RAG mit lokalen Daten erstellen: Ein Entwicklerleitfaden für datenschutzkonforme KI
10. Januar 2025Alex @puppyone
 Bildquelle: KI-Generierung
Bildquelle: KI-Generierung
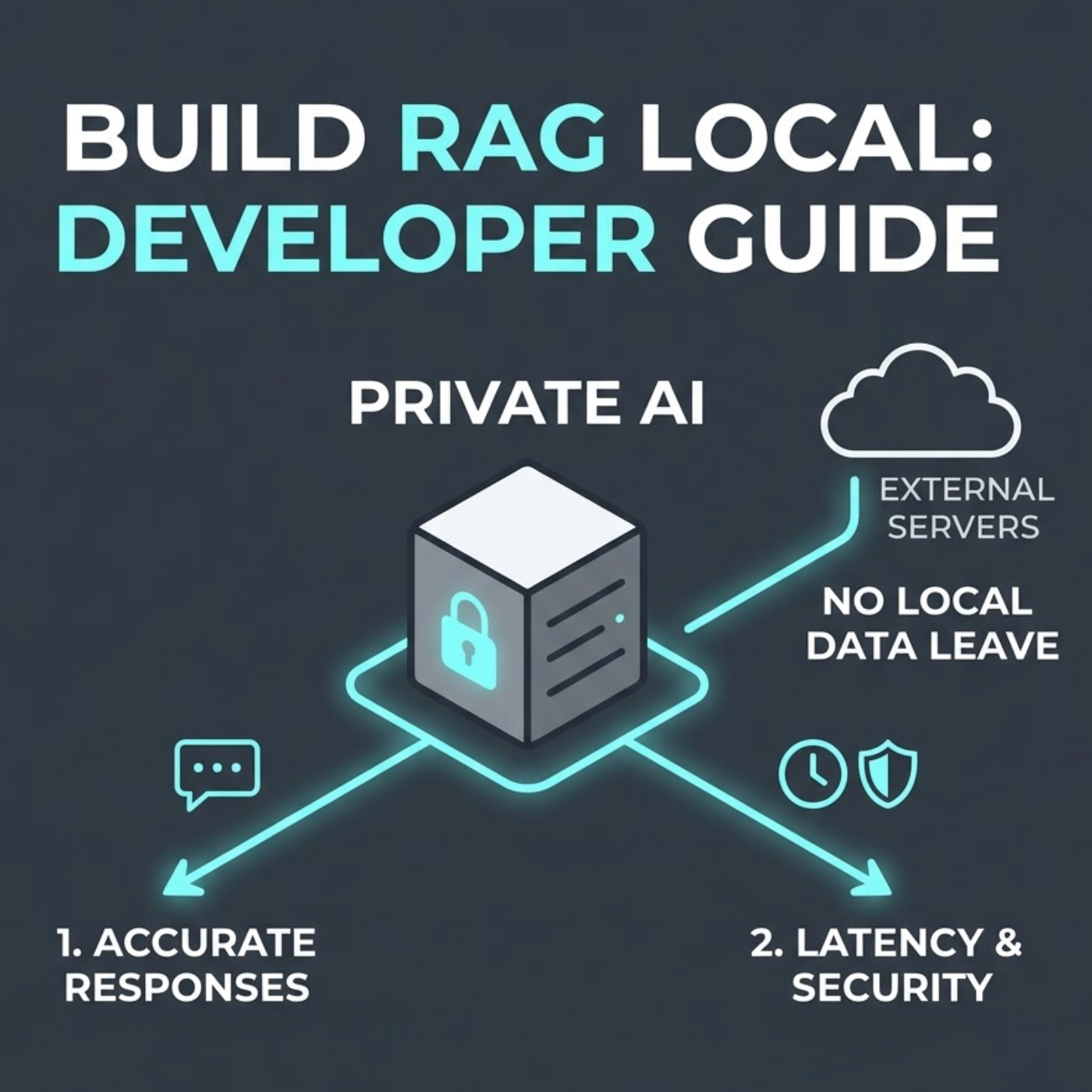
Datenschutz hat sich zu einem entscheidenden Thema in der KI-Entwicklung entwickelt, insbesondere im Umgang mit sensiblen Unternehmensdaten. Organisationen zögern, ihre vertraulichen Informationen an externe Server oder Cloud-Dienste zu senden, die KI verarbeiten. Hier kommen LangChain RAG (Retrieval-Augmented Generation)-Systeme mit lokalen Daten ins Spiel, die eine sichere Option für Entwickler bieten, die die Kontrolle über ihre Informationen behalten müssen.
Lokale RAG-Systeme, die oft mit LangChain implementiert werden, bieten über den Datenschutz hinaus große Vorteile. Sie reduzieren die Latenz, ermöglichen benutzerdefinierte Architekturen und arbeiten unabhängig von Drittanbieterdiensten. In diesem Leitfaden führen wir Sie durch die Schritte zum Erstellen Ihres eigenen lokalen RAG-Systems mit LangChain und behandeln alles von der Einrichtung der Umgebung bis zur Leistungsoptimierung. Entwickler lernen, wie sie private KI-Lösungen implementieren, die sensible Daten sicher halten und gleichzeitig die vollständige Kontrolle über den Prozess behalten.
Einrichtung Ihrer lokalen Entwicklungsumgebung
Um unser LangChain RAG-System zu erstellen, müssen wir eine stabile lokale Entwicklungsumgebung einrichten. Sehen wir uns alles an, was zum erfolgreichen Erstellen und Implementieren erforderlich ist.
Erforderliche Software und Abhängigkeiten
Python 3.11 oder höher dient als unsere Grundlage. Ein Manager für virtuelle Umgebungen hilft Ihnen beim Einstieg - Sie können wählen zwischen:
-
Virtuelle Umgebung (venv)
- Virtuelle Umgebung erstellen und aktivieren
- Erforderliche Pakete über pip installieren
- requirements.txt für die Abhängigkeitsverwaltung generieren
-
Conda-Umgebung
- Conda-Umgebung erstellen
- Notwendige Pakete installieren
- environment.yml für die Reproduzierbarkeit exportieren
Für die Entwicklung von LangChain RAG müssen Sie bestimmte Bibliotheken wie LangChain, Chroma für die Vektorspeicherung und Ollama für die lokale LLM-Bereitstellung installieren.
Hardware-Anforderungen und -Optimierung
Lokale RAG-Systeme benötigen spezielle Hardwarekonfigurationen. Hier sind die empfohlenen Spezifikationen:
| Komponente | Mindestanforderung | Empfohlen |
|---|---|---|
| CPU | Mehrkern-Prozessor | 16+ Kerne |
| RAM | 16 GB | 32 GB oder mehr |
| GPU | NVIDIA (8 GB VRAM) | NVIDIA RTX 4080/4090 |
| Speicher | Schnelle NVMe SSD | Mehrere NVMe-Laufwerke |
Das System funktioniert am besten mit mindestens 4 CPU-Kernen für jeden GPU-Beschleuniger. Es benötigt auch doppelt so viel CPU-Speicher wie der gesamte GPU-VRAM.
Erste Konfigurationsschritte
Die Einrichtung der Umgebung für die LangChain RAG-Entwicklung erfordert diese wichtigen Schritte:
-
Grundlegende Abhängigkeiten installieren:
- ChromaDB für die Vektorspeicherung
- LangChain-Tools für die Modellintegration
- Unstructured-Paket für die Dokumentenverarbeitung
-
Modelleinstellungen konfigurieren:
- Erforderliche Modelle herunterladen (z. B. LLaMA 3.1)
- Umgebungsvariablen einrichten
- Verbindung zur Vektordatenbank initialisieren
Das Testen der Grundfunktionalität hilft bei der Überprüfung unserer Installation. Teams, die an Unternehmenslösungen arbeiten, sollten von Anfang an eine ordnungsgemäße Versionskontrolle und Abhängigkeitsverwaltung einrichten.
Implementierung der lokalen Vektordatenbank
Vektordatenbanken sind die Grundlage unseres LangChain RAG-Systems. die Wahl des richtigen Vektorspeichers ist entscheidend für die beste Leistung. Sehen wir uns an, wie wir eine effiziente lokale Vektordatenbank für unsere private KI-Lösung erstellen können.
Den richtigen Vektorspeicher auswählen
Der Aufbau eines RAG-Systems erfordert sorgfältige Überlegungen bei der Auswahl des Vektorspeichers. Vektordatenbanken lassen sich in zwei Typen einteilen: traditionelle Datenbanken mit Vektorerweiterungen und speziell entwickelte Vektorlösungen.
Dies sind die wichtigsten zu berücksichtigenden Aspekte:
- Abfrageleistung: Der Vektorspeicher sollte ähnliche Elemente mithilfe fortschrittlicher Algorithmen schnell finden.
- Skalierbarkeit: Er muss in der Lage sein, mehr Daten reibungslos zu verarbeiten.
- Speicheroptionen: Sowohl In-Memory- als auch festplattenbasierte Speicheroptionen sind wichtig.
Datenindizierungsstrategien
Die richtige Indizierungsstrategie beschleunigt Ähnlichkeitssuchen erheblich. Der HNSW (Hierarchical Navigable Small World) Index funktioniert sehr gut. Er ermöglicht schnelle Abfragen, ohne viel an Genauigkeit zu verlieren. Es gibt auch andere Indizierungsoptionen:
| Indextyp | Am besten geeignet für | Kompromisse |
|---|---|---|
| Flat Index | Kleine Datensätze | Einfach, aber langsamer bei großen Mengen |
| HNSW Index | Große Datenmengen | Komplexer, bessere Skalierung |
| Dynamic Index | Wachsende Datensätze | Automatische Umschaltfähigkeit |
Techniken zur Leistungsoptimierung
Unser lokaler Vektorspeicher benötigt spezielle Anpassungen, um optimal zu funktionieren. Der Erfolg des Systems hängt davon ab, wie gut wir unsere Ressourcen verwalten und konfigurieren.
Unsere Tests zeigen, dass Vektorspeicher diese Optimierungen benötigen:
-
Speicherverwaltung:
- Vektoren sollten für die beste Suchgeschwindigkeit in den verfügbaren RAM passen.
- Schlechter Speicher führt zu langsameren Importen.
-
Abfrageoptimierung:
- Mehrere Abfragen in Stapeln verarbeiten
- Häufig verwendete Daten im Cache behalten
-
Indexkonfiguration:
- HNSW-Einstellungen für bessere Suchqualität anpassen
- Den optimalen Kompromiss zwischen Genauigkeit und Geschwindigkeit finden
Das System funktioniert am besten, wenn wir wichtige Kennzahlen wie Lade-Latenz und Abfragen pro Sekunde (QPS) verfolgen. Diese Strategien helfen unserem lokalen RAG-System, ähnliche Vektoren schnell zu finden und gleichzeitig die Daten privat und unter unserer Kontrolle zu halten.
Bereitstellung und Verwaltung lokaler LLMs
Die richtige Bereitstellung eines lokalen Sprachmodells (LLM) mit LangChain erfordert eine genaue Betrachtung mehrerer Schlüsselfaktoren. Dieser Abschnitt führt Sie durch alles, was Sie über die Einrichtung eines zuverlässigen lokalen RAG-Systems mit LangChain wissen müssen.
Kriterien für die Modellauswahl
Ihre Hardwarefähigkeiten spielen eine große Rolle bei der Auswahl eines LLM für die LangChain-Integration. Eine einfache Berechnung kann helfen: Multiplizieren Sie die Parameteranzahl des Modells (in Milliarden) mit zwei und addieren Sie einen Overhead von 20 %, um herauszufinden, wie viel GPU-Speicher Sie benötigen. Um nur ein Beispiel zu nennen: Ein Modell mit 11 Milliarden Parametern benötigt etwa 26,4 GB GPU-Speicher.
| Modellgröße | Min. GPU-Speicher | Empfohlene GPU |
|---|---|---|
| 3-7 Mrd. Parameter | 16 GB VRAM | RTX 4080 |
| 7-13 Mrd. Parameter | 32 GB VRAM | A40 |
| 13+ Mrd. Parameter | 40 GB+ VRAM | A100 |
Best Practices für die Bereitstellung
Unser lokales RAG-System mit LangChain funktioniert am besten mit diesen drei Bereitstellungsansätzen:
- Containerisierung:
- Docker für konsistente Umgebungen verwenden
- Unterstützung für GPU-Beschleunigung aktivieren
- Ordnungsgemäße Ressourcenzuweisung implementieren
Quantisierungstechniken können die Modellgröße erheblich reduzieren und die Leistung aufrechterhalten. Untersuchungen zeigen, dass Pruning die Modellgrößen um bis zu 90 % reduzieren kann und dabei 95 % der ursprünglichen Genauigkeit beibehält.
Strategien zur Ressourcenverwaltung
Gutes Ressourcenmanagement und die richtige Hardware sind entscheidend für Spitzenleistungen bei lokalen LLM-Bereitstellungen mit LangChain. Kleine Sprachmodelle (SLMs) bieten Ihnen mehrere Vorteile für die Edge-Bereitstellung:
- Reduzierte Rechenlast durch Quantisierung
- Geringere Speicheranforderungen
- Verbesserte Energieeffizienz
- Verbesserte Inferenzgeschwindigkeit
Tools wie vLLM oder der NVIDIA Triton Inference Server helfen bei Bereitstellungen für mehrere Benutzer. Mit diesen Lösungen können Sie große Modelle mithilfe von Tensor-Parallelität auf mehrere GPUs aufteilen. Einige Modelle, wie die Versionen mit 90 Milliarden Parametern, die 216 GB GPU-Speicher benötigen, funktionieren besser mit verteilten Inferenzstrategien.
So holen Sie das Beste aus Ihren Ressourcen in einem LangChain RAG-System heraus:
- Ordnungsgemäße Verwaltung des GPU-Speichers implementieren
- Stapelverarbeitung für mehrere Abfragen verwenden
- Flash Attention aktivieren, wenn verfügbar
- Systemleistungsmetriken überwachen
Ein strukturierter Ansatz für Bereitstellung und Verwaltung hilft Ihnen, ein schnelles lokales RAG-System mit LangChain zu erstellen, das sowohl Leistung als auch Datenschutz gewährleistet. Diese Methode stellt sicher, dass Sie zuverlässige Ergebnisse für Unternehmensanwendungen erhalten und gleichzeitig die Ressourcen sinnvoll nutzen.
Datenverarbeitungs- und Embedding-Pipeline
Ein gut aufgebautes RAG-System mit LangChain erfordert sorgfältige Aufmerksamkeit für die Datenverarbeitung und die Erzeugung von Embeddings. Sehen wir uns an, wie man eine robuste Pipeline erstellt, die sowohl Sicherheit als auch Leistung bietet.
Workflow der Dokumentenverarbeitung
Die Pipeline zur Dokumentenverarbeitung beginnt mit der richtigen Datenvorbereitung. Vektor-Embeddings sind zu Hauptzielen für Datendiebstahl geworden. Jüngste Studien zeigen, dass Angreifer in 92 % der Fälle exakte Eingaben wiederherstellen konnten. Dies führt uns zur Implementierung eines gut durchdachten Workflows:
-
Datenvorbereitung:
- Textextraktion und Normalisierung
- Entfernung irrelevanter Inhalte
- Formatstandardisierung
-
Chunking-Strategie:
- Optimale Chunk-Größe: 1200 Zeichen
- Chunk-Überlappung: 300 Zeichen
Zum Laden von Dokumenten können Sie je nach Datenquelle den WebBaseLoader von LangChain oder andere spezialisierte Lader verwenden.
Methoden zur Erzeugung von Embeddings
Die effektive Erzeugung von Embeddings bildet den Kern unseres LangChain RAG-Systems. Diese Embeddings ermöglichen mehrere fortgeschrittene Anwendungen:
| Anwendungstyp | Zweck |
|---|---|
| Semantische Suche | Bedeutungsbasierte Abfragen |
| Gesichtserkennung | Bildverarbeitung |
| Stimmerkennung | Audioanalyse |
| Empfehlungen | Inhaltsabgleich |
Die Qualität des Modells beeinflusst direkt die Genauigkeit der Embeddings. Embeddings sind maschinelle Repräsentationen beliebiger Daten. Wir optimieren unsere Embedding-Erzeugung durch die Implementierung einer eigenschaftserhaltenden Verschlüsselung, die Folgendes ermöglicht:
- Sinnvoller Abgleich von Abfragen
- Geschützte Vektoroperationen
- Sichere Ähnlichkeitssuchen
Für lokale Embeddings bietet LangChain Ollama Embeddings an, die in Verbindung mit der Ollama-Bibliothek zur effizienten Erzeugung von Embeddings verwendet werden können.
Maßnahmen zur Qualitätskontrolle
Hohe Standards in unserer RAG-Pipeline erfordern umfassende Maßnahmen zur Qualitätskontrolle. Studien zeigen, dass die Qualität der Embeddings die Abrufpräzision erheblich beeinflusst. Unser Qualitätssicherungsprozess umfasst:
-
Datenvalidierung:
- Eingabebereinigung
- Formatüberprüfung
- Konsistenzprüfungen
-
Leistungsüberwachung:
- Verfolgung der Abrufpräzision
- Messung der Trefferquote (Recall)
- F1-Score-Bewertung
Die Verschlüsselung auf Anwendungsebene (ALE) bietet die beste Sicherheit für Embeddings. Dadurch bleiben die Daten auch dann geschützt, wenn jemand an die Datenbank-Anmeldeinformationen gelangt. Diese Maßnahmen helfen uns, Sicherheit und Leistung aufrechtzuerhalten und gleichzeitig die Kontrolle über sensible Daten zu behalten.
Leistungsoptimierung und Überwachung
Um die beste Leistung aus unserem lokalen RAG-System mit LangChain herauszuholen, ist eine genaue Beobachtung von Metriken, Optimierung und Überwachung erforderlich. Sehen wir uns an, wie wir unser System optimal zum Laufen bringen und gleichzeitig die Daten privat halten können.
Systemleistungsmetriken
Wir müssen mehrere wichtige Leistungsindikatoren verfolgen, um den Systemzustand zu überwachen. Unser Fokus liegt auf drei Hauptkategorien von Metriken:
| Metriktyp | Beschreibung | Zielbereich |
|---|---|---|
| Latenz | Antwortzeit pro Abfrage | 100-500 ms |
| Durchsatz | Bearbeitete Anfragen pro Sekunde | Basierend auf Kernen |
| Ressourcennutzung | CPU-, Speicher-, GPU-Auslastung | 80 % Schwellenwert |
Diese Metriken helfen uns, Engpässe und verbesserungswürdige Bereiche zu erkennen. Wir verfolgen sowohl die Leistung der Vektorsuche als auch die Inferenzgeschwindigkeiten der Modelle, um einen reibungslosen Betrieb des Systems zu gewährleisten.
Optimierungstechniken
Wir verwenden mehrere bewährte Optimierungsstrategien, um die Leistung unseres LangChain RAG-Systems zu steigern. Unsere Schwerpunktbereiche sind:
-
Optimierung der Vektorsuche:
- Vektordimensionen reduzieren (max. 4096) zur schnelleren Verarbeitung
- Vorfilterung verwenden, um den Suchbereich einzugrenzen
- Dedizierte Suchknoten für bessere Leistung einrichten
-
Ressourcenmanagement:
- Separate Suchknoten einrichten, um die Arbeitslast zu isolieren
- Genügend RAM für Vektordaten und Indizes hinzufügen
- Binäre Datenvektoren verwenden, um 3x Speicher zu sparen
Unsere Tests zeigen, dass eine gute Vektorquantisierung den Speicherbedarf senken und gleichzeitig eine hohe Suchgenauigkeit beibehalten kann. Wir empfehlen die Verwendung von skalarer Quantisierung für die meisten Embedding-Modelle, da sie die Recall-Fähigkeiten stark erhält.
Einrichtung von Überwachung und Alarmierung
Unsere Überwachungseinrichtung erkennt und reagiert frühzeitig auf Leistungsprobleme. Wir haben robuste Überwachungssysteme aufgebaut, die Folgendes umfassen:
-
Alarmkonfiguration:
- Benutzerdefinierte, periodenbasierte Alarme für bestimmte Ereignisse
- Minutengenaue Abgleichalarme für kritische Probleme
- Geplante, abfragebasierte Benachrichtigungen
-
Leistungsverfolgung:
- Metriken zur Systemstabilität
- Lastüberwachung zur Erkennung ungewöhnlicher Muster
- Kostenverfolgung für jede Modellinteraktion
Wir verwenden automatisierte Metriken, um den Bewertungsprozess zu vereinfachen. Diese Metriken beantworten komplexe Fragen zur Systemleistung, z. B. wie gut Reranker funktionieren und wie effizient unsere Chunking-Techniken sind.
Das System benötigt regelmäßige Überprüfungen seiner Komponenten, um optimal zu funktionieren. Wir führen automatisierte Belastungstests durch, um zu sehen, wie gut das System Spitzenlasten bewältigt. Unsere Überwachung verfolgt auch die Leistung über die Zeit, was uns zeigt, wie sich Änderungen an Datenquellen und Benutzerverhalten auf die Systemleistung auswirken.
Diese umfassenden Überwachungs- und Optimierungsstrategien helfen uns, ein RAG-System aufrechtzuerhalten, das gut funktioniert und unsere Anforderungen erfüllt, während die Daten privat und sicher bleiben.
Fazit
Ein lokales RAG-System mit LangChain erfordert lediglich, dass Sie über mehrere technische Aspekte nachdenken. Die Vorteile machen all diese Arbeit lohnenswert. Private KI-Lösungen helfen Organisationen, die volle Kontrolle über sensible Daten zu behalten. Sie bieten leistungsstarke Funktionen durch lokale Sprachmodelle und LangChain-basierte RAG-Implementierungen.
Mehrere Faktoren bestimmen Ihren Erfolg. Gute Hardwarespezifikationen sind die Grundlage. Eine schnelle und genaue Informationsbeschaffung ergibt sich aus effizienten Vektorspeichern. Lokale LLM-Bereitstellungsstrategien arbeiten mit sicheren Datenverarbeitungspipelines. Zusammen bieten sie Ihnen eine hervorragende Leistung und Datenschutz.
Das Ressourcenmanagement des Systems spielt eine entscheidende Rolle bei der Implementierung. Gute Überwachungstools helfen, die Spitzenleistung aufrechtzuerhalten. Regelmäßige Optimierung und Verfeinerung sorgen dafür, dass alles reibungslos läuft, während die Datenmenge wächst.
Organisationen sollten ihre Reise in die private KI mit kleinen Schritten beginnen. Sie müssen sehr gut testen und auf der Grundlage der tatsächlichen Nutzung durch die Menschen wachsen. Dieser Weg hilft, Probleme frühzeitig zu erkennen und sorgt für ein stetiges Systemwachstum.
Datenschutzanforderungen sind keine Einschränkungen - sie sind Chancen, zuverlässigere KI-Systeme zu bauen. Lokale RAG-Implementierungen mit LangChain zeigen, wie Organisationen fortschrittliche KI nutzen können, ohne die Datensicherheit zu gefährden oder die betriebliche Unabhängigkeit zu verlieren.
FAQs
F1. Was sind die Hauptvorteile beim Erstellen eines RAG-Systems mit lokalen Daten unter Verwendung von LangChain?
Der Aufbau eines RAG-Systems mit lokalen Daten unter Verwendung von LangChain bietet verbesserten Datenschutz, reduzierte Latenz, anpassbare Architekturen und Unabhängigkeit von Drittanbieterdiensten. Es ermöglicht Organisationen, die vollständige Kontrolle über sensible Informationen zu behalten und gleichzeitig fortschrittliche KI-Funktionen und die leistungsstarken Werkzeuge von LangChain für die RAG-Entwicklung zu nutzen.
F2. Was sind die Schlüsselkomponenten, die für die Einrichtung eines lokalen RAG-Systems mit LangChain erforderlich sind?
Die wesentlichen Komponenten für ein lokales RAG-System mit LangChain umfassen eine robuste Entwicklungsumgebung mit Python 3.11 oder höher, einen Vektorspeicher für effiziente Datenspeicherung und -abruf, ein lokales Sprachmodell (LLM) wie LLaMA 3.1 und eine Datenverarbeitungspipeline für die Dokumentenhandhabung und die Erzeugung von Embeddings. LangChain bietet Tools wie ChatOllama für die Integration lokaler LLMs und OllamaEmbeddings für die lokale Erzeugung von Embeddings.
F3. Wie kann die Leistung in einem lokalen RAG-System mit LangChain optimiert werden?
Die Leistungsoptimierung in einem LangChain-basierten lokalen RAG-System umfasst die Implementierung effizienter Vektorsuchtechniken, ein ordnungsgemäßes Ressourcenmanagement und die regelmäßige Überwachung von Schlüsselmetriken wie Latenz, Durchsatz und Ressourcennutzung. Techniken wie Vektorquantisierung, Vorfilterung und Aufgabenzerlegung können die Systemeffizienz erheblich verbessern. Die Werkzeuge von LangChain wie RunnablePassthrough und StrOutputParser können zur Optimierung der RAG-Pipeline verwendet werden.
F4. Welche Herausforderungen können bei der Implementierung eines lokalen RAG-Systems in einer Unternehmensumgebung auftreten?
Häufige Herausforderungen sind der Umgang mit veralteter oder inkonsistenter Dokumentation, die begrenzte Kapazität von Fachexperten für die Inhaltsbereinigung und die Notwendigkeit einer sicheren Datenhandhabung innerhalb der Netzwerk-Grenzen der Organisation. Zusätzlich können Hardware- und Softwarekompatibilitätsprobleme bei der Bereitstellung lokaler LLMs und der Integration von LangChain-Komponenten auftreten.
F5. Wie kann die Datenqualität für eine bessere Leistung des RAG-Systems mit LangChain verbessert werden?
Um die Datenqualität in einem LangChain RAG-System zu verbessern, können Organisationen Sprints zur Inhaltsbereinigung implementieren, Interviews mit Fachexperten führen, eine automatisierte Bewertung der Inhaltsqualität verwenden und Metadaten anreichern. Es ist auch vorteilhaft, einen strukturierten Workflow für die Dokumentenverarbeitung mit den Werkzeugen von LangChain wie RecursiveCharacterTextSplitter für die Textaufteilung einzurichten und Qualitätskontrollmaßnahmen in der gesamten Datenpipeline zu implementieren. Die Dokumentenlader und Text-Splitter von LangChain können für ein besseres Chunking und einen besseren Kontextabruf optimiert werden.