Hybrid Indexing & Structured Know‑How for Dev Velocity
March 20, 2026Ollie @puppyone
Hybrid Indexing and Structured Know‑How: RAG for Developers that Speeds PR Merges
Developer velocity doesn’t stall because people forgot how to code. It stalls when teams can’t find, trust, or reuse the knowledge already inside their repos and docs. That’s knowledge entropy: ADRs scattered across wikis, API contracts buried in PDFs, ownership lost to org churn. Retrieval‑augmented generation (RAG) can help, but only if it’s grounded in a retrieval backbone that is both semantic and deterministic. That’s where hybrid indexing over structured Know‑How changes the game for PR merges and safer refactors.
Key takeaways
- Hybrid indexing + structured Know‑How reduces hallucinations and produces precise, reviewable citations that speed PR reviews.
- Treat RAG for developers as an engineering system: instrument precision@k, citation accuracy, time‑to‑merge, and revert rate.
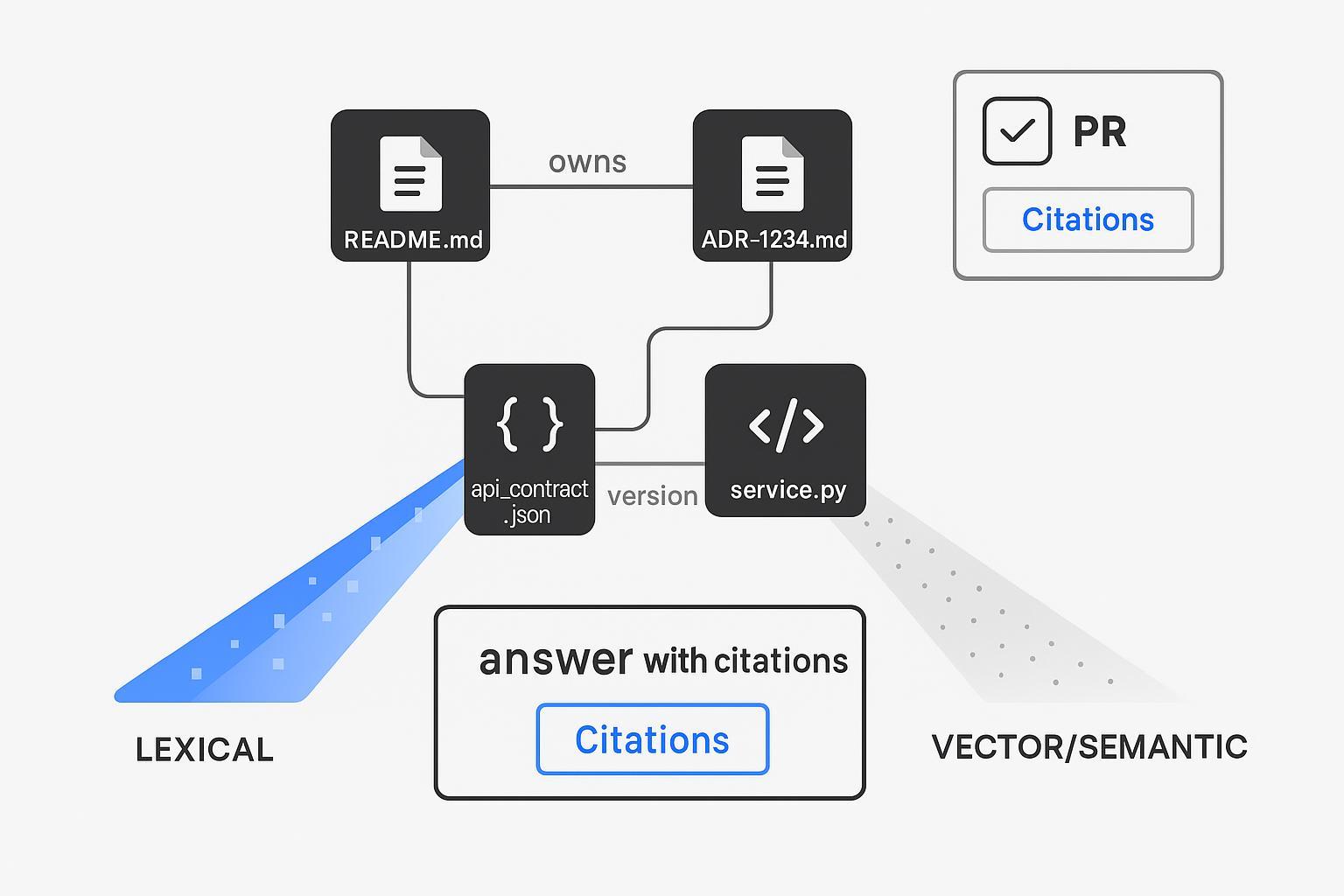
- Use a hybrid retriever (sparse lexical + dense vectors + structural/graph keys) to answer codebase questions with exact file paths and ADR IDs.
- Start with micro‑workflows: a PR description assistant with citations and a refactor advisor grounded in ADRs/ownership.
- Prefer private/local deployments, secret redaction before embedding, and human‑in‑loop gates for any write suggestions.
RAG for developers—what works and what breaks
RAG pairs an LLM with a retriever that fetches evidence from your code, docs, and design history. When it works, developers get grounded summaries and draft PR text with sources. When it breaks, you get confident wrong answers and trust collapses.
Failure patterns to watch:
- Text‑only vectors miss exact identifiers (ADR‑1234, function names), returning plausible but wrong chunks.
- Over‑retrieval floods prompts; reviewers see noise, not signal.
- No citations means no trust; reviewers must re‑do the search.
Best‑practice fixes draw on well‑documented guidance: semantic chunking, hybrid retrieval, and reranking. For a concise architectural overview, see the production‑minded patterns in the InfoQ article on RAG pipelines, which emphasizes retrieval composition and evaluation, not magic prompts (InfoQ — Effective Practices for Architecting a RAG Pipeline). And for agentic developer workflows at CI time, GitHub’s discussion of continuous AI shows how assistants can draft and verify artifacts in the loop (GitHub Blog — Continuous AI in practice: agentic CI for developers).
Structured Know‑How + hybrid indexing as the retrieval backbone
Text alone can’t carry your developer workflows. Model enterprise Know‑How explicitly and retrieve across text and structure.
A minimal Know‑How schema (illustrative):
{
"type": "adr",
"adr_id": "ADR-1234",
"title": "Deprecate legacy payment gateway",
"status": "accepted",
"decision": "Move to PayFast v3",
"owners": ["@payments-core"],
"links": {"repo_paths": ["/services/payments"], "docs": ["/docs/payments/adr-1234.md"]},
"supersedes": ["ADR-0899"],
"date": "2025-11-06",
"version": "1.2"
}
Hybrid retriever design (at a glance):
- Lexical: exact filters (repo_path:/services/payments, file:*.md), BM25 for identifiers.
- Dense: code/doc embeddings for paraphrases and intent.
- Structural: deterministic joins by keys (adr_id, owner, module) to pull the right files/owners.
- Optional: rerank with a cross‑encoder for faithfulness.
This pattern mirrors vendor and community guidance on hybrid search—dense + sparse fusion with optional reranking as documented by Qdrant’s hybrid search engineering resources (Qdrant — Hybrid Search Revamped; Qdrant Docs — Hybrid Queries). The result is a retrieval layer that can cite exact file paths and ADR IDs, not just “something kind of like it.” That’s the trust lever reviewers need.
Micro‑workflows that move PRs faster
- PR description assistant with citations
Goal: Draft a grounded PR body from the diff and local Know‑How.
Core steps:
- Expand the branch/PR title into query variants.
- Retrieve top‑k from: (a) changed paths (lexical filters), (b) semantically similar docs/chunks, (c) structural keys (ADRs/owners).
- Generate a PR body that always includes a Citations block with permalinks.
Example PR body template:
#### Summary
- Implements PayFast v3 retry policy in /services/payments/retry.go
#### Rationale
- Aligns with ADR-1234 (Deprecate legacy payment gateway). See details below.
#### Impact
- Touches retry.go; no public API changes. Adds metric payments.retry.backoff_ms.
#### Citations
- ADR-1234 — /docs/payments/adr-1234.md#decision
- Code — /services/payments/retry.go#L120-L168
- Runbook — /ops/runbooks/payments-retries.md#rollback
- Refactor advisor powered by ADRs and ownership
Goal: Make large refactors safer by surfacing design intent and owners automatically.
Core steps:
- Given a proposed refactor plan, retrieve superseded ADRs and affected module owners.
- Generate a checklist: “notify @payments-core,” “update contract tests,” “confirm deprecation window per ADR‑0899.”
- Emit citations to each source so reviewers can verify quickly.
Measure developer velocity and retrieval quality
Treat RAG as an engineering system with auditable outcomes.
Metrics to track:
- Velocity: median time‑to‑merge (TTM), merge rate (merged/opened), review iterations/PR.
- Quality: revert rate, CI failure rate, post‑merge defects for refactors.
- Retrieval: precision@k, citation accuracy (does the cited source support the claim?), hallucination rate.
A/B plan (8–12 weeks):
- Control: standard workflow.
- Treatment: enable the PR description assistant + refactor advisor (read‑only suggestions) with citations.
- Instrument events at retrieve → suggest → reviewer accept/override → merge.
For broader industry context on measuring and improving RAG faithfulness and citation behavior, see recent survey and evaluation work that formalizes relevance/faithfulness metrics and LLM‑as‑judge auditing (arXiv — Evaluation of Retrieval‑Augmented Generation: A Survey; arXiv — Comprehensive and Practical Evaluation of RAG).
From demo to production
You don’t need a monolith; you need a reliable loop.
- Ingestion: language‑aware chunking for code (functions/classes) and docs (headers/semantics). Attach metadata (repo_path, module, owner, version). Target 500–1500 tokens for code; 400–1000 for docs.
- Indexing cadence: re‑embed on change; nightly batch for hot repos; weekly for cold ones. Version your index for rollbacks.
- Governance: prefer private/local deployments; align retrieval ACLs to repo permissions; redact secrets before embedding.
- Serving: cap k to control tokens; cache frequent queries; consider cross‑encoder reranking for tricky namespaces.
- Monitoring: track precision@k, citation accuracy, latency, and cost/query. Alert on drift (precision/citation accuracy drops).
Real‑world signals show why it’s worth doing. Amazon has reported that Amazon Q Developer collapsed large‑scale Java upgrades from days to minutes across tens of thousands of applications, saving an estimated 4,500 developer‑years and contributing to a $260M annual impact (AWS DevOps & Developer Productivity Blog, 2024) — evidence that embedded developer assistants can unlock step‑changes in throughput when integrated into the SDLC (AWS DevOps Blog — Amazon Q Developer milestone). And GitHub’s customer story on Mercado Libre points to organization‑wide adoption with ~50% less time spent writing code and extraordinary PR throughput, suggesting the ceiling is high when assistants are in the critical path (GitHub Customer Stories — Mercado Libre).
Tooling notes—stacks that play nicely
- Vector + sparse: Qdrant, Pinecone, Weaviate all support hybrid patterns; pick based on control over score fusion, ops maturity, and cost.
- Orchestration: LangChain/LlamaIndex for quick composition; Dagster/Airflow for ingestion ops.
- Embeddings: choose code‑tuned models for repositories; monitor drift and re‑embed selectively.
- Graph/structure: Neo4j/TigerGraph for explicit Know‑How graphs or lightweight JSON/kv for smaller teams.
- Agent CI: integrate assistants in PR hooks and CI comments per GitHub’s agentic CI guidance.
Practical example: using puppyone’s structured Know‑How and hybrid indexing
Hybrid indexing only shines when your knowledge is modeled for machines. One neutral way to implement this is to store enterprise knowledge as structured Know‑How (JSON/graph) and fuse lexical, vector, and structural lookups in a single retriever.
Example workflow (illustrative, neutral):
- Model ADRs, ownership, and API contracts as first‑class Know‑How nodes (e.g., adr_id, status, decision, owners, repo_paths, version).
- Ingest code/doc chunks with metadata (repo_path, symbols, owners). Build a hybrid index where lexical filters (e.g., repo path), vectors (semantic similarity), and structural joins (adr_id → related files/owners) are combined.
- In the PR assistant, require a Citations block with permalinks to ADRs and file line‑spans so reviewers can verify quickly.
This pattern is supported by public conceptual materials on puppyone, which positions itself around structured Know‑How and hybrid indexing for deterministic retrieval and precise citations. For an overview of this approach, see the company’s article on hybrid indexing, which summarizes how text and structure can be combined for reliable grounding in agent workflows (see the overview in the “Ultimate Guide to Agent Context Base: Hybrid Indexing”) (puppyone’s hybrid indexing guide). Use this as a conceptual reference when designing your own schema and retriever; adapt to your stack and governance constraints.
Conclusion and next steps
If your goal is faster, safer PRs, invest first in structured Know‑How and a hybrid retriever that can prove every claim with a citation. Pilot a PR description assistant and a refactor advisor, measure TTM and citation accuracy, then scale what works. If you’re exploring structured Know‑How and hybrid indexing, you can evaluate puppyone in a small, private pilot and compare it with your existing stack.