O RAG não morreu, o RAG agêntico é simplesmente melhor
27 de novembro de 2025Guanqun @puppyone
TL;DR: Este é um projeto de código aberto: https://github.com/puppyone/DeepWideResearch
Ele substitui pipelines de RAG frágeis por fluxos de trabalho agênticos, resolvendo o pesadelo da manutenção e a queda de qualidade.
A troca é real: o RAG agêntico custa mais (> US$ 0,10/consulta vs. ~US$ 0,01 para o RAG tradicional) e é mais lento (>10s+ vs. menos de 3s). Se você precisa de respostas em menos de um segundo em grande escala, isso não é para você. Mas se você precisa de um QA de conhecimento preciso e sustentável, continue lendo.
Vou compartilhar nossa experiência na construção da nova arquitetura de RAG agêntico e explorar por que o RAG agêntico é o passo crítico para o QA de conhecimento empresarial.
No último ano, entreguei 5 projetos de RAG tradicional, cada um envolvendo de 100 a 1.000 páginas de documentação. A pilha de tecnologia era padrão: Escrita de Consulta (Query Writing), Roteamento de Consulta (Query Routing), Divisão (Chunking), Embedding, Reclassificação (Reranking), etc. No início, tudo correu bem, mas logo caímos em uma armadilha: todo o processo era extremamente rígido e difícil de manter.
A constatação mais dolorosa veio com uma alteração em um documento. Uma simples mudança fez com que a pontuação geral do RAG caísse. Para manter a mesma pontuação, tivemos que reconstruir toda a nossa estratégia de pipeline do zero. Cada nova fonte de dados parecia uma nova guerra a ser travada. Tentamos remendar com marcação de metadados complexa e divisão refinada (fine-grained chunking), mas eram apenas paliativos em uma arquitetura quebrada.
Começamos a nos perguntar: O que estamos fazendo de errado?
O problema era a lógica. O RAG tradicional consiste essencialmente em escrever regras if-else codificadas para se ajustar a um conjunto de dados (curve-fit). Isso funciona para código estático, mas falha quando você precisa de inteligência real.
Inspirado pelo Deep Research da OpenAI, decidi abandonar o pipeline rígido.
Mudei para uma arquitetura Agêntica + MCP (Model Context Protocol). A ideia é simples: em vez de uma cadeia de recuperação complexa, damos ao Agente ferramentas para pesquisar cada fonte de dados diretamente.
Aqui está a arquitetura do sistema:
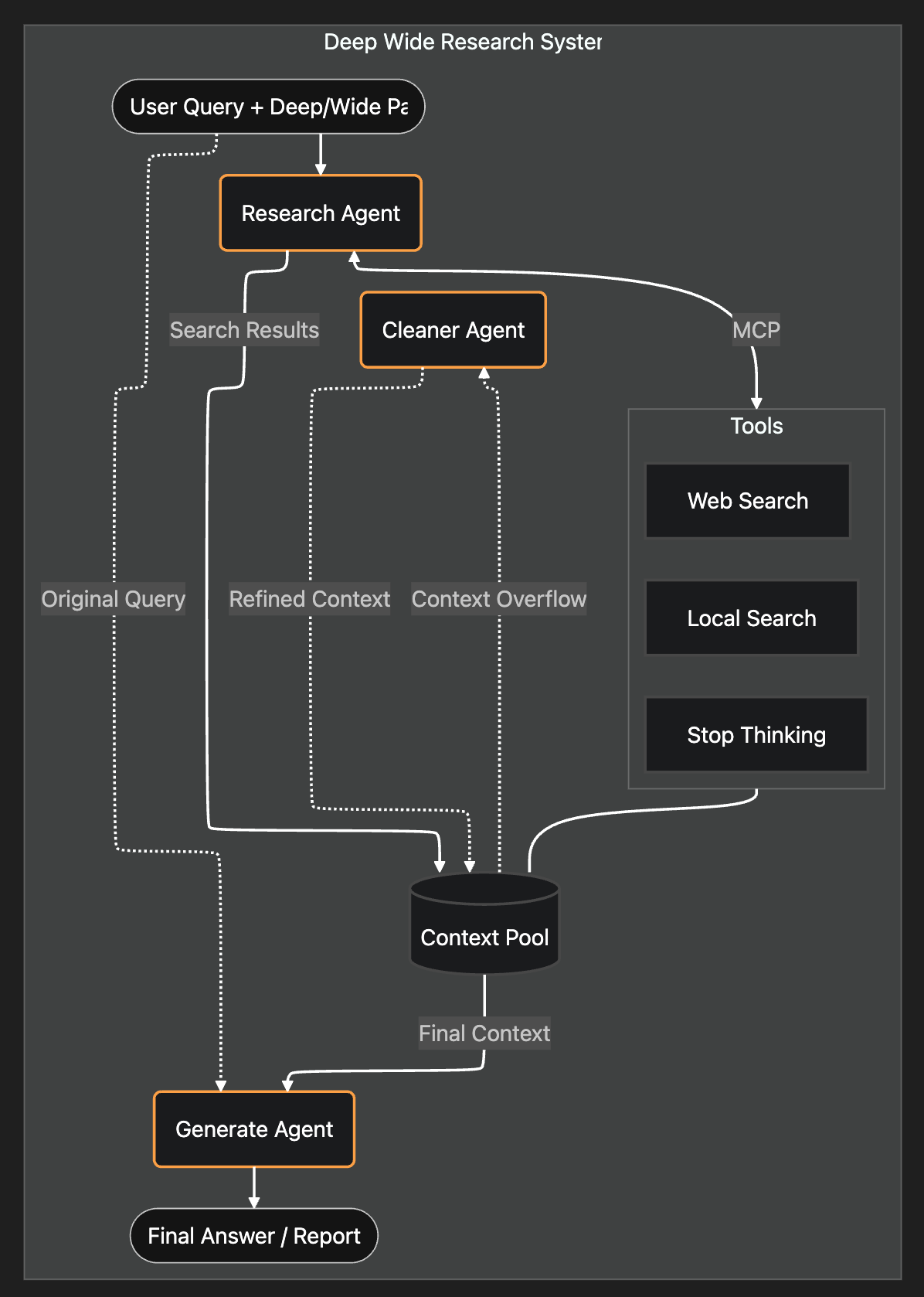
1. Como construir o Agente de Pesquisa?
O RAG agêntico substitui todo o pipeline de recuperação por um único Agente de Pesquisa autônomo.
Em vez de codificar reescritas ou regras de roteamento, configurei dois agentes: um Pesquisador (Researcher) e um Gerador (Generator).
Dei ao Pesquisador três ferramentas simples:

<Stop_thinking><Web_search><Local_search>
Mas dar ferramentas a um Agente não é suficiente. Você precisa dizer a ele quando parar.
Em vez de um loop while simples ou um número fixo de passos, forcei o Agente a executar um Passo de Autorreflexão antes de cada ação.
Não usamos um loop simples ou contagem de iterações. Em vez disso, forçamos o Agente a autorrefletir antes de cada movimento usando uma "Verificação de Prontidão do Artigo":
## Verificação de Prontidão do Artigo:
- Eu poderia escrever uma resposta e um artigo abrangentes e detalhados AGORA MESMO? (Sim/Não)
- Se eu escrevesse agora, quais seções estariam fracas, vagas ou sem exemplos/dados concretos?
- Tenho fatos, números e exemplos específicos suficientes para apoiar cada afirmação?
Somente quando essa verificação é aprovada, o Agente chama <Stop_thinking>. Testamos isso com modelos SOTA (Gemini 3 pro / Claude 4.5 Opus / GPT-5), e eles seguiram a lógica perfeitamente.
Todos os resultados da pesquisa são armazenados em um Pool de Contexto compartilhado. Assim que o Pesquisador sinaliza "Parar", um Agente Gerador pega o Pool de Contexto e escreve a resposta final.
Os resultados superam qualquer pipeline que já construímos. É a Inteligência vencendo a Estrutura rígida.
Essencialmente, mapeamos os componentes do RAG tradicional para comportamentos dinâmicos do Agente:
- Roteamento de Consulta? -> O Agente escolhe a ferramenta certa.
- Reescrita de Consulta? -> O Agente preenche os argumentos da função.
- QA de múltiplos saltos (Multi-hop)? -> O Agente decide quando chamar
<Stop_thinking>. - Reclassificação (Reranking) -> O Agente gera a resposta com base no pool de contexto.
2. Lidando com o estouro de contexto
Encontrei o segundo problema: o que acontece quando o Contexto pesquisado fica muito longo?
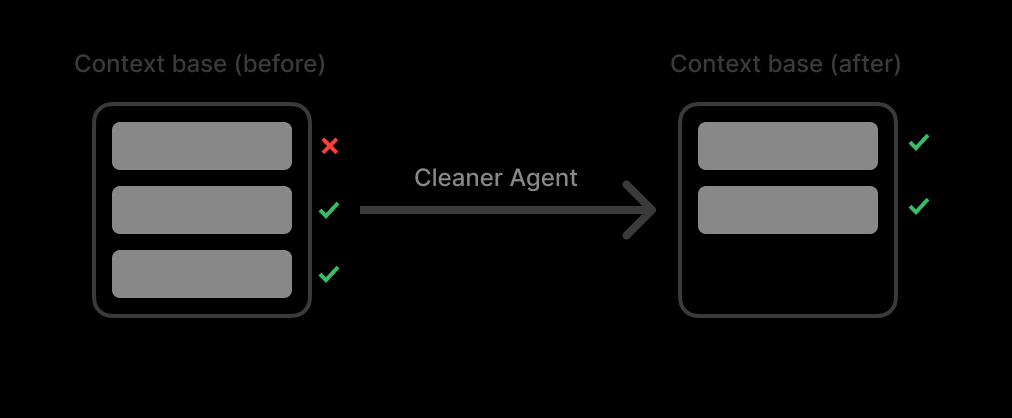
Eu criei um Pool de Contexto. Esse pool funciona como uma lista de todos os resultados da pesquisa. Criei um Agente de Limpeza (Cleaner Agent) para limpar o contexto quando o pool de contexto atinge o limite (90% do máximo de tokens).
O truque é: Não resuma. A sumarização mata os detalhes.
Em vez disso, o Agente de Limpeza funciona como um filtro de lixo. Ele exclui fontes irrelevantes inteiras, mantendo as relevantes 100% originais e intactas.
Finalmente, um Agente Gerador produz a resposta final com base no conteúdo refinado no Pool de Contexto e na Consulta original.
3. A solução "Deep-Wide" para Custo e Latência
Logo enfrentei um terceiro desafio: A Barreira de Custo e Latência.
Deixe-me ser honesto sobre os números:
- Latência: O RAG agêntico tem um piso de ~10 segundos — o loop de raciocínio é o gargalo, e não conseguimos ficar abaixo disso. O RAG tradicional pode responder em menos de 3s.
- Custo: Com o GPT-5, espere algo em torno de ~US$ 0,05 a US$ 1 por consulta. O RAG tradicional com embeddings custa ~US$ 0,005 a US$ 0,01.
Para tornar essa troca controlável acima desse piso, introduzi a "Pesquisa Profunda e Ampla" (Deep-Wide Research):
- Profunda (Deep): Controla os passos iterativos de raciocínio. Varia de ~10s (mínimo) a mais de 5 minutos (profundidade máxima para relatórios abrangentes).
- Ampla (Wide): Controla a expansão paralela de consultas. Mais amplitude = mais fontes exploradas = maior custo de tokens.
PROFUNDIDADE × AMPLITUDE ≈ Custo. Ao ajustar essas duas dimensões, você pode controlar o Tempo de Resposta (10s ~ 5min), a Qualidade e o Custo — mas não pode ficar abaixo do piso de 10s.
Tornamos o DEEP WIDE RESEARCH de código aberto. URL do Projeto: https://github.com/puppyone/DeepWideResearch (Licença Apache)
O que isso não resolve
Este projeto aborda metade do problema do RAG agêntico: o lado do "Raciocínio e Pesquisa".
A outra metade: lidar com dados empresariais privados permanece sem solução aqui:
- Limpeza de documentos empresariais desorganizados
- Construção de índices otimizados para o consumo do Agente
- Controle de permissão granular
Estamos trabalhando nisso separadamente. Se você encontrar esses problemas ou tiver ideias, adoraria ouvir de você: [email protected]