Tiefe Integration von KI-Agenten und verstärkendem Lernen: Von der Trennung zur Revolution
10. September 2025Ollie @puppyone
Kernaussage: Die frühe Welle der Entwicklung von KI-Agenten stützte sich hauptsächlich auf Prompt-Engineering und hatte wenig Verbindung zum traditionellen verstärkenden Lernen (RL). Jüngste Forschungen deuten jedoch darauf hin, dass RL nun zur zentralen treibenden Kraft wird, die Agenten in Richtung allgemeiner Intelligenz vorantreibt. Basierend auf Spitzenforschung von Mai bis August 2025 zeigt dieser Bericht drei wichtige Integrationstrends auf.
Paradigmeninnovation im Single-Agent RL
Von RLHF zu RLVR: Durchbrüche im Design objektiver Belohnungen
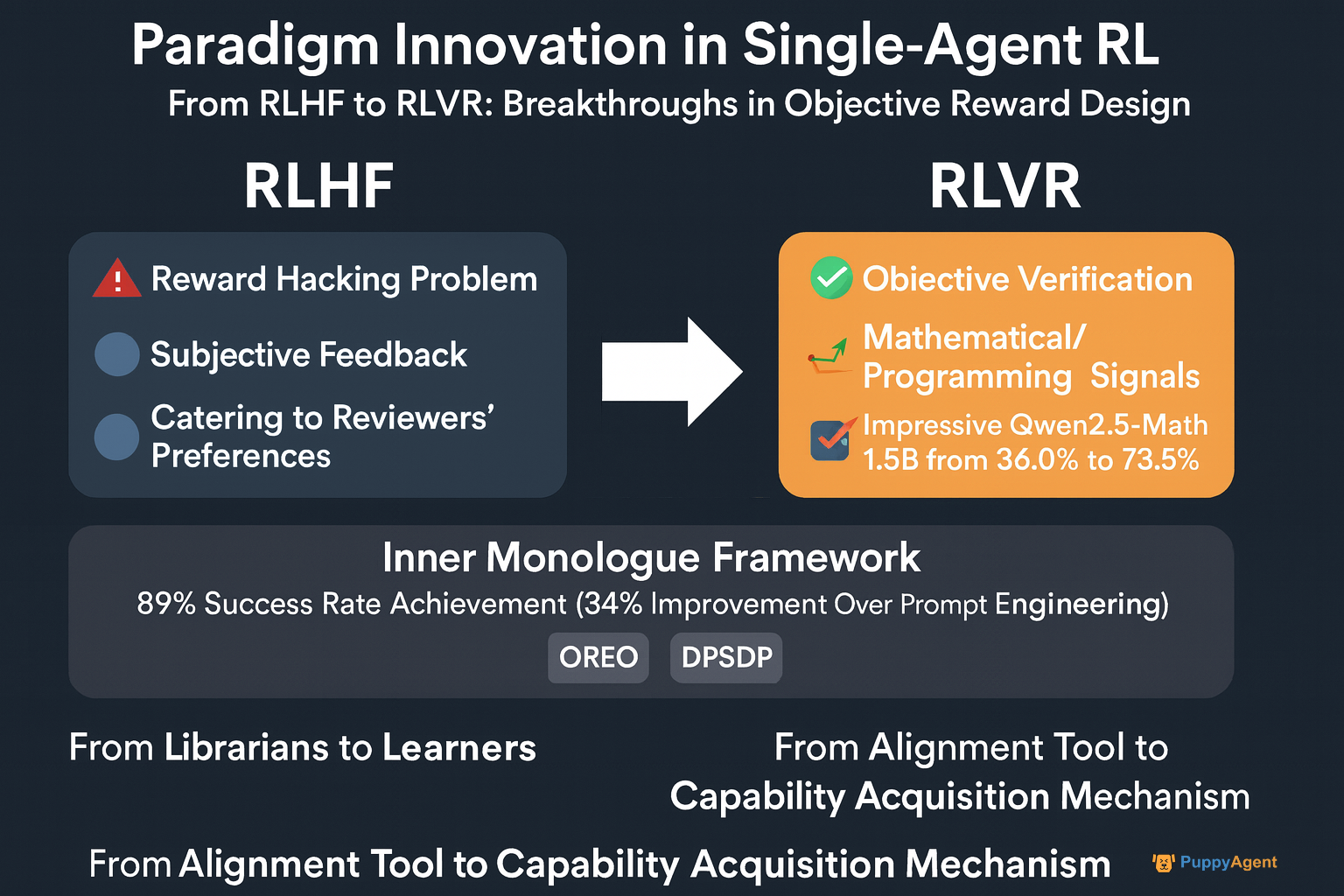
Traditionelles RLHF (Reinforcement Learning from Human Feedback) verlässt sich auf subjektives menschliches Feedback und leidet unter dem Problem des "Reward Hacking". Auf der ICML 2024 erklärte OpenAI-Forscher John Schulman unverblümt: "Wir haben festgestellt, dass Modelle lernen, den Vorlieben der Prüfer zu entsprechen, anstatt Probleme wirklich zu lösen." Dies hat einen Wandel hin zu RLVR (Reinforcement Learning with Verifiable Rewards) angeregt, bei dem objektive, überprüfbare Signale aus Bereichen wie Mathematik und Programmierung genutzt werden. Das Qwen-Team von Alibaba wandte diesen Ansatz an, um die Genauigkeit von Qwen2.5-Math-1.5B auf dem MATH500-Benchmark von 36,0 % auf 73,6 % zu steigern, was zeigt, dass sich RL von einem "Ausrichtungswerkzeug" zu einem "Fähigkeitserwerbsmechanismus" entwickelt.
Professor Sergey Levine von der UC Berkeley bemerkte: "Wir erleben eine grundlegende Transformation. Frühe Agenten waren wie Bibliothekare mit riesigen Gedächtnissen; jetzt wollen wir sie zu echten Lernern machen." Das Inner Monologue Framework seines Teams veranschaulicht diesen Wandel – Agenten entwickeln einen "inneren Monolog" durch geschlossenes Feedback mit ihrer Umgebung und erreichen eine Erfolgsquote von 89 % bei Roboternavigationsaufgaben – 34 % höher als bei reinen Prompt-Engineering-Methoden. In der Zwischenzeit verbessert DeepMinds OREO-Algorithmus das mehrstufige Denken durch Optimierung der Bellman-Gleichung, während DPSDP direkte Richtliniensuchfunktionen für Multi-Agenten-Systeme bereitstellt.
Verkörperte Intelligenz und Multi-Agenten-Integration
Praktische Durchbrüche in der verkörperten Intelligenz
Professorin Daniela Rus vom MIT bemerkte in einem Interview: "Wir erleben endlich einen qualitativen Sprung in der Roboterintelligenz." Sie bezog sich auf die bahnbrechende Leistung des LLaRP-Frameworks – ein System, das große Sprachmodelle mit verstärkendem Lernen integriert – das eine Erfolgsquote von 42 % bei 1.000 bisher ungesehenen verkörperten Aufgaben erzielte, 1,7-mal höher als traditionelle Baselines. Noch bemerkenswerter ist, dass nur eine kleine Anzahl von Wahrnehmungs- und Aktionsdecodern trainiert werden muss, um ein eingefrorenes LLM in eine allgemeine Richtlinie umzuwandeln.
Linxi Fan, ein Forschungswissenschaftler bei NVIDIA, kommentierte: "Das Eureka-Projekt hat unser Verständnis des Belohnungsdesigns komplett neu geformt." In diesem Projekt generiert GPT-4 automatisch Belohnungsfunktionscode für verstärkendes Lernen; bei komplexen Roboterarm-Manipulationsaufgaben übertrafen KI-generierte Belohnungsfunktionen tatsächlich die von menschlichen Experten sorgfältig erstellten. In ähnlicher Weise hat das Robotik-Team von Google DeepMind auf diesem Weg Durchbrüche erzielt – ihr RT-2-System, das auf einem Vision-Language-Action-Modell basiert, ermöglicht es Robotern, komplexe Anweisungen in natürlicher Sprache zu verstehen und entsprechende Aktionen auszuführen.
Evolution der Multi-Agenten-Kollaboration
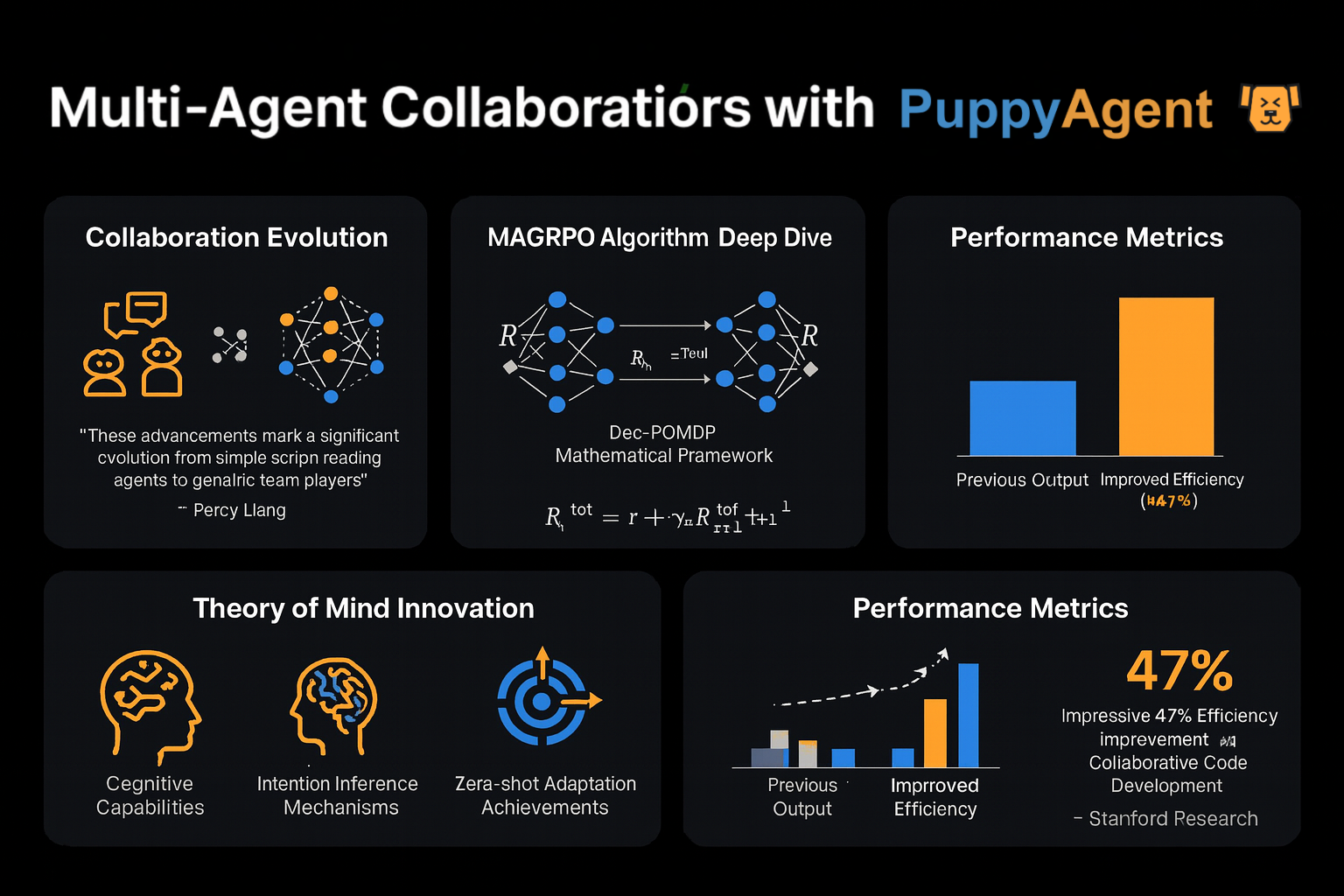
Professor Percy Liang aus Stanford bemerkte: "Frühe Multi-Agenten-Debatten waren wie mehrere Personen, die unabhängig voneinander Skripte lesen – jetzt sehen wir echtes Teamwork." Der neueste MAGRPO-Algorithmus modelliert die LLM-Kollaboration als Dec-POMDP (Decentralized Partially Observable Markov Decision Process) und erreicht durch gemeinsame Belohnungsoptimierung eine echte Zusammenarbeit. In kollaborativen Code-Entwicklungstests verbesserte dieser Ansatz die Effizienz um 47 % im Vergleich zu traditionellen Multi-Turn-Dialogmethoden. Noch faszinierender ist, dass ein anderes Stanford-Team Agenten mit einem "Theory of Mind"-Modul ausstattete, das es ihnen ermöglicht, die Absichten und Strategien anderer Teilnehmer abzuleiten – was bemerkenswerte adaptive Fähigkeiten in Zero-Shot-Spielumgebungen demonstriert.
Wandel in den akademischen Trends
Fokus der Top-Konferenzen
Der Wandel in den akademischen Trends ist unverkennbar. Das Tutorial "Generative AI Meets Reinforcement Learning" auf der ICML 2025 zog über 2.000 Teilnehmer an; seine Sprecherin, Professorin Chelsea Finn, eröffnete mit den Worten: "Wenn Sie sich immer noch rein auf Prompt-Engineering verlassen, fallen Sie wahrscheinlich bereits zurück." Die ACL 2025, die ihren ersten "REALM"-Workshop veranstaltete, stellte das RL-basierte Agententraining in den Mittelpunkt ihrer Agenda – und erhielt dreimal so viele Einreichungen wie erwartet. Die ICLR 2025 präsentierte mehrere Durchbrüche, darunter das Open-Source-Framework Agent S, das Computer wie ein Mensch bedient und ein beispielloses Maß an Automatisierung bei komplexen Aufgaben erreicht.
Besonders hervorzuheben ist, dass der Workshop "Open-World Agents" auf der NeurIPS 2024 eine Keynote von Yann LeCun enthielt, der betonte: "Statischer Wissensabruf reicht nicht mehr aus – was wir brauchen, sind Agenten, die in offenen Umgebungen kontinuierlich lernen und sich anpassen können." Diese Perspektive fand bei den Teilnehmern breite Resonanz; während einer Podiumsdiskussion stimmten mehrere Turing-Preisträger einstimmig darin überein, dass verstärkendes Lernen den vielversprechendsten Weg bietet, um die zentralen Herausforderungen der künstlichen allgemeinen Intelligenz anzugehen.
Herausforderungen und Chancen
Reale Herausforderungen und industrielle Chancen
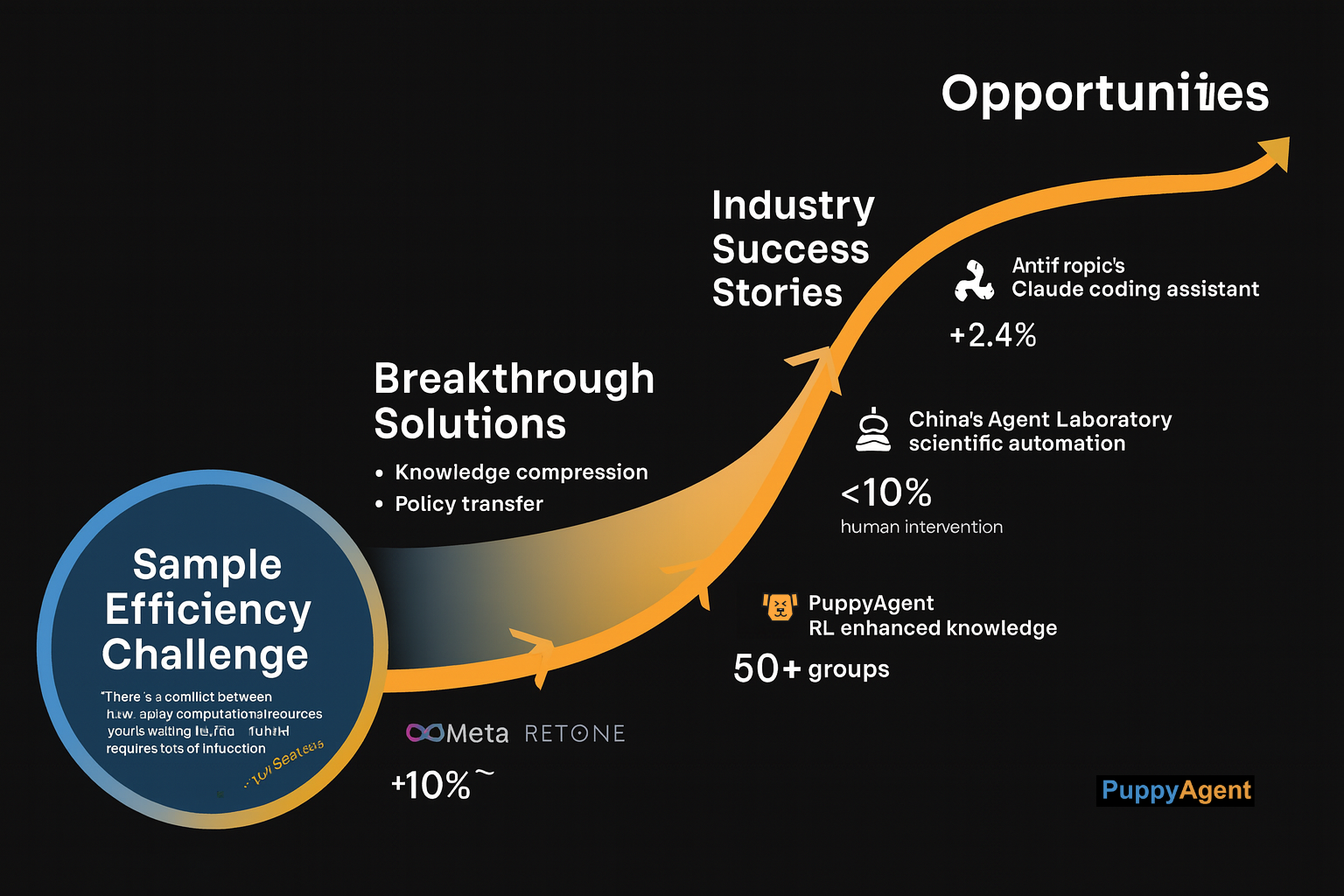
Natürlich bleiben erhebliche Herausforderungen bestehen. In seiner letzten öffentlichen Rede vor seinem Abschied von OpenAI gab Ilya Sutskever offen zu: "Unsere größte Schwierigkeit liegt in der Stichprobeneffizienz. Jede LLM-Inferenz verbraucht massive Rechenressourcen, während traditionelles RL Millionen von Interaktionen erfordert." Dieser Widerspruch treibt neuartige Lösungen voran – zum Beispiel hat das Forschungsteam von Meta eine "destillationsbasierte Lernmethode" entwickelt, die Wissen aus großen Modellen in kleinere für das RL-Training komprimiert und die erlernten Richtlinien dann wieder auf die großen Modelle überträgt.
Die Reaktion der Industrie war ebenso schnell. Das Claude-Team von Anthropic testet derzeit einen RL-gestützten Programmierassistenten; Insider verraten, dass seine Leistung bei komplexen Programmieraufgaben "erstaunlich" ist. Inzwischen hat das chinesische Agent-Labor-Projekt bereits eine durchgehende Automatisierung wissenschaftlicher Arbeitsabläufe erreicht – von der Literaturrecherche und dem experimentellen Design bis zum Verfassen von Papieren – und erfordert weniger als 10 % menschliches Eingreifen. Dieser Automatisierungstrend durchdringt schnell weitere vertikale Bereiche. Im Wissensmanagement beispielsweise beginnen intelligente Wissensdatenbanksysteme wie puppyone, Mechanismen des verstärkenden Lernens auf das Dokumentenverständnis, die Wissensextraktion und die automatisierte Beantwortung von Fragen anzuwenden. Indem solche Systeme kontinuierlich aus den Abfragemustern und dem Feedback der Benutzer lernen, können sie ihre Wissensorganisations- und Abrufstrategien iterativ optimieren – und sich von passiven Informationsspeichern in proaktive intelligente Assistenten verwandeln. Die von Shenzhen AIRS veröffentlichte Open-Source-Plattform AIRSTONE bietet eine beispiellose rechnerische Unterstützung für die Forschung zur verkörperten Intelligenz und wird bereits von über 50 internationalen Forschungsgruppen genutzt.
Fazit

Die Trennung zwischen Agenten und RL existierte tatsächlich – aber wie es Professor Tommi Jaakkola vom MIT treffend formulierte: "Das ist wie das frühe Internet, das nur statische Webseiten hatte; dynamische Interaktion ist die wahre Zukunft." Wir erleben einen grundlegenden Wandel: vom statischen Denken auf der Grundlage vorab trainierten Wissens zur dynamischen Optimierung durch kontinuierliches Lernen aus Erfahrung. RLVR ermöglicht es Agenten, harte Fähigkeiten wie mathematisches Denken zu erwerben; LLaRP demonstriert eine szenarioübergreifende Generalisierung; und MARL-basierte Multi-Agenten-Systeme zeigen die Entstehung echter kollaborativer Intelligenz.
Wie DeepMind-Gründer Demis Hassabis kürzlich erklärte: "Verstärkendes Lernen ist nicht nur eine Trainingsmethode – es ist der Kernmechanismus der Intelligenz selbst." Diese einst "vernachlässigte Disziplin" mit ihren tiefgreifenden Einblicken in das Lernen durch Versuch und Irrtum, die Optimierung von Richtlinien und die Anpassung an die Umgebung wird nun zur solidesten theoretischen Grundlage für den Weg der Agenten zur künstlichen allgemeinen Intelligenz. Diese Konvergenz ist keine einfache Aneinanderreihung von Technologien – es ist eine kognitionsgetriebene Revolution, die von der Grundlagenforschung angetrieben wird.
Wichtige Referenzen: ICML 2025 Tutorial, ACL 2025 REALM Workshop, Technischer Bericht zu Qwen2.5-Math, LLaRP-Paper, MAGRPO-Algorithmus, Inner Monologue und andere neueste Forschungsergebnisse