Ultimate Guide to Finance Back Office Automation
February 5, 2026Ollie @puppyone
Key takeaways
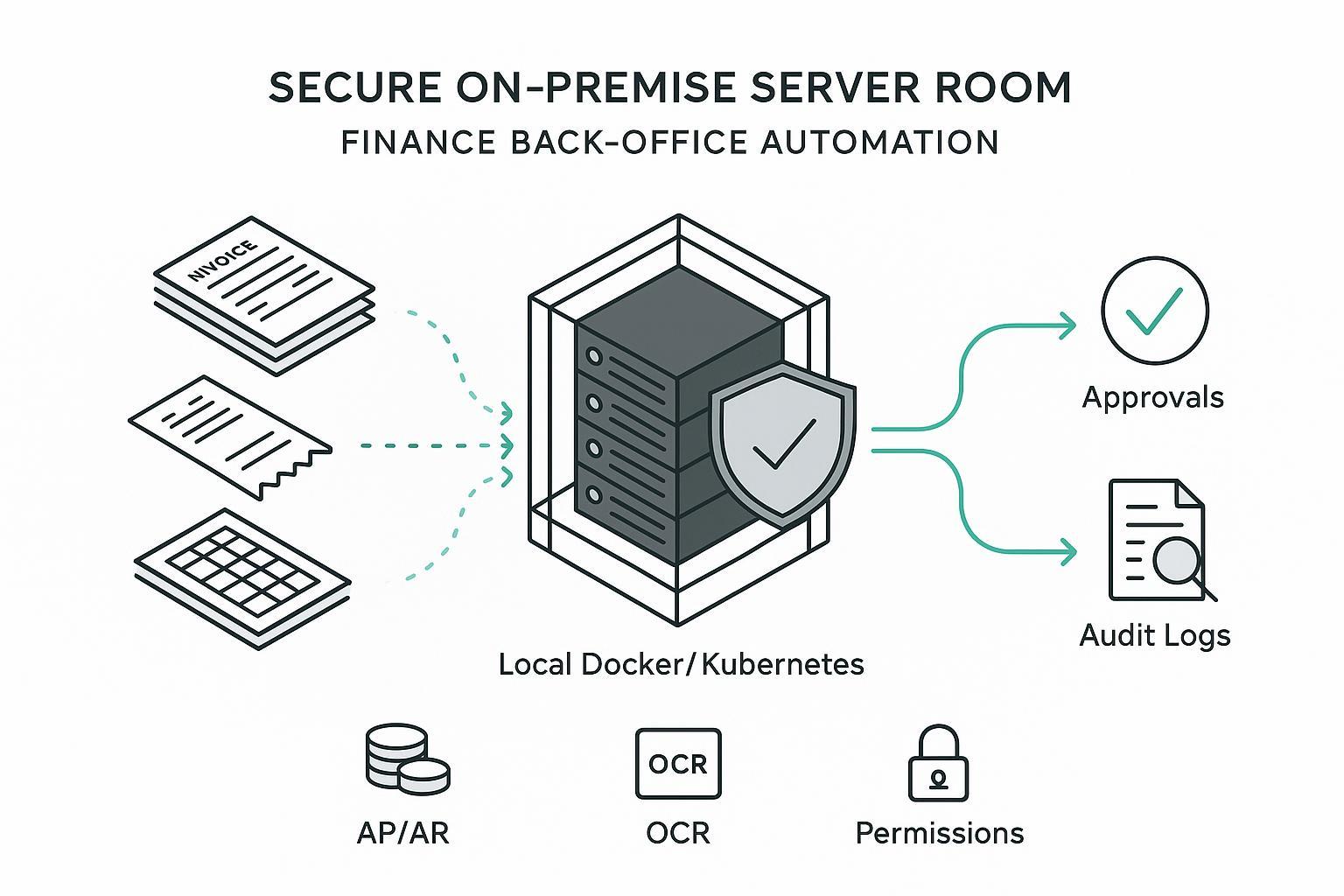
- Local‑first deployments reduce cross‑border data transfer risk and improve control, while raising ops ownership you should plan for.
- Deterministic retrieval comes from structuring finance “know‑how” into JSON or graph models plus hybrid indexing, not from vectors alone.
- Agentic workflows must enforce segregation of duties with human‑in‑the‑loop checkpoints and full provenance of every step.
- The compliance controls that matter most are access governance, encryption, audit logging, retention, and SoD mapping to ICFR.
- Measure what moves the needle: cycle time, touchless rate, exception rate, extraction accuracy, and cost per invoice.
Why local‑first matters for finance back office automation
Local‑first means the core of your finance back office automation—ingestion, parsing, indexing, retrieval, and orchestration—runs on infrastructure you control, typically via Docker or Kubernetes in a private data center or VPC. This matters for three reasons.
First, privacy and residency. Keeping receipt images, invoices, and vendor records in‑house minimizes data transfer exposure and simplifies residency posture under GDPR principles like data minimization and storage limitation. Supervisors emphasize scoping, retention, and contestability for automated decisions; see the European Data Protection Board’s guidance on AI systems and GDPR principles in 2024, which stresses necessity tests and human oversight for automated decisions described in Article 22, summarized in the EDPB’s opinion on AI models and GDPR principles in 2024.
Second, auditability and explainability. Finance decisions—posting, approvals, holds—need traceable reasons. Local‑first stacks favor deterministic pipelines with reproducible retrieval, explicit indexes, and step‑by‑step logs that support internal control assertions.
Third, operational predictability. Co‑located compute and data give stable latency and cost visibility. You own bursting and HA/DR patterns, but you also avoid opaque throttles and shared‑tenant surprises.
For implementation patterns of on‑prem generative AI, including containerized model servers and network isolation, a concise engineering overview is provided in TrueFoundry’s perspective on on‑prem generative AI deployments, which outlines isolation, encryption, and observability patterns.
The hero use case across AP and AR
In the finance back office, three documents dominate daily work: invoices and receipts, spreadsheets that hold allocations and vendor data, and the emails that connect them. Automating this flow looks like:
- Capture and normalize inputs from shared inboxes, SFTP drops, AP portals, and chat exports.
- Apply OCR and document AI to extract header and line items, totals, dates, VAT or tax IDs, and supplier references.
- Enrich with master data and policies, then route to a retrieval layer that agents or workflows consult for approvals.
- Enforce SoD and approval thresholds with explicit human checkpoints when confidence or amount crosses a line.
- Post back into the GL or AP system with complete provenance, or raise exceptions.
Vendor‑reported examples suggest meaningful gains when this is done well: Hypatos reports a 60–80% reduction in invoice cycle time with agentic AP approaches, and NetSuite’s business case pages describe high straight‑through processing rates on standard invoices. Treat such figures as directional and validate against your own baselines once deployed.
Architecture patterns compared
Below is a compact comparison of three deployment approaches you can choose for finance back office automation.
| Pattern | Data residency | Control over models and logs | Latency predictability | Ops ownership |
|---|---|---|---|---|
| Cloud SaaS | Limited by vendor regions and subprocessors | Low, vendor managed | Variable across tenants | Minimal |
| Hybrid | Sensitive docs local, inference may burst to cloud | Medium, shared across planes | Mixed, depends on traffic paths | Moderate |
| Local‑first | In‑country or on‑prem by default | High, full control and audit trails | Stable and tunable | High |
Tip: choose local‑first when handling sensitive receipts, payroll‑adjacent docs, or card‑present data, and when your auditors require strong evidence of residency and access control. For hybrid, document exactly what data stays local and what transiently leaves.
Ingestion and document AI that finance can trust
The aim is not 100% automated extraction on day one; it’s reliable data with clear confidence and routing. Favor engines that expose field‑level confidences and layout primitives so you can design review loops. Microsoft’s Azure Document Intelligence documentation explains how to interpret confidence and service limits, which helps teams design human‑in‑the‑loop review when needed.
A minimal, vendor‑neutral connector configuration might look like this YAML. It ingests emails and PDFs from a secure inbox and S3, applies OCR with language hints, and writes normalized JSON to a secure bucket with PII redaction enabled.
connectors:
- name: ap_shared_inbox
type: imap
host: imap.company.local
mailbox: Invoices
tls: true
extract_attachments: [".pdf", ".png", ".jpg"]
- name: s3_receipts
type: s3
bucket: finance-receipts-prod
prefix: raw/2026/
server_side_encryption: AES256
pipelines:
- name: idp_pipeline
sources: [ap_shared_inbox, s3_receipts]
steps:
- ocr:
engine: generic_idp
language_hints: ["en", "de"]
- redact:
fields: ["card_number", "email", "phone"]
- normalize:
schema: invoice_v1
- sink:
type: s3
bucket: finance-receipts-prod
prefix: normalized/
Focus evaluation on your document mix, not generic benchmarks. For example, track extraction accuracy for vendor name, invoice number, issue date, tax ID, currency, subtotal, tax, total, and GL code suggestions. Confidence below threshold? Route to review.
Structuring for deterministic retrieval
Vectors accelerate semantic similarity, but finance needs repeatable answers tied to explicit sources and rules. The pattern that works combines a structured “know‑how” layer—JSON or a lightweight graph—with hybrid indexing across text and structure, plus query plans that prefer deterministic paths.
- Structure invoices, receipts, and policies into typed objects with IDs and relationships. Think Vendor → Invoices → Lines → Approvals → Payment.
- Index both the text surfaces and the structured fields like vendor_id, due_date, tax_amount, and approval_threshold.
- At query time, combine deterministic filters or graph traversals with re‑ranking. Log the path and sources for audit.
For a practitioner look at hybrid RAG with graph‑backed provenance and why it improves auditability, ArangoDB’s perspectives on HybridRAG discuss combining vector and graph stores to get both semantic recall and explicit relations in one system. Complement this with explainable graph‑RAG approaches in recent research that emphasize controllable traversal and provenance logging.
A compact object example for deterministic retrieval could be:
{
"type": "invoice",
"id": "inv_2026_000312",
"vendor_id": "ven_0192",
"invoice_number": "A-55231",
"issue_date": "2026-02-01",
"due_date": "2026-03-02",
"currency": "USD",
"lines": [
{"sku": "CONSULT", "qty": 12, "unit_price": 150, "gl_code": "6205"}
],
"totals": {"subtotal": 1800, "tax": 162, "grand_total": 1962},
"policy_refs": ["ap_policy_threshold_usa"],
"provenance": [
{"source": "s3://finance-receipts-prod/normalized/inv_000312.json", "hash": "sha256:..."}
]
}
Agentic workflows with approvals and human oversight
Agentic orchestration helps when it is bounded by explicit policies, thresholds, and HITL pauses. Effective patterns borrow from coordinator and hierarchical designs described in Google Cloud’s agentic AI design patterns, where a planner decomposes tasks and delegates to narrow tools, and every decision emits structured logs.
Design cues that work in finance:
- Separate agents by responsibility: extraction, policy check, GL coding, and approvals coordination.
- Enforce SoD so the same principal cannot extract, approve, and post. Map roles to IdP groups, then assert checks at runtime.
- Treat uncertain or high‑risk items as “pauses” for humans with context snapshots and recommended actions.
For SoD reference, Hyperproof’s overview of segregation of duties outlines separating authorization, custody, recordkeeping, and reconciliation, which maps cleanly to agent roles in AP and AR.
Permissions and distribution for agents
A robust permission model prevents over‑privilege while keeping automation effective. Use a blend of role‑based and attribute‑based controls tied to your IdP groups and document tags.
A minimal, illustrative access policy can be expressed in Rego or as structured rules. The example below allows the AP bot to read invoices for the US entity under a threshold but denies posting rights.
package finance.authz
import future.keywords.contains
allow_read[doc_id] {
input.principal == "ap_bot"
input.action == "read"
docs[doc_id].type == "invoice"
docs[doc_id].entity == "US"
docs[doc_id].totals.grand_total <= 5000
}
deny_post {
input.principal == "ap_bot"
input.action == "post_gl"
}
Distribution matters too. Some agents integrate via an API, others via a local tool protocol or sandboxed shell. Keep a single source of truth for context and expose multiple protocols from there, so you do not duplicate permissions or fragment audit logs.
Compliance controls that actually matter
- GDPR themes: lawfulness, minimization, storage limitation, and contestability for automated decisions. The European Data Protection Board’s 2024 opinion on AI models and GDPR principles underscores necessity tests, governance, and human oversight.
- SOC 2 Trust Services Criteria: access, operations, change, and risk management. Processing Integrity is especially relevant for finance pipelines; AuditBoard’s SOC 2 guidance summarizes control families and actionable checklists.
- PCI DSS 4.0 when card data appears anywhere: strong access control, MFA, encryption at rest and in transit, monitoring, and physical security for on‑prem. The PCI Security Standards Council’s PCI DSS portal is the canonical reference.
- SOX 404: tie system controls to ICFR assertions and keep complete, immutable audit trails. A readable explainer is Exabeam’s guide to SOX 404 requirements and control checklists.
Document your data flows and retention, link policies to technical controls, and set up continuous evidence collection. That way, compliance is an outcome of engineering, not a scramble before audits.
Observability and continuous evaluation
Two planes matter: extraction quality and workflow reliability. On extraction, sample invoices weekly and compute field‑level precision and recall. On workflows, monitor cycle time distributions, touchless rate, exception reasons, and approval SLA adherence. Emit correlation IDs across ingestion, extraction, retrieval, and posting so you can reconstruct any event chain within minutes.
For security observability and retention patterns that auditors recognize, see AuditBoard’s overview of security log retention practices, which highlights retention horizons and chain‑of‑custody expectations.
Practical example with a local‑first context base
Disclosure: puppyone is our product. In a local‑first deployment, a context base runs via Docker on your infrastructure to ingest and structure receipts, invoices, and email threads into machine‑readable “know‑how,” index both text and fields, and expose the result to agents via multiple protocols. You would point your IMAP connector and S3 bucket to the ingestion service, define folder‑style permissions for AP and AR agents, and enable distribution via an internal API for approval bots and a local tool protocol for reconciliation scripts. The benefit is one source of truth for context, deterministic retrieval plans grounded in structure, and unified audit logs across all agent channels. Teams that prefer an alternative pattern can compose open‑source OCR, a Postgres plus vector store, a graph DB for relationships, and a policy engine like OPA to achieve similar goals with more assembly required.
Migration playbook from shared inboxes to deterministic pipelines
- Baseline and risk review: map data flows, classify documents, confirm lawful bases, and define retention. Establish baseline KPIs and create a test corpus of 200–500 real documents.
- Local‑first foundation: provision a private Kubernetes or Docker host with encryption at rest and TLS, integrate SSO, and set up logging and backups. Configure IMAP and object storage connectors.
- Document AI evaluation: run A–B tests on your corpus, tune templates and confidence thresholds, and instrument human‑in‑the‑loop review.
- Structure and indexing: define JSON schemas, relationships, and hybrid indexes. Implement deterministic filters and graph traversals with reranking.
- Workflow orchestration: codify approval thresholds, SoD checks, and escalation paths. Add HITL pauses and exception queues.
- Controls and evidence: map policies to GDPR, SOC 2, PCI DSS, and SOX controls. Automate evidence capture and retention.
- Rollout and iterate: start with one entity or business unit, then broaden coverage while watching KPIs and remediating failure modes.
KPIs and realistic outcome ranges
What to track:
- Cost per invoice and cycle time from receipt to approval
- Touchless rate and exception rate with reasons
- Field‑level extraction accuracy and approval SLA adherence
Vendor‑reported examples provide directional ranges only and should be validated against your baselines: Hypatos cites 60–80% cycle‑time reductions for agentic AP, and NetSuite’s business case content highlights large reductions in processing time and high straight‑through processing for standard invoices. Use these as hypotheses, not promises. If your baseline cycle time is 10 days with 20% touchless, a reasonable first‑phase target might be 30–40% cycle‑time improvement and +15–25 points in touchless with proper HITL and controls.
Tooling selection criteria
- Document AI fit: supports your languages, handwriting if needed, tables, and exposes confidences and bounding boxes for review.
- Storage and indexing: hybrid capability across text and structure, with support for deterministic filters and provenance capture.
- Orchestration and policy: mature scheduler or workflow engine plus a policy layer that can enforce SoD at runtime tied to IdP groups.
- Observability: end‑to‑end logs with correlation IDs, metrics for extraction and workflow health, and evidence export for auditors.
- Deployment model: first‑class local‑first and on‑prem support with clear guidance on encryption, backups, and HA/DR.
Representative resources you can consult while making these choices include the PCI Security Standards Council’s PCI DSS 4.0 pages for card‑data implications, AuditBoard’s SOC 2 control checklists for processing integrity and access control, and Google Cloud’s agentic design patterns for reliable orchestration under human oversight.
Next steps
If you’re exploring local‑first finance back office automation and want to see how a context base integrates with your document mix, IAM, and approval flows, book a short working session with our team. We’ll review your architecture, identify a pilot slice, and outline a deterministic retrieval plan tailored to your controls. Book a demo.