 Fuente de la Imagen: Generación IA
Fuente de la Imagen: Generación IA
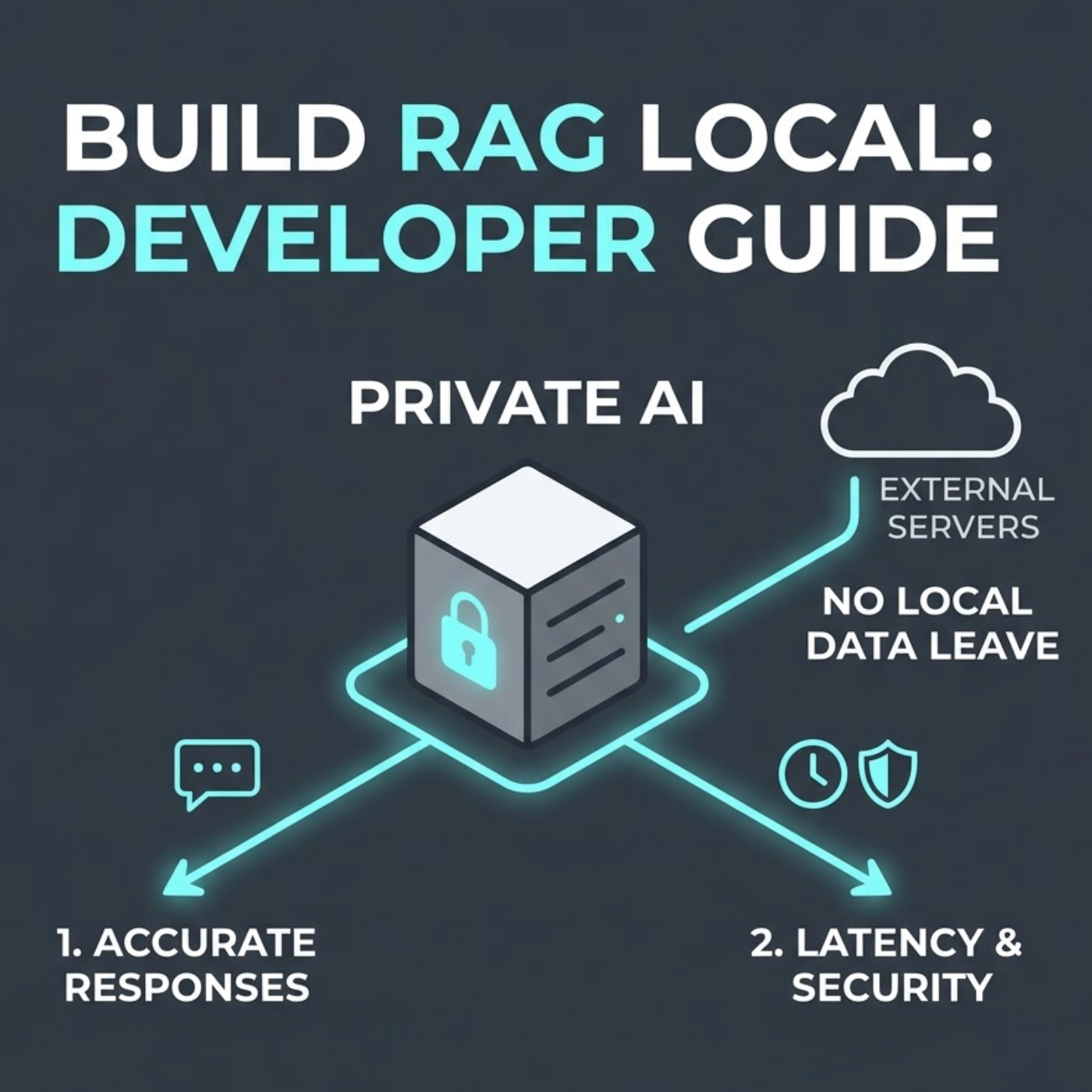
La privacidad de datos ha emergido como un tema crucial en el desarrollo de IA, particularmente en el manejo de datos empresariales sensibles. Las organizaciones se muestran reacias a enviar su información confidencial a servidores externos o servicios en la nube que procesan IA. Aquí es donde entran en juego los sistemas RAG (Generación Aumentada por Recuperación) de LangChain con datos locales, ofreciendo una opción segura para desarrolladores que necesitan mantener el control de su información.
Los sistemas RAG con datos locales, a menudo implementados usando LangChain, proporcionan grandes beneficios más allá de la privacidad. Reducen la latencia, permiten arquitecturas personalizadas y funcionan independientemente de servicios de terceros. En esta guía, te guiaremos a través de los pasos para construir tu propio sistema RAG local usando LangChain, cubriendo todo desde la configuración del entorno hasta la optimización del rendimiento. Los desarrolladores aprenderán cómo implementar soluciones de IA privadas que mantienen los datos sensibles seguros mientras conservan el control completo del proceso.
Configurando tu Entorno de Desarrollo Local
Para construir nuestro sistema RAG de LangChain, necesitamos configurar un entorno de desarrollo local resistente. Veamos todo lo que implica construirlo e implementarlo exitosamente.
Software y Dependencias Requeridas
Python 3.11 o superior sirve como nuestra base. Un gestor de entorno virtual te ayudará a comenzar - puedes elegir entre:
-
Entorno Virtual (venv)
- Crear y activar entorno virtual
- Instalar paquetes requeridos vía pip
- Generar requirements.txt para gestión de dependencias
-
Entorno Conda
- Crear entorno conda
- Instalar paquetes necesarios
- Exportar environment.yml para reproducibilidad
Para el desarrollo RAG de LangChain, necesitarás instalar librerías específicas como LangChain, Chroma para almacenamiento vectorial, y Ollama para despliegue local de LLM.
Requisitos de Hardware y Optimización
Los sistemas RAG locales necesitan configuraciones de hardware específicas. Aquí están las especificaciones recomendadas:
| Component | Minimum Requirement | Recommended |
|---|
| CPU | Multi-core processor | 16+ cores |
| RAM | 16GB | 32GB or higher |
| GPU | NVIDIA (8GB VRAM) | NVIDIA RTX 4080/4090 |
| Storage | Fast NVMe SSD | Multiple NVMe drives |
The system performs best with at least 4 CPU cores for each GPU accelerator. It also needs double the amount of CPU memory compared to the total GPU VRAM.
Pasos de Configuración Inicial
The environment setup for LangChain RAG development requires these key steps:
-
Install base dependencies:
- ChromaDB for vector storage
- LangChain tools for model integration
- Unstructured package for document processing
-
Configure model settings:
- Download required models (e.g., LLaMA 3.1)
- Set up environment variables
- Initialize vector database connection
Testing the basic functionality helps verify our installation. Teams working on enterprise solutions should set up proper version control and dependency management from the start.
Implementando la Base de Datos Vectorial Local
Vector databases are the foundations of our LangChain RAG system. The right vector store choice is vital for the best performance. Let's look at how we can build an efficient local vector database for our private AI solution.
Eligiendo el Almacén Vectorial Correcto
Building a RAG system needs careful thought about which vector store to use. Vector databases fall into two types: traditional databases with vector extensions and purpose-built vector solutions.
These are the main things to think about:
- Query Performance: The vector store should quickly find similar items using advanced algorithms
- Scalability: It needs to handle more data smoothly
- Storage Options: Both in-memory and disk-based storage options matter
Estrategias de Indexación de Datos
The right indexing strategy makes similarity searches much faster. The HNSW (Hierarchical Navigable Small World) index works really well. It gives you quick queries without losing much accuracy. There are other indexing options too:
| Index Type | Best For | Trade-offs |
|---|
| Flat Index | Small datasets | Simple but slower for large sets |
| HNSW Index | Large-scale data | More complex, better scaling |
| Dynamic Index | Growing datasets | Automatic switching capability |
Técnicas de Optimización del Rendimiento
Our local vector store needs specific tweaks to work at its best. The system's success depends on how well we manage and configure our resources.
Our tests show that vector stores need these optimizations:
-
Memory Management:
- Vectors should fit in available RAM for the best search speed
- Poor memory leads to slower imports
-
Query Optimization:
- Process multiple queries in batches
- Keep frequently used data in cache
-
Index Configuration:
- Tweak HNSW settings for better search quality
- Find the sweet spot between accuracy and speed
The system works best when we track important numbers like load latency and queries per second (QPS). These strategies help our local RAG system find similar vectors quickly while keeping data private and under our control.
Desplegando y Gestionando LLMs Locales
The right Local Language Model (LLM) deployment using LangChain needs a good look at several key factors. This section will walk you through everything you need to know about setting up a reliable local RAG system with LangChain.
Criterios de Selección de Modelos
Your hardware capabilities play a big role in choosing an LLM for LangChain integration. A simple calculation can help: multiply the model's parameter count (in billions) by two and add 20% overhead to find out how much GPU memory you need. To name just one example, see how a model with 11 billion parameters needs about 26.4GB of GPU memory.
| Model Size | Min. GPU Memory | Recommended GPU |
|---|
| 3-7B params | 16GB VRAM | RTX 4080 |
| 7-13B params | 32GB VRAM | A40 |
| 13B+ params | 40GB+ VRAM | A100 |
Mejores Prácticas de Despliegue
Our local RAG system with LangChain works best with these three deployment approaches:
- Containerization:
- Use Docker for consistent environments
- Enable GPU acceleration support
- Implement proper resource allocation
Quantization techniques can substantially reduce model size and maintain performance. Research shows that pruning can reduce model sizes by up to 90% while keeping 95% of original accuracy.
Estrategias de Gestión de Recursos
Good resource management and the right hardware are vital for peak performance in LangChain local LLM deployments. Small Language Models (SLMs) give you several advantages for edge deployment:
- Reduced computational load through quantization
- Lower memory requirements
- Enhanced energy efficiency
- Improved inference speed
Tools like vLLM or NVIDIA Triton Inference Server help with multi-user deployments. These solutions let you split large models across multiple GPUs with tensor parallelism. Some models, like the 90B parameter versions that need 216GB of GPU memory, work better with distributed inference strategies.
Here's how to get the most from your resources in a LangChain RAG system:
- Implement proper GPU memory management
- Use batch processing for multiple queries
- Enable Flash Attention when available
- Monitor system performance metrics
A structured approach to deployment and management will help you build a quick local RAG system with LangChain that keeps both performance and privacy intact. This method ensures you get reliable results for enterprise applications while using resources wisely.
Procesamiento de Datos y Pipeline de Embeddings
A well-built RAG system using LangChain demands careful attention to data processing and embedding generation. Let's look at how to create a resilient pipeline that will give both security and performance.
Flujo de Trabajo de Procesamiento de Documentos
The document processing pipeline starts with proper data preparation. Vector embeddings have become prime targets for data theft. Recent studies show attackers could recover exact inputs in 92% of cases. This leads us to implement a well-laid-out workflow:
-
Data Preparation:
- Text extraction and normalization
- Removal of irrelevant content
- Format standardization
-
Chunking Strategy:
- Optimal chunk size: 1200 characters
- Chunk overlap: 300 characters
For document loading, you can use LangChain's WebBaseLoader or other specialized loaders depending on your data sources.
Métodos de Generación de Embeddings
Effective embedding generation forms the core of our LangChain RAG system. These embeddings enable several advanced applications:
| Application Type | Purpose |
|---|
| Semantic Search | Meaning-based queries |
| Facial Recognition | Image processing |
| Voice Identification | Audio analysis |
| Recommendations | Content matching |
The model's quality directly affects embedding fidelity. Embeddings are machine representations of arbitrary data. We optimize our embedding generation by implementing property-preserving encryption, which allows for:
- Meaningful query matching
- Protected vector operations
- Secure similarity searches
For local embeddings, LangChain offers Ollama Embeddings, which can be used in conjunction with the Ollama library for efficient embedding generation.
Medidas de Control de Calidad
High standards in our RAG pipeline need complete quality control measures. Studies show that embedding quality substantially affects retrieval precision. Our quality assurance process has:
-
Data Validation:
- Input cleansing
- Format verification
- Consistency checks
-
Performance Monitoring:
- Retrieval precision tracking
- Recall measurement
- F1 score evaluation
Application-layer encryption (ALE) provides the best security for embeddings. This keeps data protected even when someone gets database credentials. These measures help us maintain security and performance while keeping sensitive data under control.
Optimización del Rendimiento y Monitoreo
Getting the best performance from our local RAG system with LangChain needs close attention to metrics, optimization, and monitoring. Let's look at how we can make our system work at its best while keeping data private.
Métricas de Rendimiento del Sistema
We need to track several key performance indicators to monitor system health. Our focus stays on three main metric categories:
| Metric Type | Description | Target Range |
|---|
| Latency | Response time per query | 100-500ms |
| Throughput | Requests handled per second | Based on cores |
| Resource Usage | CPU, memory, GPU utilization | 80% threshold |
These metrics help us spot bottlenecks and areas we can improve. We track both vector search performance and model inference speeds to keep the system running smoothly.
Técnicas de Optimización
We use several tested optimization strategies to boost our LangChain RAG system's performance. Our focus areas are:
-
Vector Search Optimization:
- Reduce vector dimensions (max 4096) to process faster
- Use pre-filtering to narrow search scope
- Set up dedicated search nodes for better performance
-
Resource Management:
- Set up separate search nodes to isolate workload
- Add enough RAM for vector data and indexes
- Use binary data vectors to save 3x storage
Our tests show that good vector quantization can cut storage needs while keeping search accuracy high. We suggest using scalar quantization for most embedding models because it keeps recall capabilities strong.
Configuración de Monitoreo y Alertas
Our monitoring setup spots and responds to performance issues early. We built strong monitoring systems that have:
-
Alert Configuration:
- Custom period-based alerts for specific events
- Up-to-the-minute matching alerts for critical issues
- Scheduled query-based notifications
-
Performance Tracking:
- System stability metrics
- Load monitoring to catch unusual patterns
- Cost tracking for each model interaction
We use automated metrics to make the assessment process smoother. These metrics answer complex questions about system performance, like how well rerankers work and how efficient our chunking techniques are.
The system needs regular checks of its components to work at its best. We run automated stress tests to see how well the system handles peak loads. Our monitoring also tracks performance over time, which shows us how changes in data sources and user behavior affect how well the system works.
These complete monitoring and optimization strategies help us maintain a RAG system that performs well and meets our needs while keeping data private and secure.
Conclusión
A local RAG system using LangChain just needs you to think over multiple technical aspects. The benefits make all this work worth it. Private AI solutions help organizations keep full control of sensitive data. They deliver powerful capabilities through local language models and LangChain-based RAG implementations.
Several factors determine your success. Good hardware specs are the foundations. Quick and accurate information retrieval comes from efficient vector stores. Local LLM deployment strategies work with secure data processing pipelines. Together, they will give you great performance and privacy protection.
The system's resource management plays a vital role in implementation. Good monitoring tools help maintain peak performance. Regular optimization and refinement keep everything running smoothly as data grows.
Organizations should begin their private AI journey with small steps. They need to test really well and grow based on how people actually use the system. This path helps spot problems early and will give you steady system growth.
Privacy requirements aren't limitations - they're chances to build more reliable AI systems. Local RAG implementations with LangChain show how organizations can use advanced AI without risking data security or losing operational independence.
Preguntas Frecuentes
Q1. What are the main advantages of building a RAG system with local data using LangChain?
Building a RAG system with local data using LangChain offers enhanced data privacy, reduced latency, customizable architectures, and independence from third-party services. It allows organizations to maintain complete control over sensitive information while leveraging advanced AI capabilities and LangChain's powerful tools for RAG development.
Q2. What are the key components needed to set up a local RAG system with LangChain?
The essential components for a local RAG system with LangChain include a robust development environment with Python 3.11 or higher, a vector store for efficient data storage and retrieval, a local language model (LLM) like LLaMA 3.1, and a data processing pipeline for document handling and embedding generation. LangChain provides tools like ChatOllama for local LLM integration and OllamaEmbeddings for local embedding generation.
Performance optimization in a LangChain-based local RAG system involves implementing efficient vector search techniques, proper resource management, and regular monitoring of key metrics such as latency, throughput, and resource usage. Techniques like vector quantization, pre-filtering, and task decomposition can significantly improve system efficiency. LangChain's tools like RunnablePassthrough and StrOutputParser can be used for optimizing the RAG pipeline.
Q4. What challenges might arise when implementing a local RAG system in an enterprise setting?
Common challenges include dealing with outdated or inconsistent documentation, limited capacity of subject matter experts for content cleanup, and the need for secure data handling within organizational network boundaries. Additionally, there may be hardware and software compatibility issues to address when deploying local LLMs and integrating LangChain components.
To improve data quality in a LangChain RAG system, organizations can implement content cleanup sprints, conduct subject matter expert interviews, use automated content quality scoring, and enrich metadata. It's also beneficial to establish a structured workflow for document processing using LangChain's tools like RecursiveCharacterTextSplitter for text splitting and implement quality control measures throughout the data pipeline. LangChain's document loaders and text splitters can be optimized for better chunking and context retrieval.