RAG与RL扩展:AI优化的双引擎
2025年4月27日Mei @puppyone
 图片来源:Pexels
图片来源:Pexels
强化学习(RL)扩展通过自适应学习策略优化模型性能,从而改变了AI。通过利用扩展定律,RL扩展可以根据小规模实验预测大型模型的行为,从而实现高效的资源利用。例如,与基线模型相比,具有更长内存长度的模型的性能提升高达50%。
检索增强生成(RAG)通过将数据检索与文本生成相结合来增强AI系统。它从庞大的数据存储库中检索上下文信息,确保输出保持准确和相关。这种方法显著改善了深度研究和实时知识检索等应用。
RAG和RL的整合创造了强大的协同效应。像DeepResearcher这样的系统展示了这一点,与传统方法相比,其任务完成率提高了28.9个百分点。通过将上下文信息检索与RL优化相结合,AI系统在不同领域都能提供增强的性能。
核心要点
- 强化学习(RL)扩展帮助AI更好、更快地学习。
- 检索增强生成(RAG)将数据查找与文本生成相结合。这可以保持结果的正确性和主题相关性。
- 将RAG与RL结合使用可以显著提高模型性能。它可以将错误减少69%,并改善决策能力。
- 要将RL扩展与RAG结合使用,请选择一个基础模型。然后,用标记数据对其进行训练,并使用Pinecone等工具快速查找数据。
- RAG和RL共同改进了许多领域的AI。它们使客户服务、搜索引擎和知识系统变得更智能。
理解检索增强生成(RAG)
 图片来源:Pexels
图片来源:Pexels
什么是检索增强生成?
检索增强生成(RAG)代表了人工智能领域的一种突破性方法。它结合了两个基本过程:检索相关数据和生成上下文准确的输出。与仅依赖预训练知识的传统生成模型不同,RAG整合了实时信息检索以增强其响应。这种双重机制确保输出不仅连贯,而且基于事实数据。
RAG的概念通过Lewis等人2021年的论文《知识密集型NLP任务的检索增强生成》等研究工作而声名鹊起。Guu等人早期的基础性工作引入了在预训练期间整合知识检索的想法。这些进步使RAG成为现代AI应用的基石,使系统能够提供更权威和可靠的结果。
RAG如何结合检索与生成
RAG通过利用外部信息检索系统和大型语言模型(LLM)无缝地集成了检索和生成。该过程始于检索阶段,系统从外部来源(如数据库或知识库)搜索相关数据。然后,这些检索到的信息作为生成阶段的输入,模型在此阶段生成既上下文准确又语义丰富的响应。
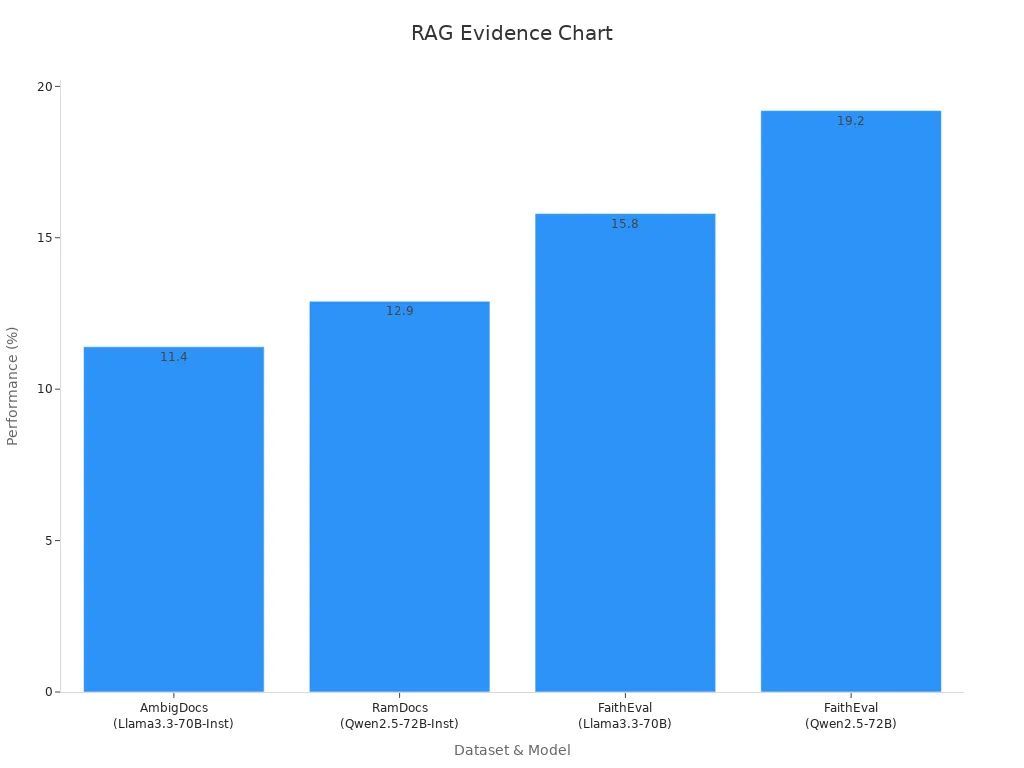
例如,Madam-RAG模型展示了这种组合如何提高在各种数据集上的性能:
| 模型 | 数据集 | 性能提升 |
|---|---|---|
| Madam-RAG | AmbigDocs | +11.40% (Llama3.3-70B-Inst) |
| Madam-RAG | RamDocs | +12.90% (Qwen2.5-72B-Inst) |
| Madam-RAG | FaithEval | +15.80% (Llama3.3-70B) |
| Madam-RAG | FaithEval | +19.20% (Qwen2.5-72B) |
 图片来源:Pexels
图片来源:Pexels
检索增强生成管道的知识增强优势
检索增强生成管道为增强知识密集型任务提供了许多优势。其能够动态检索和生成信息的能力使其成为跨行业的多功能工具。关键优势包括:
- 改善客户服务互动: RAG提供个性化和精确的响应,提升客户满意度。
- 增强内容创作和文案撰写: 它生成与特定受众相关的引人入胜且上下文相关的文案。
- 提升E-learning和虚拟辅导系统: RAG通过从教育数据库中检索合适的解释创建互动学习环境。
- 革新医疗诊断: 它通过检索相关健康记录,实现准确和及时的咨询。
- 客户反馈分析: RAG通过访问多样化的反馈来源,加速情感分析,帮助企业优化产品。
检索增强生成的影响超越了这些用例。通过将动态知识检索与生成准确性相结合,RAG重塑了AI在各个行业的应用。其能够利用实时数据和专业知识的能力显著提升了AI系统的性能和可靠性。预测表明,RAG市场预计将在2035年增长至$40.34 billion,年均增长率约为35%。这一增长突显了其在解决AI的幻觉问题和提高内容相关性方面的重要性。
RL扩展及其在AI中的重要性
什么是RL扩展?
RL扩展指的是通过增强强化学习(RL)模型处理复杂任务的能力来提升其性能的过程。它涉及扩展计算资源、数据输入和模型架构,以提高学习效率和适应性。与传统的扩展方法不同,RL扩展强调通过动态交互和反馈机制进行主动学习。
RL扩展的关键原则包括:
- 自对弈强化学习(SPRL):该方法使智能体通过与自身互动来学习,通过经验促进主动学习。
- 学习周期:智能体观察其环境、采取行动、接收反馈并调整其行为,形成一个持续的循环。
- 重新定义可扩展性:新的扩展定律包含了探索的计算成本,挑战了传统方法。
这些原则凸显了RL扩展在推进AI系统方面的变革潜力。
RL扩展在AI模型中的目的
RL扩展的主要目标是增强AI模型的效率和适应性。传统的扩展方法通常难以处理不稳定的训练动态,这会影响性能。RL扩展通过引入诸如软专家混合(MoEs)等机制来解决这些挑战。这些机制优化资源分配并改善不同RL环境下的学习成果。
实证研究证明了RL扩展的有效性。例如,Open Reasoner Zero模型通过利用基础模型,达到了与专业RL系统相当的性能水平。这凸显了RL扩展在改进大型语言模型并确保其提供准确可靠结果方面的重要性。
RAG与RL结合的优势
将RAG与RL集成,为知识密集型任务创建了一个强大的框架。RAG增强了相关数据的检索,而RL则优化了学习过程。它们共同显著提高了大型语言模型的性能。试验表明,模型损失减少了69%,从0.32降至0.1。这一改进确保用户获得精确且上下文准确的信息。
RAG和RL的结合也支持多智能体系统。这些系统使智能体能够协作,增强其进行深度研究和解决复杂问题的能力。通过将检索过程整合到RL工作流中,AI系统实现了更高的稳定性和可扩展性。这种协同作用凸显了RAG在解决传统RL方法局限性方面的重要性。
使用RAG后进行RL扩展的分步指南
 图片来源:Pexels
图片来源:Pexels
使用RAG进行RL扩展的先决条件
在实施使用RAG进行RL扩展之前,必须满足某些先决条件以确保工作流程的顺利进行。这些先决条件包括:
- 基础模型:选择一个能够处理检索和生成任务的基础大型语言模型(LLM)。像Llama或Qwen这样的模型因其适应性而常被使用。
- 知识检索系统:集成一个强大的检索系统,如Pinecone向量数据库,以促进高效的相似性搜索和智能体的动态查询。这确保了为生成任务检索到相关数据。
- 带注释的数据集:准备一个以推理链形式结构的查询特定数据集。该数据集是监督式微调和后续RL对齐的基础。
- 知识选择器:实现一个知识选择器来过滤检索到的信息。这在处理较弱的生成器模型或模糊任务时至关重要。
- 多智能体协作:建立一个多智能体系统以增强可扩展性和深度研究能力。智能体可以协作以优化检索和生成过程。
这些先决条件为构建能够进行高效RL扩展的RAG智能体奠定了基础。
RL扩展的工具和框架
有多种工具和框架支持RL扩展,从而实现高效的实施和优化。主要选项包括:
- Pinecone向量数据库:该工具专门从事高效的相似性搜索,确保快速检索相关数据。它在查询我们的智能体和提高检索准确性方面起着关键作用。
- VeRL框架:字节跳动的VeRL框架为RL训练提供了一个强大的环境。它支持RAG和RL的集成,实现了检索和生成过程的无缝对齐。
- 改进的PPO算法:为RL扩展而调整的近端策略优化(PPO)算法改善了学习动态和收敛速度。这些修改已在Atari游戏和Box2D等环境中进行了基准测试。
- 对比多任务学习(CML):该技术增强了模型在训练期间区分相关和无关信息的能力。它通过优化检索过程来补充RL对齐。
| 模型 | 平均准确率(%) | 提升(%) |
|---|---|---|
| ToRL-1.5B | 48.5 | - |
| Qwen2.5-Math-1.5B-Instruct | 35.9 | - |
| Qwen2.5-Math-1.5B-Instruct-TIR | 41.3 | - |
| ToRL-7B | 62.1 | 14.7 |
这些工具和框架为在利用RAG的同时高效扩展RL提供了必要的基础设施。
RL扩展的实施步骤
在应用RAG后实施RL扩展需要一个结构化的方法。请遵循以下步骤以确保最佳性能:
- 数据收集:收集一个以推理链形式结构的查询特定带注释数据集。该数据集是监督式微调的基础。
- 监督式微调(SFT):使用收集的数据集训练基础模型。此步骤增强了模型的检索和生成能力。
- 对比多任务学习(CML):优化模型区分相关和无关信息的能力。此步骤提高了检索准确性和生成质量。
- RL对齐:使用强化学习技术微调模型。根据反馈机制将其输出与期望结果对齐。
- 与Pinecone集成:将模型连接到Pinecone向量数据库以进行高效的相似性搜索。此集成确保了在生成任务期间的快速准确检索。
- 多智能体协作:部署一个多智能体系统以增强可扩展性和深度研究能力。智能体协作以优化检索和生成工作流。
- 性能监控:使用知识F1和检索准确性等指标持续监控模型的性能。调整训练参数以保持效率。
提示:在训练期间混合黄金知识和干扰知识可以模拟多样化的选择结果,从而提高模型的适应性。
通过遵循这些步骤,开发人员可以成功地使用RAG实施RL扩展,从而在AI系统中实现增强的性能和可扩展性。
RAG管道中的微调和优化
微调和优化在增强RAG管道中模型的性能方面起着至关重要的作用。这些过程优化了模型检索和生成准确、上下文相关输出的能力。然而,要获得最佳结果,需要仔细规划和执行以避免潜在的陷阱。
RAG管道微调中的挑战
RAG管道内的微调通常会遇到可能影响模型性能的挑战。例如,在微调期间增加样本量并不总能带来更好的结果。研究表明,更大的样本量会降低准确性和完整性。在一个实验中,当样本量从500增加到1000时,Mixtral模型的准确率从4.04下降到3.28。这凸显了在微调中需要采取平衡的方法,即数据质量优先于数量。
另一个挑战是保持模型在不同任务间的泛化能力。在微调期间对特定数据集的过拟合会限制模型的适应性。这在知识密集型应用中尤其成问题,因为RAG管道必须处理广泛的查询和上下文。
有效微调的策略
为了应对这些挑战,开发人员可以采取几种策略:
- 选择性数据抽样:与其不加选择地使用大型数据集,不如专注于与模型目标任务一致的高质量、带注释的样本。这种方法最大限度地降低了性能下降的风险。
- 增量微调:分阶段逐步微调模型,使其能够在不过度负荷其学习能力的情况下进行调整。这种方法有助于在专业化和泛化之间保持平衡。
- 知识混合:在训练期间结合使用黄金标准知识和干扰信息。该技术增强了模型区分相关和无关数据的能力,从而提高了检索准确性。
RAG管道的优化技术
优化可确保RAG管道高效运行并提供一致的结果。关键技术包括:
- 动态检索机制:实施实时检索系统使模型能够访问最新信息。这在知识快速发展的深度研究等应用中尤其有用。
- 多智能体协作:在RAG管道内部署多个智能体可增强可扩展性和任务专业化。每个智能体可以专注于检索或生成的特定方面,从而提高整体系统性能。
- 对比多任务学习(CML):该技术优化了模型在训练期间优先处理相关信息的能力。通过对比正确和错误的检索,CML提高了模型的决策能力。
提示:定期监控检索准确率和知识F1分数等性能指标。根据这些指标调整训练参数以保持最佳性能。
通过将微调与强大的优化策略相结合,RAG管道可以在知识密集型任务中实现卓越的性能。这些方法确保了管道即使在其应用复杂性增加时仍能保持适应性、准确性和效率。
RAG和RL的实际应用
增强客户支持聊天机器人
由RAG和RL驱动的客户支持聊天机器人能够提供精确且与上下文相关的响应。通过集成检索机制,这些聊天机器人可以访问实时数据,从而有效解决用户查询。强化学习通过将响应与用户偏好和反馈对齐,进一步优化其性能。这种结合确保聊天机器人在提供准确信息的同时,还能提高用户满意度。
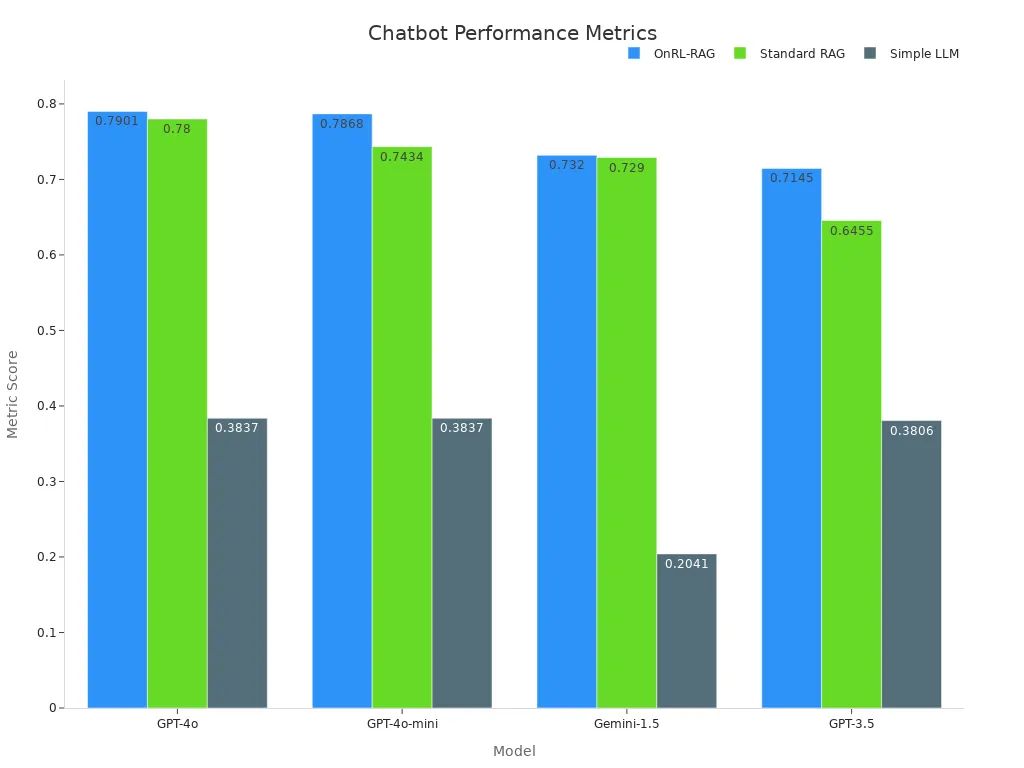
实证研究凸显了这种方法的有效性。例如,OnRL-RAG框架在各种模型上始终优于标准RAG和简单的LLM。下表展示了其性能指标:
| 模型 | OnRL-RAG | 标准RAG | 简单LLM |
|---|---|---|---|
| GPT-4o | 0.7901 | 0.7800 | 0.3837 |
| GPT-4o-mini | 0.7868 | 0.7434 | 0.3837 |
| Gemini-1.5 | 0.7320 | 0.7290 | 0.2041 |
| GPT-3.5 | 0.7145 | 0.6455 | 0.3806 |
 图片来源:Pexels
图片来源:Pexels
使用RAG和RL的零售聊天机器人还通过减少响应时间来提高运营效率。这些系统能够动态适应用户需求,确保无缝的客户体验。
利用RAG和RL改进搜索引擎
搜索引擎通过集成RAG和RL获益匪浅。RAG通过从庞大的知识库中访问相关数据来增强检索过程,而RL则优化搜索算法以提高准确性和相关性。这种协同作用使搜索引擎即使对于复杂查询也能提供精确的结果。
ReZero框架体现了这种改进。它奖励搜索尝试的持久性,实现了46.88%的峰值准确率,而基线为25%。下表突出了这一性能:
| 模型 | 准确率 (%) | 基线 (%) |
|---|---|---|
| ReZero模型 | 46.88 | 25.00 |
通过利用RL,搜索引擎优化其算法以优先考虑用户意图。这种方法确保用户获得最相关的信息,从而提升整体体验。此外,Pinecone等工具有助于高效检索,使搜索引擎能够轻松处理大规模数据查询。
企业知识管理系统
企业依靠知识管理系统来简化运营并改进决策。RAG和RL通过实现信息的动态检索和生成来增强这些系统。RAG从内部和外部来源检索相关数据,而RL则将输出与组织目标对齐。
例如,一家大型银行的数字助理使用RAG来获取监管信息,确保合规性并改善客户互动。同样,医疗机构利用RAG系统访问医疗指南和研究,从而增强临床决策支持。Pinecone在这些应用中通过实现高效的相似性搜索和检索发挥了关键作用。
多智能体协作进一步增强了企业系统的可扩展性。智能体共同协作以优化检索和生成过程,确保用户获得准确且可操作的见解。这种方法改变了知识管理,使其更具适应性和效率。
将RL扩展与RAG集成,通过增强其准确性、鲁棒性和适应性来改变AI系统。这种协同作用使模型能够检索实时知识,从而改善决策和在各种任务中的表现。例如:
| 关键优势 | 描述 |
|---|---|
| 提高准确性 | 增强数据检索和响应生成的精度。 |
| 鲁棒性 | 提高AI系统在动态环境中的韧性。 |
| 泛化能力 | 在不同数据集和复杂任务上表现更佳。 |
提示:探索RL扩展以释放AI模型的全部潜力。将RAG与RL结合,为知识密集型应用提供了一个强大的框架。
常见问题
RAG和RL扩展有什么区别?
RAG检索相关数据并生成上下文准确的输出。RL扩展通过提高AI模型的学习效率和适应性来优化它们。它们共同通过将实时知识检索与强化学习相结合,以改善决策,从而增强性能。
RAG可以与任何基础模型一起使用吗?
是的,RAG适用于大多数大型语言模型(LLM)。由于其适应性,Llama和Qwen是热门选择。开发人员必须确保基础模型支持检索和生成任务,以实现无缝集成。
RL扩展如何改进AI系统?
RL扩展通过优化其学习过程来增强AI系统。它使用动态反馈机制将输出与期望目标对齐。这种方法提高了准确性、稳定性和可扩展性,尤其是在复杂环境中。
实施RAG和RL需要哪些基本工具?
关键工具包括用于高效数据检索的Pinecone、用于RL训练的VeRL以及用于优化的改进PPO算法。这些工具简化了工作流程,并确保了扩展期间的高性能。
RL扩展是否需要多智能体系统?
多智能体系统不是强制性的,但非常有益。它们提高了可扩展性和任务专业化。智能体协作以优化检索和生成过程,从而提高整体系统效率。