 Fuente de la Imagen: Pexels
Fuente de la Imagen: Pexels
El escalado del Aprendizaje por Refuerzo (RL) transforma la IA optimizando el rendimiento del modelo a través de estrategias de aprendizaje adaptativas. Aprovechando las leyes de escalado, el escalado de RL predice el comportamiento de modelos grandes a partir de experimentos a menor escala, permitiendo una utilización eficiente de los recursos. Por ejemplo, los modelos con mayores longitudes de memoria demuestran mejoras de rendimiento de hasta un 50% en comparación con los modelos de referencia.
La Generación Aumentada por Recuperación (RAG) mejora los sistemas de IA combinando la recuperación de datos con la generación de texto. Recupera información contextual de vastos repositorios de datos, asegurando que los resultados sigan siendo precisos y relevantes. Este enfoque mejora significativamente aplicaciones como la investigación profunda y la recuperación de conocimiento en tiempo real.
La integración de RAG y RL crea una sinergia poderosa. Sistemas como DeepResearcher lo demuestran, logrando tasas de finalización de tareas hasta 28.9 puntos más altas en comparación con los métodos tradicionales. Al combinar la recuperación de información contextual con la optimización de RL, los sistemas de IA ofrecen un rendimiento mejorado en diversos dominios.
Puntos Clave
- El escalado del Aprendizaje por Refuerzo (RL) ayuda a la IA a aprender mejor y más rápido.
- La Generación Aumentada por Recuperación (RAG) mezcla la búsqueda de datos con la creación de texto. Esto mantiene los resultados correctos y relevantes.
- Usar RAG con RL hace que los modelos funcionen mucho mejor. Puede reducir los errores en un 69% y mejorar la toma de decisiones.
- Para usar el escalado de RL con RAG, elige un modelo base. Luego, entrénalo con datos etiquetados y usa herramientas como Pinecone para encontrar datos rápidamente.
- Juntos, RAG y RL mejoran la IA en muchas áreas. Hacen más inteligentes el servicio al cliente, los motores de búsqueda y los sistemas de conocimiento.
Comprendiendo la Generación Aumentada por Recuperación (RAG)
 Fuente de la Imagen: Pexels
Fuente de la Imagen: Pexels
¿Qué es la Generación Aumentada por Recuperación?
La Generación Aumentada por Recuperación (RAG) representa un enfoque innovador en inteligencia artificial. Combina dos procesos esenciales: la recuperación de datos relevantes y la generación de resultados contextualmente precisos. A diferencia de los modelos generativos tradicionales, que dependen únicamente del conocimiento pre-entrenado, RAG integra la recuperación de información en tiempo real para mejorar sus respuestas. Este mecanismo dual asegura que los resultados no solo sean coherentes, sino que también estén fundamentados en datos factuales.
El concepto de RAG ganó prominencia a través de esfuerzos de investigación como el artículo de Lewis et al. de 2021, Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Trabajos fundacionales anteriores de Guu et al. introdujeron la idea de integrar la recuperación de conocimiento durante el pre-entrenamiento. Estos avances han convertido a RAG en una piedra angular en las aplicaciones modernas de IA, permitiendo que los sistemas ofrezcan resultados más autorizados y confiables.
Cómo RAG Combina Recuperación y Generación
RAG integra sin problemas la recuperación y la generación aprovechando sistemas de recuperación de información externos junto con grandes modelos de lenguaje (LLM). El proceso comienza con una fase de recuperación, donde el sistema busca datos relevantes de fuentes externas, como bases de datos o repositorios de conocimiento. Esta información recuperada sirve luego como entrada para la fase de generación, donde el modelo produce respuestas que son tanto contextualmente precisas como semánticamente ricas.
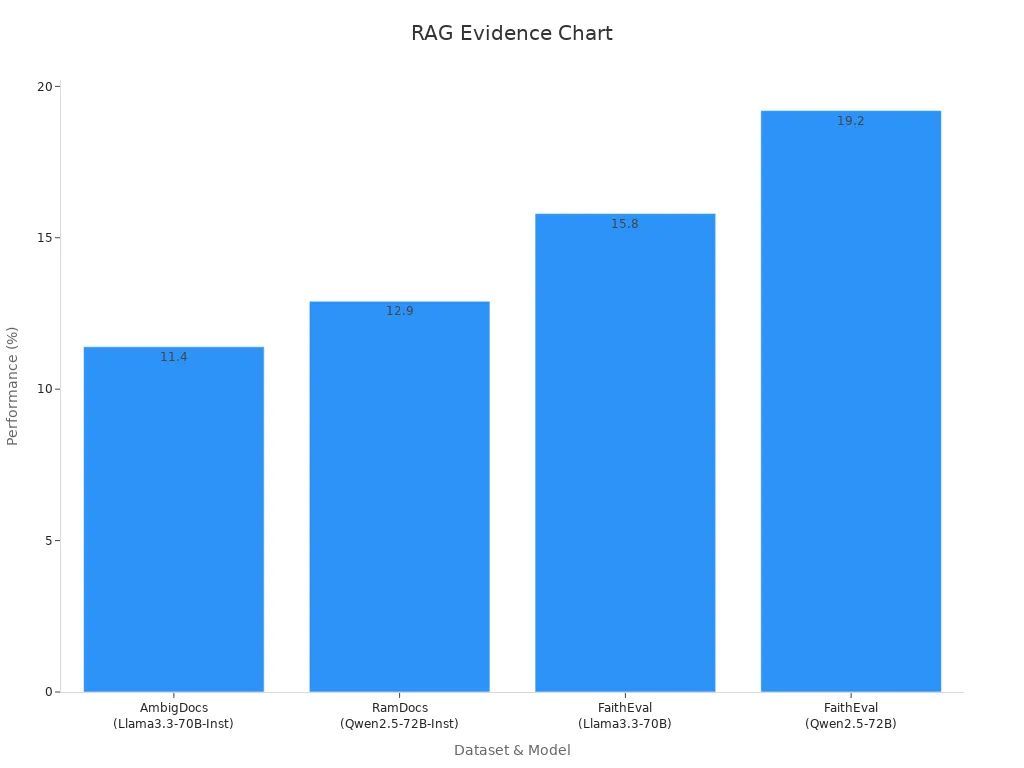
Por ejemplo, el modelo Madam-RAG demuestra cómo esta combinación mejora el rendimiento en varios conjuntos de datos:
| Modelo | Conjunto de Datos | Mejora de Rendimiento |
|---|
| Madam-RAG | AmbigDocs | +11.40% (Llama3.3-70B-Inst) |
| Madam-RAG | RamDocs | +12.90% (Qwen2.5-72B-Inst) |
| Madam-RAG | FaithEval | +15.80% (Llama3.3-70B) |
| Madam-RAG | FaithEval | +19.20% (Qwen2.5-72B) |
 Fuente de la Imagen: Pexels
Fuente de la Imagen: Pexels
Beneficios del Pipeline de RAG para la Mejora del Conocimiento
El pipeline de RAG ofrece numerosas ventajas para mejorar las tareas intensivas en conocimiento. Su capacidad para recuperar y generar información dinámicamente lo convierte en una herramienta versátil en todas las industrias. Los beneficios clave incluyen:
- Mejorar las Interacciones de Servicio al Cliente: RAG proporciona respuestas personalizadas y precisas, aumentando la satisfacción del cliente.
- Mejorar la Creación de Contenido y el Copywriting: Genera contenido atractivo y contextualmente relevante adaptado a audiencias específicas.
- Impulsar los Sistemas de E-learning y Tutoría Virtual: RAG crea entornos de aprendizaje interactivos al recuperar explicaciones adecuadas de bases de datos educativas.
- Revolucionar el Diagnóstico en Salud: Agiliza el diagnóstico al recuperar registros de salud relevantes, permitiendo consultas precisas y oportunas.
- Análisis de Comentarios de Clientes: RAG acelera el análisis de sentimientos al acceder a diversas fuentes de retroalimentación, ayudando a las empresas a refinar sus ofertas.
El impacto transformador de RAG se extiende más allá de estos casos de uso. Al fusionar la recuperación dinámica de conocimiento con la precisión generativa, RAG remodela las aplicaciones de IA en todas las industrias. Su capacidad para utilizar datos en tiempo real y conocimiento especializado mejora significativamente el rendimiento y la fiabilidad de los sistemas de IA. Las proyecciones indican que el mercado de RAG crecerá a $40.34 mil millones para 2035, con una tasa de crecimiento anual de aproximadamente el 35%. Este crecimiento subraya su papel crítico en abordar los problemas de alucinación de la IA y mejorar la relevancia del contenido.
Escalado de RL y su Importancia en la IA
¿Qué es el Escalado de RL?
El escalado de RL se refiere al proceso de mejorar los modelos de aprendizaje por refuerzo (RL) aumentando su capacidad para manejar tareas complejas. Implica escalar los recursos computacionales, las entradas de datos y las arquitecturas de los modelos para mejorar la eficiencia y adaptabilidad del aprendizaje. A diferencia de los métodos de escalado tradicionales, el escalado de RL enfatiza el aprendizaje activo a través de interacciones dinámicas y mecanismos de retroalimentación.
Los principios clave del escalado de RL incluyen:
- Aprendizaje por Refuerzo de Auto-juego (SPRL): Este método permite a los agentes aprender interactuando consigo mismos, fomentando el aprendizaje activo a través de la experiencia.
- El Ciclo de Aprendizaje: Los agentes observan su entorno, actúan, reciben retroalimentación y ajustan su comportamiento en un bucle continuo.
- Redefiniendo la Escalabilidad: Las nuevas leyes de escalado incorporan el costo computacional de la exploración, desafiando los métodos convencionales.
Estos principios destacan el potencial transformador del escalado de RL en el avance de los sistemas de IA.
Propósito del Escalado de RL en los Modelos de IA
El objetivo principal del escalado de RL es mejorar la eficiencia y adaptabilidad de los modelos de IA. Los métodos de escalado tradicionales a menudo luchan con dinámicas de entrenamiento inestables, lo que puede afectar el rendimiento. El escalado de RL aborda estos desafíos introduciendo mecanismos como las Mezclas Suaves de Expertos (MoEs). Estos mecanismos optimizan la asignación de recursos y mejoran los resultados del aprendizaje en diversos entornos de RL.
Estudios empíricos demuestran la efectividad del escalado de RL. Por ejemplo, el modelo Open Reasoner Zero alcanzó niveles de rendimiento comparables a los sistemas de RL especializados al aprovechar un modelo base. Esto subraya la importancia del escalado de RL para refinar los grandes modelos de lenguaje y asegurar que ofrezcan resultados precisos y confiables.
Beneficios de Combinar RAG y RL
La integración de RAG con RL crea un marco robusto para tareas intensivas en conocimiento. RAG mejora la recuperación de datos relevantes, mientras que RL optimiza el proceso de aprendizaje. Juntos, mejoran significativamente el rendimiento de los grandes modelos de lenguaje. Las pruebas han mostrado una reducción del 69% en la pérdida del modelo, disminuyendo de 0.32 a 0.1. Esta mejora asegura que los usuarios reciban información precisa y contextualmente precisa.
La combinación de RAG y RL también apoya los sistemas multi-agente. Estos sistemas permiten a los agentes colaborar, mejorando su capacidad para realizar investigaciones profundas y resolver problemas complejos. Al incorporar procesos de recuperación en los flujos de trabajo de RL, los sistemas de IA logran una mayor estabilidad y escalabilidad. Esta sinergia destaca la importancia de RAG para abordar las limitaciones de los métodos de RL tradicionales.
Guía Paso a Paso para el Escalado de RL Después de Usar RAG
 Fuente de la Imagen: Pexels
Fuente de la Imagen: Pexels
Prerrequisitos para el Escalado de RL con RAG
Antes de implementar el escalado de RL con RAG, se deben cumplir ciertos prerrequisitos para asegurar un flujo de trabajo fluido. Estos prerrequisitos incluyen:
- Un Modelo Base: Selecciona un modelo de lenguaje grande (LLM) fundamental capaz de manejar tareas de recuperación y generación. Modelos como Llama o Qwen se usan comúnmente debido a su adaptabilidad.
- Sistema de Recuperación de Conocimiento: Integra un sistema de recuperación robusto, como la base de datos vectorial Pinecone, para facilitar la búsqueda eficiente por similitud y la consulta dinámica del agente. Esto asegura la recuperación de datos relevantes para las tareas de generación.
- Conjunto de Datos Anotado: Prepara un conjunto de datos específico para la consulta, estructurado como cadenas de razonamiento. Este conjunto de datos sirve como base para el ajuste fino supervisado y la posterior alineación con RL.
- Selector de Conocimiento: Implementa un selector de conocimiento para filtrar la información recuperada. Esto se vuelve crítico cuando se trabaja con modelos generadores más débiles o tareas ambiguas.
- Colaboración Multi-Agente: Establece un sistema multi-agente para mejorar la escalabilidad y las capacidades de investigación profunda. Los agentes pueden colaborar para refinar los procesos de recuperación y generación.
Estos prerrequisitos sientan las bases para construir un agente RAG capaz de un escalado de RL eficiente.
Herramientas y Marcos para el Escalado de RL
Varias herramientas y marcos apoyan el escalado de RL, permitiendo una implementación y optimización eficientes. Las opciones clave incluyen:
- Base de Datos Vectorial Pinecone: Esta herramienta se especializa en la búsqueda eficiente por similitud, asegurando una rápida recuperación de datos relevantes. Desempeña un papel fundamental en la consulta de nuestro agente y en la mejora de la precisión de la recuperación.
- Marco VeRL: El marco VeRL de ByteDance proporciona un entorno robusto para el entrenamiento de RL. Apoya la integración de RAG y RL, permitiendo una alineación perfecta de los procesos de recuperación y generación.
- Algoritmos PPO Modificados: Los algoritmos de Optimización de Políticas Próximas (PPO), adaptados para el escalado de RL, mejoran la dinámica de aprendizaje y las tasas de convergencia. Estas modificaciones han sido evaluadas en entornos como los juegos de Atari y Box2D.
- Aprendizaje Multi-Tarea Contrastivo (CML): Esta técnica mejora la capacidad del modelo para diferenciar entre información relevante e irrelevante durante el entrenamiento. Complementa la alineación con RL al refinar el proceso de recuperación.
| Modelo | Precisión Promedio (%) | Mejora (%) |
|---|
| ToRL-1.5B | 48.5 | - |
| Qwen2.5-Math-1.5B-Instruct | 35.9 | - |
| Qwen2.5-Math-1.5B-Instruct-TIR | 41.3 | - |
| ToRL-7B | 62.1 | 14.7 |
Estas herramientas y marcos proporcionan la infraestructura necesaria para escalar RL de manera eficiente mientras se aprovecha RAG.
Pasos de Implementación para el Escalado de RL
Implementar el escalado de RL después de aplicar RAG implica un enfoque estructurado. Sigue estos pasos para asegurar un rendimiento óptimo:
- Recopilación de Datos: Reúne un conjunto de datos anotado específico para la consulta, estructurado como cadenas de razonamiento. Este conjunto de datos forma la base para el ajuste fino supervisado.
- Ajuste Fino Supervisado (SFT): Entrena el modelo base usando el conjunto de datos recopilado. Este paso mejora las capacidades de recuperación y generación del modelo.
- Aprendizaje Multi-Tarea Contrastivo (CML): Refina la capacidad del modelo para distinguir entre información relevante e irrelevante. Este paso mejora la precisión de la recuperación y la calidad de la generación.
- Alineación con RL: Ajusta finamente el modelo usando técnicas de aprendizaje por refuerzo. Alinea sus resultados con los resultados deseados basándose en mecanismos de retroalimentación.
- Integración con Pinecone: Conecta el modelo a la base de datos vectorial Pinecone para una búsqueda eficiente por similitud. Esta integración asegura una recuperación rápida y precisa durante las tareas de generación.
- Colaboración Multi-Agente: Despliega un sistema multi-agente para mejorar la escalabilidad y las capacidades de investigación profunda. Los agentes colaboran para optimizar los flujos de trabajo de recuperación y generación.
- Monitoreo del Rendimiento: Monitorea continuamente el rendimiento del modelo usando métricas como Knowledge F1 y la precisión de la recuperación. Ajusta los parámetros de entrenamiento para mantener la eficiencia.
Consejo: Mezclar conocimiento verificado con conocimiento distractor durante el entrenamiento puede simular diversos resultados de selección, mejorando la adaptabilidad del modelo.
Siguiendo estos pasos, los desarrolladores pueden implementar con éxito el escalado de RL con RAG, logrando un rendimiento y escalabilidad mejorados en los sistemas de IA.
Ajuste Fino y Optimización en el Pipeline de RAG
El ajuste fino y la optimización juegan un papel crítico en la mejora del rendimiento de los modelos dentro del pipeline de RAG. Estos procesos refinan la capacidad del modelo para recuperar y generar resultados precisos y contextualmente relevantes. Sin embargo, lograr resultados óptimos requiere una planificación y ejecución cuidadosas para evitar posibles escollos.
Desafíos en el Ajuste Fino del Pipeline de RAG
El ajuste fino dentro del pipeline de RAG a menudo encuentra desafíos que pueden impactar el rendimiento del modelo. Por ejemplo, aumentar el tamaño de la muestra durante el ajuste fino no siempre conduce a mejores resultados. Los estudios han demostrado que tamaños de muestra más grandes pueden reducir tanto la precisión como la completitud. En un experimento, la precisión del modelo Mixtral cayó de 4.04 a 3.28 cuando el tamaño de la muestra aumentó de 500 a 1000. Esto destaca la necesidad de un enfoque equilibrado para el ajuste fino, donde la calidad de los datos tiene prioridad sobre la cantidad.
Otro desafío implica mantener la capacidad del modelo para generalizar en diversas tareas. El sobreajuste a conjuntos de datos específicos durante el ajuste fino puede limitar la adaptabilidad del modelo. Esto es particularmente problemático в aplicaciones intensivas en conocimiento, donde el pipeline de RAG debe manejar una amplia gama de consultas y contextos.
Estrategias para un Ajuste Fino Efectivo
Para abordar estos desafíos, los desarrolladores pueden adoptar varias estrategias:
- Muestreo Selectivo de Datos: En lugar de usar grandes conjuntos de datos indiscriminadamente, enfócate en muestras de alta calidad y anotadas que se alineen con las tareas objetivo del modelo. Este enfoque minimiza el riesgo de degradación del rendimiento.
- Ajuste Fino Incremental: Ajusta gradualmente el modelo en etapas más pequeñas, permitiéndole adaptarse sin sobrecargar su capacidad de aprendizaje. Este método ayuda a mantener un equilibrio entre especialización y generalización.
- Mezcla de Conocimiento: Incorpora una mezcla de conocimiento de referencia (gold-standard) e información distractora durante el entrenamiento. Esta técnica mejora la capacidad del modelo para diferenciar entre datos relevantes e irrelevantes, mejorando la precisión de la recuperación.
Técnicas de Optimización para el Pipeline de RAG
La optimización asegura que el pipeline de RAG opere de manera eficiente y ofrezca resultados consistentes. Las técnicas clave incluyen:
- Mecanismos de Recuperación Dinámicos: La implementación de sistemas de recuperación en tiempo real permite al modelo acceder a información actualizada. Esto es particularmente útil en aplicaciones como la investigación profunda, donde el conocimiento evoluciona rápidamente.
- Colaboración Multi-Agente: El despliegue de múltiples agentes dentro del pipeline de RAG mejora la escalabilidad y la especialización de tareas. Cada agente puede enfocarse en aspectos específicos de la recuperación o generación, mejorando el rendimiento general del sistema.
- Aprendizaje Multi-Tarea Contrastivo (CML): Esta técnica refina la capacidad del modelo para priorizar información relevante durante el entrenamiento. Al contrastar recuperaciones correctas e incorrectas, CML agudiza las capacidades de toma de decisiones del modelo.
Consejo: Monitorea regularmente las métricas de rendimiento como la precisión de la recuperación y las puntuaciones Knowledge F1. Ajusta los parámetros de entrenamiento basándote en estas métricas para mantener un rendimiento óptimo.
Al combinar el ajuste fino con estrategias de optimización robustas, el pipeline de RAG puede lograr un rendimiento superior en tareas intensivas en conocimiento. Estos métodos aseguran que el pipeline permanezca adaptable, preciso y eficiente, incluso a medida que aumenta la complejidad de sus aplicaciones.
Aplicaciones Prácticas de RAG y RL
Mejorando los Chatbots de Soporte al Cliente
Los chatbots de soporte al cliente impulsados por RAG y RL ofrecen respuestas precisas y contextualmente relevantes. Al integrar mecanismos de recuperación, estos chatbots acceden a datos en tiempo real para abordar las consultas de los usuarios de manera efectiva. El aprendizaje por refuerzo optimiza aún más su rendimiento al alinear las respuestas con las preferencias y la retroalimentación de los usuarios. Esta combinación asegura que los chatbots proporcionen información precisa mientras mejoran la satisfacción del usuario.
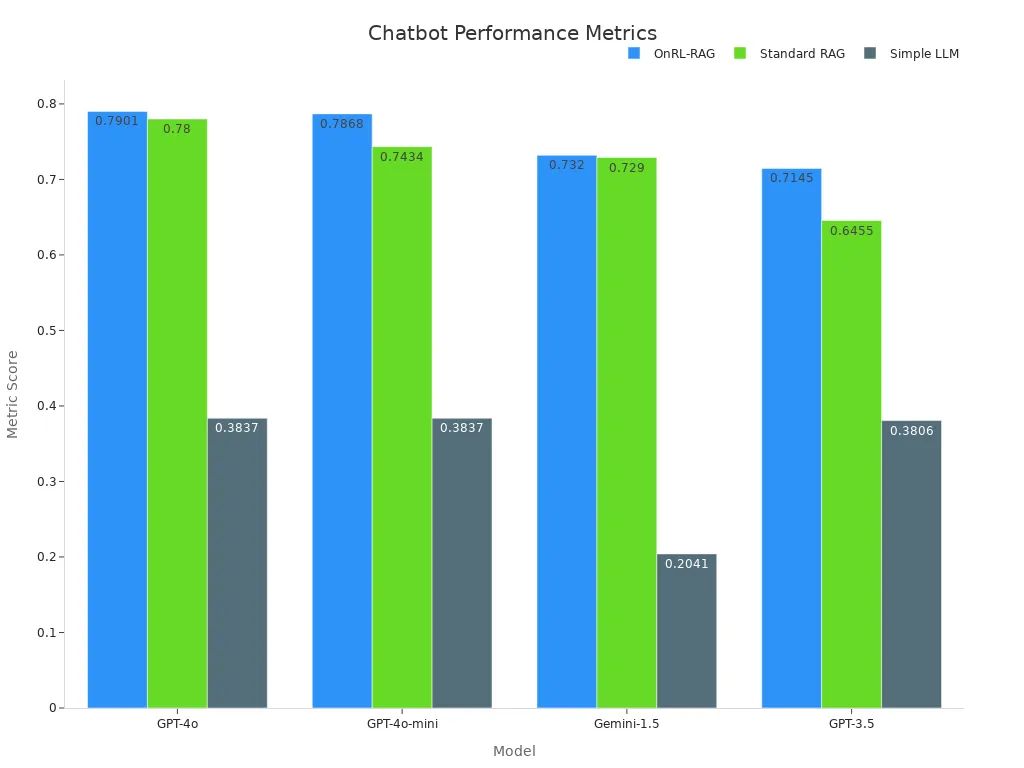
Estudios empíricos destacan la efectividad de este enfoque. Por ejemplo, el marco OnRL-RAG supera consistentemente al RAG estándar y a los LLM simples en varios modelos. La siguiente tabla ilustra las métricas de rendimiento:
| Modelo | OnRL-RAG | RAG Estándar | LLM Simple |
|---|
| GPT-4o | 0.7901 | 0.7800 | 0.3837 |
| GPT-4o-mini | 0.7868 | 0.7434 | 0.3837 |
| Gemini-1.5 | 0.7320 | 0.7290 | 0.2041 |
| GPT-3.5 | 0.7145 | 0.6455 | 0.3806 |
 Fuente de la Imagen: Pexels
Fuente de la Imagen: Pexels
Los chatbots de retail que usan RAG y RL también mejoran la eficiencia operativa al reducir los tiempos de respuesta. Estos sistemas se adaptan dinámicamente a las necesidades del usuario, asegurando una experiencia de cliente fluida.
Mejorando los Motores de Búsqueda con RAG y RL
Los motores de búsqueda se benefician significativamente de la integración de RAG y RL. RAG mejora el proceso de recuperación al acceder a datos relevantes de vastos repositorios, mientras que RL optimiza los algoritmos de búsqueda para mejorar la precisión y relevancia. Esta sinergia permite a los motores de búsqueda ofrecer resultados precisos, incluso para consultas complejas.
El marco ReZero ejemplifica esta mejora. Recompensa la persistencia en los intentos de búsqueda, logrando una precisión máxima del 46.88%, en comparación con una línea base del 25%. La siguiente tabla destaca este rendimiento:
| Modelo | Precisión (%) | Línea Base (%) |
|---|
| Modelo ReZero | 46.88 | 25.00 |
Al aprovechar RL, los motores de búsqueda refinan sus algoritmos para priorizar la intención del usuario. Este enfoque asegura que los usuarios reciban la información más relevante, mejorando su experiencia general. Además, herramientas como Pinecone facilitan la recuperación eficiente, permitiendo a los motores de búsqueda manejar consultas de datos a gran escala con facilidad.
Sistemas de Gestión del Conocimiento en Empresas
Las empresas dependen de los sistemas de gestión del conocimiento para optimizar las operaciones y mejorar la toma de decisiones. RAG y RL mejoran estos sistemas al permitir la recuperación y generación dinámica de información. RAG recupera datos relevantes de fuentes internas y externas, mientras que RL alinea los resultados con los objetivos organizacionales.
Por ejemplo, el asistente digital de un banco importante usa RAG para obtener información regulatoria, asegurando el cumplimiento y mejorando las interacciones con los clientes. De manera similar, las organizaciones de salud utilizan sistemas RAG para acceder a guías médicas e investigaciones, mejorando el apoyo a la decisión clínica. Pinecone juega un papel crucial en estas aplicaciones al permitir una búsqueda y recuperación eficientes por similitud.
La colaboración multi-agente mejora aún más la escalabilidad en los sistemas empresariales. Los agentes trabajan juntos para refinar los procesos de recuperación y generación, asegurando que los usuarios reciban insights precisos y accionables. Este enfoque transforma la gestión del conocimiento, haciéndola más adaptativa y eficiente.
La integración del escalado de RL con RAG transforma los sistemas de IA al mejorar su precisión, robustez y adaptabilidad. Esta sinergia permite a los modelos recuperar conocimiento en tiempo real, mejorando la toma de decisiones y el rendimiento en diversas tareas. Por ejemplo:
| Beneficio Clave | Descripción |
|---|
| Precisión Mejorada | Mayor precisión en la recuperación de datos y la generación de respuestas. |
| Robustez | Mayor resiliencia de los sistemas de IA en entornos dinámicos. |
| Capacidades de Generalización | Mejor rendimiento en diversos conjuntos de datos y tareas complejas. |
Consejo: Explora el escalado de RL para desbloquear todo el potencial de tus modelos de IA. La combinación de RAG con RL ofrece un marco poderoso para aplicaciones intensivas en conocimiento.
FAQ
¿Cuál es la diferencia entre RAG y el escalado de RL?
RAG recupera datos relevantes y genera resultados contextualmente precisos. El escalado de RL optimiza los modelos de IA mejorando su eficiencia y adaptabilidad de aprendizaje. Juntos, mejoran el rendimiento combinando la recuperación de conocimiento en tiempo real con el aprendizaje por refuerzo para una mejor toma de decisiones.
¿Se puede usar RAG con cualquier modelo base?
Sí, RAG funciona con la mayoría de los grandes modelos de lenguaje (LLM). Las opciones populares incluyen Llama y Qwen debido a su adaptabilidad. Los desarrolladores deben asegurarse de que el modelo base admita tareas de recuperación y generación para una integración perfecta.
¿Cómo mejora el escalado de RL los sistemas de IA?
El escalado de RL mejora los sistemas de IA al refinar su proceso de aprendizaje. Utiliza mecanismos de retroalimentación dinámicos para alinear los resultados con los objetivos deseados. Este enfoque mejora la precisión, la estabilidad y la escalabilidad, especialmente en entornos complejos.
¿Qué herramientas son esenciales para implementar RAG y RL?
Las herramientas clave incluyen Pinecone para una recuperación de datos eficiente, VeRL para el entrenamiento de RL y algoritmos PPO modificados para la optimización. Estas herramientas agilizan los flujos de trabajo y aseguran un alto rendimiento durante el escalado.
¿Son necesarios los sistemas multi-agente para el escalado de RL?
Los sistemas multi-agente no son obligatorios, pero sí muy beneficiosos. Mejoran la escalabilidad y la especialización de tareas. Los agentes colaboran para refinar los procesos de recuperación y generación, mejorando la eficiencia general del sistema.