Integración Profunda de Agentes IA y Aprendizaje por Refuerzo: De la Separación a la Revolución
10 de septiembre de 2025Ollie @puppyone
Observación Central: La primera ola de desarrollo de agentes IA se basó principalmente en ingeniería de prompts y tuvo poca conexión con el aprendizaje por refuerzo (RL) tradicional. Sin embargo, investigaciones recientes indican que el RL se está convirtiendo ahora en la fuerza motriz central que impulsa a los agentes hacia la inteligencia general. Basado en investigación de vanguardia de mayo a agosto de 2025, este reporte revela tres tendencias de integración principales.
Innovación de Paradigma en RL de Agente Único
De RLHF a RLVR: Avances en Diseño de Recompensas Objetivas
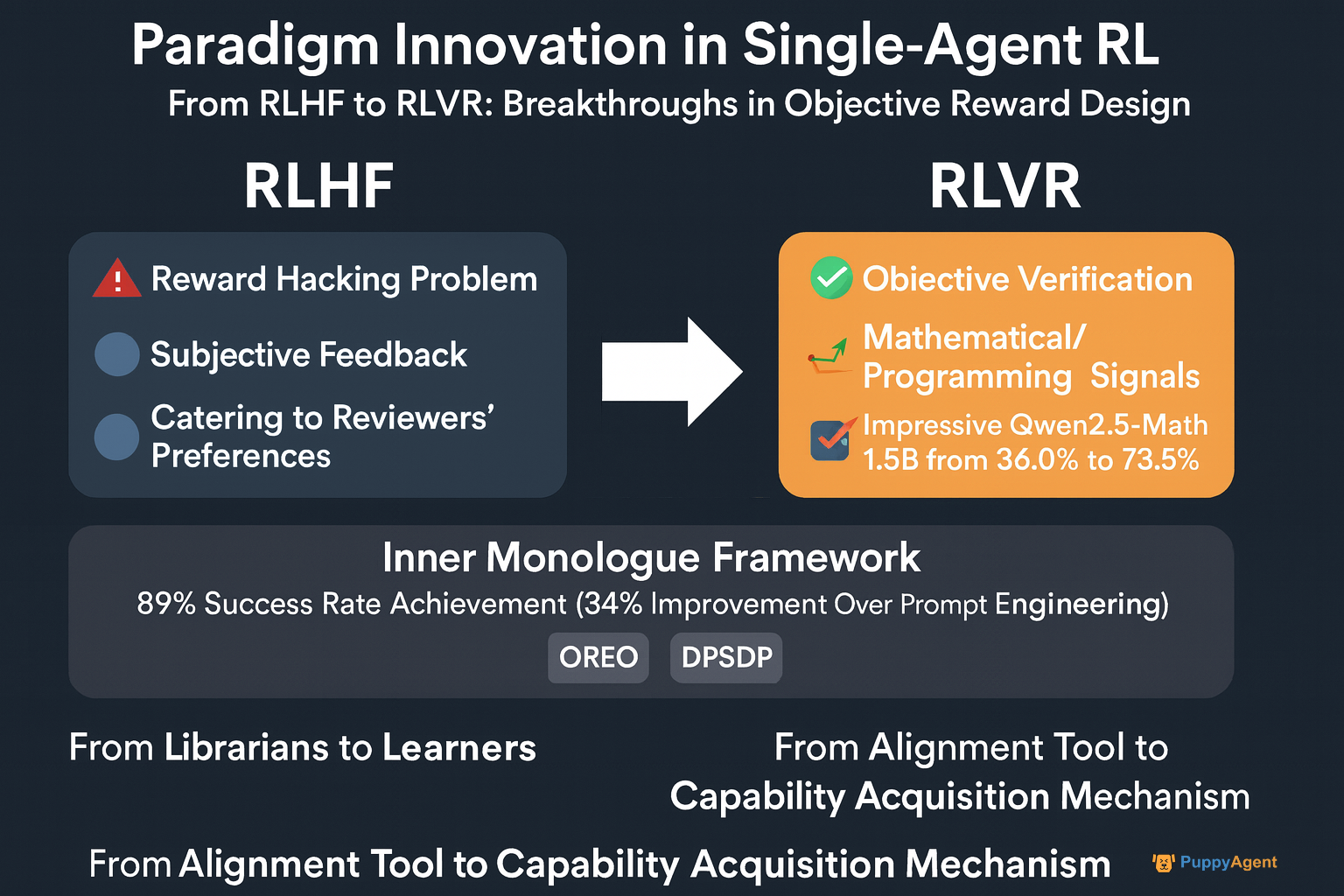
El RLHF tradicional (Aprendizaje por Refuerzo con Retroalimentación Humana) depende de retroalimentación humana subjetiva y sufre del problema de "hackeo de recompensas". En ICML 2024, el investigador de OpenAI John Schulman declaró francamente: "Descubrimos que los modelos aprenden a complacer las preferencias de los revisores en lugar de resolver genuinamente los problemas". Esto ha impulsado un cambio hacia RLVR (Aprendizaje por Refuerzo con Recompensas Verificables), aprovechando señales objetivas y verificables de dominios como matemáticas y programación. El equipo Qwen de Alibaba aplicó este enfoque para aumentar la precisión de Qwen2.5-Math-1.5B en el benchmark MATH500 de 36.0% a 73.6%, demostrando que el RL está evolucionando de una "herramienta de alineación" a un "mecanismo de adquisición de capacidades".
El profesor Sergey Levine de UC Berkeley observó: "Estamos presenciando una transformación fundamental. Los primeros agentes eran como bibliotecarios con vastas memorias; ahora, buscamos convertirlos en aprendices genuinos". El marco Inner Monologue de su equipo ejemplifica este cambio — los agentes desarrollan un "monólogo interno" a través de retroalimentación de bucle cerrado con su entorno, logrando una tasa de éxito del 89% en tareas de navegación robótica — 34% más alta que los métodos puros de ingeniería de prompts. Mientras tanto, el algoritmo OREO de DeepMind mejora el razonamiento multi-paso optimizando la ecuación de Bellman, mientras que DPSDP proporciona capacidades de búsqueda directa de políticas para sistemas multiagente.
Inteligencia Encarnada e Integración Multiagente
Avances Prácticos en Inteligencia Encarnada
La profesora Daniela Rus del MIT comentó en una entrevista: "Finalmente estamos presenciando un salto cualitativo en la inteligencia robótica". Se refería al rendimiento revolucionario del marco LLaRP — un sistema que integra modelos de lenguaje grandes con aprendizaje por refuerzo — que logró una tasa de éxito del 42% en 1,000 tareas encarnadas previamente no vistas, 1.7x más alta que las líneas base tradicionales. Aún más notable, requiere entrenar solo un pequeño número de decodificadores de percepción y acción para transformar un LLM congelado en una política de propósito general.
Linxi Fan, científico investigador en NVIDIA, comentó: "El proyecto Eureka ha remodelado completamente nuestro entendimiento del diseño de recompensas". En este proyecto, GPT-4 genera automáticamente código de funciones de recompensa para aprendizaje por refuerzo; en tareas complejas de manipulación de brazos robóticos, las funciones de recompensa generadas por IA realmente superaron a aquellas meticulosamente creadas por expertos humanos. De manera similar, el equipo de robótica de Google DeepMind ha logrado avances en este camino — su sistema RT-2, basado en un modelo visión-lenguaje-acción, permite a los robots comprender instrucciones complejas en lenguaje natural y ejecutar las acciones correspondientes.
Evolución de la Colaboración Multiagente
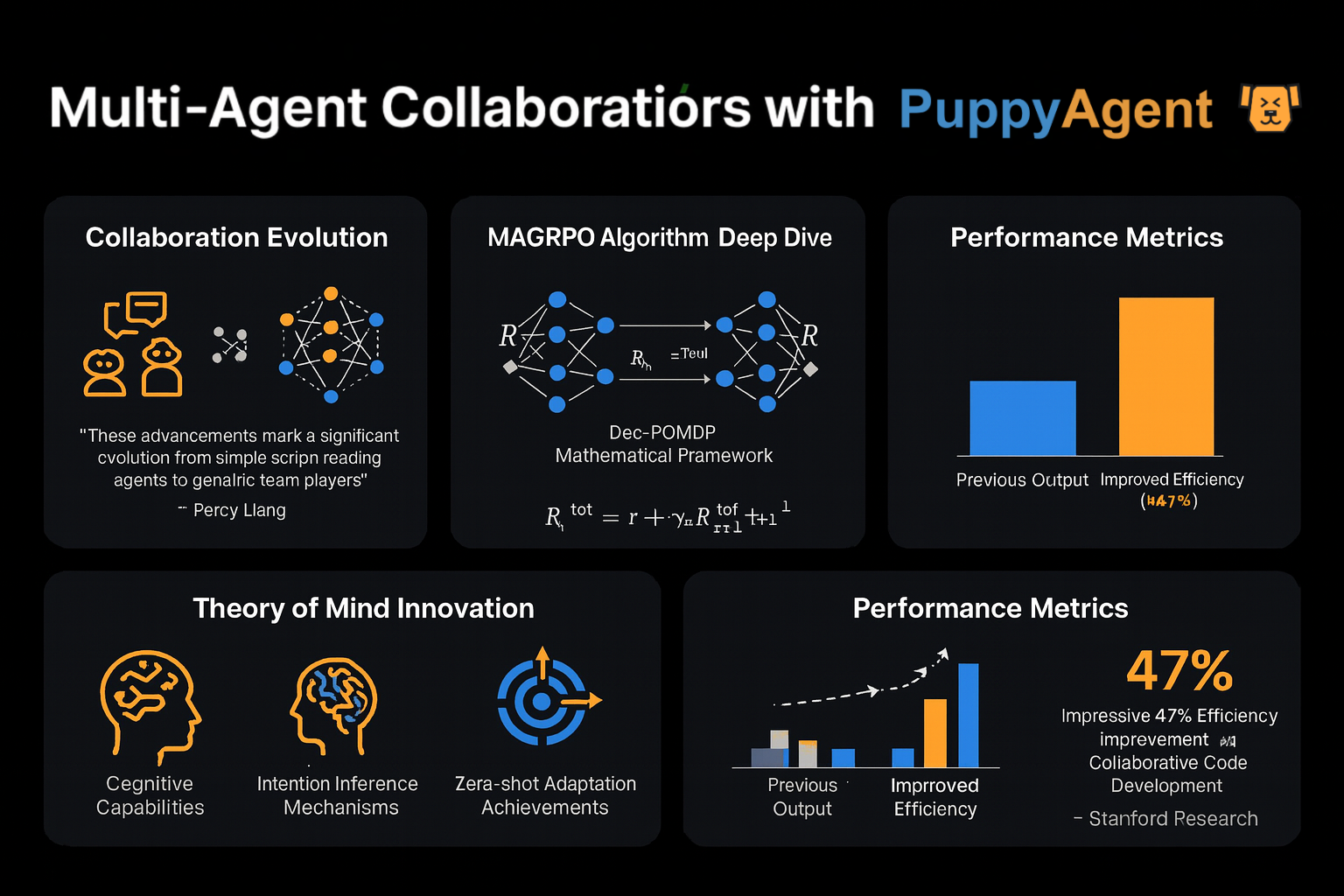
El profesor Percy Liang de Stanford observó: "Los primeros debates multiagente eran como varias personas leyendo guiones independientemente — ahora estamos viendo trabajo en equipo genuino". El algoritmo MAGRPO más reciente modela la colaboración de LLM como un Dec-POMDP (Proceso de Decisión de Markov Parcialmente Observable Descentralizado) y logra cooperación verdadera a través de optimización conjunta de recompensas. En pruebas de desarrollo colaborativo de código, este enfoque mejoró la eficiencia en un 47% comparado con métodos tradicionales de diálogo multi-turno. Aún más intrigante, otro equipo de Stanford equipó a los agentes con un módulo de "Teoría de la Mente", permitiéndoles inferir las intenciones y estrategias de otros participantes — demostrando capacidades adaptativas notables en entornos de juego de cero disparos.
Cambio en las Tendencias Académicas
Enfoque de las Principales Conferencias
El cambio en las tendencias académicas es inconfundible. El tutorial "IA Generativa se Encuentra con Aprendizaje por Refuerzo" en ICML 2025 atrajo más de 2,000 asistentes; su ponente, la profesora Chelsea Finn, abrió con: "Si aún dependes puramente de ingeniería de prompts, probablemente ya te estés quedando atrás". ACL 2025, organizando su inaugural taller "REALM", colocó el entrenamiento de agentes basado en RL en el centro de su agenda — recibiendo tres veces el número esperado de envíos de artículos. ICLR 2025 mostró múltiples avances, incluyendo el marco de código abierto Agent S, que opera computadoras como un humano y logra niveles sin precedentes de automatización en tareas complejas.
Más notablemente, el taller "Agentes de Mundo Abierto" en NeurIPS 2024 presentó una conferencia magistral de Yann LeCun, quien enfatizó: "La recuperación estática de conocimiento ya no es suficiente — lo que necesitamos son agentes capaces de aprendizaje continuo y adaptación en entornos abiertos". Esta perspectiva resonó ampliamente entre los asistentes; durante una discusión de mesa redonda, múltiples laureados del Premio Turing acordaron unánimemente que el aprendizaje por refuerzo ofrece el camino más prometedor para abordar los desafíos centrales de la inteligencia artificial general.
Desafíos y Oportunidades
Desafíos del Mundo Real y Oportunidades Industriales
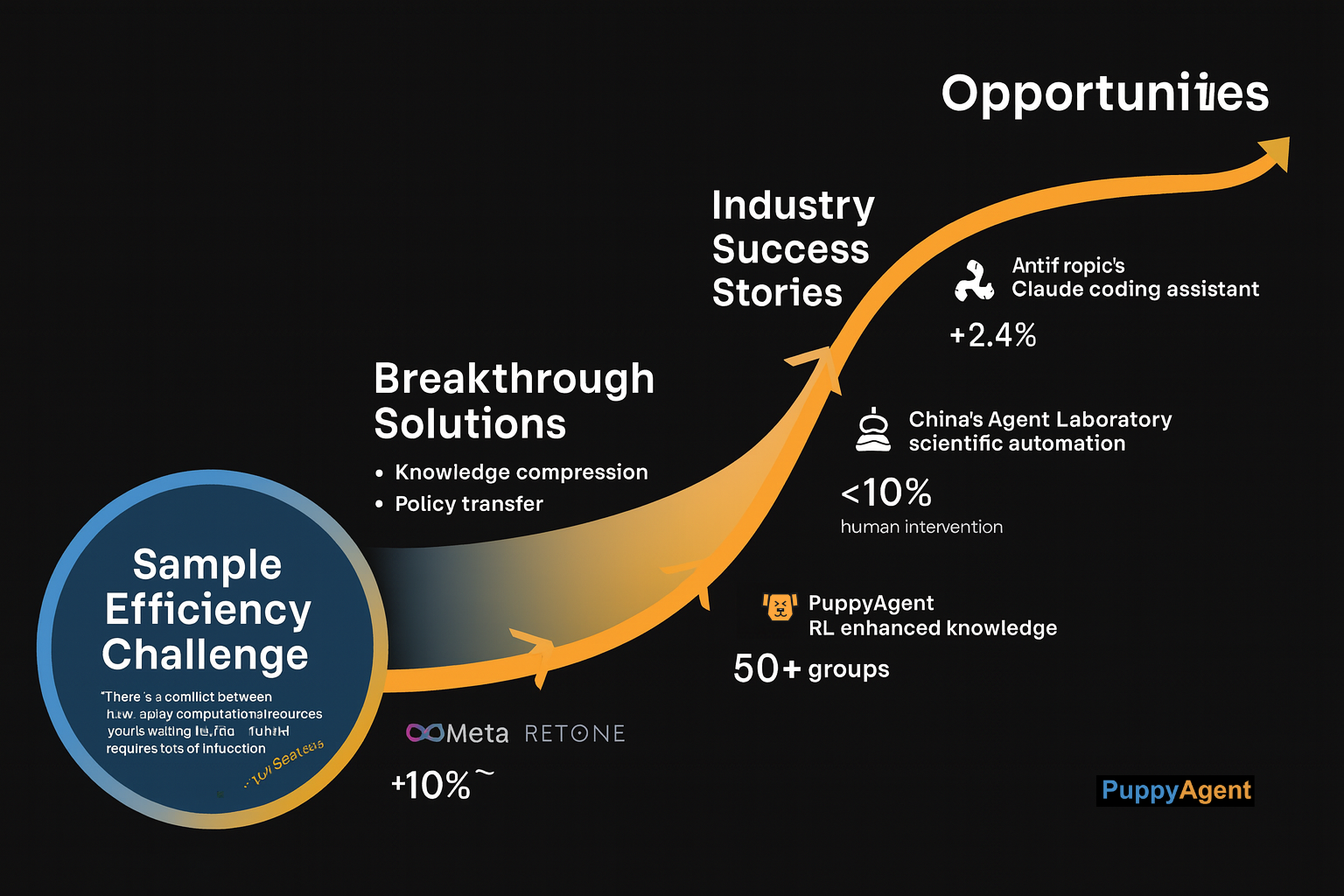
Por supuesto, persisten desafíos significativos. En su último discurso público antes de dejar OpenAI, Ilya Sutskever admitió francamente: "Nuestra mayor dificultad radica en la eficiencia de muestras. Cada inferencia de LLM consume recursos computacionales masivos, mientras que el RL tradicional requiere millones de interacciones". Esta contradicción está impulsando soluciones novedosas — por ejemplo, el equipo de investigación de Meta ha desarrollado un método de "aprendizaje basado en destilación" que comprime conocimiento de modelos grandes en otros más pequeños para entrenamiento RL, luego transfiere las políticas aprendidas de vuelta a los modelos grandes.
La respuesta de la industria ha sido igualmente rápida. El equipo Claude de Anthropic actualmente está probando en beta un asistente de codificación impulsado por RL; personas internas revelan que su rendimiento en tareas de programación complejas es "asombroso". Mientras tanto, el proyecto Agent Laboratory de China ya ha logrado automatización de extremo a extremo de flujos de trabajo de investigación científica — desde revisión de literatura y diseño experimental hasta escritura de artículos — requiriendo menos del 10% de intervención humana. Esta tendencia de automatización está permeando rápidamente más dominios verticales. En gestión del conocimiento, por ejemplo, sistemas inteligentes de bases de conocimiento como puppyone están comenzando a aplicar mecanismos de aprendizaje por refuerzo a la comprensión de documentos, extracción de conocimiento y respuesta automática de preguntas. Al aprender continuamente de los patrones de consulta de usuarios y retroalimentación, tales sistemas pueden optimizar iterativamente sus estrategias de organización y recuperación de conocimiento — transformándose de repositorios pasivos de información en asistentes inteligentes proactivos. La plataforma de código abierto AIRSTONE lanzada por Shenzhen AIRS proporciona soporte computacional sin precedentes para investigación de inteligencia encarnada, y ya está siendo usada por más de 50 grupos de investigación internacionales.
Conclusión

La separación entre Agentes y RL ciertamente existía — pero como el profesor Tommi Jaakkola del MIT lo expresó acertadamente, "Esto es como el internet temprano que tenía solo páginas web estáticas; la interacción dinámica es el verdadero futuro". Estamos presenciando un cambio fundamental: del razonamiento estático basado en conocimiento pre-entrenado a la optimización dinámica a través del aprendizaje continuo de la experiencia. RLVR permite a los Agentes adquirir habilidades difíciles como razonamiento matemático; LLaRP demuestra generalización entre escenarios; y los sistemas multiagente basados en MARL revelan la emergencia de inteligencia colaborativa genuina.
Como el fundador de DeepMind Demis Hassabis declaró recientemente: "El aprendizaje por refuerzo no es meramente un método de entrenamiento — es el mecanismo central de la inteligencia misma". Esta disciplina una vez "descuidada", con sus profundos insights sobre aprendizaje de prueba y error, optimización de políticas y adaptación ambiental, ahora se está convirtiendo en la base teórica más sólida para el viaje de los Agentes hacia la inteligencia artificial general. Esta convergencia no es un simple apilamiento de tecnologías — es una revolución impulsada por la cognición y alimentada por la ciencia fundamental.
Referencias Clave: Tutorial ICML 2025, Taller ACL 2025 REALM, Reporte Técnico Qwen2.5-Math, Artículo LLaRP, Algoritmo MAGRPO, Inner Monologue, y otras investigaciones más recientes