Como implantar Agentic RAG para automação do atendimento ao cliente
8 de abril de 2026Lin Ivan
Atendimento ao cliente é um ambiente duro para LLMs: perguntas ambíguas, documentação desatualizada, dados sensíveis e erros que aparecem imediatamente para usuários reais.
Se você quer automação de suporte que aguente tráfego de produção, um demo simples de RAG não basta. Você precisa de um sistema agentic que roteie solicitações, encontre a evidência certa, use ferramentas com segurança e escale quando a confiança for baixa.
Defina o que "automação" significa antes do deploy
Muitos times pulam direto para o chatbot. O melhor começo é escolher quais workflows serão automatizados e o que significa "pronto" em cada um.
Escolha um modo de implantação
Pontos de partida comuns:
- Agent-assist: o sistema prepara resposta e evidências; uma pessoa envia.
- Automação parcial: intents estreitos e de baixo risco são resolvidos automaticamente.
- Automação ampliada: a maior parte dos intents é automatizada, mas só depois de forte validação.
Crie limites de "nunca automatizar"
Inclua pelo menos:
- ações financeiras acima de um limite
- mudança de titularidade de conta
- exportação de dados
- qualquer fluxo regulado ou de alto risco
Esses casos devem escalar imediatamente.
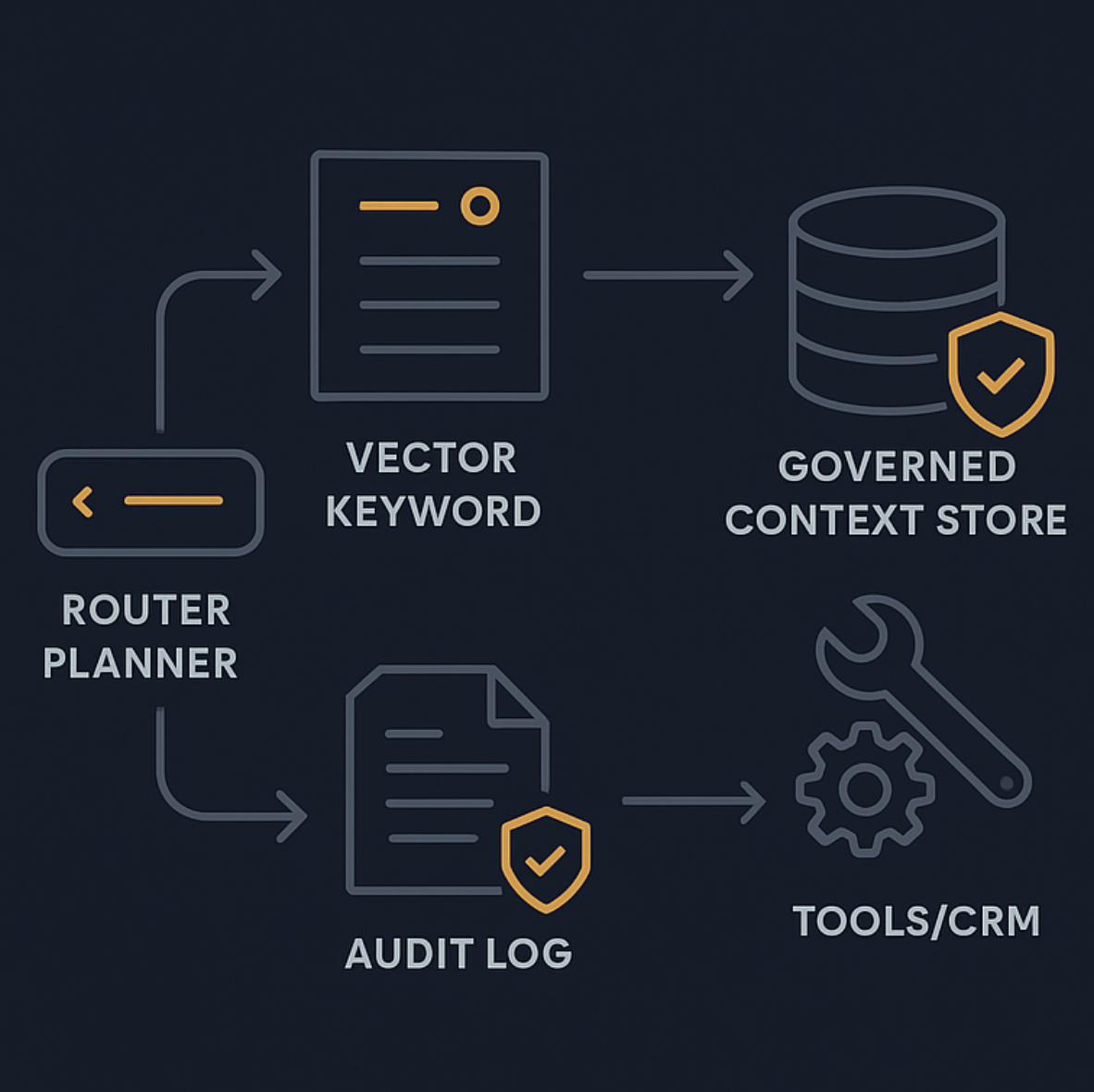
Arquitetura de referência: Agentic RAG para suporte
Um sistema de produção não é uma única pipeline. É um sistema de decisão com guardrails.
Uma forma útil de pensar nisso é a divisão em orchestration, execution e infrastructure, como em production-ready agentic RAG architecture and observability.
Orchestration: router + policy engine
Essa camada decide o próximo passo.
- classificar intents
- decidir se retrieval é realmente necessário
- escolher tools como CRM, pedidos e ticketing
- aplicar regras de escalonamento e limites de risco
Execution: retrieval + tools + síntese de resposta
Essa camada faz o trabalho:
- montar a query de retrieval
- buscar evidências com busca híbrida e reranking
- chamar tools com least privilege
- gerar resposta ancorada em evidências
Resultados de retrieval devem ser tratados como entrada não confiável.
Infrastructure: observabilidade, avaliação e confiabilidade
Você precisa de:
- traces por etapa
- sinais de groundedness e qualidade
- retries, timeouts e fallbacks
Se você não consegue responder que evidência foi usada e por que uma ação aconteceu, o sistema ainda não está pronto para produção.
Pré-requisitos de dados e retrieval
Se a documentação estiver bagunçada, o modelo errará com muita confiança.
1. Monte um corpus preparado para suporte
Normalmente inclui:
- help center público
- runbooks internos bem escopados
- políticas de reembolso, cancelamento e SLA
- changelogs de produto
2. Faça chunking preservando contexto
Muitos projetos de RAG falham silenciosamente aqui.
Vale priorizar fronteiras semânticas e acrescentar títulos ou resumos contextuais a cada chunk. Veja também best practices for chunking and hybrid retrieval in production RAG.
3. Use retrieval híbrido com reranking
Solicitações de suporte misturam strings exatas e intenção difusa.
Então, na prática:
- keyword search pega IDs e termos exatos
- vector search pega paráfrases
- reranking melhora o conjunto final
4. Adicione metadados de freshness e ownership
No mínimo:
- tipo de fonte
- timestamp da última atualização
- owner ou time
- tags de produto e versão
- classificação de sensibilidade
Como implantar Agentic RAG para suporte ao cliente
Cada etapa precisa de propósito, output e critério de conclusão.
Etapa 1: coloque um intent router e só faça retrieval quando necessário
Ação: classifique solicitações em poucos workflows.
Done when:
- você registra o intent escolhido por request
- você mede quantos requests realmente dispararam retrieval
Etapa 2: delimite tools com least privilege
Ação: separe o acesso a tools por intent e risco.
Exemplos:
- billing status pode ler faturas, mas não iniciar reembolso
- account access pode enviar link de reset, mas não mudar ownership
- não misture leitura sensível e escrita ampla sem gate humano
Etapa 3: aplique autorização no momento do retrieval
Em ambientes multi-tenant, um erro aqui é crítico.
O padrão mais robusto é aplicar permissões na fonte autoritativa e propagar identidade até o retrieval. AWS explica isso em retrieval-time authorization and identity propagation for RAG.
Etapa 4: trate o texto recuperado como não confiável
A base de conhecimento é uma cadeia de suprimentos.
Se conteúdo recuperado trouxer instruções maliciosas, o modelo pode segui-las. Por isso, use:
- sanitização de entradas e saídas
- separação rígida entre instruções do sistema e conteúdo recuperado
- confirmação antes de ações com efeito real
- logging completo
Etapa 5: crie um contrato de grounding
O modelo deve:
- responder perguntas de conhecimento apenas com base na evidência recuperada
- citar fontes
- recusar ou escalar quando a cobertura for insuficiente
Etapa 6: adicione verificação e escalonamento
Um verificador deve checar:
- contradição com políticas
- desalinhamento entre intent e evidência
- tentativa de ação proibida
Governança: contexto versionado, auditabilidade e colaboração segura
Tratar contexto como um saco de embeddings é arriscado em suporte.
Em produção, você precisa controlar:
- quem pode editar conhecimento
- o que mudou
- quando mudou
- qual versão embasou qual decisão
Um context layer governado com arquivos legíveis por agentes, escopo de acesso, versionamento e audit logs é uma abordagem sólida.
Avaliação e observabilidade antes de escalar
Sem medição, não há melhoria.
Métricas mínimas:
- retrieval quality
- faithfulness
- escalation rate
- latências p50/p95
- custo por classe de intent
Também vale montar um conjunto de avaliação com tickets reais.
Rollout: de shadow mode à automação
Stage 0: shadow mode
- o sistema roda em paralelo
- registra intents, retrieval, drafts e triggers de escalonamento
Stage 1: agent-assist
- humanos continuam enviando
- o sistema entrega draft e evidências
Stage 2: automação parcial
- automatize intents estreitos e de baixo risco
- mantenha fluxos críticos com intervenção humana
Stage 3: automação ampliada
Somente quando cada ação puder ser rastreada até sua evidência e houver rollback e kill-switch operacional.
Troubleshooting: falhas comuns
Resposta confiante sem evidência
- recusar abaixo de um limiar de confiança
- exigir citações
- refinar o routing
Recuperação da policy errada
- usar freshness metadata
- criar regras de precedência
- detectar drift e permitir rollback
Prompt injection via conteúdo recuperado
- tratar como untrusted
- adicionar gates para tools
- separar nitidamente sistema e conteúdo
Picos de latência
- retrieval condicional
- cache para intents frequentes
- reranking só onde importa
Key takeaways
- Agentic RAG para suporte é um sistema de workflow com router, retrieval, tools, verificação e escalonamento.
- As partes difíceis são operacionais: autorização, defesa contra injection, avaliação e rollout gradual.
- Governança importa porque contexto e decisões precisam ser auditáveis e reversíveis.
Next steps
Se você já está ligando RAG e tools e começou a esbarrar em permissões, auditoria ou rollback, vale revisar: