Compliance Management FOR AI Agents
AI 智能体的合规管理:治理与审计
AI 智能体合规管理的技术指南:审计跟踪、信息治理、沙盒隔离,以及为什么 MUT 等协议层至关重要。
Ollie @puppyone2026年3月31日
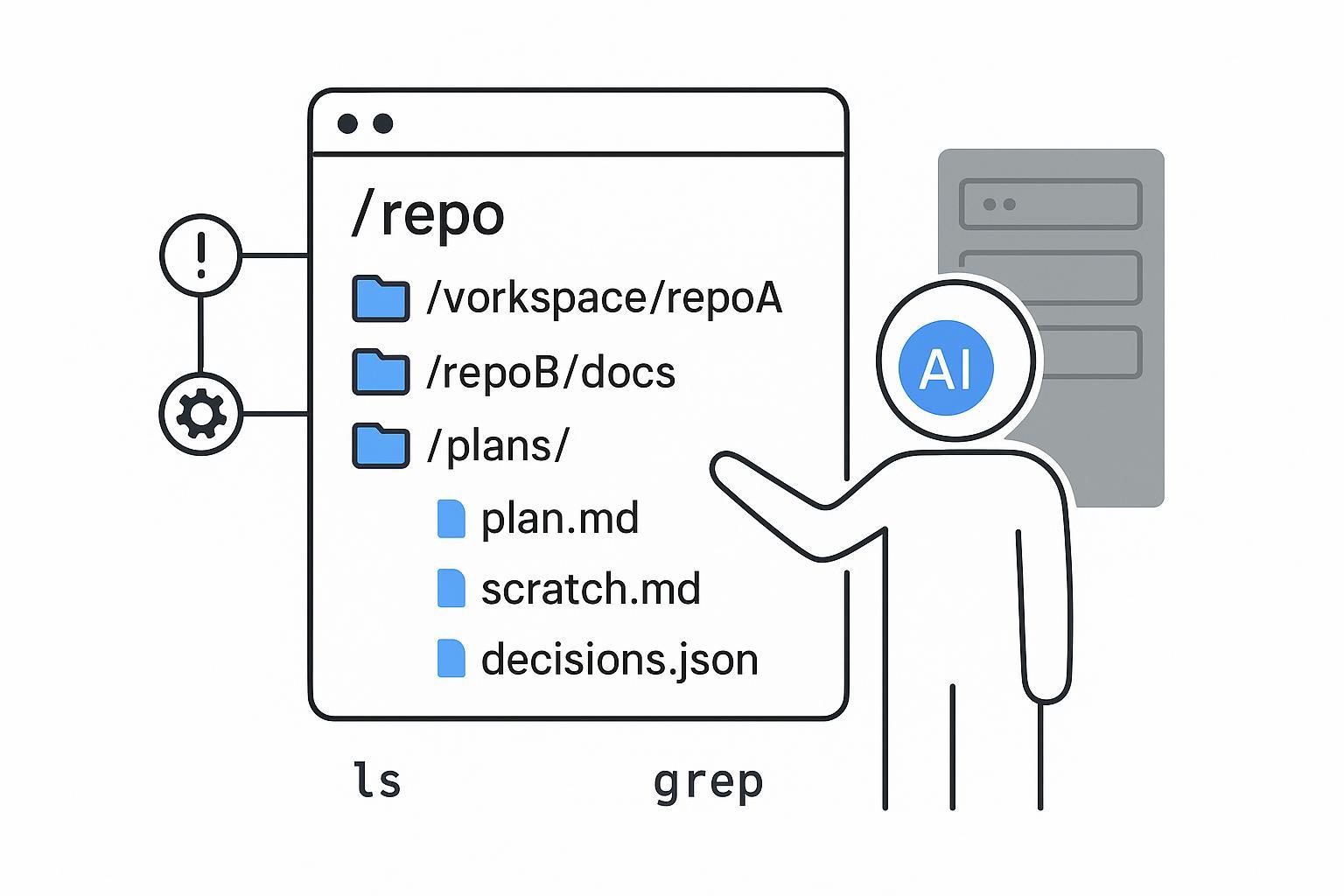
当计划、中间产物和决策被写入文件(plan.md、scratch.md、decisions.json、trace.log)时,它们成为推理的“事实来源”,而不是 token 窗口里逐渐淡忘的记忆。文件带来版本、diff 和检查点:可以回顾计划如何演变、回滚错误分支、从已知状态复现一次运行。不妨这样理解:文件系统是你可以审计的智能体工作记忆,而不是只能猜测的隐形 prompt 线程。
Jakob Emmerling 在 2026 年初的文章为“文件系统优先”智能体做了概念论证,例如将邮件即目录、POSIX 读写/列表/移动作为自然智能体操作。参见 《FUSE is All You Need – Giving agents access to anything via filesystems》。关于治理化上下文层为何重要,我们曾在 How LLM Agent Architectures Work 中讨论过架构权衡。
实际好处是可复现性:decisions.json 和 trace.log 等文件提供“发生了什么、为什么”的确定性轨迹,并改善工程师与智能体的协作——人类可以读 plan.md、改一段、让智能体继续,无需专用工具。
在一个具体工作区中:
在此设置下,智能体使用熟悉的 POSIX 操作:ls 枚举仓库与目录、grep 跨仓库搜索、mv/cp 重组或提升 scratch 输出、echo >> 追加扩展 scratch.md 或 plan.md、diff/patch 在迭代间比较与应用变更。
生命周期:(1) 创建或加载 plan.md 与目标与约束;(2) 在 scratch.md 中迭代:尝试片段、记录发现与阻碍;(3) 在 decisions.json 中记录决策与理由、时间戳;(4) 在 trace.log 中记录动作与智能体 action ID 以便审计;(5) 将验证过的产物从 scratch 提升到对应仓库目录,并通过 MCP 暴露的 issue/PR 工具开 PR。
为何适合多仓库工程知识?因为智能体可以“用文件思考”,跨仓库操作而无需定制适配器;文件系统提供一层抽象,MCP 服务器通过统一接口暴露外部系统(issue 跟踪、CI、文档库),智能体不必为每个工具写新封装。
MCP 的定位:作为连接外部工具(issue 跟踪、CI、文档库、内部服务)的标准化桥梁;文件系统仍是本地工作基底,MCP 提供结构化连接。参见 MCP 一周年规范、MCP 授权更新、Anthropic 关于 MCP 代码执行、JetBrains MCP 文档。
文件系统优先不等于放任。应按最小权限设计:按任务挂载、路径级 ACL 与审计日志、OS 级控制(SELinux/AppArmor、Landlock)。本地优先/本地部署有利于数据驻留与合规;将 MCP 作用域与文件系统层的最小权限模型对齐。
稳定推理只是一半,还需度量:POSIX 追踪、核心指标(任务成功率、延迟、可复现性、可审计性)、基准方法(文件系统优先智能体 vs 仅 API/MCP 工具链)。更多关于智能体“上下文层”:Building a RAG Model That Scales。
FUSE 增加用户态中介,相比内核文件系统可能增加 CPU 与延迟;重度写入或元数据密集型负载更明显。流式或事务型场景(高频消息、金融交易)仍可能更适合直接 SDK/API。常见做法是混合:文件系统负责 plan/scratch/state,MCP 负责结构化、事务性调用。
说明:Puppyone 为我们产品。
治理化上下文库可支撑此架构:将企业知识存为结构化“Know-How”(JSON/图)、混合索引与确定性检索、通过 Docker 本地部署。实践中可用上下文库将精选、版本化知识挂载进智能体工作区,MCP 连接外部系统。参见 Puppyone 上下文库、How Agentic Process Automation Is Transforming Enterprise Operations in 2026。
评估此模式时从小做起:在两个仓库上试点本地 FUSE 挂载与 plan/scratch,加入 PR/issue 的 MCP 连接器,接入 POSIX 追踪,尽早定义最小权限挂载与路径级 ACL。参考:FUSE is All You Need、AgentFS(Penberg)、Turso AgentFS FUSE、MCP 周年规范、Anthropic MCP、JetBrains MCP。
FUSE 会带来一定延迟,但智能体负载通常以读为主、写入呈突发。内核页缓存可缓解首次读取后的开销。Turso 试点显示跨仓库 grep 等工程任务延迟 <10ms,相对 LLM 推理可忽略。通过 trace.log 的确定性可追溯与 plan.md 检查点的可重放工作流,5–15% 的延迟代价是合理的。
选一个封闭的双仓库任务(例如为某认证流程写文档)。仅挂载这两个仓库及空的 plans/、scratch/、logs/,在本地用 fusepy 或 fuse-turso。让智能体初始化 plan.md、在 scratch.md 中迭代、写入 trace.log,并添加最小的 GitHub PR 用 MCP 连接器。全程在开发笔记本上运行,两周内验证可复现性与调试收益,无需动生产环境。
以下场景应避免文件系统优先:高频流式(实时行情)、ACID 关键事务(支付)、无状态单步任务(URL 摘要)。这些需要亚毫秒延迟或原生事务保证,FUSE 无法提供。常用混合方式:文件系统负责 plan/scratch/state,对延迟敏感调用通过限定范围的 MCP 工具。经验法则:如果明天你会想用 git diff plan.md 审计某次决策,那么文件系统优先就有价值。