RAG 并未消亡,Agentic RAG 才是更优解
2025年11月27日Guanqun @puppyone
长话短说:这是一个开源项目:https://github.com/puppyone/DeepWideResearch
该项目用 Agentic 工作流取代了脆弱的 RAG 流程,解决了维护噩梦和质量下降的问题。
这种取舍是真实存在的: Agentic RAG 成本更高(每次查询 >$0.1,而传统 RAG 约为 $0.01),速度也更慢(>10 秒,而传统 RAG 不到 3 秒)。如果你需要大规模的亚秒级响应,这个方案可能不适合你。但如果你需要准确、可维护的知识问答系统,请继续阅读。
我将分享我们构建新型 Agentic RAG 架构的经验,并探讨为什么 Agentic RAG 是企业知识问答的关键一步。
在过去一年里,我交付了 5 个传统的 RAG 项目,每个项目都涉及 100 到 1000 页的文档。技术栈很标准:查询编写、查询路由、分块、嵌入、重排等等。起初一切顺利,但我们很快就掉进了一个陷阱:整个流程极其僵化,难以维护。
最痛苦的领悟来自于一次文档变更。一个简单的改动就导致 RAG 的整体评分下降。为了维持同样的分数,我们不得不从头开始重建整个流程策略。每增加一个新的数据源,都像打一场新的战役。我们尝试用复杂的元数据标签和更细粒度的分块来修补,但这些都只是治标不治本的权宜之计。
我们开始反思:我们到底做错了什么?
问题出在逻辑上。传统的 RAG 本质上是在编写硬编码的 if-else 规则来拟合一个数据集。这对于静态代码是可行的,但当你需要真正的智能时,它就行不通了。
受 OpenAI 的 Deep Research 启发,我决定抛弃僵化的流程。
我转向了一种 Agentic + MCP (模型上下文协议) 的架构。想法很简单:我们不使用复杂的检索链,而是给 Agent 工具,让它直接搜索每个数据源。
这是系统架构图:
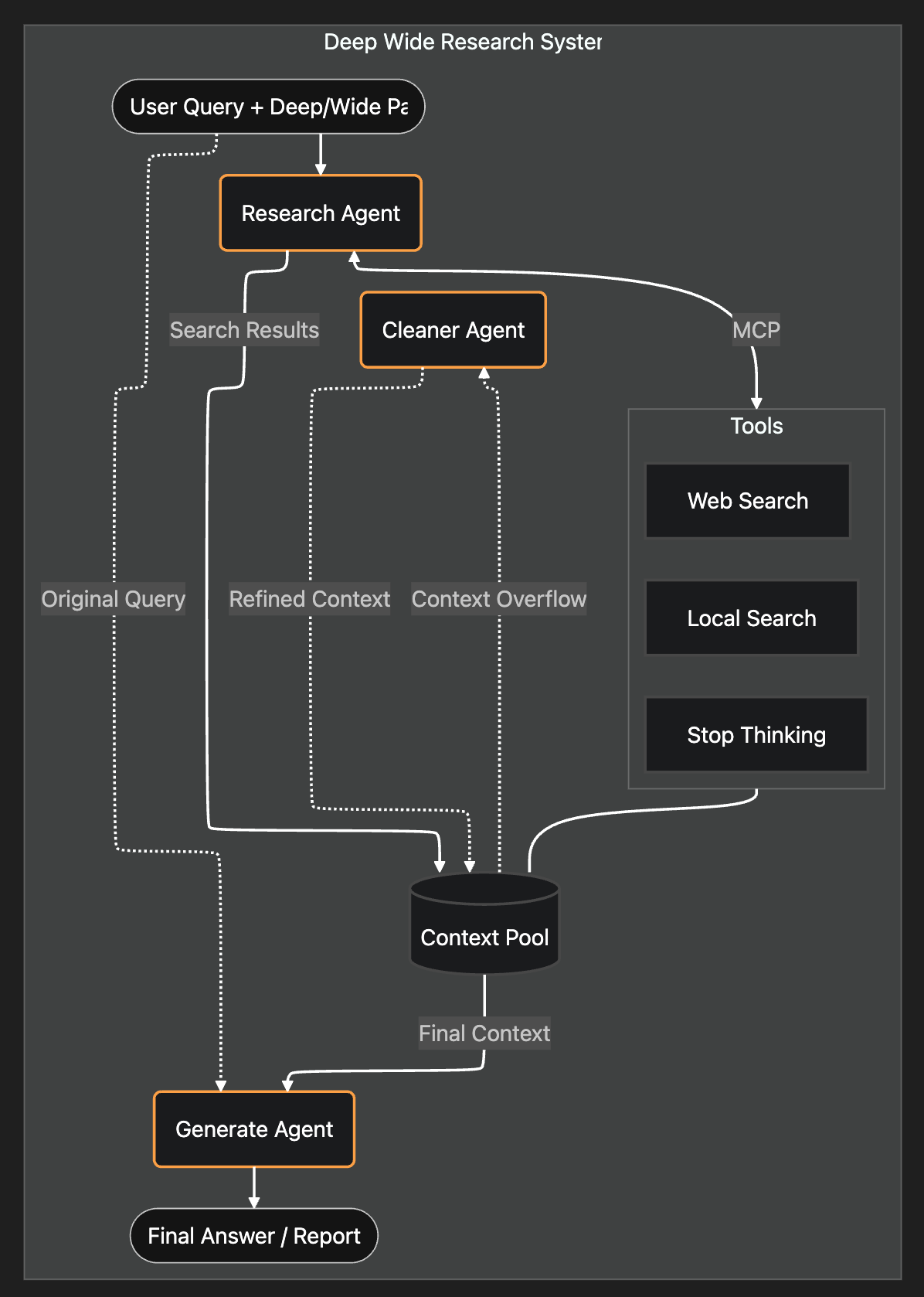
1. 如何构建研究型 Agent?
Agentic RAG 用一个单一、自主的研究型 Agent (Research Agent) 取代了整个检索流程。
我没有硬编码重写或路由规则,而是设置了两个 Agent:一个研究员 (Researcher) 和一个生成器 (Generator)。
我给了研究员 (Researcher) 三个简单的工具:

<Stop_thinking><Web_search><Local_search>
但仅仅给 Agent 工具是不够的。你还需要告诉它何时停止。
我没有使用简单的 while 循环或固定的步数,而是强制 Agent 在每次行动前都执行一个自我反思步骤 (Self-Reflection Step)。
我们不使用简单的循环或迭代计数。相反,我们通过一个**“文章就绪度检查”**来强制 Agent 在每一步行动前进行自我反思:
## 文章就绪度检查:
- 我现在能写出一篇全面、详尽的回答和文章吗? (能/否)
- 如果我现在就写,哪些部分会显得薄弱、模糊或缺少具体的例子/数据?
- 我是否有足够具体的事实、数字、例子来支持每一个论点?
只有当这个检查通过时,Agent 才会调用 <Stop_thinking>。我们用 SOTA 模型(Gemini 3 pro / Claude 4.5 Opus / GPT-5)进行了测试,它们完美地遵循了这一逻辑。
所有的研究发现都存储在一个共享的上下文池 (Context Pool) 中。一旦研究员发出“停止”信号,一个生成 Agent (Generate Agent) 就会接管上下文池并撰写最终答案。
结果超越了我们以往构建的任何流程。这是智能战胜了僵化结构。
我们基本上将传统的 RAG 组件映射到了动态的 Agent 行为上:
- 查询路由? -> Agent 自行选择合适的工具。
- 查询重写? -> Agent 自行填充函数参数。
- 多跳问答? -> Agent 自行决定何时调用
<Stop_thinking>。 - 重排 -> Agent 基于上下文池生成答案。
2. 处理上下文溢出
我遇到了第二个问题:当搜索到的上下文变得过长时该怎么办?
我构建了一个上下文池 (Context Pool)。这个池子作为一个列表,存储所有搜索结果。当上下文池达到阈值(最大 token 数量的 90%)时,我构建的一个清理 Agent (Cleaner Agent) 会来清理上下文。
诀窍是:不要总结。 总结会丢失细节。
相反,清理 Agent 就像一个垃圾过滤器。它会删除整个不相关的来源,同时保持相关来源100% 的原创和完整。
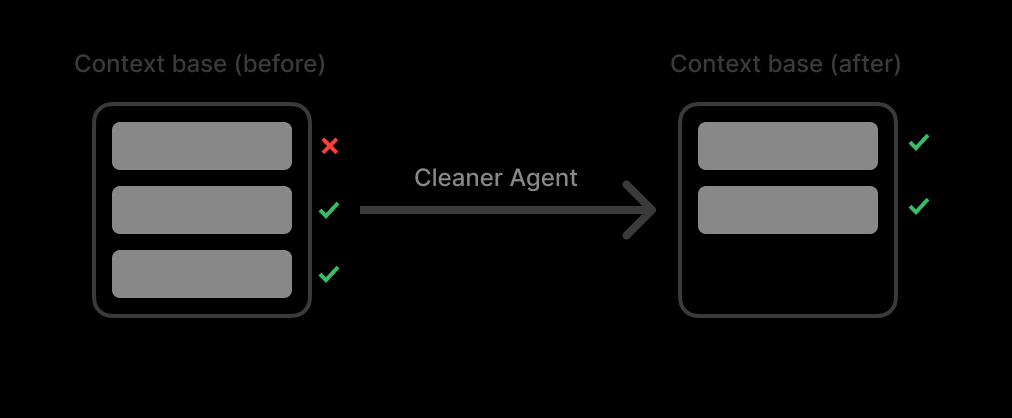
最后,一个生成 Agent (Generate Agent) 会根据上下文池中提炼过的内容和原始查询,生成最终答案。
3. 应对成本与延迟的“深度-广度”方案
我很快又面临了第三个挑战:成本与延迟的障碍。
让我坦诚地谈谈数据:
- 延迟: Agentic RAG 的延迟有大约 10 秒的硬性下限——推理循环是瓶颈,我们无法低于这个值。而传统 RAG 可以在 3 秒内响应。
- 成本: 使用 GPT-5,每次查询的成本预计在 $0.05 到 $1 之间。而使用嵌入的传统 RAG 成本约为 $0.005 到 $0.01。
为了让这种取舍在这个下限之上变得可控,我引入了**“深度-广度研究 (Deep-Wide Research)”**:
- Deep (深度): 控制迭代推理的步骤。范围从约 10 秒(最低)到 5 分钟以上(用于综合报告的最大深度)。
- Wide (广度): 控制并行的查询扩展。广度越大 = 探索的来源越多 = token 成本越高。
深度 × 广度 ≈ 成本。 通过调整这两个维度,你可以控制响应时间(10秒 ~ 5分钟)、质量和成本——但无法突破 10 秒的下限。
我们已经开源了 DEEP WIDE RESEARCH。 项目地址: https://github.com/puppyone/DeepWideResearch (Apache 许可证)
这个方案没有解决什么问题
这个项目解决了 Agentic RAG 问题的一半:即“推理与搜索”这一侧。
另一半问题:处理私有企业数据,在这里仍未解决:
- 清理混乱的企业文档
- 构建为 Agent 使用而优化的索引
- 精细的权限控制
我们正在另外着手解决这些问题。如果你也遇到了这些问题或有任何想法,欢迎与我联系:[email protected]