Ultimate Guide to Hybrid Indexing for Context Learning
February 7, 2026Ollie @puppyone
Key takeaways
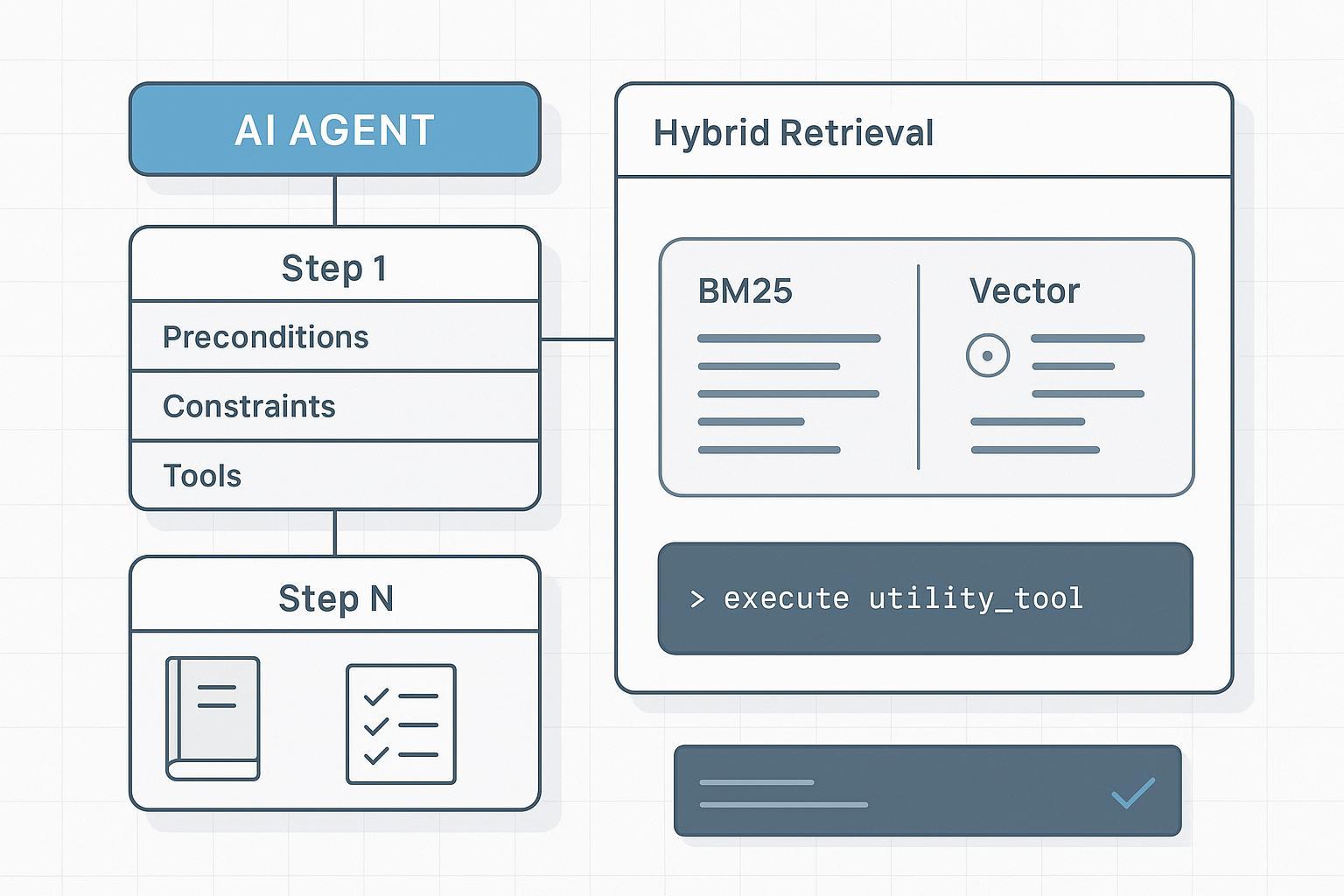
- Hybrid, field‑aware retrieval beats “just make the context longer.” You need deterministic slices per step, not a wall of text.
- Model limits are real: benchmarks show high rates of ignored/misused context; design your stack to prevent, detect, and correct these errors.
- For Operations/Support, pair a Know‑How JSON/Graph with hybrid indexing and an agentic planner→executor→verifier loop to achieve step adherence and auditability.
Why models ignore and misuse context for SOPs
A new benchmark built precisely to test in‑context learning shows how fragile today’s models are when learning from provided context. In CL‑bench (500 contexts, 1,899 tasks, 31,607 verification rubrics), ten frontier models solved only about 17.2% of tasks on average; the best model reached roughly 23.7% even in reasoning mode. Crucially, the dominant error was failing to use the provided context correctly—overlooking key details or applying the wrong rule. See the primary report in the CL‑bench paper by Tencent Hunyuan and collaborators: the authors document self‑contained tasks designed to force learning from the given materials and report the low solve rates with error analyses in 2026; details are in the paper PDF under the title CL‑bench: A Benchmark for Context Learning and in the project coverage on Hunyuan’s site (CL‑bench paper, arXiv PDF; Tencent Hunyuan research blog overview).
Long‑context capability alone doesn’t fix this. Recent long‑context studies show better window handling still leaves gaps in reasoning and aggregation across multi‑document inputs; length tolerance isn’t the same as learning and applying the right detail at the right time (see the ACL‑archived discussion in the LongBench v2 work: LongBench v2 ACL paper). For multi‑step SOPs—where preconditions, constraints, and tool parameters matter—this gap shows up as step‑skipping, instruction drift, or unsafe actions.
The common failure modes of naïve RAG for SOP execution
Even competent RAG stacks falter on operations workflows because the retrieval unit is misaligned with the action unit. Over‑broad chunks cause retrieval drift, the agent sees too much narrative and too few constraints, and unweighted fields bury critical tokens (step IDs, preconditions, warnings) under dense prose. Monolithic prompts further encourage the model to improvise, skipping verification or inventing steps and tools. These are solvable system problems, not just “train a bigger model.” The remedy is to design for deterministic retrieval and verifiable execution.
Foundations: Model your SOPs as a Know‑How JSON/Graph
Text manuals are written for people. Agents need structured, fielded knowledge that mirrors how actions are taken in production. A practical schema encodes steps, dependencies, constraints, and verification methods so retrieval can target exactly what the executor needs.
Here’s a compact example:
{
"id": "sop.router.reset.v3",
"title": "Router Safe Reset",
"version": "3.2",
"steps": [
{
"step_number": 7,
"description": "Apply staged configuration from backup",
"preconditions": ["Backup verified within 24h", "Device in maintenance mode"],
"constraints": ["Do not overwrite ACL table A unless delta<5 rules", "Max outage 90s"],
"tools_allowed": [
{
"name": "net.push_config",
"params_schema": {"backup_id": "string", "dry_run": "boolean"}
}
],
"checkpoints": [
{"name": "acl_delta_check", "type": "query", "expected": "<5"},
{"name": "latency_budget", "type": "timer", "expected": "<=90s"}
],
"verification_method": "Compare running-config hash to backup; confirm ACL delta and outage time"
}
],
"dependencies": [{"from": 6, "to": 7, "condition": "backup_verified==true"}],
"owners": ["netops"],
"permissions": {"roles": ["netops", "sre"], "min_clearance": "internal"}
}
This structure lets a retriever weight titles, step_number, preconditions, and constraints more than narrative. It also creates auditable “slices” the executor can cite. If you’re evaluating the “Agent Context Base” pattern in general, see a vendor‑neutral description of storing procedures as structured, versioned Know‑How rather than raw text; one example of this positioning is presented on puppyone’s site under About (internal resource: Context Base overview on puppyone About).
Hybrid indexing for context learning in long, dense manuals
The core move isn’t “longer context.” It’s “better retrieval units, better ranking signals.” In practice, that means hybrid indexing with field awareness and a small rerank pass.
- Combine sparse lexical signals (BM25/BM25F) with dense vectors. Lexical hits surface exact IDs, warnings, and constraints; dense vectors improve recall on semantically phrased steps. Practical introductions to hybrid fusion are available from leading engines like Elastic and Weaviate; both describe score blending and reciprocal rank fusion (RRF) with field weighting (see Elastic’s overview in What is hybrid search and their retriever/RRF notes: Elastic — What is hybrid search?; Elastic retrievers and RRF). For a conceptual breakdown of hybrid scoring, Weaviate’s technical write‑up is also helpful (Weaviate — Hybrid search explained).
- Use field‑aware boosts. Prefer titles, step_number, preconditions, constraints, tools_allowed over narrative.
- Retrieve minimal, deterministic slices per step. Don’t feed the entire SOP every time; fetch only the fields required for the current action and verification.
- Optionally rerank the top‑k with a cross‑encoder or a structure‑aware reranker to prioritize constraints and checkpoints.
This is the essence of hybrid indexing for context learning: you’re not trusting the model to “discover” the right detail in a sea of tokens—you’re putting the right atoms in its hand at the right moment.
Agentic RAG for SOPs: planner → retriever → executor → verifier
For operations work, execution reliability comes from orchestration that mirrors how humans follow procedures. The planner decomposes the task into step‑level intents and formulates targeted retrieval queries using fields like step_number and required tools. The retriever returns the minimal, fielded slices (preconditions, constraints, parameters, checkpoints) with IDs. The executor calls only enumerated tools with schema‑validated parameters; it must cite the slice IDs used and attach tool feedback to state. The verifier checks completion against checkpoints and constraints before advancing; it can trigger a re‑plan or human review on deviation. This pattern is widely discussed across industry design notes on agentic workflows; see overviews of agentic orchestration and verifier loops from platform and research teams (for example, Anthropic’s engineering notes on multi‑agent research systems discuss verifier and collaboration patterns: Anthropic — Multi‑agent research system).
Hands‑on example: one step, end‑to‑end (neutral, reproducible)
Disclosure: puppyone is our product. In this example block, it’s mentioned neutrally as one possible context base you can substitute with any stack you prefer. Learn more on the homepage (internal resource: puppyone — Agent Context Base).
Goal: Execute Step 7 of “Router Safe Reset” using hybrid retrieval and an agentic loop.
Query plan (planner):
- intent: apply staged configuration
- constraints_required: [“Do not overwrite ACL table A unless delta<5 rules”, “Max outage 90s”]
- fields: [step_number=7, preconditions, constraints, tools_allowed, checkpoints, verification_method]
Pseudocode (Python‑style):
# 1) Retrieve minimal, fielded slice (hybrid: BM25F + vector + RRF)
q = {
"step_number": 7,
"must_fields": ["preconditions", "constraints", "tools_allowed", "checkpoints"],
"keywords": ["staged configuration", "ACL delta", "outage 90s"],
}
results = hybrid_search(index="knowhow", query=q, k=5, field_boosts={
"constraints": 3.0, "preconditions": 2.0, "title": 1.5, "description": 1.0
})
slice = rerank_and_select_minimal(results, need=[
"preconditions", "constraints", "tools_allowed", "checkpoints", "verification_method"
])
# 2) Validate sufficiency before execution
assert slice.has_all(["preconditions", "constraints", "tools_allowed"]) and slice.confidence > 0.75
# 3) Execute with schema‑validated tool call
params = {"backup_id": env["LATEST_VERIFIED_BACKUP"], "dry_run": True}
resp = tool_call("net.push_config", params)
# 4) Verify checkpoints and constraints
ok_acl = check_acl_delta("A") < 5
ok_outage = measure_outage() <= 90
if ok_acl and ok_outage and resp.success:
mark_step_complete(step=7, used_slice_id=slice.id)
else:
escalate_or_replan(reason="constraint_failed", details={
"ok_acl": ok_acl, "ok_outage": ok_outage, "resp": resp
})
Tiny, illustrative state log:
used_slice: sop.router.reset.v3#step7
preconditions_ok: true
constraints_ok: {"acl_delta": true, "max_outage": true}
executor: net.push_config(dry_run=true) → success
verifier: passed
You can implement the same loop with Elastic/OpenSearch/Vespa/Weaviate or an RDBMS + pgvector + BM25 extension. The keys are fielded schema, hybrid scoring, and verifier checkpoints—vendor‑neutral by design.
Evaluation playbook: prove reliability, then scale
A credible SOP automation program measures both retrieval and execution. For retrieval quality, track Recall@k, MRR/nDCG on per‑step ground truth; context precision (fraction of injected tokens that are relevant); and context sufficiency (whether injected fields are enough to act correctly). For execution, measure Step Adherence %, Action Success Rate (schema‑valid tool calls that succeed), Instruction Drift Rate (deviations from constraints), Incidents per 1,000 Executions, and Time‑to‑Resolution. Your harness should, for each SOP step, store ground‑truth slice IDs and expected tool/result patterns; assert that the executor cites the used slice and that checkpoints pass before advancing. For an evidence‑based perspective on retrieval evaluation in RAG systems, see an up‑to‑date survey summarizing Recall@k, MRR, nDCG, and faithfulness/relevance measures (research overview: RAG evaluation survey (2024)).
Alternatives and parity (choose what fits your constraints)
Multiple stacks support hybrid search and on‑prem deployments. Choose based on field‑aware scoring, fusion support, deployment model, and observability.
| Stack | Hybrid fusion options | Field‑aware boosts | On‑prem/VPC fit | Notes |
|---|---|---|---|---|
| Elasticsearch | RRF, weighted blending | BM25F, multi‑field boosts | Mature self‑host | Rich retriever APIs; cross‑encoder rerankers |
| OpenSearch | Weighted + rerank patterns | Field boosts via analyzers | First‑class self‑host | Active vector perf work |
| Vespa | Lexical + ANN + rerank | Per‑field features | Self‑host, scale‑out | Strong ranking/ML pipeline |
| Weaviate | RRF/weighted hybrid | Property weights/filters | Managed + self‑host | Clear hybrid docs |
If you favor the “Agent Context Base” approach—storing procedures as structured, versioned Know‑How and serving deterministic slices—product options exist. One such option is puppyone (internal resource: puppyone homepage). Use neutral evaluation criteria: field‑aware scoring, deterministic slicing guarantees, audit logs, and evaluation harness support.
What “good” looks like in practice
In pilots, teams report that shifting from whole‑document prompts to per‑step, fielded slices substantially reduces instruction drift and increases step adherence. That aligns with benchmark evidence: models won’t autonomously extract and respect every constraint buried in prose. The point of hybrid indexing for context learning is to bring the exact constraint surface into the agent’s hands, then require it to verify before moving on. Do this consistently, and your incident reviews start to read like boring checklists—exactly how ops prefers them.
Next steps
If you’re evaluating a production‑grade approach to SOP automation—structured Know‑How, hybrid indexing, and an agentic planner→executor→verifier loop—let’s look at your corpus and constraints together. Book a technical demo focused on hybrid indexing + agentic RAG for your environment.