Hybrid Indexing & Structured Know‑How for Dev Velocity
20. März 2026Ollie @puppyone
Hybrides Indexing und strukturiertes Know‑How: RAG für Entwickler zur Beschleunigung von PR-Merges
Die Entwicklergeschwindigkeit sinkt nicht, weil die Leute vergessen haben, wie man programmiert. Sie stagniert, wenn Teams das Wissen, das bereits in ihren Repos und Dokumenten vorhanden ist, nicht finden, ihm nicht vertrauen oder es nicht wiederverwenden können. Das ist Wissensentropie: ADRs, die über Wikis verstreut sind, API-Verträge, die in PDFs vergraben sind, und verlorenes Ownership durch organisatorische Fluktuation. Retrieval‑Augmented Generation (RAG) kann helfen, aber nur, wenn sie auf einem Retrieval-Backbone basiert, das sowohl semantisch als auch deterministisch ist. Hier verändert hybrides Indexing über strukturiertes Know‑How die Spielregeln für PR-Merges und sicherere Refactorings.
Die wichtigsten Erkenntnisse
- Hybrides Indexing + strukturiertes Know‑How reduziert Halluzinationen und liefert präzise, überprüfbare Zitate, die PR-Reviews beschleunigen.
- Betrachten Sie RAG für Entwickler als ein technisches System: Messen Sie precision@k, Zitatgenauigkeit, Time‑to‑Merge und Revert-Rate.
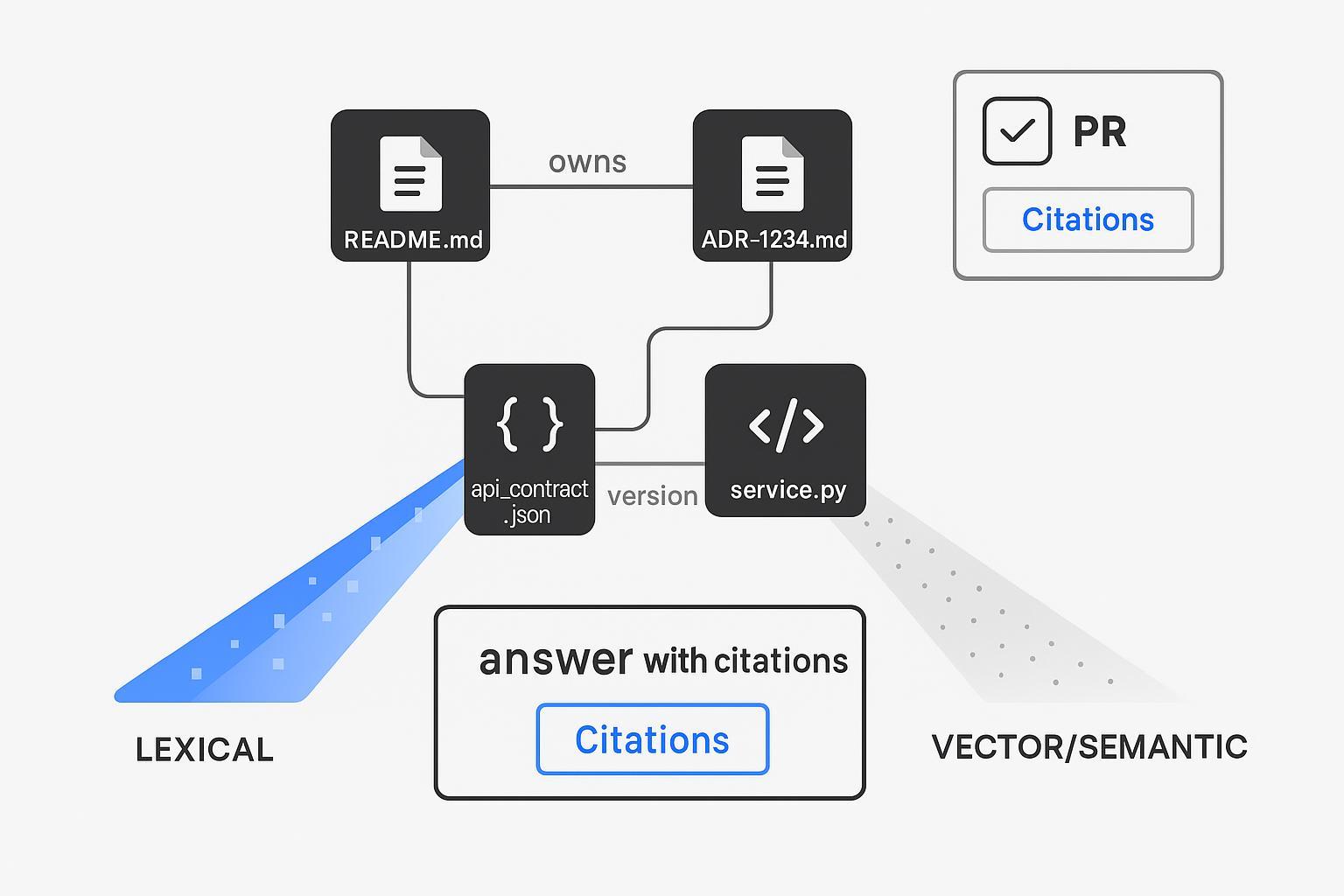
- Verwenden Sie einen hybriden Retriever (sparse lexical + dense vectors + structural/graph keys), um Fragen zur Codebasis mit exakten Dateipfaden und ADR-IDs zu beantworten.
- Beginnen Sie mit Micro‑Workflows: einem Assistenten für PR-Beschreibungen mit Zitaten und einem Refactoring-Berater, der auf ADRs/Ownership basiert.
- Bevorzugen Sie private/lokale Deployments, die Schwärzung von Geheimnissen vor dem Embedding und Human‑in‑the‑Loop-Gates für alle Schreibvorschläge.
RAG für Entwickler – was funktioniert und was scheitert
RAG kombiniert ein LLM mit einem Retriever, der Belege aus Ihrem Code, Ihren Dokumenten und Ihrer Design-Historie abruft. Wenn es funktioniert, erhalten Entwickler fundierte Zusammenfassungen und Entwürfe für PR-Texte mit Quellenangaben. Wenn es scheitert, erhalten Sie selbstbewusste, falsche Antworten und das Vertrauen bricht zusammen.
Fehlermuster, auf die Sie achten sollten:
- Nur-Text-Vektoren übersehen exakte Identifikatoren (ADR‑1234, Funktionsnamen) und liefern plausible, aber falsche Chunks zurück.
- Over-Retrieval überflutet Prompts; Reviewer sehen Rauschen statt Signale.
- Fehlende Zitate bedeuten fehlendes Vertrauen; Reviewer müssen die Suche erneut selbst durchführen.
Best-Practice-Lösungen stützen sich auf gut dokumentierte Leitfäden: semantisches Chunking, hybrides Retrieval und Reranking. Für einen prägnanten Architekturüberblick siehe die produktionsorientierten Muster im InfoQ-Artikel über RAG-Pipelines, der die Komposition und Evaluierung des Retrievals betont, nicht magische Prompts (InfoQ — Effective Practices for Architecting a RAG Pipeline). Und für agentische Entwickler-Workflows zur CI-Zeit zeigt die Diskussion von GitHub über Continuous AI, wie Assistenten Artefakte im Loop entwerfen und verifizieren können (GitHub Blog — Continuous AI in practice: agentic CI for developers).
Strukturiertes Know‑How + hybrides Indexing als Retrieval-Backbone
Text allein kann Ihre Entwickler-Workflows nicht tragen. Modellieren Sie Enterprise-Know‑How explizit und führen Sie Abrufe über Text und Struktur hinweg durch.
Ein minimales Know‑How-Schema (illustrativ):
{
"type": "adr",
"adr_id": "ADR-1234",
"title": "Deprecate legacy payment gateway",
"status": "accepted",
"decision": "Move to PayFast v3",
"owners": ["@payments-core"],
"links": {"repo_paths": ["/services/payments"], "docs": ["/docs/payments/adr-1234.md"]},
"supersedes": ["ADR-0899"],
"date": "2025-11-06",
"version": "1.2"
}
Hybrides Retriever-Design (auf einen Blick):
- Lexikalisch: exakte Filter (repo_path:/services/payments, file:*.md), BM25 für Identifikatoren.
- Dense: Code/Doc-Embeddings für Paraphrasen und Intentionen.
- Strukturell: deterministische Joins über Schlüssel (adr_id, owner, module), um die richtigen Dateien/Owner abzurufen.
- Optional: Reranking mit einem Cross‑Encoder für die Originaltreue (faithfulness).
Dieses Muster spiegelt die Leitfäden von Anbietern und der Community zum Thema hybride Suche wider – Dense + Sparse Fusion mit optionalem Reranking, wie in den Engineering-Ressourcen zur hybriden Suche von Qdrant dokumentiert (Qdrant — Hybrid Search Revamped; Qdrant Docs — Hybrid Queries). Das Ergebnis ist ein Retrieval-Layer, der exakte Dateipfade und ADR-IDs zitieren kann, nicht nur „etwas, das so ähnlich ist“. Das ist der Vertrauenshebel, den Reviewer benötigen.
Micro‑Workflows, die PRs beschleunigen
- PR-Beschreibungs-Assistent mit Zitaten
Ziel: Erstellung eines fundierten PR-Bodys aus dem Diff und dem lokalen Know‑How.
Kernschritte:
- Erweitern Sie den Branch/PR-Titel in Query-Varianten.
- Rufen Sie Top‑k ab aus: (a) geänderten Pfaden (lexikalische Filter), (b) semantisch ähnlichen Dokumenten/Chunks, (c) strukturellen Schlüsseln (ADRs/Owners).
- Generieren Sie einen PR-Body, der immer einen Zitate-Block mit Permalinks enthält.
Beispiel für ein PR-Body-Template:
#### Summary
- Implements PayFast v3 retry policy in /services/payments/retry.go
#### Rationale
- Aligns with ADR-1234 (Deprecate legacy payment gateway). See details below.
#### Impact
- Touches retry.go; no public API changes. Adds metric payments.retry.backoff_ms.
#### Citations
- ADR-1234 — /docs/payments/adr-1234.md#decision
- Code — /services/payments/retry.go#L120-L168
- Runbook — /ops/runbooks/payments-retries.md#rollback
- Refactoring-Berater auf Basis von ADRs und Ownership
Ziel: Große Refactorings sicherer machen, indem Design-Intentionen und Owner automatisch eingeblendet werden.
Kernschritte:
- Rufen Sie bei einem vorgeschlagenen Refactoring-Plan ersetzte ADRs und betroffene Modul-Owner ab.
- Generieren Sie eine Checkliste: „@payments-core benachrichtigen“, „Contract-Tests aktualisieren“, „Deprecation-Window gemäß ADR‑0899 bestätigen“.
- Geben Sie Zitate zu jeder Quelle aus, damit Reviewer diese schnell verifizieren können.
Entwicklergeschwindigkeit und Retrieval-Qualität messen
Behandeln Sie RAG als ein technisches System mit prüfbaren Ergebnissen.
Zu verfolgende Metriken:
- Geschwindigkeit: Median Time‑to‑Merge (TTM), Merge-Rate (merged/opened), Review-Iterationen pro PR.
- Qualität: Revert-Rate, CI-Fehlerrate, Defekte nach dem Merge bei Refactorings.
- Retrieval: precision@k, Zitatgenauigkeit (stützt die zitierte Quelle die Behauptung?), Halluzinationsrate.
A/B-Plan (8–12 Wochen):
- Kontrollgruppe: Standard-Workflow.
- Testgruppe: Aktivierung des PR-Beschreibungs-Assistenten + Refactoring-Berater (nur Lese-Vorschläge) mit Zitaten.
- Instrumentierung von Ereignissen bei Retrieval → Vorschlag → Reviewer-Akzeptanz/Überschreibung → Merge.
Für einen breiteren Branchenkontext zur Messung und Verbesserung der RAG-Originaltreue und des Zitierverhaltens siehe aktuelle Survey- und Evaluierungsarbeiten, die Relevanz/Originaltreue-Metriken und LLM‑as‑Judge-Auditing formalisieren (arXiv — Evaluation of Retrieval‑Augmented Generation: A Survey; arXiv — Comprehensive and Practical Evaluation of RAG).
Von der Demo zur Produktion
Sie brauchen keinen Monolithen; Sie brauchen einen zuverlässigen Loop.
- Ingestion: Sprachsensitives Chunking für Code (Funktionen/Klassen) und Dokumente (Header/Semantik). Metadaten anhängen (repo_path, module, owner, version). Ziel: 500–1500 Token für Code; 400–1000 für Dokumente.
- Indexierungs-Rhythmus: Re-Embedding bei Änderungen; nächtlicher Batch für aktive Repos; wöchentlich für inaktive. Versionieren Sie Ihren Index für Rollbacks.
- Governance: Bevorzugen Sie private/lokale Deployments; passen Sie Retrieval-ACLs an Repo-Berechtigungen an; schwärzen Sie Geheimnisse vor dem Embedding.
- Serving: Begrenzen Sie k, um Token zu kontrollieren; cachen Sie häufige Abfragen; ziehen Sie Cross-Encoder-Reranking für schwierige Namespaces in Betracht.
- Monitoring: Verfolgen Sie precision@k, Zitatgenauigkeit, Latenz und Kosten pro Abfrage. Alarmierung bei Drift (Abfall der Präzision/Zitatgenauigkeit).
Signale aus der Praxis zeigen, warum es sich lohnt. Amazon berichtete, dass Amazon Q Developer groß angelegte Java-Upgrades bei Zehntausenden von Anwendungen von Tagen auf Minuten verkürzte, was schätzungsweise 4.500 Entwicklerjahre einsparte und zu einem jährlichen Effekt von 260 Millionen US-Dollar beitrug (AWS DevOps & Developer Productivity Blog, 2024) – ein Beweis dafür, dass eingebettete Entwickler-Assistenten Sprünge im Durchsatz ermöglichen können, wenn sie in den SDLC integriert werden (AWS DevOps Blog — Amazon Q Developer milestone). Und die GitHub-Kundenstory über Mercado Libre weist auf eine unternehmensweite Einführung mit ca. 50 % weniger Zeitaufwand für das Schreiben von Code und einem außergewöhnlichen PR-Durchsatz hin, was darauf hindeutet, dass das Potenzial hoch ist, wenn Assistenten im kritischen Pfad liegen (GitHub Customer Stories — Mercado Libre).
Hinweise zum Tooling – Stacks, die gut zusammenspielen
- Vektor + Sparse: Qdrant, Pinecone, Weaviate unterstützen alle hybride Muster; wählen Sie basierend auf der Kontrolle über Score-Fusion, operativer Reife und Kosten.
- Orchestrierung: LangChain/LlamaIndex für schnelle Komposition; Dagster/Airflow für Ingestion-Ops.
- Embeddings: Wählen Sie auf Code abgestimmte Modelle für Repositories; überwachen Sie Drift und führen Sie selektives Re-Embedding durch.
- Graph/Struktur: Neo4j/TigerGraph für explizite Know‑How-Graphen oder leichtgewichtiges JSON/kv für kleinere Teams.
- Agent CI: Integrieren Sie Assistenten in PR-Hooks und CI-Kommentare gemäß GitHubs Leitfaden für agentische CI.
Praktisches Beispiel: Nutzung von puppyones strukturiertem Know‑How und hybridem Indexing
Hybrides Indexing glänzt nur dann, wenn Ihr Wissen für Maschinen modelliert ist. Ein neutraler Weg, dies zu implementieren, besteht darin, Enterprise-Wissen als strukturiertes Know‑How (JSON/Graph) zu speichern und lexikalische, Vektor- und strukturelle Lookups in einem einzigen Retriever zu verschmelzen.
Beispiel-Workflow (illustrativ, neutral):
- Modellieren Sie ADRs, Ownership und API-Verträge als erstklassige Know‑How-Knoten (z. B. adr_id, status, decision, owners, repo_paths, version).
- Ingestieren Sie Code/Doc-Chunks mit Metadaten (repo_path, symbols, owners). Erstellen Sie einen hybriden Index, in dem lexikalische Filter (z. B. Repo-Pfad), Vektoren (semantische Ähnlichkeit) und strukturelle Joins (adr_id → zugehörige Dateien/Owner) kombiniert werden.
- Verlangen Sie im PR-Assistenten einen Zitate-Block mit Permalinks zu ADRs und Dateizeilen-Bereichen, damit Reviewer diese schnell verifizieren können.
Dieses Muster wird durch öffentliche konzeptionelle Materialien von puppyone unterstützt, das sich um strukturiertes Know‑How und hybrides Indexing für deterministisches Retrieval und präzise Zitate positioniert. Für einen Überblick über diesen Ansatz siehe den Artikel des Unternehmens über hybrides Indexing, der zusammenfasst, wie Text und Struktur für eine zuverlässige Fundierung in Agent-Workflows kombiniert werden können (siehe die Übersicht im „Ultimate Guide to Agent Context Base: Hybrid Indexing“) (puppyone’s hybrid indexing guide). Nutzen Sie dies als konzeptionelle Referenz bei der Gestaltung Ihres eigenen Schemas und Retrievers; passen Sie es an Ihren Stack und Ihre Governance-Beschränkungen an.
Fazit und nächste Schritte
Wenn Ihr Ziel schnellere und sicherere PRs sind, investieren Sie zuerst in strukturiertes Know‑How und einen hybriden Retriever, der jede Behauptung mit einem Zitat belegen kann. Pilotieren Sie einen PR-Beschreibungs-Assistenten und einen Refactoring-Berater, messen Sie TTM und Zitatgenauigkeit und skalieren Sie dann das, was funktioniert. Wenn Sie strukturiertes Know‑How und hybrides Indexing erkunden, können Sie puppyone in einem kleinen, privaten Pilotprojekt evaluieren und mit Ihrem bestehenden Stack vergleichen.