客户服务是 LLM 最难落地的场景之一:问题模糊、文档过时、数据敏感,而且一旦出错,真实用户会立刻感知到。
如果你想做出能扛生产流量的客服自动化,单纯的 RAG demo 远远不够。你需要的是一个 agentic 系统:它能路由请求、检索证据、安全调用工具,并在没有把握时及时升级给人工。
在部署前,先定义“自动化”到底是什么意思
很多团队一上来就做 chatbot,这其实是倒过来的。更合理的顺序是先明确:你到底要自动化哪些 workflow,以及每个 workflow 的“完成”标准是什么。
先选一个部署模式
比较常见的起点有三种:
- Agent-assist:系统起草回复并收集证据,由人工发送。
- 部分自动化:自动处理一小部分低风险 intent,比如重置密码、查发票。
- 扩展自动化:大部分 intent 都能自动处理,但前提是已经完成足够严格的验证。
建立“绝不自动化”的边界
至少应包括:
- 超过阈值的财务动作
- 账户所有权变更
- 数据导出请求
- 一切受监管或高风险的业务动作
这些情况应该 立即升级。
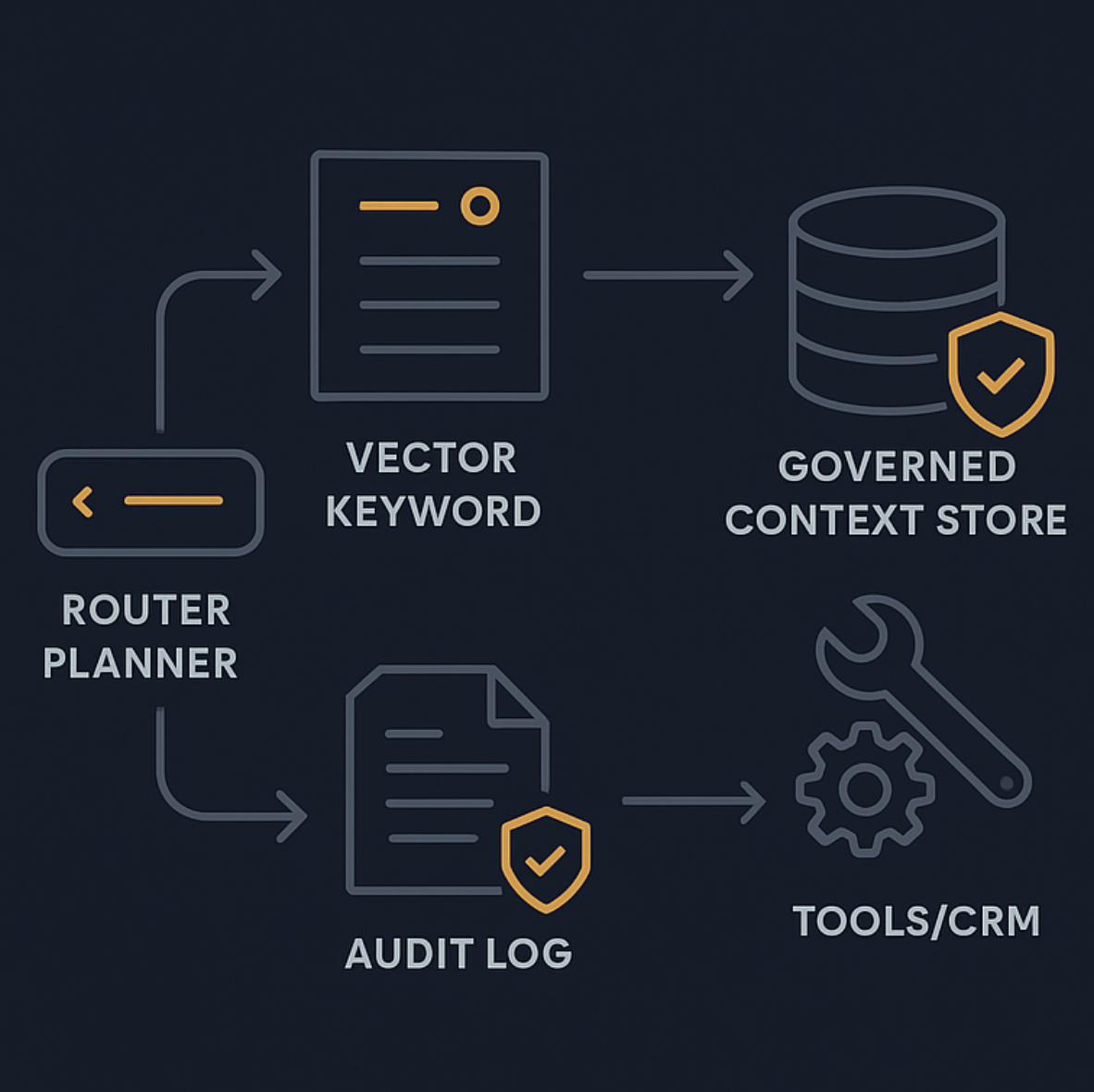
参考架构:面向客服的 Agentic RAG
生产级系统不是一条简单 pipeline,而是一个带有 guardrail 的决策系统。
一个很实用的划分方式,是像 Adaline Labs 在 production-ready agentic RAG architecture and observability 里那样,拆成 orchestration、execution、infrastructure 三层。
Orchestration:router + policy engine
这一层负责决定下一步做什么。
- 识别 intent
- 判断是否真的需要 retrieval
- 选择要调用的 tools
- 执行升级规则和“绝不自动化”边界
这一层负责真正干活:
- 构建 retrieval query
- 通过 hybrid retrieval 与 reranking 找到证据
- 以 least privilege 调用工具
- 基于证据生成回答
retrieval 得到的文本必须被视为 不可信输入。
Infrastructure:observability、evaluation、reliability
生产环境至少要有:
- 覆盖 routing、retrieval、tool call 的 trace
- 判断回答是否 grounded 的评估信号
- retries、timeouts、fallbacks
如果你无法回答“我们用了哪些证据,为什么做了这个动作”,那它还不算可上线系统。
数据和 retrieval 的前置条件
如果文档本身很乱,模型就会很自信地答错。
1. 先构建适合客服的知识语料
通常最少包括:
- 公共帮助中心文章
- 有明确范围的内部 runbook
- 退款、取消、SLA 等政策文档
- 产品 changelog
2. 做不会打碎上下文的 chunking
很多 RAG 项目都是在这里悄悄失败的。
更实用的方式是:优先按语义边界切块,并给每个 chunk 加上标题或摘要等 contextual header。可参考 best practices for chunking and hybrid retrieval in production RAG。
3. 使用 hybrid retrieval + reranking
客服问题既包含精确字符串,也包含模糊意图。
因此,生产里通常更靠谱的是:
- keyword search 用来抓精确 ID 和术语
- vector search 用来抓同义改写
- reranking 用来精修最终证据集
4. 给知识加 freshness 和 ownership 元数据
最少应包含:
- source type
- 最后更新时间
- owner 或负责团队
- 产品 / 版本标签
- 敏感级别
如何部署用于客户服务自动化的 Agentic RAG
每一步都应该有明确目标、输出和“done when”条件。
Step 1:加上 intent router,只在需要时 retrieval
Action: 把请求分到少数几个清晰 workflow 中。
Done when:
- 每个 request 都能记录最终 intent
- 能衡量触发 retrieval 的比例
Action: 按 intent 和风险拆分 tool access。
例如:
- billing status 只能读 invoice,不能发起 refund
- account access 可以发 reset link,但不能改 ownership
- 不要把敏感读权限和宽泛写权限无条件放到同一 workflow
Step 3:实现 retrieval-time authorization
在多租户环境里,这一步出错会非常致命。
最稳妥的模式,是在 authoritative data source 那一层做权限判断,并把 identity 一路传到 retrieval。AWS 在 retrieval-time authorization and identity propagation for RAG 里有很好的实践说明。
Step 4:把 retrieved text 当成 untrusted input,对抗间接 prompt injection
知识库本质上是一条供应链。
如果被检索出的文本里夹带恶意指令,而你的系统边界又不够硬,模型就可能被诱导。更稳妥的做法包括:
- 对输入和工具输出做 sanitization
- 明确分隔 system instruction 与 retrieved content
- 所有真实动作前加确认步骤
- 把全链路日志留好
Step 5:建立 grounding contract
模型应被要求:
- 知识性问题只能基于 retrieved evidence 回答
- 必须带上来源引用
- 证据不足时要拒答或升级
Step 6:增加 verification 与 escalation
一个 verifier 至少应检查:
- 回答是否和 policy 冲突
- intent 与 evidence 是否错位
- 是否正准备执行 denylist 上的动作
Get Started with puppyone for governed customer service automationGet started→
治理:版本化上下文、审计能力与安全协作
如果把 context 只是当作一堆 embeddings 来看,在客服场景里风险很高。
在生产环境里,你至少需要知道:
- 谁修改了知识
- 改了什么
- 什么时候改的
- 哪个版本支撑了哪个自动决策
更稳妥的方式,是使用一个受治理的 context layer:agent-readable files、权限范围、versioning、audit logs 一起存在。
在扩容前先把评估和可观测性建起来
不能度量,就很难改进。
最基本应该看:
- retrieval quality
- faithfulness
- escalation rate
- p50 / p95 latency
- 每类 intent 的成本
同时,也应该用真实 ticket 构建 eval set。
Rollout:从 shadow mode 到真实自动化
Stage 0:shadow mode
- 系统并行运行,但不直接回复客户
- 记录 intents、retrieval、drafts、escalation triggers
Stage 1:agent-assist
- 仍然由人工发送
- 系统提供 draft 与 evidence bundle
Stage 2:部分自动化
- 只自动处理狭窄、低风险 intent
- 高风险流程继续人工把关
Stage 3:扩展自动化
只有当每个 action 都能追溯到证据、知识变更可以 rollback、tool execution 可以被快速 kill-switch 时,才继续扩展。
Troubleshooting:常见失败模式
没有证据却自信作答
- 在低 confidence 下强制拒答
- 强制 citation
- 进一步收紧 routing
检索到了错误版本的 policy
- 加 freshness metadata
- 建 precedence rules
- 做 drift detection 与 rollback
retrieved content 里的 prompt injection
- 一律当作 untrusted
- 加 tool gating
- 严格隔离 system 与 content
线上延迟飙升
- 不要每个请求都 retrieval
- 对高频 intent 做缓存
- 只在必要时做 reranking
Key takeaways
- 客服 Agentic RAG 本质上是一个 workflow system:router、retrieval、tools、verification、escalation。
- 真正难的是运营层:authorization、注入防御、evaluation、分阶段 rollout。
- 治理不是可选项,因为 context 和 decisions 都必须可审计、可回滚、可版本化。
Next steps
如果你现在已经在把 RAG 和 tools 拼起来,而且已经遇到 permissions、audit trails、rollback 的问题,可以继续看: