused summarization.
- Você precisa de proveniência, controle de acesso, versionamento e rollback. Isso se alinha com a função GOVERN do NIST AI Risk Management Framework.
- Determinismo e testabilidade importam: você quer montagem de contexto reproduzível, traços de recuperação explicáveis e CI para atualizações de contexto. A orientação da Anthropic sobre subagentes e higiene de contexto apoia essa direção; veja Effective context engineering for AI agents.
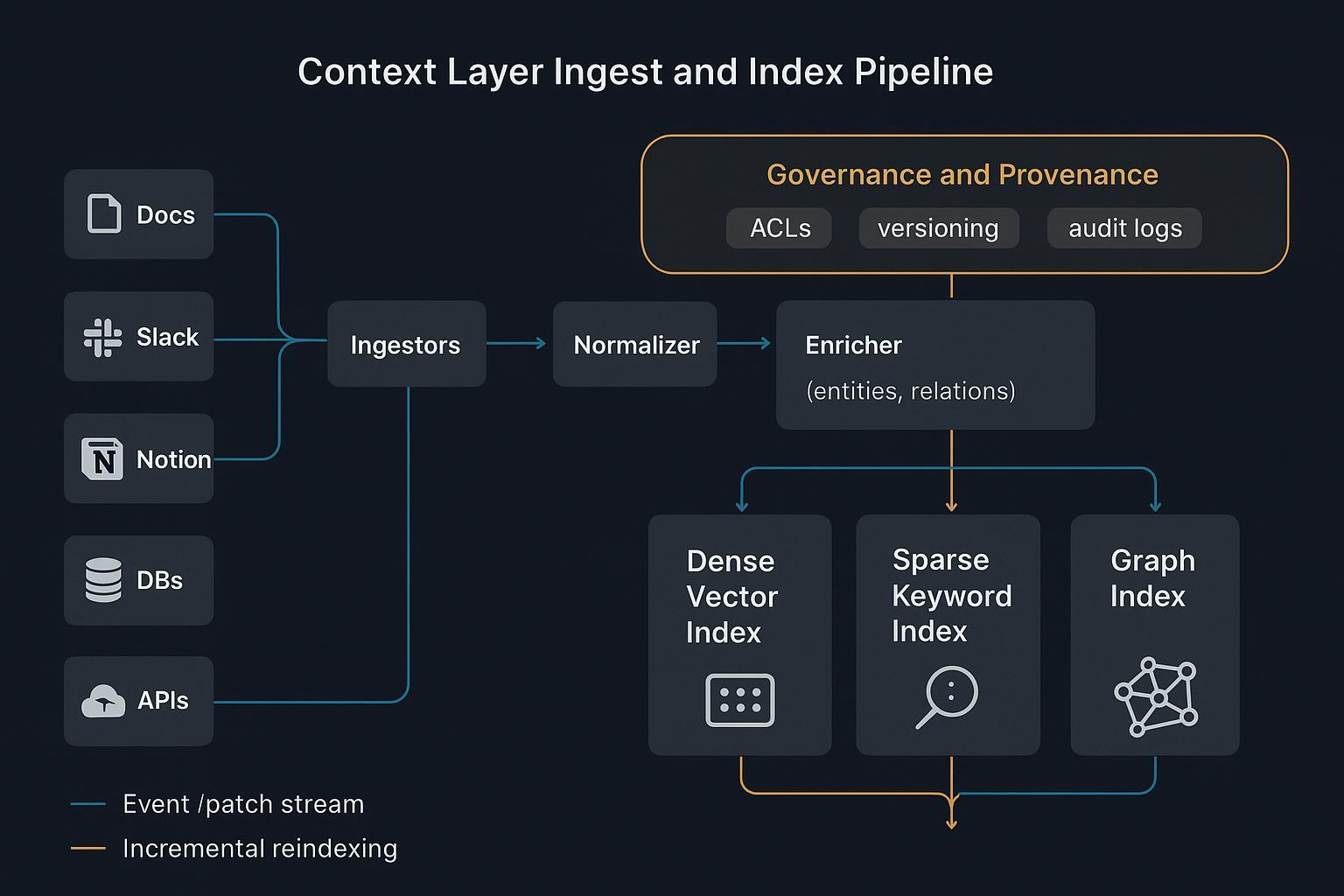
Arquitetura de engenharia de contexto além do RAG
Know‑How estruturado e esquemas
HTML não estruturado é ruído para máquinas. Uma camada de contexto transforma procedimentos, entidades, restrições e regras de negócio em Know‑How estruturado: documentos JSON e grafos com esquemas claros:
{
"entity": "PurchaseOrder",
"id": "PO-2026-1783",
"vendor": {"name": "Acme", "id": "V-882"},
"line_items": [
{"sku": "X12", "qty": 5, "unit_price": 49.00}
],
"approval_policy": {
"threshold": 10000,
"requires_dual_signoff": true,
"exceptions": ["emergency"]
},
"provenance": {"source": "ERP", "version": "v14.2", "ingested_at": "2026-02-06"}
}
Esse contexto esquematizado dá aos agentes lógica legível por máquina e proveniência para auditoria, em vez de depender de fragmentos de texto frágeis.
Indexação híbrida e roteamento
- A busca semântica densa encontra similaridade tópica rapidamente.
- Índices lexicais esparsos preservam termos exatos, IDs e linguagem de políticas.
- Estruturas grafo/árvore codificam relações e hierarquia para raciocínio multietapa.
Juntos permitem recuperação determinística: rotear por cluster ou vizinhança de grafo, depois compor um contexto mínimo e relevante. Padrões operacionais em Weaviate best practices for hybrid search.
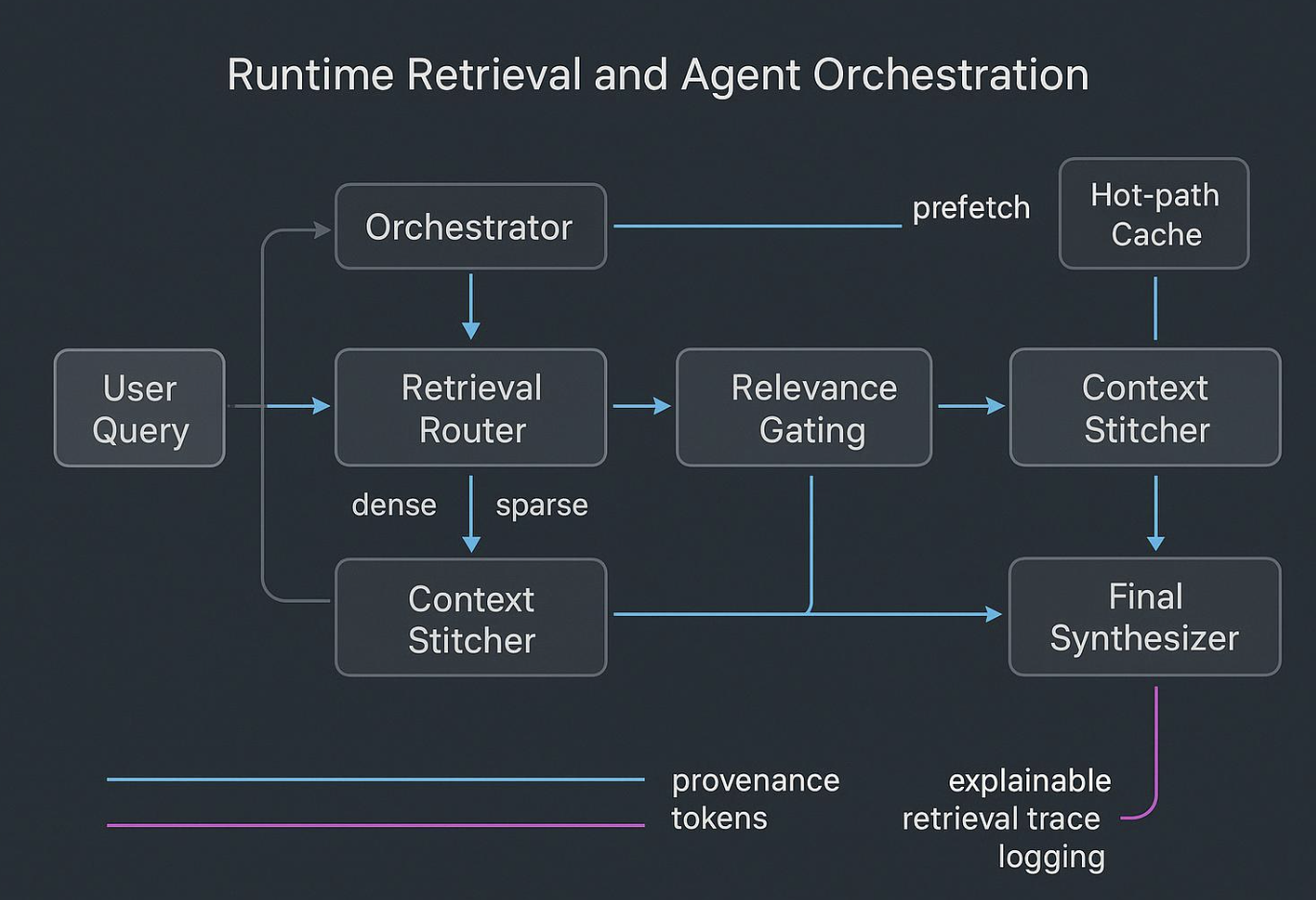
Costura e orquestração em tempo de execução
Os agentes falham quando tentam "pensar" sobre dumps brutos e ruidosos. O runtime deve ser assim:
- Um planner hipotetiza quais evidências e ferramentas são necessárias.
- Um router distribui consultas entre índices dense, sparse e graph.
- Um gate filtra por proveniência e política; um stitcher compõe um bundle compacto e bem delimitado.
- Subagentes executam tarefas estreitas e retornam resumos rígidos a um sintetizador.
# Pseudocódigo para recuperação híbrida + costura
plan = planner.make_plan(user_query)
results = []
for hop in plan.hops:
dense = dense_index.search(hop.query, k=10)
sparse = sparse_index.search(hop.query, k=10, filter=plan.filters)
graph_ctx = graph.walk(hop.entities, depth=2)
gated = gate.by_provenance(dense + sparse + graph_ctx)
stitched = stitch.compact(gated, budget_tokens=1200)
results.append(stitched)
final = synthesize(results, tools=plan.tools)
return final
Checklist do pipeline de contexto
- Ingerir fontes → normalizar → mapear ao esquema.
- Enriquecer com entidades e relações → armazenar como Know‑How estruturado.
- Construir índices híbridos (dense, sparse, graph) com metadados de proveniência.
- Aplicar gates com ACLs, versionamento e logs de auditoria.
- Avaliar fidelidade de recuperação e resultados ao nível de tarefa antes do deploy.
- Fazer deploy com caches de hot-path e prefetch.
- Monitorar latência, precisão/recall, drift e traços de auditoria.
Microbenchmark leve: latência vs. qualidade da resposta
Este design ajuda a comparar três padrões de recuperação. Manter pequeno e reproduzível.
Premissas: 50K documentos (políticas, tickets, especificações); 75 consultas de avaliação com ground truth em 40; mesmo LLM; paridade de hardware; reranker quando aplicável. Reportar latência mediana p50/p90 e qualidade via EM/F1 ou LLM-juiz documentado.
| Padrão | Stack de recuperação | Características esperadas |
|---|---|---|
| RAG ingênuo | Dense apenas | Rápido, menor coerência global; dificuldades em perguntas entre documentos |
| RAG afinado | Dense + sparse + reranker | Latência moderada, melhor precisão em IDs e termos de política |
| Camada de contexto | Híbrido + graph + costura + resumos | Latência p50 um pouco maior mas p90 mais apertada; respostas globais mais estáveis |
Interpretação: o RAG afinado corrige muitas lacunas fáceis; a camada de contexto brilha em tarefas entre documentos e multietapa, com latência de cauda mais previsível por roteamento e caches.
Modos de falha e mitigação
- Fragmentação entre documentos: construir grafos de entidade/relação e travessias locais/globais; adicionar âncoras hierárquicas em narrativas longas.
- Obsolecência e drift: ingestão event-sourced, reindexação incremental, TTLs; reproduzir changelogs em upgrades de esquema.
- Picos de latência sob carga: caches de hot-path em níveis, roteamento por cluster, prefetch para subconsultas comuns; dimensionar shards e habilitar quantização onde disponível.
- Alucinação por contexto ruidoso: impor esquemas e filtros de proveniência; estreitar escopos de subagentes; preferir resumos compactos a dumps brutos.
- Lacunas de governança: registrar traços de recuperação e chamadas de ferramentas; exigir linhas de evidência explicáveis; condicionar deploys a limiares de avaliação e planos de rollback.
Microexemplo prático: Know‑How estruturado e indexação híbrida em ação
Suponha que você constrói um agente de compras que deve aplicar políticas de aprovação ao montar cotações de fornecedores. Você ingere exportações ERP, PDFs de contratos, aprovações no Slack e resumos por email. O pipeline mapeia tudo a um esquema comum: PurchaseOrder, Vendor, Policy, Exception. Você enriquece com entity linking para que cada PurchaseOrder conheça seu Vendor e nós Policy aplicáveis. Depois constrói um índice denso para recall semântico, um esparso para IDs e termos legais, e um grafo para caminhos Policy → Exception → Approver.
Nesse setup, um loop de orquestração roteia uma consulta "Podemos aprovar PO‑2026‑1783 hoje?" via: busca esparsa do ID da PO, caminhada no grafo dessa PO até sua Policy e exceções, e recuperação densa de notas recentes de aprovadores. O stitcher compacta tudo em um bundle de 1,2K tokens e o agente produz uma resposta curta citada com decisão de aprovação e links para proveniência.
Uma plataforma como puppyone pode ajudar porque armazena conhecimento como Know‑How estruturado (JSON/grafo) e suporta indexação híbrida sobre texto e estrutura, permitindo padrões de recuperação determinísticos e traços auditáveis sem depender de scraping de texto frágil.
Governança e CI para contexto
Trate o contexto como código. Cada mudança deve ter proveniência, revisão e testes. Manter esquemas versionados, políticas de acesso e suites de avaliação. Antes de rollouts: executar verificações de fidelidade de recuperação e testes ao nível de tarefa; capturar traços explicáveis e manter rollback pronto. Se os agentes tocam dados regulados ou sensíveis, alinhar processos ao NIST AI Risk Management Framework. Para interop: Model Context Protocol.
Próximos passos
Comece com RAG afinado se o problema for local e de baixo risco. Se surgirem perguntas entre documentos, necessidades de governança ou corpus voláteis, planeje um piloto de camada de contexto focado em um workflow. Construa Know‑How estruturado primeiro; a indexação híbrida e a orquestração ficam bem mais simples quando os esquemas estão estáveis. Mantenha a avaliação apertada e humana: testar tarefas reais, registrar traços e vincular melhorias aos SLOs de negócio.
FAQs
Q1: Preciso de um grafo logo?
R: Não. Comece com dense + sparse; adicione grafo quando surgirem lacunas de raciocínio entre documentos ou de resumo global.
Q2: Qual tamanho para meus chunks?
R: Fragmentar por unidades semânticas ligadas ao seu esquema (entidades, procedimentos), não por contagem fixa de tokens. Deixe o resto para rerankers e resumos.
Q3: Posso adiar a governança?
R: Pode, mas pagará por isso. Adicione proveniência leve e controles de acesso desde o primeiro dia para que avaliação e rollbacks sejam possíveis.