上下文工程:当 RAG 不够用时
2026年2月10日Ollie @puppyone
核心要点
- 当语料小、问题局部、治理轻时,基础 RAG 足够;超出则需专用上下文层。
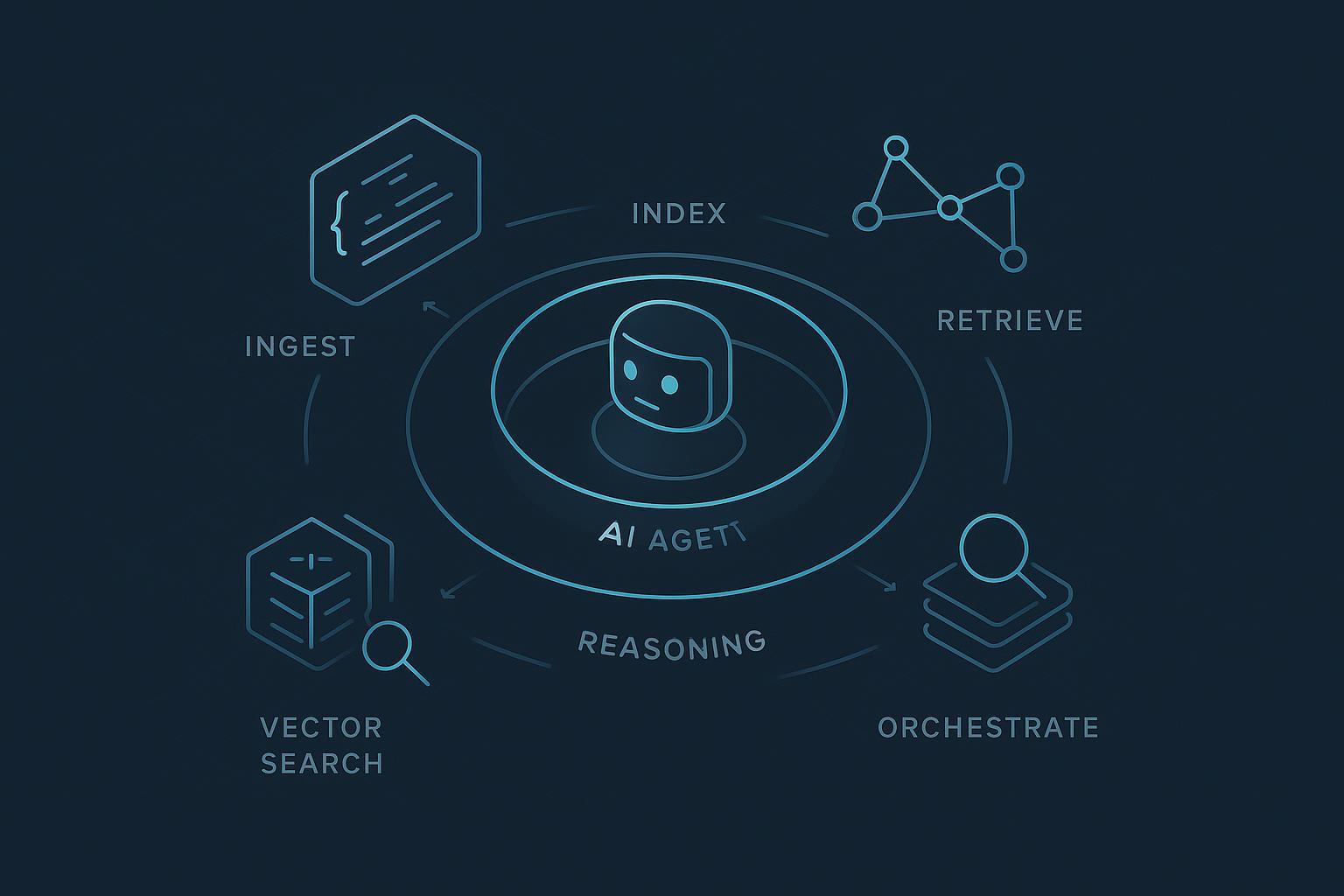
- 上下文层将知识重塑为结构化 Know‑How(JSON/图),与混合索引(dense + sparse + graph)配合,并通过出处、ACL、版本管理进行治理。
- 图与树增强的检索可填补纯向量 RAG 在跨文档与全局查询上的不足,参见 Microsoft Research 的 GraphRAG(2024)。
- 子智能体编排与严格的摘要预算使上下文保持高信号、可测试,与 Anthropic 关于有效上下文工程的技术说明一致。
- 治理不是可选项;NIST AI RMF 将出处与生命周期控制置于可信系统的中心。
反直觉决策框架:RAG 何时足够 vs. 何时需要上下文层
从简单开始,抵制过早基建。以下情况下通常不需要上下文层:
- 语料小、基本静态,且集中在一两个系统内。
- 问题为局部、单跳(例如:“产品 X 的保修是?”)。
- 延迟 SLO 可放宽,能容忍偶尔检索失败。
- 治理轻;不需要可审计的追溯或严格的 ACL。
当满足以下一项或多项时,需要专用上下文层:
- 数据分散在 Docs、Slack、Notion、数据库和外部 SaaS,且经常变动。搜索公司也在投连接器;见 Perplexity 2024 年收购 Carbon:Perplexity welcoming Carbon。
- 智能体需回答全局或跨文档问题,并规划多步工作流。纯向量检索在此失效;Microsoft 团队在 arXiv 2024 中概述了图增强策略:A Graph RAG approach to query‑focused summarization。
- 需要出处、访问控制、版本管理与回滚。这与 NIST AI Risk Management Framework 中的 GOVERN 职能一致。
- 确定性可测性重要:需要可复现的上下文组装、可解释的检索追溯,以及上下文更新的 CI。Anthropic 关于子智能体与严格上下文卫生的指导支持此方向;参见 Effective context engineering for AI agents。
超越 RAG 的上下文工程架构
结构化 Know‑How 与模式
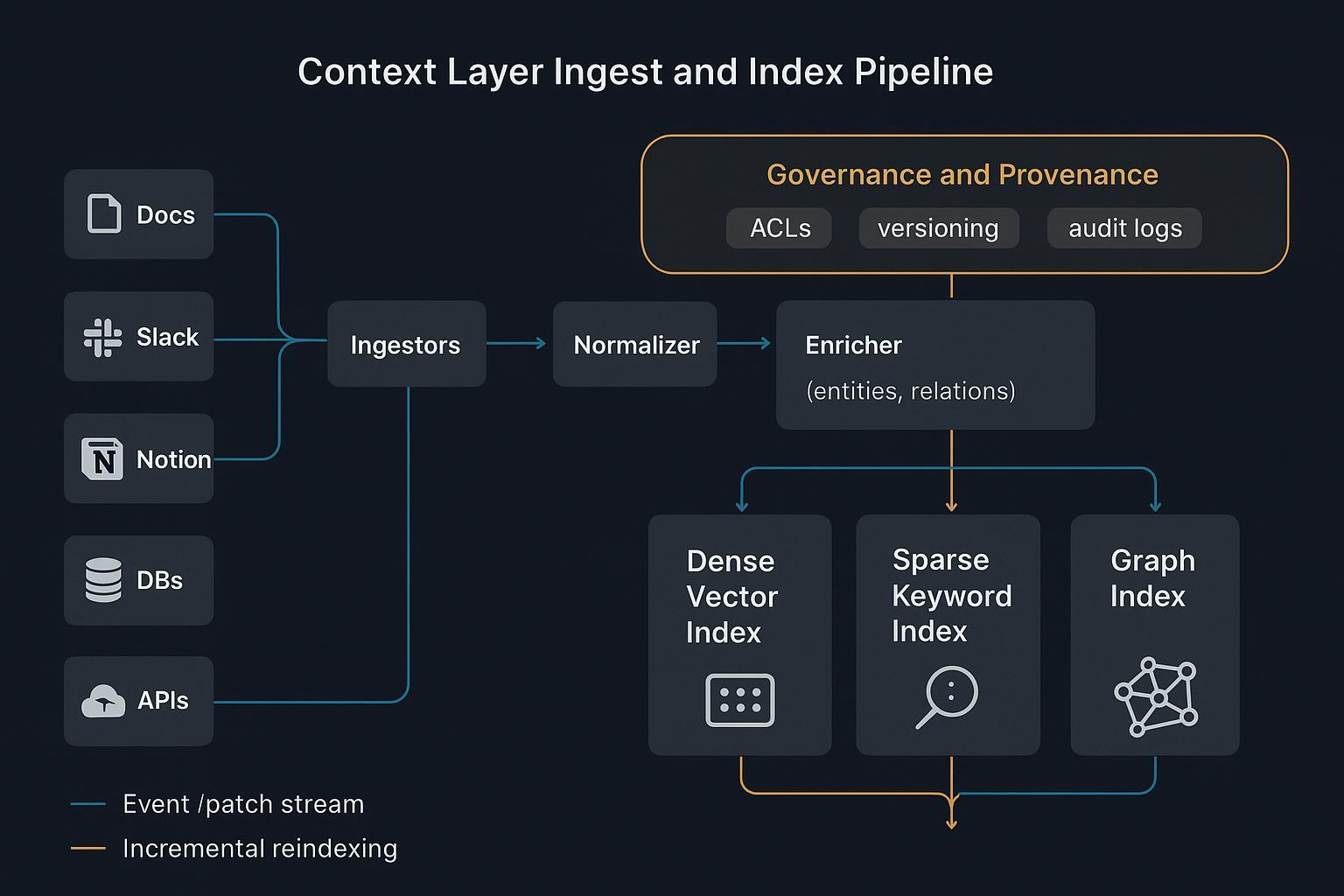
非结构化 HTML 对机器是噪声。上下文层将流程、实体、约束与业务规则转化为结构化 Know‑How:带清晰模式的 JSON 文档与图:
{
"entity": "PurchaseOrder",
"id": "PO-2026-1783",
"vendor": {"name": "Acme", "id": "V-882"},
"line_items": [
{"sku": "X12", "qty": 5, "unit_price": 49.00}
],
"approval_policy": {
"threshold": 10000,
"requires_dual_signoff": true,
"exceptions": ["emergency"]
},
"provenance": {"source": "ERP", "version": "v14.2", "ingested_at": "2026-02-06"}
}
这种带模式的上下文给智能体提供机器可读逻辑与可审计出处,而不是依赖脆弱的文本片段。
混合索引与路由
- 稠密语义检索快速找到主题相似性。
- 稀疏词法索引保留精确术语、ID 与政策表述。
- 图/树结构编码关系与层级,支持多跳推理。
组合起来实现确定性检索:按集群或图邻域路由,再缝合出最小、相关的上下文。运维实践见 Weaviate best practices for hybrid search。
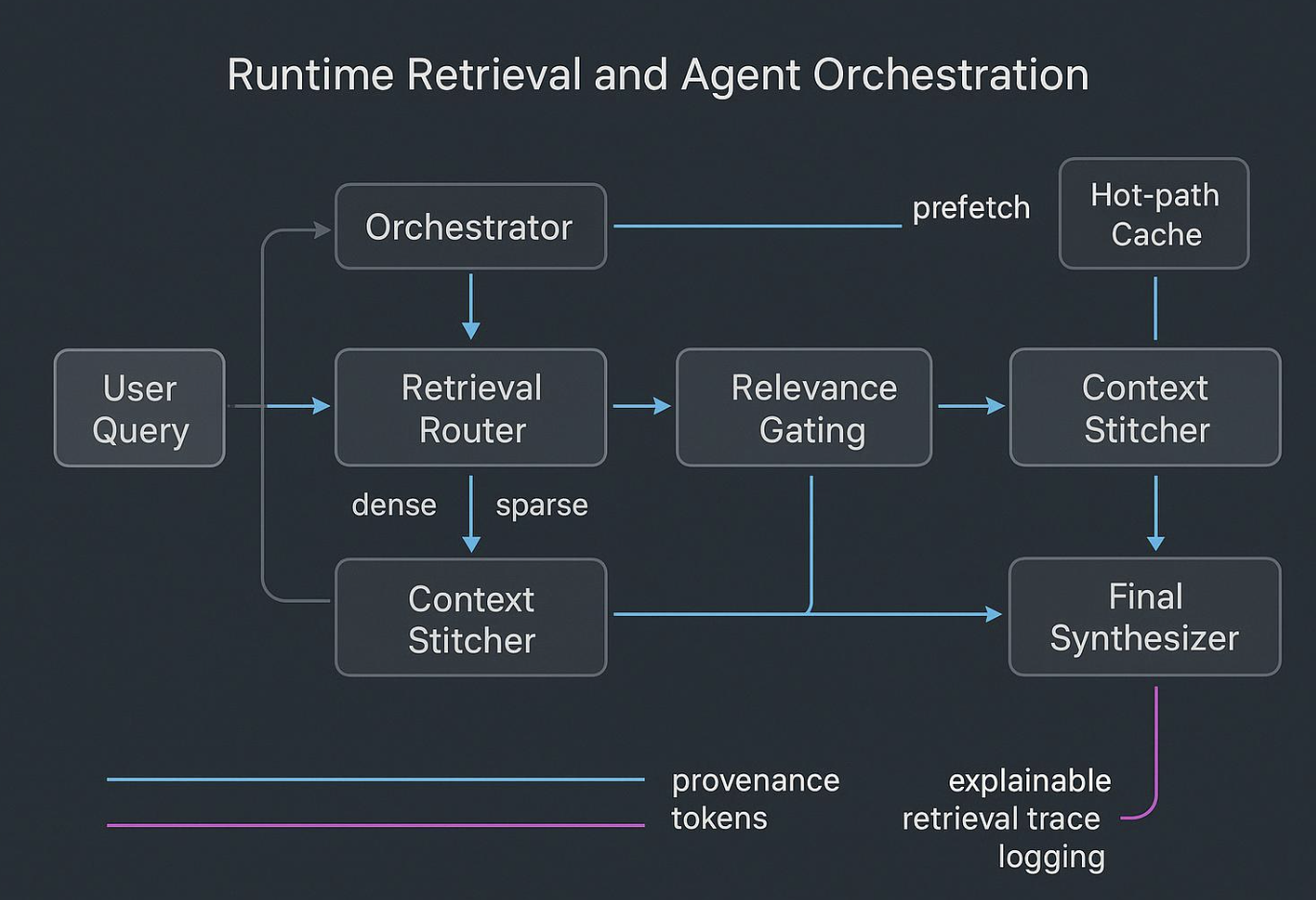
运行时拼接与编排
智能体在试图对原始、噪声大的 dump 进行“思考”时会失败。运行时应呈现为:
- 规划器假设所需证据与工具。
- 路由器将查询分散到 dense、sparse 与 graph 索引。
- 闸门按出处与策略过滤;缝合器将结果组装为紧凑、范围明确的 bundle。
- 子智能体执行窄任务,向综合器返回严格摘要。
# 混合检索 + 缝合的伪代码
plan = planner.make_plan(user_query)
results = []
for hop in plan.hops:
dense = dense_index.search(hop.query, k=10)
sparse = sparse_index.search(hop.query, k=10, filter=plan.filters)
graph_ctx = graph.walk(hop.entities, depth=2)
gated = gate.by_provenance(dense + sparse + graph_ctx)
stitched = stitch.compact(gated, budget_tokens=1200)
results.append(stitched)
final = synthesize(results, tools=plan.tools)
return final
上下文流水线检查清单
- 摄取来源 → 规范化 → 映射到模式。
- 用实体与关系富化 → 存储为结构化 Know‑How。
- 构建带出处元数据的混合索引(dense、sparse、graph)。
- 用 ACL、版本管理与审计日志做闸门控制。
- 部署前评估检索保真度与任务级结果。
- 使用热路径缓存与预取进行部署。
- 监控延迟、精确率/召回、漂移与审计追溯。
轻量微基准:延迟 vs. 答案质量
该设计便于比较三种检索模式。保持小规模与可复现。
假设:5 万文档(政策、工单、产品规格);75 个评估查询,其中 40 个有 ground truth;同一 LLM;硬件一致;在适用处启用 reranker。报告 p50/p90 中位延迟及通过 EM/F1 或文档化 LLM 评判的答案质量。
| 模式 | 检索栈 | 预期特征 |
|---|---|---|
| 朴素 RAG | 仅 Dense | 快,全局连贯性较低;在跨文档问题上吃力 |
| 调优 RAG | Dense + sparse + reranker | 中等延迟,在 ID 与政策用语上精度更高 |
| 上下文层 | Hybrid + graph + 缝合 + 摘要 | p50 延迟略高但 p90 更紧;全局答案更稳定 |
解读:调优 RAG 可修正许多简单遗漏;上下文层在跨文档与多步任务上表现更佳,因路由与缓存使尾部延迟更可预测。
故障模式与缓解
- 文档间碎片化:构建实体/关系图,使用局部/全局遍历收集连贯 bundle;为长叙述添加层级锚点。
- 陈旧与漂移:采用事件溯源摄取、增量重索引与 TTL;在模式升级时重放 changelog。
- 负载下延迟尖峰:使用分层热路径缓存、集群路由与常见子查询预取;合理调整分片大小并启用量化。
- 噪声上下文导致幻觉:强制模式与出处过滤;缩小子智能体范围;优先紧凑摘要而非原始 dump。
- 治理缺口:记录检索追溯与工具调用;要求可解释的证据链;用评估阈值与回滚计划对部署做闸门控制。
实践微例:结构化 Know‑How 与混合索引实战
假设你在构建采购智能体,需在汇总供应商报价时应用审批政策。摄取 ERP 导出、合同 PDF、Slack 审批与邮件摘要。摄取流水线将它们映射到公共模式:PurchaseOrder、Vendor、Policy、Exception。用实体链接富化,使每条 PurchaseOrder 知道其 Vendor 与适用 Policy 节点。然后构建稠密索引做语义召回、稀疏索引捕获 ID 与法律用语、图索引导航 Policy→Exception→Approver 路径。
在此设置下,编排循环通过以下方式路由“今天能否批准 PO‑2026‑1783?”的查询:PO ID 的稀疏查找、从该 PO 到其 Policy 及例外的图遍历、以及最近审批人备注的稠密检索。缝合器将上述内容压缩为 1.2K token bundle,智能体产出带审批决定与出处链接的简短引用回答。
puppyone 这类平台可提供支持,因其将知识存储为结构化 Know‑How(JSON/图)并支持文本与结构的混合索引,从而在不必依赖脆弱文本抓取的情况下实现确定性检索模式与可审计追溯。
上下文的治理与 CI
像对待代码一样对待上下文。每次变更都应有出处、审查与测试。维护带版本的模式、访问策略与评估集。在发布前执行检索保真度检查与任务级测试;捕获可解释追溯并保持回滚就绪。若智能体涉及受管制或敏感数据,请将流程与 NIST AI Risk Management Framework 中的 GOVERN 对齐。互操作性见 Model Context Protocol。
后续步骤
若问题局部且风险低,先从调优 RAG 开始。若出现跨文档问题、治理需求或波动语料,则规划聚焦单一工作流的上下文层试点。先构建结构化 Know‑How;模式稳定后,混合索引与编排会大幅简化。保持评估紧密且人性化:测试真实任务、记录追溯、将改进绑定到业务 SLO。
FAQs
Q1: 是否需要一开始就上图?
A: 不需要。先上 dense + sparse;当出现跨文档推理或全局摘要缺口时再加图。
Q2: 分块应多大?
A: 按与模式绑定的语义单元(实体、流程)分块,而非固定 token 数。其余交给 reranker 与摘要。
Q3: 能否推迟治理?
A: 可以,但会付出代价。从第一天起加入轻量出处与访问控制,以便评估与回滚成为可能。