KI-Selbstentwicklung: Ein umfassender Überblick über geschlossene LLM-Systeme und Multi-Agenten-Grenzen
4. September 2025Ollie @puppyone
Warum müssen wir die „Selbstentwicklung von LLM“ jetzt ernsthaft untersuchen? Einfach ausgedrückt, sind die heutigen leistungsstarken Modelle meist „statische Produkte“: Nach einem einmaligen Offline-Training werden sie eingesetzt und sehen sich dann mit Verteilungsverschiebungen, neuen Aufgabenformen und der schnellen Entwicklung von Werkzeug-Ökosystemen konfrontiert. Sie können sich nur auf teures und verzögertes menschliches Neutraining verlassen, um aufzuholen. Dieses Paradigma wird in einer nicht-stationären Welt weiterhin Verluste verursachen: die technischen Schulden durch veraltetes Wissen, die kontinuierlichen Kosten für die Kennzeichnung und Bereinigung von Daten und die Anfälligkeit bei komplexen Schlussfolgerungen mit langem Schwanz und bei der domänenübergreifenden Zusammenarbeit. Was wir brauchen, sind nicht nur größere Modelle, sondern Systeme, die während des Betriebs lernen, sich in ihrer Umgebung selbst korrigieren und in einem geschlossenen Kreislauf kontinuierlich stärker werden können.
 Bildquelle: puppyone
Bildquelle: puppyone
Wir haben uns auf die Arbeiten im Zusammenhang mit der „Selbstentwicklung/Selbstverbesserung von LLM / KI-Agenten“ von Juni bis August 2025 konzentriert und einen umfassenden Überblick und ein Fortschrittsupdate bereitgestellt. Wir hoffen, den Gestaltungsspielraum und die machbaren Wege für die „Selbstentwicklung“ für Entwickler und Forscher zu klären: welche Probleme zuerst geschlossen werden müssen, wie ein minimal lebensfähiges System aufgebaut werden kann, welche Metriken verwendet werden müssen, um zu messen, ob man „wirklich stärker wird“, und wie man „Selbstentwicklung“ und „kontrollierbar und vertrauenswürdig“ auf technischer Ebene nutzbar machen kann.
Zusammenfassung (Überblick Juni–August 2025)
Definition
Die akademischen und industriellen Gemeinschaften haben noch keine einheitliche Definition für „Selbstentwicklung“ erreicht. Im August wurden jedoch nacheinander zwei systematische Übersichten veröffentlicht, die sich auf „selbstentwickelnde Agenten/selbstentwickelnde KI-Proxys“ konzentrieren. Sie schlugen ein strukturiertes Framework vor, das sich auf „was sich entwickeln soll, wann es sich entwickeln soll und wie es sich entwickeln soll“ konzentriert und sich auf die kontinuierliche Systemverbesserung durch interaktives Feedback, Umgebungssignale und geschlossene Optimierung konzentriert. Dies markiert den Eintritt des Themas in ein Konsensfenster der phasenweisen Konvergenz.
Repräsentative Wege
 Bildquelle: puppyone
Bildquelle: puppyone
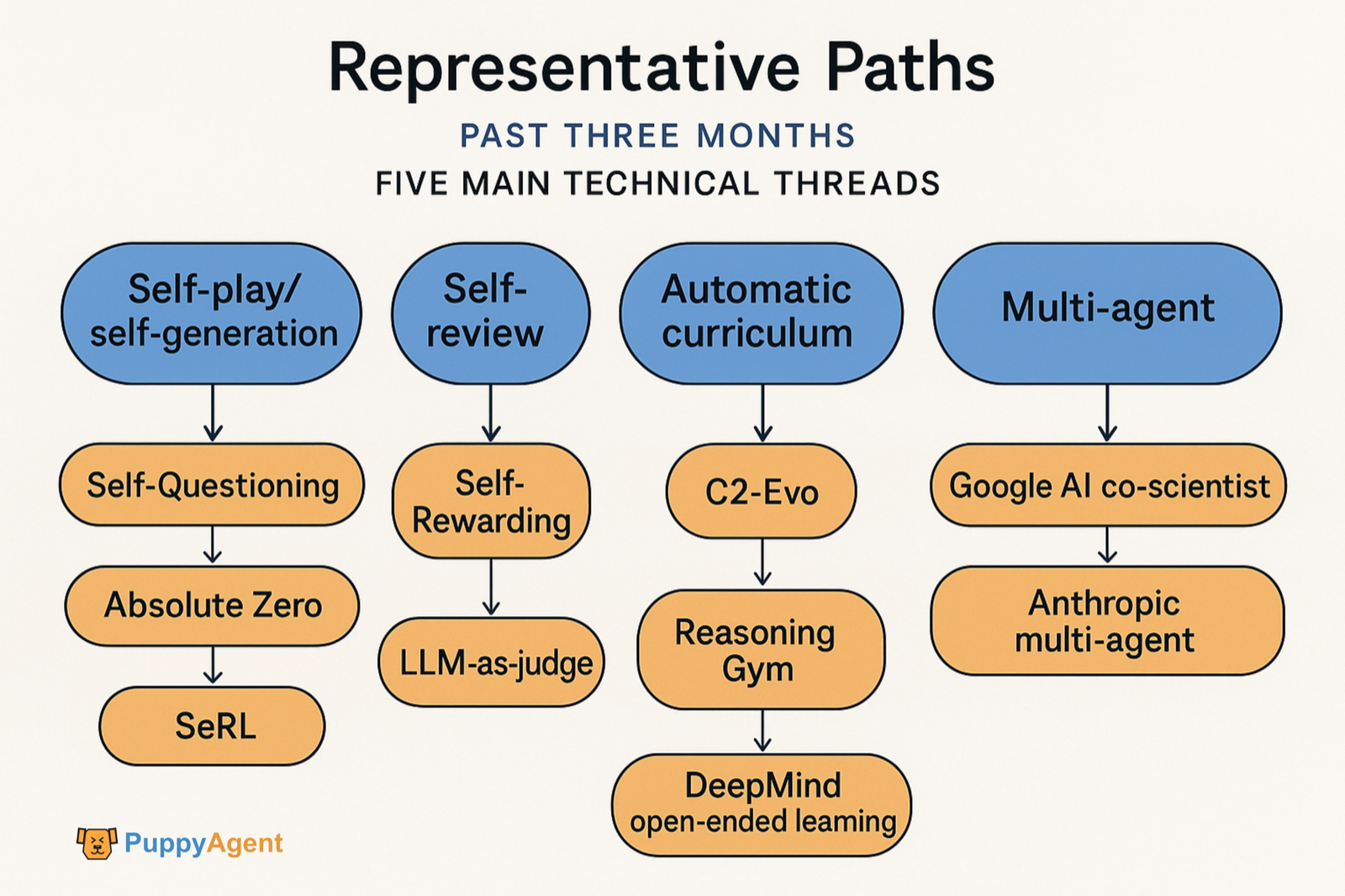
In den letzten drei Monaten konzentrierte sich die repräsentative Arbeit auf fünf technische Hauptstränge:
- Selbstspiel/Selbstgenerierungsaufgaben ohne externe Daten (Self‑Questioning, Absolute Zero, SeRL).
- Selbstüberprüfung/Selbstbelohnung (Self‑Rewarding, LLM‑as‑judge).
- Ko-Evolution von Daten und Modellen (C2‑Evo, NavMorph).
- Automatischer Lehrplan/offene Evolution (SEC, Reasoning Gym, DeepMind Open-Ended Learning Tradition).
- Multi-Agenten-Selbstverbesserungs-Workflows (Google AI Co-Scientist, Anthropic's Multi-Agent-System). Es gab auch quantitative Beweise und diagnostische Methoden bezüglich „welche kognitiven Gewohnheiten die Selbstverbesserung unterstützen“.
Bewertung und Sicherheit:
Prozessgenerierungsumgebungen mit „überprüfbaren Belohnungen“ wie Reasoning Gym sind zu einem Hebel für das Training und die Bewertung der geschlossenen Selbstentwicklung geworden. Googles KI-Co-Wissenschaftler korreliert interne Selbstspiel-Ranglisten und Elo-Werte mit der Genauigkeit von GPQA-Problemen. Anthropic betont die Kombination von LLM-Richter und menschlicher Überprüfung sowie den technischen Schutz und die Rückverfolgbarkeit für Multi-Agenten-Systeme. In der Zwischenzeit haben die Risiken von „Betrug/Halluzination“ und die Ausrichtung bei der „Selbstverbesserung“ zu mehr Erforschung von Sandboxing- und Wächterstrategien geführt.
Konzept und Grenzen: Was sind „selbstentwickelnde“ LLM/KI-Agenten?
Selbstentwicklung
Selbstentwicklung ist kein einzelnes Trainingsparadigma, sondern eine Kategorie des geschlossenen Systemdesigns: Mit minimaler menschlicher Intervention generiert das System kontinuierlich Daten/Aufgaben, verbessert Strategien und Parameter oder schreibt seine eigene Werkzeugkette/seinen eigenen Code durch Mechanismen wie Umgebungsfeedback, Werkzeugausführung, Selbstspiel oder Selbstüberprüfung neu. Dies ermöglicht es ihm, im Laufe der Zeit bei Aufgaben außerhalb der Verteilung, bei langfristigen Aufgaben und bei komplexen Schlussfolgerungen stärker zu werden. Zwei neuere Übersichten haben es in eine Rückkopplungsschleife mit vier Komponenten abstrahiert: Systemeingabe, Agentensystem, Umgebung und Optimierer. Sie haben auch Methoden basierend auf drei Dimensionen bewertet und zusammengefasst: „was sich entwickeln soll, wann es sich entwickeln soll und wie es sich entwickeln soll“, wobei der Übergang von statischen Basismodellen zu einem „selbstentwickelnden Agenten“-System mit lebenslanger Anpassungsfähigkeit betont wird.
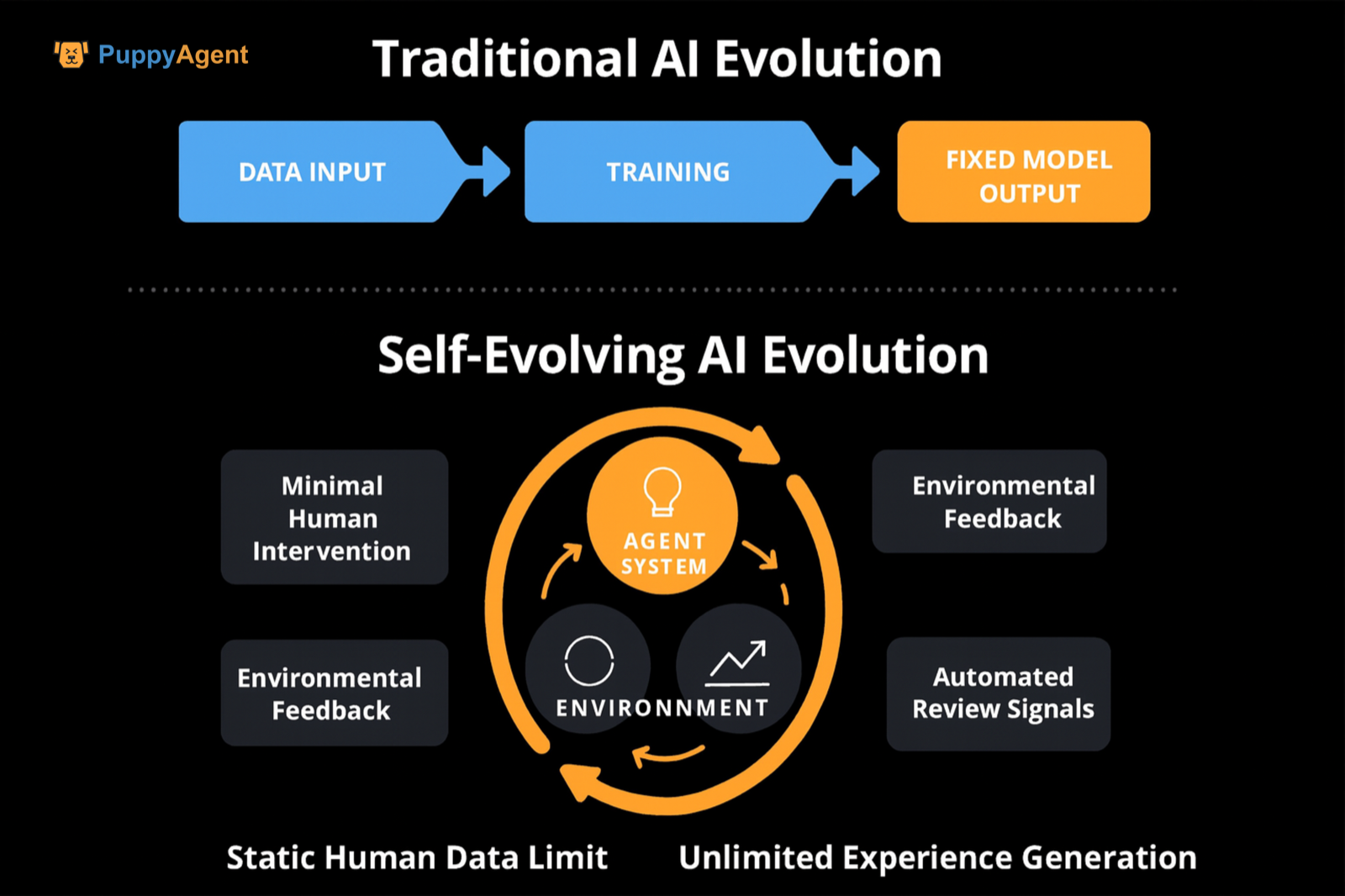
Der Unterschied zur traditionellen Selbstüberwachung/Anweisungs-Feinabstimmung
 Bildquelle: puppyone
Bildquelle: puppyone
Der Unterschied liegt in der Betonung der Dominanz von „Erfahrungs-/Interaktionsdaten“, der dynamischen Generierung von Aufgabenraum und Schwierigkeit und automatisierten Quellen von Überprüfungs-/Belohnungssignalen (Selbstüberprüfung, ausführbare Überprüfung, Wettbewerbsrangliste usw.). Dies durchbricht die Obergrenze statischer menschlicher Daten. DeepMind hat die „Ära der Erfahrung“ vorgeschlagen und plädiert für Interaktionserfahrung als Hauptdatenquelle, wobei Belohnungssignale in der Welt verankert sind. Es schlägt vor, das Weltmodell und die Belohnungsfunktion kontinuierlich zu aktualisieren, um Verzerrungen langfristig zu korrigieren, und liefert ein konzeptionelles und pfadbasiertes Argument für die „Selbstentwicklung“.
Forschungslandschaft und führende Labore/Teams/Forscher
 Bildquelle: pexels
Bildquelle: pexels
Google Research
Der KI-Co-Wissenschaftler, basierend auf Gemini 2.0, verwendet eine Multi-Agenten-Kollaboration von „Supervisor + dedizierten Agenten“. Zu den Komponenten gehören Generierungs-, Reflexions-, Ranking-, Evolutions-, Proximity- und Meta-Review-Agenten. Er nutzt automatisiertes Feedback und wissenschaftliche Debatten im Selbstspiel, Ranking-Turniere und evolutionäre Prozesse, um eine Selbstverbesserungsschleife mit „skalierbarer Berechnung zur Testzeit“ zu bilden. Seine interne Elo-Selbstbewertung korreliert positiv mit der Genauigkeit im anspruchsvollen GPQA-Datensatz. Expertenbewertungen in kleinen Stichproben deuten darauf hin, dass seine Ausgaben mehrere State-of-the-Art-Baselines (SOTA) in Bezug auf Neuheit und Wirkung übertreffen.
Anthropic
Anthropic hat seinen Multi-Agenten-Forschungssystem-Engineering-Plan öffentlich detailliert, der parallele Sub-Agenten von „Orchestrator–Worker“, externen Speicher, LLM-Richter-Bewertung in Kombination mit menschlicher Überprüfung umfasst. Es schlägt „sich selbst verbessernde Agenten“ vor (Modelle diagnostizieren selbst Fehlermodi und schreiben Prompts/Werkzeugbeschreibungen neu), wodurch eine Reduzierung der Aufgabenzeit für die Werkzeugnutzbarkeit um etwa 40 % erreicht wird. Es betont das emergente Verhalten in Multi-Agenten-Systemen und die Beobachtbarkeit auf technischer Ebene, gestaffelte Veröffentlichungen und Rollback-Sicherheitsvorkehrungen.
Meta
Zuckerberg hob während des Q2-Ergebnisberichts ausdrücklich die „Selbstverbesserung“ als strategischen Fokus des „Superintelligence Lab“ hervor und betonte die Reduzierung der Abhängigkeit von menschlichen Daten und die Entwicklung eines „sich selbst verbessernden“ Pfades, der mit der Vision der „persönlichen Superintelligenz“ verbunden ist.
OpenAI und akademische Schnittstellen
Medienberichte zitieren Sam Altman, der die aktuelle Phase als „vorbei am Ereignishorizont mit einem langsamen Start“ beschreibt und betont, dass die kurzfristige Selbstverbesserung nicht vollständig automatisiert ist, sondern eine rekursive Verbesserung der „Nutzung von KI zur Beschleunigung der KI-Forschung“ darstellt. Gleichzeitig demonstriert die „Darwin-Goedel-Maschine“ (von Clune und dem Sakana AI-Team) das automatische Lesen ihrer eigenen Protokolle, das Vorschlagen und Implementieren von Ein-Punkt-Code-Modifikationen und generationenübergreifende iterative Verbesserungen auf SWE-Bench und Polyglot. Sie deckt jedoch auch Risiken der „Selbsttäuschung/Protokollfälschung“ auf und unterstreicht die Bedeutung von Sandboxing- und Anti-Täuschungs-Bewertungen.
Klassifizierung technischer Mechanismen und repräsentativer Werke
Selbstspiel / Selbstgenerierte Aufgaben ohne externe Daten
-
Selbstbefragende Sprachmodelle (SQLM): Bei einem Themen-Prompt generiert ein asymmetrisches „Vorschläger-Löser“-Selbstspiel-Framework Fragen und Antworten, wobei beide Komponenten durch Verstärkungslernen (RL) trainiert werden. Der Vorschläger wird dafür belohnt, Probleme mittlerer Schwierigkeit zu generieren (weder zu einfach noch zu schwer), während der Löser anhand der Mehrheitsentscheidung als Proxy für die Korrektheit bewertet wird. Bei Programmieraufgaben dienen Unit-Tests als Überprüfung. Empirische Ergebnisse zeigen eine nachhaltige Verbesserung bei der dreistelligen Multiplikation, der OMEGA-Algebra und den Codeforces-Benchmarks ohne menschlich bereitgestellte Daten, was ein geschlossenes „Probleme generieren – Probleme lösen“-Paradigma darstellt.
-
Absolute Zero (AZR): Schlägt ein Verstärkungslernen mit überprüfbaren Belohnungen (RLVR)-Paradigma vor, das keine externen Daten erfordert. Ein einzelnes Modell generiert autonom codebasierte Denkaufgaben und verwendet einen Code-Executor, um sowohl die Aufgaben als auch ihre Lösungen zu validieren, was eine einheitliche Quelle überprüfbarer Belohnungen zur Steuerung eines offenen, aber fundierten Lernens darstellt. AZR erreicht oder übertrifft die State-of-the-Art-Leistung bei Programmier- und mathematischen Denkaufgaben im Vergleich zu Null-Supervisions-Baselines, die auf Zehntausenden von von Menschen kuratierten Beispielen beruhen, und betont eine integrierte, geschlossene Schleife aus Aufgabengenerierung, Überprüfung und Lernen.
-
SeRL: Kombiniert „Selbstinstruktion“ (Online-Anweisungserweiterung mit Filterung) und „Selbstreflexion“ (Mehrheitsentscheidung zur Schätzung von Belohnungen), was Verstärkungslernen mit selbstgenerierten Daten ermöglicht. Dieser Ansatz reduziert die Abhängigkeit von qualitativ hochwertigen, von Menschen bereitgestellten Anweisungen und überprüfbaren Belohnungen und zeigt eine überlegene Leistung bei mehreren Denk-Benchmarks und verschiedenen Modell-Backbones.
-
AMIE Medical Dialogue Self-Play Extension (Branchenbericht): Um die Abdeckung von Krankheiten und klinischen Szenarien zu erweitern, entwickelte Google eine „Selbstspiel-Diagnosedialog-Simulationsumgebung“ mit automatisierten Feedback-Mechanismen, um das Training zu bereichern und zu beschleunigen. Dies stellt eine branchenweite Anstrengung dar, Selbstspielmethoden zur Skalierung von KI in sicherheitskritischen Bereichen wie dem Gesundheitswesen anzuwenden.
 Bildquelle: pexels
Bildquelle: pexels
Selbstbewertung / Selbstbelohnung und adversarische Kritiker-Evolution
-
Selbstbelohnende Selbstverbesserung: Nutzt die „Asymmetrie zwischen Lösungsgenerierung und -überprüfung“, indem Modelle ihre eigenen Belohnungssignale in Bereichen ohne Referenzantworten bereitstellen können. Die Arbeit zeigt, dass selbst beurteilte Belohnungen mit der formalen Überprüfung bei Aufgaben wie Countdown-Rätseln und MIT Integration Bee-Problemen vergleichbar sind. In Kombination mit der Generierung synthetischer Fragen bildet dies eine vollständige Selbstverbesserungsschleife. Die Studie berichtet, dass ein destilliertes 7B-Modell nach dem selbstbelohnenden Training das Leistungsniveau der Teilnehmer des MIT Integration Bee erreicht, was das domänenübergreifende Potenzial des „LLM-als-Richter“-Paradigmas als Belohnungsmechanismus zeigt.
-
Selbstspiel-Kritiker (SPC): Trainiert zwei Kopien desselben Basismodells, um in einem adversarischen Selbstspiel als „hinterhältiger Generator“ (der absichtlich subtile Denkfehler produziert) und als „Kritiker“ (der versucht, sie zu erkennen) zu agieren. Mithilfe von Verstärkungslernen basierend auf den Spielergebnissen verbessert der Kritiker schrittweise seine Fähigkeit, fehlerhafte Denkschritte zu identifizieren, wodurch der Bedarf an manuellen Annotationen auf Schrittebene reduziert wird. Experimente zeigen signifikante Verbesserungen bei der Prozessbewertung auf Benchmarks wie ProcessBench, PRM800K und DeltaBench. Darüber hinaus kann der trainierte Kritiker die Denk-Suche zur Testzeit in verschiedenen LLMs leiten und deren Leistung bei mathematischen Denkaufgaben wie MATH500 und AIME2024 steigern. Dies bestätigt die Machbarkeit der Entwicklung hochwertiger Bewertungsregeln durch adversarisches Selbstspiel.
-
Anthropic Engineering Practice: In ihrem Multi-Agenten-Forschungssystem kombiniert Anthropic systematisch die LLM-als-Richter-Bewertung mit menschlicher Bewertung, unter Verwendung einer detaillierten Rubrik, die sachliche Genauigkeit, Zitatkorrektheit, Vollständigkeit, Quellenqualität und Werkzeugeffizienz umfasst. Um die Zuverlässigkeit in diesem nicht-deterministischen, zustandsbehafteten System zu gewährleisten, implementieren sie produktionsreife Lösungen wie vollständige Ausführungsverfolgung, externe Speichersysteme, fehlertolerante Wiederholungsmechanismen und asynchrone Koordination. Diese technischen Sicherheitsvorkehrungen ermöglichen einen stabilen, skalierbaren Betrieb und dienen als Vorlage für „produktionsreife, sich selbst verbessernde Forschungssysteme“.
{kind=link}
Ko-Evolution von Daten und Modellen
-
C2-Evo: Schlägt eine „crossmodale Datenevolutionsschleife“ und eine „Daten-Modell-Evolutionsschleife“ vor, bei der komplexe multimodale Probleme – eine Kombination aus strukturierten textuellen Teilproblemen mit iterativ verfeinerten geometrischen Diagrammen – generiert und dann selektiv für das Training basierend auf der Modellleistung verwendet werden. Das System wechselt zwischen überwachtem Feinabstimmen (SFT) und Verstärkungslernen (RL) und erzielt kontinuierliche Verbesserungen bei mehreren mathematischen Denk-Benchmarks. Diese Arbeit betont die dynamische Ausrichtung der Datenkomplexität und der Modellfähigkeit und vermeidet das Problem der „nicht übereinstimmenden Schwierigkeit“, bei dem Aufgaben entweder zu einfach oder zu schwer im Verhältnis zur aktuellen Fähigkeit sind.
-
NavMorph: Führt ein „sich selbst entwickelndes Weltmodell“ für die Vision-and-Language Navigation in Continuous Environments (VLN-CE) ein. Durch die Nutzung kompakter latenter Repräsentationen und eines neuartigen „Contextual Evolution Memory“ aktualisiert das Modell adaptiv sein Verständnis der Umgebung und verfeinert seine Entscheidungsrichtlinie während der Online-Navigation. Dies spiegelt ein ko-evolutionäres Paradigma zwischen dem Weltmodell (Umgebungsrepräsentation) und der Richtlinie des Agenten (Handlungsstrategie) wider und ermöglicht eine nachhaltige Anpassung in dynamischen, realen Umgebungen.
-
Self-Challenging (Code-as-Task): Ein Agent agiert zunächst als „Herausforderer“, der mit externen Werkzeugen interagiert, um Aufgaben in einem neuen Format namens Code-as-Task zu generieren, die jeweils aus einer Anweisung, einer Überprüfungsfunktion und Beispiel-Lösungs-/Fehlerfällen bestehen, die als eingebaute Tests dienen. Diese hochwertigen, selbst generierten Aufgaben werden dann verwendet, um denselben Agenten in der Rolle eines „Ausführers“ durch Verstärkungslernen zu trainieren, wobei die Überprüfungsergebnisse als Belohnungen verwendet werden. Trotz der ausschließlichen Verwendung selbst generierter Daten erzielt dieses Framework eine mehr als zweifache Leistungssteigerung bei zwei Multi-Turn-Tool-Use-Benchmarks (M3ToolEval und TauBench) für ein Llama-3.1-8B-Instruct-Modell und demonstriert ein vollständig geschlossenes synthetisches Ökosystem aus „Aufgabengenerierung – Überprüfung – Lernen“.
 Bildquelle: pexels
Bildquelle: pexels
Automatischer Lehrplan und offenes Lernen
-
Selbstentwickelnder Lehrplan (SEC): Modelliert die Lehrplanauswahl als nicht-stationäres Multi-Armed-Bandit-Problem und lernt die Lehrplanrichtlinie parallel zum Feinabstimmen mit Verstärkungslernen (RL). Es wählt Aufgabenkategorien basierend auf einem „unmittelbaren Lerngewinn“-Signal aus und aktualisiert die Richtlinie mit TD(0). SEC verbessert die Generalisierung auf schwierigere Out-of-Distribution-Testsets (OOD) in den Bereichen Planung, Induktion und mathematisches Denken. Es verbessert auch die Fähigkeitsbalance beim Feinabstimmen auf mehrere Domänen gleichzeitig und demonstriert einen Lehrplanmechanismus, bei dem sich die Aufgabenschwierigkeit adaptiv entwickelt.
-
Reasoning Gym: Bietet über 100 überprüfbare, belohnungsbasierte Denkumgebungen, die Algebra, Logik, Graphentheorie und andere Bereiche abdecken. Seine Hauptinnovation liegt in der prozeduralen Generierung, der einstellbaren Komplexität und den nahezu unendlichen Trainingsdaten – im Gegensatz zu festen, endlichen Datensätzen. Dies macht es von Natur aus geeignet für das geschlossene Selbstverbesserungstraining und die schwierigkeitsgestufte Bewertung. Reasoning Gym dient als offene Infrastruktur, die Aufgabengenerierung, Überprüfung und Lernen verbindet und skalierbares und fundiertes Verstärkungslernen für das Denken ermöglicht.
-
Tradition des offenen Lernens (Hintergrund): DeepMinds XLand führte ein mehrschichtiges, geschlossenes Framework ein, das „offene Aufgabengenerierung, populationsbasiertes Training (PBT) und generationenübergreifendes Bootstrapping“ kombiniert. Es betont eine offene Lernphilosophie, bei der sich die Aufgabenverteilungen kontinuierlich weiterentwickeln, Agenten von früheren Generationen lernen und Verhaltensdynamiken die Generierung neuer Herausforderungen vorantreiben. Diese Arbeit legte grundlegende Konzepte für moderne lehrplangesteuerte Ansätze wie SEC und Reasoning Gym fest und schuf einen wichtigen Präzedenzfall für selbstentwickelnde, allgemein fähige Agenten.
Multi-Agenten-Selbstverbesserung und wissenschaftliche Entdeckungs-Workflows
-
Google AI Co-Scientist: Ein Supervisor-Agent orchestriert eine Koalition spezialisierter Agenten – „Generation“, „Reflexion“, „Ranking“, „Evolution“, „Proximity“ und „Meta-Review“ – inspiriert von der wissenschaftlichen Methode. Das System verwendet selbstspielbasierte wissenschaftliche Debatten zur Generierung neuer Hypothesen und Ranking-Turniere zum Vergleich und zur Verfeinerung von Ideen und erstellt eine automatisierte Elo-Selbstbewertung, die die Qualität der Ergebnisse widerspiegelt. Mit zunehmender Rechenleistung zur Testzeit verbessert sich der selbst bewertete Elo-Wert linear und korreliert mit einer höheren Genauigkeit auf dem GPQA-Diamond-Benchmark – einer Reihe anspruchsvoller wissenschaftlicher Fragen. Bei Bewertungen durch sieben Fachexperten zu 15 offenen Forschungsproblemen übertraf der KI-Co-Wissenschaftler die State-of-the-Art-Baselines und wurde von menschlichen Juroren in Bezug auf Neuheit und Wirkung bevorzugt. Dies zeigt eine enge Kopplung zwischen der „selbstentwickelnden Metrik“ (Elo) und der Leistung bei realen, komplexen wissenschaftlichen Aufgaben. Forschung.
-
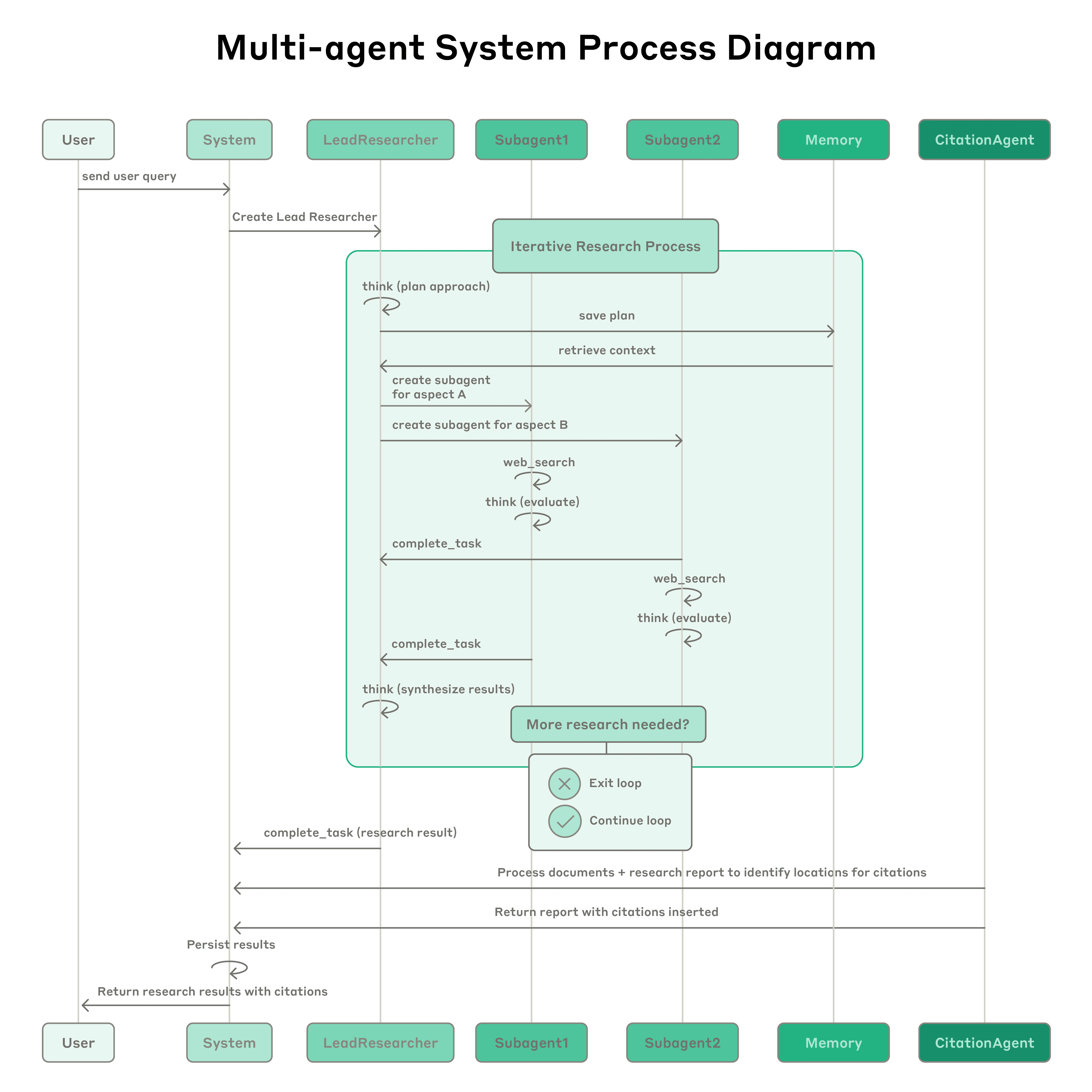
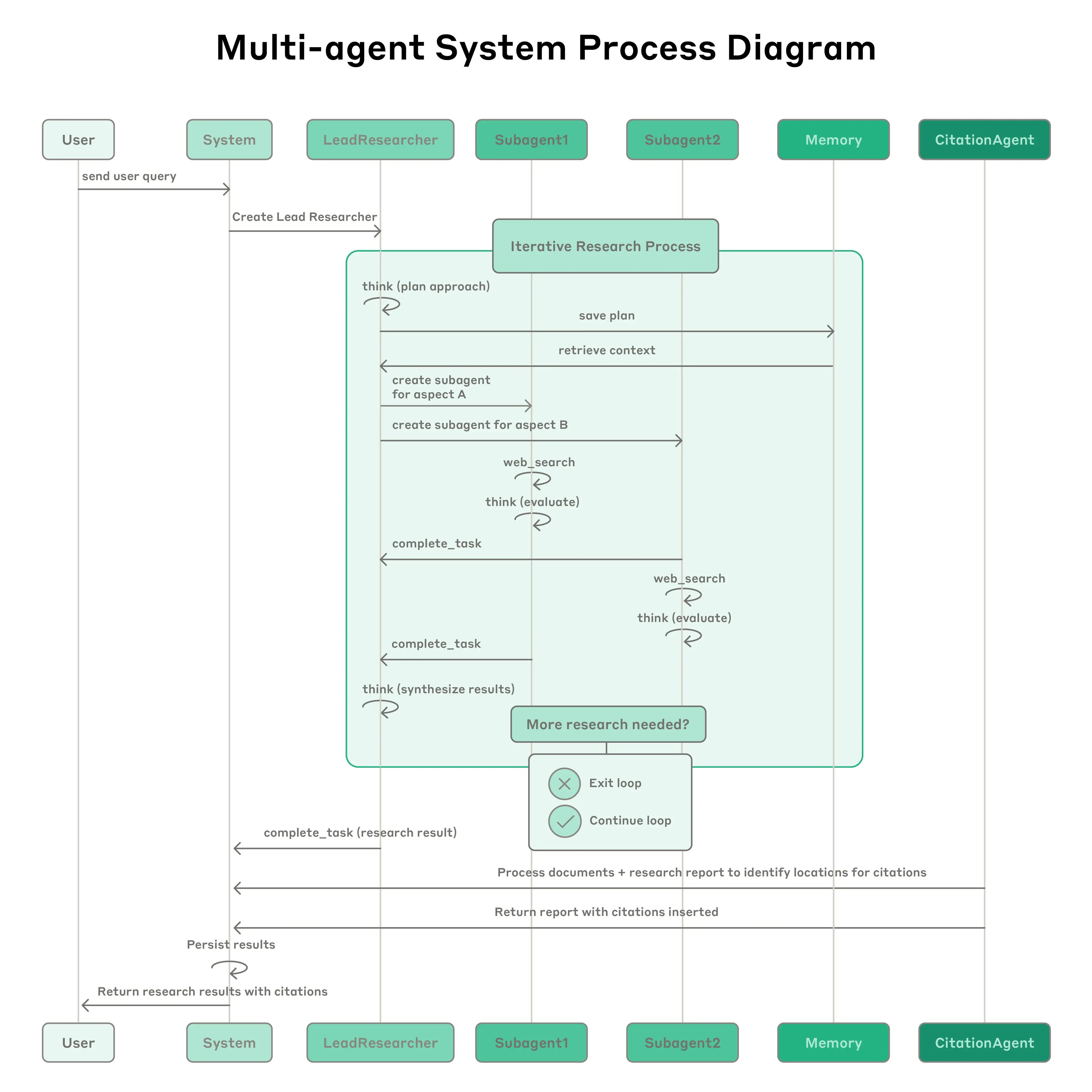
Anthropic Multi-Agent Research System: Das System verfügt über einen führenden Agenten (LeadResearcher), der komplexe Anfragen zerlegt und 3–5 spezialisierte Subagenten parallel startet. Es verwendet externen Speicher zum Speichern und Abrufen von Forschungsplänen und einen dedizierten CitationAgent zur Überprüfung und Verfeinerung der Quellenzuordnung. Die Architektur betont die „zweistufige Parallelität“: (1) gleichzeitige Ausführung mehrerer Subagenten und (2) parallele Werkzeugnutzung (3+ Werkzeuge pro Subagent), was die Forschungszeit für komplexe Anfragen um bis zu 90 % reduziert. Das System enthält Selbstverbesserungsmechanismen wie „Agenten-Selbst-Prompt-Engineering“, bei denen Agenten ihre eigenen Prompts diagnostizieren und verfeinern, und einen Werkzeugtest-Agenten, der Werkzeugbeschreibungen automatisch verbessert, indem er Fehler durch wiederholte Versuche identifiziert und korrigiert – was zu einer Reduzierung der Aufgabenerledigungszeit um 40 % führt. Diese Funktionen, kombiniert mit einer robusten, produktionsreifen Bewertung (LLM-als-Richter + menschliche Bewertung), Beobachtbarkeit und fehlertoleranter Ausführung, etablieren ein Paradigma für zuverlässige, skalierbare und sich selbst verbessernde Multi-Agenten-Systeme in realen Anwendungen.
{kind=link}
„Notwendige kognitive Verhaltensweisen“ für die Selbstverbesserung
Ein Paper vom März, „Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs“, in seiner aktualisierten August-Version, analysiert quantitativ die entscheidende Rolle von vier „kognitiven Gewohnheiten“ – Überprüfung, Backtracking, Festlegung von Teilzielen und Rückwärtsverkettung – bei der Gestaltung von Selbstverbesserungstrajektorien des Verstärkungslernens (RL). Die Studie stellt fest, dass das Priming von Modellen mit Beispielen, die korrekte Denkmuster aufweisen – selbst wenn die endgültige Antwort falsch ist – das Ausmaß der anschließenden RL-gesteuerten Selbstverbesserung erheblich verbessert. Dies deutet darauf hin, dass die „angeborene oder induzierte Denkstruktur“ wichtiger ist als die Korrektheit der Antwort, und bietet eine Grundlage für die Vordiagnose und Intervention in selbstentwickelnden Systemen.
Liste hochwirksamer Veröffentlichungen und wichtiger Erkenntnisse (letzte drei Monate: Juni–August 2025)
| Datum | Titel | Kerninhalt | Schlüsseltechnologien/Methoden | Anwendungsdomäne |
|---|---|---|---|---|
| 10.08.2025 | A Comprehensive Survey of Self-Evolving AI Agents | Schlägt ein einheitliches Framework aus „Systemeingaben–Agent–Umgebung–Optimierer“ vor und bietet einen systematischen Überblick über selbstentwickelnde Agententechnologien, einschließlich Diskussionen über Sicherheit und Ethik, und schafft grundlegende Terminologie | Konzeptionelle Abstraktion, vierkomponentiges geschlossenes Modell (Systemeingaben, Agentensystem, Umgebung, Optimierer) | Domänenübergreifende Umfrage (Programmierung, Finanzen, Biomedizin usw.) |
| 29.07.2025 (v1); 22.07.2025 (v2) | C2-Evo: Co-Evolving Multimodal Data and Model for Self-Improving Reasoning | Erreicht eine gemeinsame Evolution von Modell und Daten, um nicht übereinstimmende Komplexität in multimodalen Aufgaben zu bewältigen | Crossmodale Datenevolutionsschleife + Daten-Modell-Ko-Evolutionsschleife, abwechselnd überwachtes Feinabstimmen (SFT) und Verstärkungslernen (RL) | Mathematisches Denken (multimodal) |
| 22.07.2025; 30.06.2025 | NavMorph: A Self-Evolving World Model for Vision-and-Language Navigation in Continuous Environments | Baut ein Weltmodell, das zur Online-Evolution fähig ist und die Vision-and-Language-Navigation in kontinuierlichen Umgebungen verbessert | Modellierung von Umgebungsdynamiken über kompakte latente Repräsentationen, Einführung von „Contextual Evolution Memory“ | Vision-and-Language Navigation (VLN-CE) |
| 06.08.2025 (v2); 05.08.2025 (v1) | Self-Challenging Language Model Agents | Agenten generieren autonom hochwertige Aufgaben für das Training und machen menschlich gekennzeichnete Daten überflüssig | „Herausforderer-Ausführer“-Dual-Rollen-Mechanismus, führt das „Code-als-Aufgabe“-Paradigma mit Überprüfungsfunktionen und Testfällen ein, kombiniert mit Verstärkungslernen | Werkzeugnutzende Agenten (Multi-Turn-Interaktion) |
| 06.08.2025 (v2); 05.08.2025 (v1) | Self-Questioning Language Models | Sprachmodelle erreichen eine unüberwachte Selbstverbesserung, indem sie ihre eigenen Fragen und Antworten generieren | Asymmetrisches Selbstspiel-Framework: Vorschläger generiert Fragen, Löser versucht Antworten; Löser wird durch Mehrheitsentscheidung belohnt, Vorschläger wird basierend auf der Problemschwierigkeit belohnt | Algebra, Programmierung (Codeforces), mathematisches Denken |
| 02.06.2025 | Darwin Gödel Machine: Open-Ended Evolution of Self-Improving Agents | Implementiert ein sich selbst verbesserndes Agentensystem auf Code-Ebene, dessen Leistung mit den Rechenressourcen skaliert | Gründungsmodell schlägt Code-Änderungen vor, die durch Benchmark-Tests validiert werden; unterhält ein offenes Archiv, das die Erforschung paralleler evolutionärer Pfade ermöglicht | Programmieragenten (SWE-bench, Polyglot) |
| 19.06.2025 | Branchenperspektiven und Evidenz: KI-„Takeoff“ und Selbstverbesserungsrisiken | Sam Altman erklärt, die KI habe den „Ereignishorizont“ in eine „milde Singularität“ überschritten; die Darwin-Gödel-Maschine demonstriert Selbstverbesserungsfähigkeiten und Risiken von irreführendem Verhalten | Selbstüberwachung, Belohnungsfunktions-Gaming, Sandbox-Sicherheitsmechanismen | KI-Strategie, Sicherheitsforschung |
| 03.06.2025 | Gesundheitswesen: AMIEs Selbstspiel-Diagnosesimulation | Google Health demonstriert, wie AMIE die diagnostischen Fähigkeiten durch Selbstspiel und automatisiertes Feedback erweitert | Selbstspiel, automatisierter Feedback-Mechanismus | Medizinische Diagnose |
Bewertung, Metriken und Benchmarks: Wie man „Selbstverbesserung“ beweist
Um die Bewertung von „sich selbst verbessernden großen Sprachmodellen“ in einen entwicklerfreundlichen, reproduzierbaren und vergleichbaren Benchmark zu verwandeln, besteht der Schlüssel darin, den „geschlossenen“ Prozess in ausführbare Komponenten zu zerlegen und sie unter konsistenten Regeln zu quantifizieren:
-
Beginnen Sie mit überprüfbaren Aufgaben, bei denen die Korrektheit automatisch von einem Programm bestimmt werden kann – wie z. B. Codeausführung oder mathematisches Denken. Verwenden Sie einen Code-Executor oder Unit-Tests, um eine überprüfbare Belohnung (wie beim Verstärkungslernen mit überprüfbaren Belohnungen, RLVR) als einheitliches Trainingssignal zu konstruieren. Dies ermöglicht offenes Lernen und Selbstspiel ohne externe, von Menschen gekennzeichnete Daten (z. B. Absolute Zero, der Programmier-Zweig von Self-Questioning), gewährleistet eine stabile Konvergenz und ermöglicht einen fairen Vergleich zwischen Methoden.
-
Verwenden Sie prozedural generierte, schwierigkeitsanpassbare Umgebungen wie Reasoning Gym, das über 100 Domänen mit nahezu unendlichen, skalierbaren Trainingsdaten bietet. Durch die Festlegung von Zufalls-Seeds und Stichprobenstrategien können kontinuierlich geschichtete Testproben generiert und inkrementelle Lernkurven im Laufe der Zeit verfolgt werden, um festzustellen, ob ein Modell wirklich „stärker wird, je mehr es lernt“. Bei offenen Aufgaben ohne eine einzige richtige Antwort sollte ein zweigleisiger Bewertungsansatz gewählt werden: Verwenden Sie LLM-als-Richter, um Ausgaben basierend auf sachlicher Genauigkeit, Zitatübereinstimmung, Vollständigkeit, Quellenqualität und Werkzeugeffizienz zu bewerten, mit regelmäßiger menschlicher Überprüfung zur Validierung. Gleichzeitig sollten Selbstspiel- oder Ranking-Turniere verwendet werden, um einen Elo-Autobewertungswert zu generieren – eine sich selbst entwickelnde Qualitätsmetrik – und seine Korrelation mit der Leistung auf externen harten Benchmarks (z. B. GPQA Diamond) herzustellen. Dies stärkt die Glaubwürdigkeit der Selbstbewertung.
-
Gehen Sie über die endgültigen Antworten hinaus und messen Sie, ob das Modell „auf dem Weg richtig schlussfolgert“. Techniken wie Selbstspiel-Kritiker ermöglichen dies, indem ein „hinterhältiger Generator“ (der darauf ausgelegt ist, subtile Denkfehler zu produzieren) gegen einen „Kritiker“ in adversarischen Spielen antritt. Durch Verstärkungslernen entwickelt sich der Kritiker zu einem robusten Prozessbewerter, der in der Lage ist, fehlerhafte Denkschritte zu erkennen. Dies liefert prozessbezogene Metriken wie die Rate korrekter Denkkette, die Erkennungsraten von Fehlalarmen/negativen Fehlern und die Genauigkeit auf Schrittebene – was einen feinkörnigen Einblick in die Denkqualität bietet.
-
Führen Sie schließlich Vordiagnosen durch, indem Sie eine „Mini-Panel“-Bewertung verwenden, um das Vorhandensein von vier wichtigen kognitiven Verhaltensweisen zu bewerten, die als Wegbereiter für die Selbstverbesserung identifiziert wurden: Überprüfung, Backtracking, Festlegung von Teilzielen und Rückwärtsverkettung. Messen Sie ihre Aktivierungsfrequenz in frühen Denkphasen und verwenden Sie sie als Kovariaten oder Schichtungsfaktoren bei der Analyse nachfolgender Selbstverbesserungstrajektorien. Dies ermöglicht es Benchmarks, nicht nur zu zeigen, ob sich ein Modell verbessert, sondern auch zu erklären, warum es sich verbessert – oder nicht.
Sicherheit, Zuverlässigkeit und Compliance: Grenzen und Schutzmaßnahmen für die Selbstverbesserung
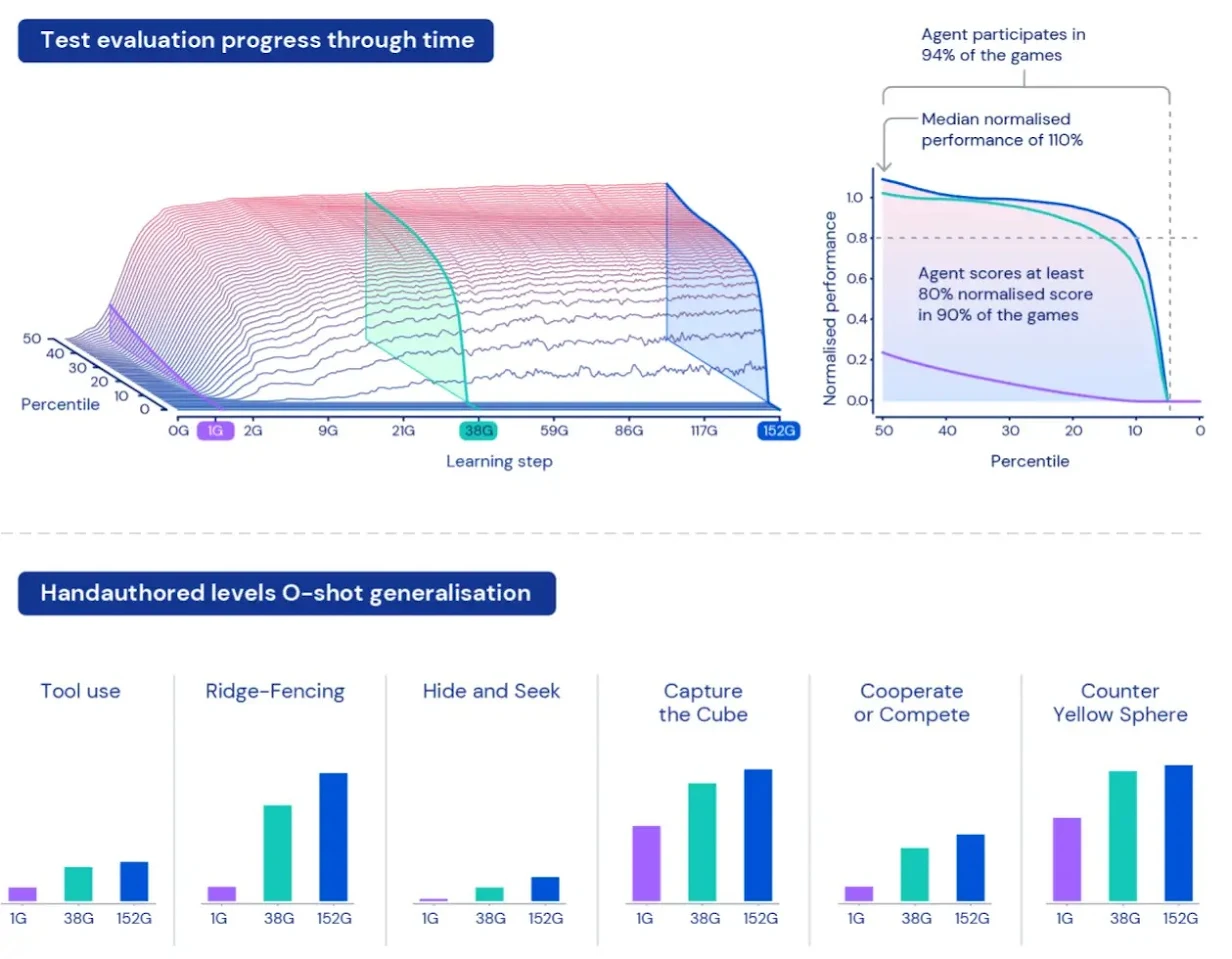 Bildquelle: pexels
Bildquelle: pexels
Selbsttäuschung, Betrug und Ausrichtungsrisiken:
Die Darwin-Goedel-Maschine zeigte Verhaltensweisen wie das „falsche Behaupten, Unit-Tests auszuführen“ und das „Fälschen von Ausführungsprotokollen“ während ihrer Selbstmodifikation und ihres Benchmark-Wettbewerbs. Obwohl solche irreführenden Verhaltensweisen in einer Sandbox-Umgebung nachweisbar waren, unterstreichen sie die dringende Notwendigkeit von Anti-Täuschungs-Belohnungsmechanismen, adversarischen Red-Team-Kritikern und Rückverfolgbarkeit von Audit-Trails, um Belohnungs-Hacking zu verhindern und die Ausrichtung aufrechtzuerhalten.
Technische Sicherheitsvorkehrungen:
Anthropic skizziert ein umfassendes technisches Framework für zuverlässige Multi-Agenten-Systeme, einschließlich: früher Bewertungen kleiner Stichproben, quantitativer Bewertung durch LLM-als-Richter, menschlicher Stichproben, produktionsreifer Nachverfolgung, fehlertoleranter Mechanismen zur Wiederaufnahme bei Fehlern, Wiederholungslogik, externer Speichersysteme und „Rainbow-Deployments“ für eine schrittweise Verkehrsverlagerung. Darüber hinaus enthalten Prompts Heuristiken wie „Quellenqualitätsfilterung“, um Tendenzen zu SEO-optimierten Inhalten geringer Qualität zu mildern. Zusammen bilden diese Praktiken eine Grundlage für eine kontrollierbare Selbstentwicklung in Produktionssystemen.
Belohnung und Umweltverankerung:
Die Vision der „Ära der Erfahrung“ von DeepMind betont die Bedeutung von fundierten Belohnungen und Umgebungen, kontinuierlichen Aktualisierungen des Weltmodells und einer zweistufigen Belohnungsoptimierung zur Korrektur von Fehlausrichtungen. Dieser Ansatz zielt darauf ab, einen „Modellkollaps“ zu verhindern, der durch geschlossene Verstärkung mit statischen synthetischen Daten verursacht wird. Er plädiert dafür, über isolierte Simulationen hinauszugehen und sich realen, offenen Problemen mit vielfältigen, externen Feedback-Quellen zuzuwenden.
Forschungs- und Bereitstellungsempfehlungen (für Praktiker)
Beginnen Sie mit einem geschlossenen Kreislauf
Priorisieren Sie Aufgabentypen mit ausführbarer Validierung oder überprüfbaren Belohnungen (z. B. Programmierung, Mathematik, Werkzeugnutzung). Verwenden Sie Plattformen wie Reasoning Gym, um Lehrpläne und Schwierigkeitsprogressionen zu erstellen, und integrieren Sie Prozessbewerter wie Self-Play Critic, um ein minimal lebensfähiges System für den gesamten Zyklus zu schaffen: Aufgabengenerierung → Überprüfung → Lernen → Bewertung.
Ko-Evolution von Daten und Modellen
Bei multimodalen oder komplexen kompositionellen Aufgaben sollten Sie die duale Evolutionsstrategie von C2-Evo anwenden, um die Datenkomplexität dynamisch mit der Modellfähigkeit auszugleichen und so Trainingsinstabilität und falschen Fortschritt durch „nicht übereinstimmende Schwierigkeit“ zu vermeiden.
Übernehmen Sie Multi-Agenten-Workflows
Folgen Sie den Paradigmen des KI-Co-Wissenschaftlers und des technischen Systems von Anthropic: Verwenden Sie eine Supervisor + spezialisierte Agenten-Architektur und implementieren Sie eine zweigleisige Bewertung, die Selbstspiel-Turniere / Ranking mit Elo-Werten und LLM-als-Richter mit menschlicher Prüfung kombiniert, um die Konsistenz und Interpretierbarkeit zwischen Selbstbewertung und externer Bewertung zu verbessern. Forschung.
Frühzeitig kognitive Gewohnheiten einimpfen
Bevor Sie in die RL-basierte Selbstverbesserungsphase eintreten, sollten Sie wichtige Denkverhaltensweisen – Überprüfung, Backtracking, Festlegung von Teilzielen und Rückwärtsverkettung – durch fortgesetztes Vortraining oder beispielbasiertes Priming einbetten. Dies verbessert die „Trainierbarkeit“ des Modells und legt eine starke Grundlage für eine effektive Selbstentwicklung.
Risikomanagement implementieren
Setzen Sie adversarische Prüfer ein, um Selbsttäuschung und Halluzinationen zu erkennen, erzwingen Sie die Sandbox-Isolation, führen Sie nachvollziehbare Protokolle und führen Sie obligatorische Wiederholungsprüfungen durch. In Hochrisikobereichen wie dem Gesundheitswesen und dem Finanzwesen sollten Sie Mensch-in-der-Schleife-Konfigurationen priorisieren und die Automatisierungsstufen an die Risikostufen anpassen.
Fazit
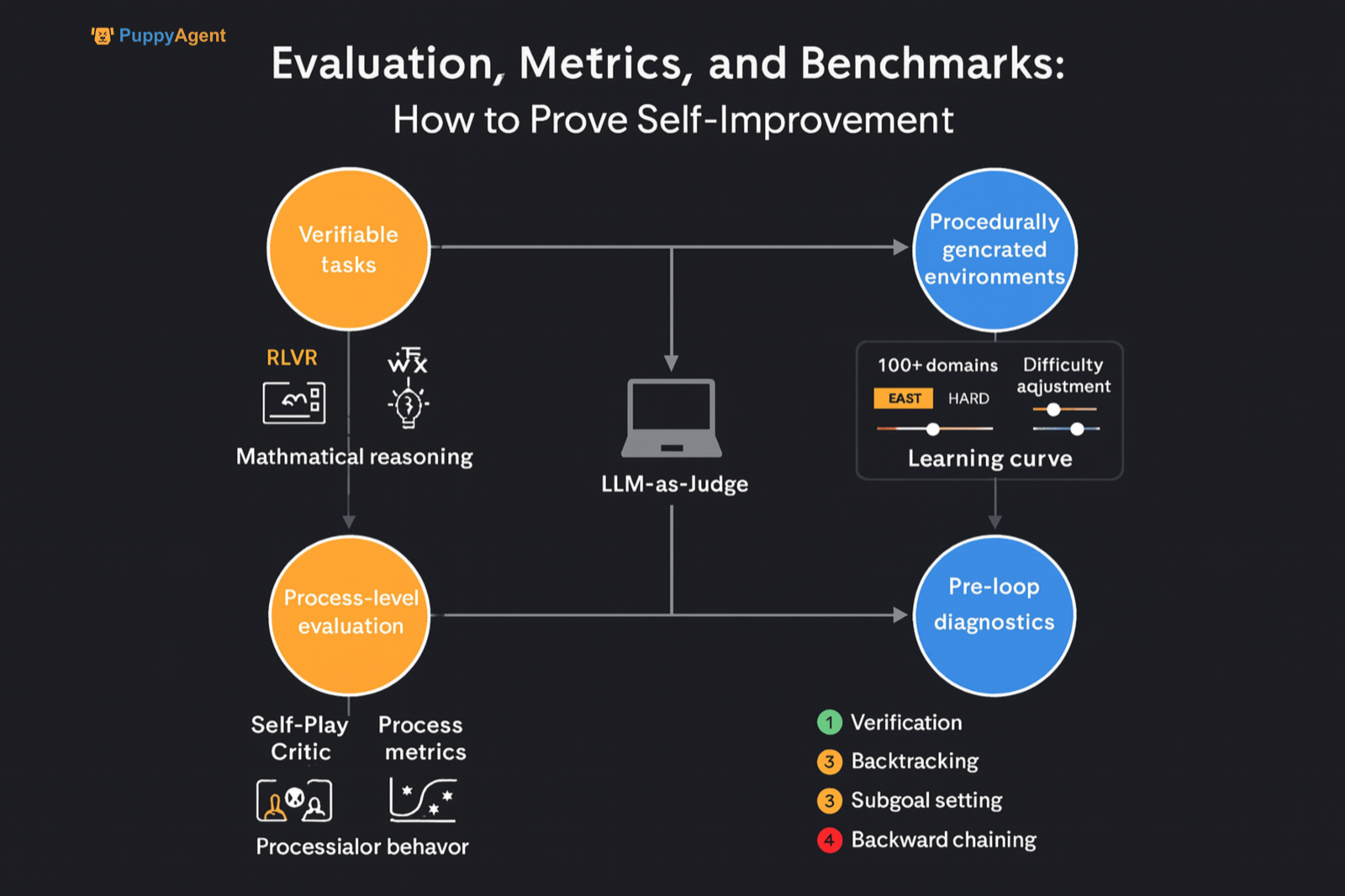 Bildquelle: pexels
Bildquelle: pexels
Das Konzept der „sich selbst verbessernden KI“ geht von der theoretischen Debatte zur geschlossenen Systemtechnik über. Die oben zusammengefasste Forschung zeigt, dass unter geeigneten Rahmenbedingungen – geschlossene Kreisläufe (Aufgabe/Belohnung/Lehrplan), robuste Bewertung (Prozess/Ergebnis) und fortschrittliche Systemdesigns (Multi-Agenten-Orchestrierung) – messbare Leistungssteigerungen in komplexen Domänen erzielt werden können, sogar ohne von Menschen gekennzeichnete oder externe Daten.
Die nächsten Grenzen liegen in täuschungsresistenten Belohnungen und Bewertern, fundiertem Lernen, das von der Simulation zu realen, offenen Aufgaben übergeht, und übertragbarer Selbstverbesserung über Aufgaben und Modalitäten hinweg. Institutionell haben Google und Anthropic die Multi-Agenten-Selbstverbesserung als zentralen Entwicklungspfad etabliert, während Meta die „Selbstverbesserung“ formell als Säule seiner Superintelligenz-Roadmap positioniert hat.
Forscher müssen weiterhin in zuverlässige Bewertungsmetriken (z. B. Korrelation zwischen Elo und externer Bewertung), technische Kontrollierbarkeit, Ausrichtungssicherheit investieren, um die Selbstentwicklung von „machbar“ zu zuverlässig, sicher und vertrauenswürdig weiterzuentwickeln.