KI-Agenten-Kontextverwaltung — Leitfaden zu Session & Memory
11. Februar 2026Ollie @puppyone
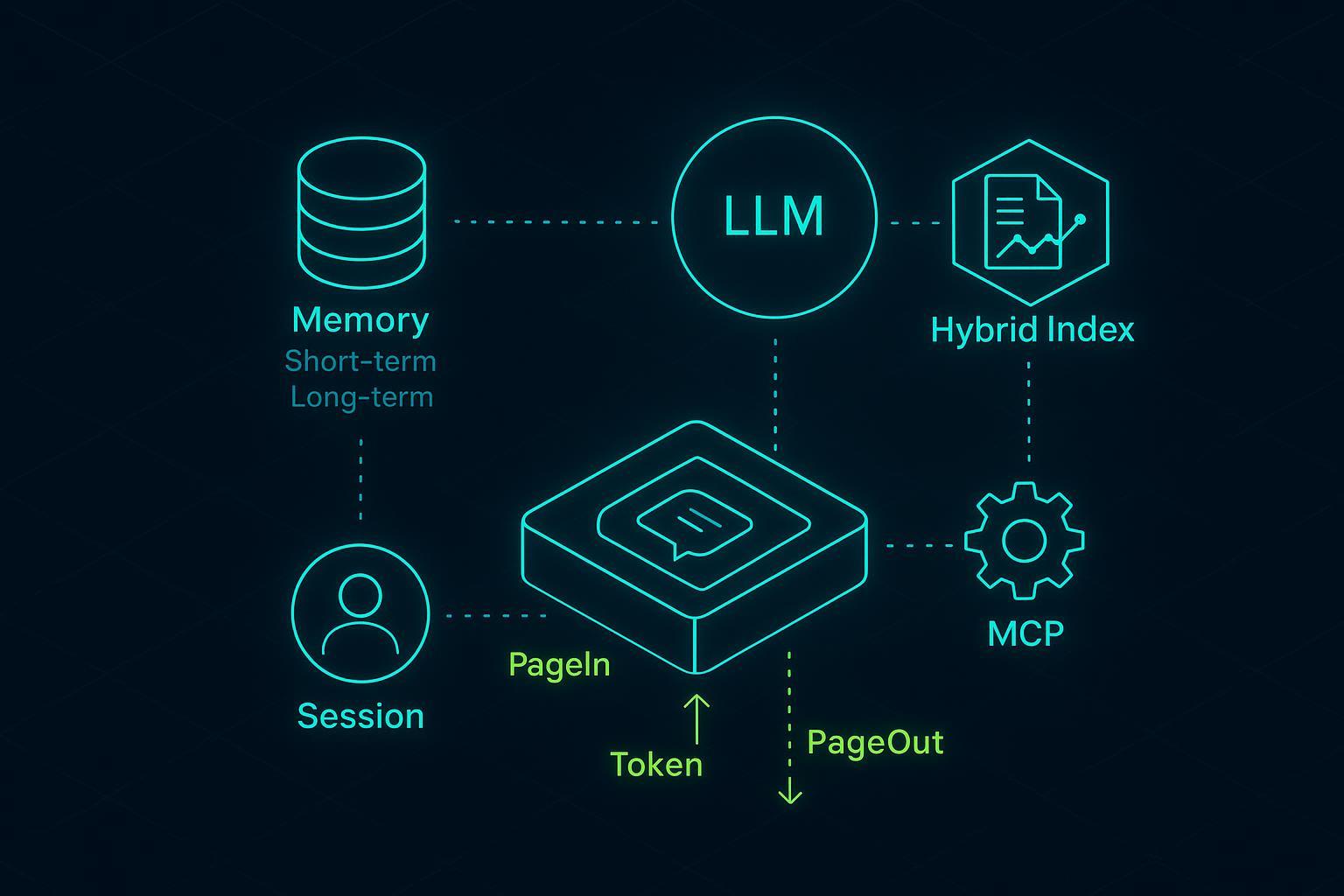
Wichtigste Erkenntnisse
- Session, Memory und Kontext als getrennte Belange behandeln; Kontext pro Turn deterministisch zusammenstellen.
- Windowing mit explizitem PageIn/PageOut: bewerten, was einbezogen wird; kürzen oder zusammenfassen, was ausgeschlossen wird.
- Extraktive und abstraktive Kompression mit Meilenstein-Notizen kombinieren, um Summary-Drift zu minimieren.
- Hybrid Retriever aufbauen: Filter → lexikalisch (BM25) → Vektoren → Fusion/Rerank; Vektoren für exakte IDs umgehen.
- Tools per programmatischer Orchestrierung (MCP) aus dem Prompt halten, mit Idempotenz und Audit-Trails.
- Für Kundensupport: User-Präferenzen und episodische Summaries persistieren; nur Relevantes pro Turn injizieren.
- Local-First-Deployments für sensible Daten bevorzugen; verschlüsseln, auditieren und RBAC durchsetzen.
Was Session, Memory und Kontext in der Produktion bedeuten
- Session: Der begrenzte Interaktionsfaden (ein Gesprächsfenster) mit Lebenszykluszuständen wie opened, active, compacted, archived. Sessions besitzen Kurzzeithistorie und Zähler (Turns, Tokens).
- Memory: Dauerhaftes Wissen, das Sessions überlebt. Zwei Varianten: Kurzzeit (aktuelle Turns wörtlich oder zusammengefasst) und Langzeit (Fakten, Präferenzen, episodische Summaries an User/Entitäten).
- Kontext: Das turn-spezifische Bundle, das das Modell tatsächlich sieht—Systemanweisungen, letzte Nachrichten, ausgewählte Memories, abgerufene Snippets, Tool-Ergebnisse. Bei KI-Agenten-Kontextverwaltung speichern Sie alles, injizieren aber nur einen Bruchteil pro Turn. Diese Auswahl ist, wo Engineering sich auszahlt.
Session-Lebenszyklus und Windowing-Modell
Eine einfache relationale Struktur funktioniert gut:
-- Core session objects
CREATE TABLE sessions (
session_id TEXT PRIMARY KEY,
user_id TEXT NOT NULL,
status TEXT CHECK (status IN ('opened','active','compacted','archived')),
created_at TIMESTAMP NOT NULL,
last_turn_at TIMESTAMP,
turn_count INT DEFAULT 0,
token_in INT DEFAULT 0,
token_out INT DEFAULT 0
);
CREATE TABLE messages (
msg_id TEXT PRIMARY KEY,
session_id TEXT NOT NULL,
role TEXT CHECK (role IN ('user','assistant','system','tool')),
content TEXT NOT NULL,
tokens INT,
created_at TIMESTAMP NOT NULL,
FOREIGN KEY (session_id) REFERENCES sessions(session_id)
);
CREATE INDEX idx_messages_session_time ON messages(session_id, created_at);
Kurzzeithistorie kann als Ringpuffer der letzten N Tokens/Turns modelliert werden. Über Schwellenwerte hinaus ältere Spannen in Summaries und Meilenstein-Notizen komprimieren.
class Window:
def __init__(self, max_tokens: int, keep_last_turns: int = 6):
self.max_tokens = max_tokens
self.keep_last_turns = keep_last_turns
def assemble(self, sys_msg, recent_msgs, milestone_notes, retrieved_snippets, tool_outputs):
context = [sys_msg]
context += recent_msgs[-self.keep_last_turns:]
context += milestone_notes
context += retrieved_snippets
context += tool_outputs
return trim_to_token_budget(context, self.max_tokens)
Kompaktions-Trigger halten das Fenster stabil:
def maybe_compact(session, messages, thresholds):
too_many_turns = session.turn_count > thresholds.max_turns
too_many_tokens = (session.token_in + session.token_out) > thresholds.max_tokens
if not (too_many_turns or too_many_tokens):
return None
span = select_older_span(messages, keep_last=thresholds.keep_last_turns)
summary = summarize_extractive_then_abstractive(span)
milestone = extract_structured_facts(span)
persist_summary_and_milestone(session.id, summary, milestone)
mark_span_compacted(span)
Wichtige Design-Hinweise: Die letzten K Turns wörtlich halten (z.B. 4–8); Summaries werden synthetische „assistant“-Notizen mit Provenance; Meilenstein-Notizen strukturiert (YAML/JSON); Token-Accounting messen, nicht raten.
PageIn- und PageOut-Auswahl — Scoring und Eviction
PageIn als sortierte Include-Liste, PageOut als prinzipielles Vergessen in der KI-Agenten-Kontextverwaltung.
Scoring-Funktion (Beispiel):
def score(item, now):
# item: {type, text, embedding, timestamp, role, metadata}
w_recency = 0.35
w_semantic = 0.45
w_role = 0.10
w_signal = 0.10 # clicks, tool success, citations
recency = exp_decay(now - item.timestamp, half_life_minutes=45)
semantic = cosine(item.embedding, query_embedding())
role_boost = 1.0 if item.role in ("system","milestone") else 0.7
signal = min(1.0, item.metadata.get("utilization_rate", 0.0))
return w_recency*recency + w_semantic*semantic + w_role*role_boost + w_signal*signal
Auswahl und Eviction:
def page_in_out(candidates, budget_tokens):
ranked = sorted(candidates, key=lambda x: score(x, now()), reverse=True)
selected, used = [], 0
for c in ranked:
if used + c.tokens <= budget_tokens:
selected.append(c)
used += c.tokens
else:
continue
# PageOut policy: LRU for plain chat, semantic TTL for knowledge
evict = [x for x in candidates if x not in selected and should_evict(x)]
return selected, evict
def should_evict(item):
if item.type == 'verbatim_turn' and is_older_than(item, minutes=120):
return True
if item.type == 'snippet' and below_similarity(item, 0.25):
return True
return False
Operative Hinweise: Relevanz und Ähnlichkeit fusionieren; System-Prompts und Meilenstein-Notizen priorisieren; Eviction deterministisch halten; loggen, was verworfen wurde.
Kompression ohne Recall-Verlust
Sie brauchen sowohl harte als auch weiche Kompression:
- Extraktiv: wichtige Sätze, IDs, Zahlen behalten. Schnell, treu, kann paraphrasierte Nuancen verlieren.
- Abstraktiv: umformulieren und kondensieren. Erfasst den Kern, riskiert Randdetails; mehr Latenz.
- Token-Pruning: modellbasiert (z.B. LLMLingua-2); starke Ratios, aber Prompts werden knapp.
Eine hybride Pipeline funktioniert gut in der Praxis:
def summarize_extractive_then_abstractive(span):
key_sents = extract_top_k_sentences(span, k=8, with_numbers=True)
draft = llm_abstractive_summary(key_sents, style="bullet+yaml_facts")
return draft
Safeguards gegen Summary-Drift: Meilenstein-Notizen als strukturierte Fakten (YAML/JSON); N aktuelle Turns wörtlich; On-Demand-Details per Retrieval rehydrieren.
| Methode | Stärke | Risiko | Zusätzliche Latenz |
|---|---|---|---|
| Extraktiv | Treu, günstig | Fragmentierter Kontext | Niedrig |
| Abstraktiv | Kohärenter Kern | Seltene Fakten verpassen | Mittel |
| Token-Pruning | Große Einsparung | Kryptische Prompts | Mittel–Hoch |
Referenzen: Prompt Compression Survey (2024), LLM-DCP (2025).
KI-Agenten-Kontextverwaltung mit Hybrid-Indexierung und deterministischem Retrieval
Vektor-only Retrieval ist gut für Paraphrasen, aber brüchig für IDs und Policies. Hybrid-Pipelines kombinieren Filter, sparse lexikalische Signale und dense Vektoren; Top-K fusionieren und optional reranken.
Retrieval-Plan: Filter zuerst (Tenant, Produkt, Locale, Version); lexikalischer Pass (BM25/BM25F); Dense-Pass; Fusion (RRF); optional Cross-Encoder-Reranker.
def hybrid_retrieve(query, k=20, filters=None):
cand_a = bm25_search(query, filters=filters, k=3*k)
cand_b = vector_search(embedding(query), filters=filters, k=3*k)
fused = reciprocal_rank_fusion(cand_a, cand_b, top=k)
return fused
Wann Vektoren umgehen: deterministische Lookups (Ticket-IDs, SKUs, Policy-Codes) → exakter Abgleich in strukturierten Stores. Referenzen: Elastic hybrid search, Weaviate hybrid search, Pinecone RAG guide.
MCP-Tool-Orchestrierungsmuster für schlanken Kontext
Tools programmatisch aufrufen statt Specs und Transkripte in den Prompt stopfen. MCP formalisiert sichere, bidirektionale Verbindungen zu Tools und Daten. Prinzipien: Idempotenz, atomare Ausführung, Observability, Timeouts und Backoff.
@retry(idempotent=True, backoff=expo)
def update_ticket(tool, ticket_id, payload):
with atomic():
ok = tool.call("update_ticket", {"id": ticket_id, "payload": payload})
log_tool_io(tool="ticketing", op="update", id=ticket_id, ok=ok)
return ok
Referenzen: Anthropic — Model Context Protocol (2024), Advanced tool use (2025).
Referenz-Build — Kundensupport-Agent mit Langzeitgedächtnis
Ziel: Agent, der User-Präferenzen und frühere Lösungen über Sessions hinweg merkt, richtigen Policy/Ticket-Kontext abruft und Updates sicher ausführt.
Minimales Schema (users, memories, tool_logs), Memory-Capture, Per-Turn-Retrieval (assemble_turn_context, page_in_out), Tool-Aktionen mit MCP, Turn-Loop (handle_turn): Pseudocode wie im Englischen. Neutrale Produktoption: puppyone für strukturiertes Know-How und Hybrid-Indexe, Local-First via Docker.
Privacy und Local-First-Deployment
Local-First: Agent-Kernel und Stores in Ihrer VPC; signierte Images. Verschlüsselung at rest; strenge RBAC; Audit-Logging. Referenzen: NIST SP 800-171 Rev.3.
Evaluieren, was zählt
Metriken: Retrieval-Qualität (Precision@K, Recall@K, nDCG@K, MRR), Antwortqualität, System (Token-in/out, Latenz). Pilotplan: Token in (p50) 11k→6k, Latenz (p50) 3.2s→2.1s, nDCG@10 0.62→0.74, Task-Erfolg 72%→83%. A/B-Tests für Kompression, K in Hybrid-Retrieval, keep_last_turns.
Schlussgedanken und nächste Schritte
Fenster klein, Regeln explizit, Logs ehrlich halten. Mit deterministischen Trims beginnen, Hybrid-Retrieval hinzufügen, Kompression nur wo es sich lohnt. Recall als Produktfeature behandeln. Optionen wie puppyone evaluieren.