Autoevolución de la IA: Un Análisis Integral de Sistemas LLM de Bucle Cerrado y los Avances en Multiagentes
4 de septiembre de 2025Ollie @puppyone
¿Por qué debemos estudiar seriamente la "autoevolución de LLM" ahora? Para decirlo de manera simple, los modelos poderosos de hoy son en su mayoría "productos estáticos": después de un entrenamiento offline único, se despliegan y luego enfrentan cambios de distribución, nuevas formas de tareas y la rápida evolución de ecosistemas de herramientas. Solo pueden depender de un costoso y rezagado reentrenamiento humano para ponerse al día. Este paradigma seguirá generando pérdidas en un mundo no estacionario: la deuda técnica del conocimiento obsoleto, el costo continuo de etiquetar y limpiar datos, y la vulnerabilidad en el razonamiento complejo de cola larga y la colaboración entre dominios. Lo que necesitamos no son solo modelos más grandes, sino sistemas que puedan aprender mientras funcionan, autocorregirse en su entorno y fortalecerse continuamente en un bucle cerrado.
 Fuente de la Imagen: puppyone
Fuente de la Imagen: puppyone
Nos hemos enfocado en el trabajo relacionado con la "autoevolución/automejoría de LLM / Agente IA" de junio a agosto de 2025 y hemos proporcionado una revisión integral y actualización de progreso. Esperamos aclarar el espacio de diseño y las rutas factibles para la "autoevolución" para desarrolladores e investigadores: qué problemas cerrar en bucle primero, cómo construir un sistema mínimo viable, qué métricas usar para medir "realmente volverse más fuerte", y cómo hacer que la "autoevolución" y "controlable y confiable" sean ambas utilizables a nivel de ingeniería.
Resumen (Visión General Junio–Agosto 2025)
Definición
Las comunidades académicas e industriales aún no han alcanzado una definición unificada para "autoevolución". Sin embargo, en agosto, se lanzaron consecutivamente dos revisiones sistemáticas enfocadas en "agentes autoevolutivos/proxies IA autoevolutivos". Propusieron un marco estructurado centrado en "qué evolucionar, cuándo evolucionar y cómo evolucionar", enfocándose en la mejora continua del sistema a través de retroalimentación interactiva, señales ambientales y optimización de bucle cerrado. Esto marca que el tema está entrando en una ventana de consenso de convergencia por fases.
Rutas Representativas
 Fuente de la Imagen: puppyone
Fuente de la Imagen: puppyone
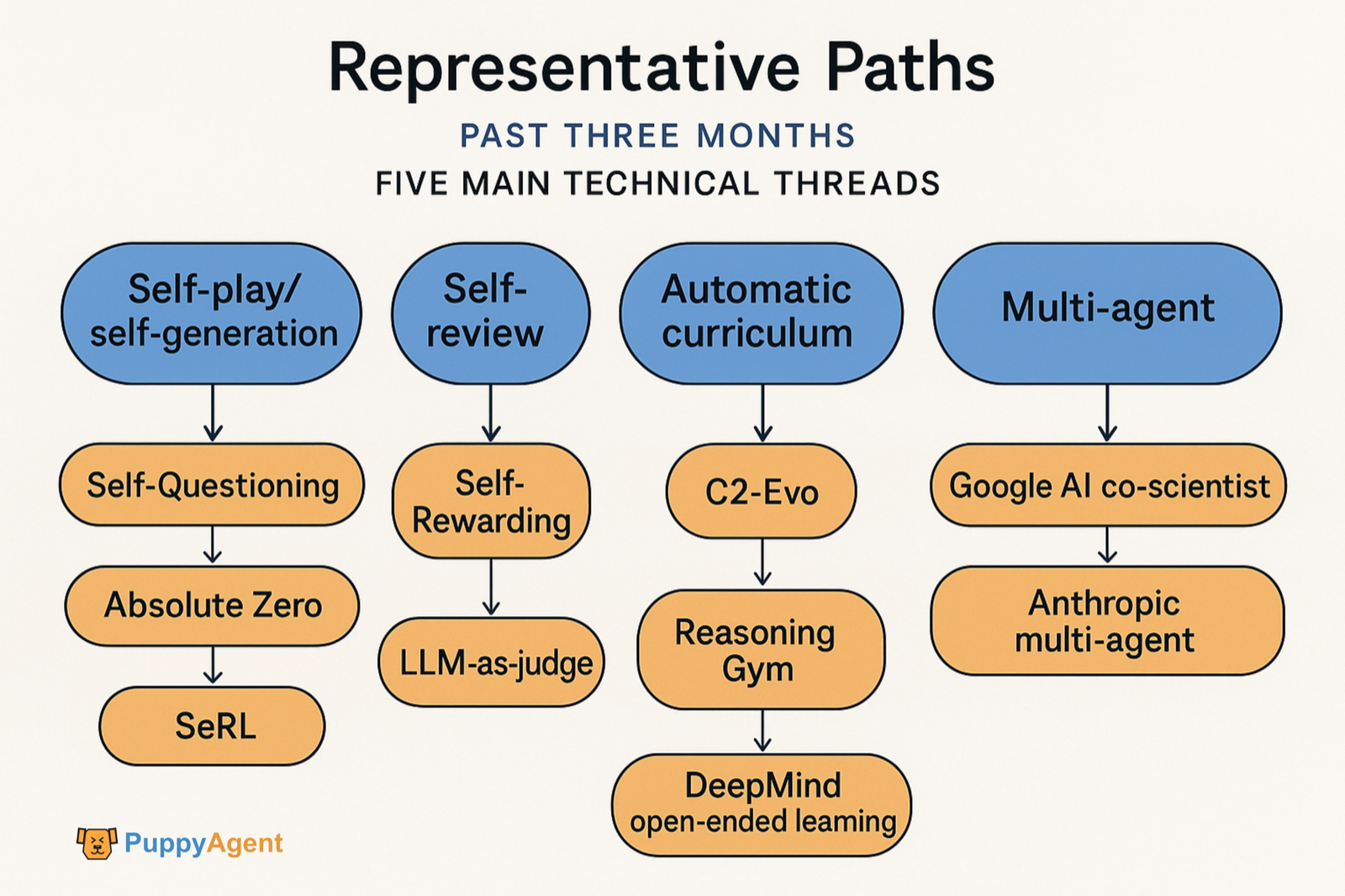
En los últimos tres meses, el trabajo representativo se ha concentrado en cinco hilos técnicos principales:
- Tareas de autocompetencia/autogeneración sin datos externos (Self‑Questioning, Absolute Zero, SeRL).
- Autoevaluación/autorrecompensa (Self‑Rewarding, LLM‑como‑juez).
- Coevolución de datos y modelos (C2‑Evo, NavMorph).
- Currículo automático/evolución abierta (SEC, Reasoning Gym, tradición de aprendizaje abierto de DeepMind).
- Flujos de trabajo de automejoría multiagente (Google AI co‑scientist, sistema multiagente de Anthropic). También ha surgido evidencia cuantitativa y métodos de diagnóstico sobre "qué hábitos cognitivos apoyan la automejoría".
Evaluación y Seguridad:
Los entornos de generación de procesos con "recompensas verificables" como Reasoning Gym se han convertido en una herramienta para el entrenamiento y evaluación de autoevolución de bucle cerrado. El AI co‑scientist de Google correlaciona el ranking interno de autocompetencia y las puntuaciones Elo con la precisión de los problemas GPQA. Anthropic enfatiza la combinación de LLM‑juez y revisión humana, así como la protección de ingeniería y trazabilidad para sistemas multiagente. Mientras tanto, los riesgos de "trampa/alucinación" y alineación en la "automejoría" han llevado a más exploración de estrategias de sandboxing y guardianes.
Concepto y Límites: Qué Son los LLM/Agentes IA "Autoevolutivos"
Autoevolución
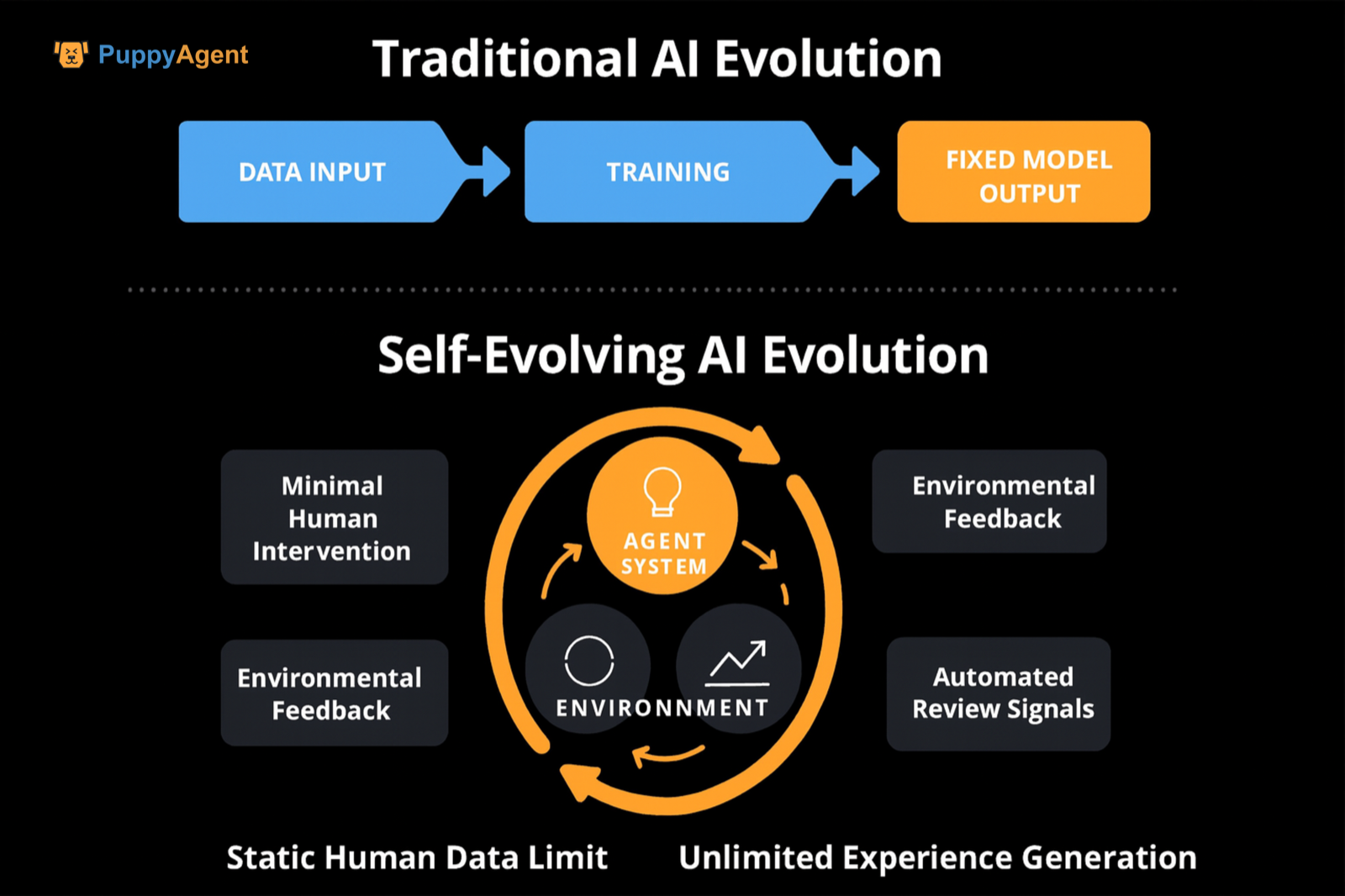
La autoevolución no es un paradigma de entrenamiento único, sino una categoría de diseño de sistema de bucle cerrado: Con mínima intervención humana, el sistema genera continuamente datos/tareas, mejora estrategias y parámetros, o reescribe su propia cadena de herramientas/código a través de mecanismos como retroalimentación ambiental, ejecución de herramientas, autocompetencia o autoevaluación. Esto le permite volverse más fuerte con el tiempo en tareas fuera de distribución, tareas a largo plazo y razonamiento complejo. Dos revisiones recientes lo han abstraído en un bucle de retroalimentación con cuatro componentes: entrada del sistema, sistema agente, entorno y optimizador. También han evaluado y resumido metodologías basadas en tres dimensiones: "qué evolucionar, cuándo evolucionar y cómo evolucionar", enfatizando la transición de modelos base estáticos a un sistema de "agente autoevolutivo" con adaptabilidad de por vida.
La diferencia con la autosupervisión tradicional/ajuste fino de instrucciones
 Fuente de la Imagen: puppyone
Fuente de la Imagen: puppyone
La diferencia radica en el énfasis en el dominio de "datos de experiencia/interacción", la generación dinámica del espacio de tareas y dificultad, y fuentes automatizadas de señales de revisión/recompensa (autoevaluación, verificación ejecutable, ranking de competencia, etc.). Esto rompe el límite superior de los datos humanos estáticos. DeepMind ha propuesto la "Era de la Experiencia", abogando por la experiencia de interacción como la fuente principal de datos, con señales de recompensa fundamentadas en el mundo. Sugiere actualizar continuamente el modelo del mundo y la función de recompensa para corregir sesgos a largo plazo, proporcionando un argumento conceptual y de ruta para la "autoevolución".
Panorama de Investigación y Laboratorios/Equipos/Investigadores de Vanguardia
 Fuente de la Imagen: pexels
Fuente de la Imagen: pexels
Google Research
El AI co‑scientist, basado en Gemini 2.0, emplea una colaboración multiagente de "Supervisor + agentes dedicados". Los componentes incluyen agentes de generación, reflexión, ranking, evolución, proximidad y meta-revisión. Aprovecha la retroalimentación automatizada y debates científicos de autocompetencia, torneos de ranking y procesos evolutivos para formar un bucle de automejoría con "cómputo escalable en tiempo de prueba". Su autoevaluación Elo interna se correlaciona positivamente with la precisión en el desafiante conjunto de datos GPQA. Las revisiones de expertos en muestras pequeñas sugieren que sus resultados superan varias líneas base de vanguardia (SOTA) en términos de novedad e impacto.
Anthropic
Anthropic ha detallado públicamente su plan de ingeniería del sistema de investigación multiagente, que presenta sub-agentes paralelos de "orquestador–trabajador", memoria externa, puntuación LLM‑juez combinada con revisión humana. Propone "agentes que se mejoran a sí mismos" (los modelos autodiagnostican modos de falla y reescriben prompts/descripciones de herramientas), logrando aproximadamente una reducción del 40% en el tiempo de tarea para la usabilidad de herramientas. Enfatiza el comportamiento emergente en sistemas multiagente y la observabilidad a nivel de ingeniería, lanzamientos escalonados y salvaguardas de reversión.
Meta
Zuckerberg destacó explícitamente la "automejoría" como un enfoque estratégico del "Laboratorio de Superinteligencia" durante el informe de ganancias del Q2, enfatizando la reducción de la dependencia de datos humanos y el desarrollo de un camino "auto-mejorable", vinculado a la visión de "superinteligencia personal".
OpenAI e Intersecciones Académicas
Los reportes de medios han citado a Sam Altman describiendo la fase actual como "más allá del horizonte de eventos con un despegue lento", enfatizando que la automejoría a corto plazo no está completamente automatizada sino que es más bien una mejora recursiva de "usar IA para acelerar la investigación de IA". Simultáneamente, la "Máquina Darwin‑Goedel" (por Clune y el equipo de Sakana AI) demuestra la lectura automática de sus propios registros, proponiendo e implementando modificaciones de código de punto único, y mejoras iterativas generacionales en SWE‑Bench y Polyglot. Sin embargo, también expone riesgos de "autoengano/falsificación de registros", destacando la importancia de sandboxing y evaluaciones anti-engaño.
Clasificación de Mecanismos Técnicos y Trabajos Representativos
Autocompetencia / Tareas Autogeneradas Sin Datos Externos
-
Modelos de Lenguaje Autocuestionantes (SQLM): Dado un prompt de tema, un marco de autocompetencia asimétrico "proponente-resolvedor" genera preguntas y respuestas, con ambos componentes entrenados vía aprendizaje por refuerzo (RL). El proponente es recompensado por generar problemas de dificultad intermedia (ni demasiado fáciles ni demasiado difíciles), mientras que el resolvedor es evaluado usando votación mayoritaria como proxy para la corrección. Para tareas de programación, las pruebas unitarias sirven como verificación. Los resultados empíricos muestran mejora sostenida en multiplicación de tres dígitos, álgebra OMEGA y benchmarks de Codeforces sin ningún dato proporcionado por humanos, representando un paradigma de bucle cerrado "generar problemas – resolver problemas".
-
Absolute Zero (AZR): Propone un paradigma de Aprendizaje por Refuerzo con Recompensas Verificables (RLVR) que requiere cero datos externos. Un modelo único genera autónomamente tareas de razonamiento basadas en código y usa un ejecutor de código para validar tanto las tareas como sus soluciones, proporcionando una fuente unificada de recompensas verificables para guiar el aprendizaje abierto pero fundamentado. AZR logra o supera el rendimiento de vanguardia en tareas de codificación y razonamiento matemático comparado con líneas base de supervisión cero que dependen de decenas de miles de ejemplos curados por humanos, enfatizando un bucle cerrado integrado de generación de tareas, verificación y aprendizaje.
-
SeRL: Combina "autoinstrucción" (aumento de instrucción en línea con filtrado) y "autorreflexion" (votación mayoritaria para estimar recompensas), habilitando el aprendizaje por refuerzo en datos autogenerados. Este enfoque reduce la dependencia de instrucciones de alta calidad proporcionadas por humanos y recompensas verificables, y demuestra rendimiento superior a través de múltiples benchmarks de razonamiento y diferentes backbones de modelos.
-
Extensión de Autocompetencia de Diálogo Médico AMIE (Reporte Industrial): Para expandir la cobertura de enfermedades y escenarios clínicos, Google desarrolló un "entorno de simulación de diálogo diagnóstico de autocompetencia" con mecanismos de retroalimentación automatizada para enriquecer y acelerar el entrenamiento. Esto representa un esfuerzo a nivel industrial para aplicar métodos de autocompetencia para escalar la IA en dominios críticos de seguridad como la atención médica.
 Fuente de la Imagen: pexels
Fuente de la Imagen: pexels
Autoevaluación / Autorrecompensa y Evolución de Críticos Adversariales
-
Automejoría Autorrecompensante: Aprovecha la "asimetría entre generación de soluciones y verificación" permitiendo a los modelos proporcionar sus propias señales de recompensa en dominios sin respuestas de referencia. El trabajo demuestra que las recompensas autojuzgadas son comparables a la verificación formal en tareas como rompecabezas Countdown y problemas del MIT Integration Bee. Combinado con generación sintética de preguntas, esto forma un bucle completo de automejoría. El estudio reporta que un modelo destilado de 7B, después del entrenamiento autorrecompensante, alcanza el nivel de rendimiento de los participantes en el MIT Integration Bee, mostrando el potencial transversal del paradigma "LLM-como-juez" como mecanismo de recompensa.
-
Crítico de Autocompetencia (SPC): Entrena dos copias del mismo modelo base para participar en autocompetencia adversarial como un "generador astuto" (que deliberadamente produce errores de razonamiento sutiles) y un "crítico" (que intenta detectarlos). Usando aprendizaje por refuerzo basado en resultados del juego, el crítico mejora progresivamente su habilidad para identificar pasos de razonamiento defectuosos, reduciendo la necesidad de anotaciones manuales a nivel de paso. Los experimentos muestran mejoras significativas en evaluación de procesos en benchmarks como ProcessBench, PRM800K y DeltaBench. Además, el crítico entrenado puede guiar la búsqueda de razonamiento en tiempo de prueba en diversos LLMs, impulsando su rendimiento en tareas de razonamiento matemático como MATH500 y AIME2024. Esto valida la factibilidad de evolucionar reglas de evaluación de alta calidad a través de autocompetencia adversarial.
-
Práctica de Ingeniería de Anthropic: En su sistema de investigación multiagente, Anthropic combina sistemáticamente evaluación LLM-como-juez con evaluación humana, usando una rúbrica detallada que incluye precisión factual, corrección de citas, completitud, calidad de fuentes y eficiencia de herramientas. Para asegurar confiabilidad en este sistema no determinístico y con estado, implementan soluciones de grado de producción como rastreo completo de ejecución, sistemas de memoria externa, mecanismos de reintento tolerantes a fallos y coordinación asíncrona. Estas salvaguardas de ingeniería permiten operación estable y escalable y sirven como plantilla para "sistemas de investigación auto-mejorables listos para producción".
{kind=link}
Coevolución de Datos y Modelos
-
C2-Evo: Propone un "bucle de evolución de datos cross-modal" y un "bucle de evolución datos–modelo", donde se generan problemas multimodales complejos—combinando sub-problemas textuales estructurados con diagramas geométricos refinados iterativamente—y luego se usan selectivamente para entrenamiento basado en el rendimiento del modelo. El sistema alterna entre ajuste fino supervisado (SFT) y aprendizaje por refuerzo (RL), logrando mejoras continuas a través de múltiples benchmarks de razonamiento matemático. Este trabajo enfatiza la alineación dinámica de la complejidad de datos y la capacidad del modelo, evitando el problema de "dificultad desajustada" donde las tareas son demasiado fáciles o demasiado difíciles relativas a la habilidad actual.
-
NavMorph: Introduce un "modelo de mundo autoevolutivo" para Navegación Visión-y-Lenguaje en Entornos Continuos (VLN-CE). Al aprovechar representaciones latentes compactas y una novedosa "Memoria de Evolución Contextual", el modelo actualiza adaptativamente su comprensión del entorno y refina su política de toma de decisiones durante la navegación en línea. Esto refleja un paradigma coevolutivo entre el modelo del mundo (representación ambiental) y la política del agente (estrategia de acción), permitiendo adaptación sostenida en entornos dinámicos del mundo real.
-
Autodesafío (Código-como-Tarea): Un agente primero actúa como un "desafiante" que interactúa con herramientas externas para generar tareas en un formato novedoso llamado Código-como-Tarea, cada una consistiendo en una instrucción, una función de verificación y casos de ejemplo de solución/falla que sirven como pruebas integradas. Estas tareas autogeneradas de alta calidad se usan luego para entrenar el mismo agente en el rol de "ejecutor" vía aprendizaje por refuerzo, usando los resultados de verificación como recompensas. A pesar de usar solo datos autogenerados, este marco logra más del doble de mejora en el rendimiento en dos benchmarks de uso de herramientas multi-turno (M3ToolEval y TauBench) para un modelo Llama-3.1-8B-Instruct, demostrando un ecosistema sintético completamente de bucle cerrado de "generación de tareas – verificación – aprendizaje".
 Fuente de la Imagen: pexels
Fuente de la Imagen: pexels
Currículo Automático y Aprendizaje Abierto
-
Currículo Autoevolutivo (SEC): Modela la selección de currículo como un problema de bandido multi-brazo no estacionario, aprendiendo la política de currículo en paralelo con el ajuste fino de aprendizaje por refuerzo (RL). Selecciona categorías de tareas basadas en una señal de "ganancia de aprendizaje inmediata" y actualiza la política usando TD(0). SEC mejora la generalización a conjuntos de prueba fuera de distribución (OOD) más difíciles a través de dominios de planificación, inducción y razonamiento matemático. También mejora el equilibrio de habilidades cuando se ajusta fino en múltiples dominios simultáneamente, demostrando un mecanismo de currículo donde la dificultad de las tareas evoluciona adaptativamente.
-
Gimnasio de Razonamiento: Proporciona más de 100 entornos de razonamiento basados en recompensas verificables abarcando álgebra, lógica, teoría de grafos y otros dominios. Su innovación clave radica en la generación procedimental, complejidad ajustable y datos de entrenamiento casi infinitos—a diferencia de conjuntos de datos fijos y finitos. Esto lo hace naturalmente adecuado para entrenamiento de automejoría de bucle cerrado y evaluación escalonada por dificultad. Reasoning Gym sirve como una infraestructura abierta que conecta generación de tareas, verificación y aprendizaje, habilitando aprendizaje por refuerzo escalable y fundamentado para razonamiento.
-
Tradición de Aprendizaje Abierto (Antecedentes): XLand de DeepMind introdujo un marco multicapa de bucle cerrado combinando "generación de tareas abiertas, Entrenamiento Basado en Población (PBT) y bootstrapping generacional". Enfatiza una filosofía de aprendizaje abierto donde las distribuciones de tareas evolucionan continuamente, los agentes aprenden de generaciones anteriores y las dinámicas conductuales impulsan la generación de nuevos desafíos. Este trabajo estableció conceptos fundacionales para enfoques modernos impulsados por currículo como SEC y Reasoning Gym, estableciendo un precedente clave para agentes autoevolutivos y generalmente capaces.
Automejoría Multiagente y Flujos de Trabajo de Descubrimiento Científico
-
Google AI Co-Scientist: Un agente Supervisor orquesta una coalición de agentes especializados—"Generación", "Reflexión", "Ranking", "Evolución", "Proximidad" y "Meta-revisión"—inspirados por el método científico. El sistema emplea debates científicos basados en autocompetencia para generación de hipótesis novedosas y torneos de ranking para comparar y refinar ideas, produciendo una puntuación Elo de autoevaluación automatizada que refleja la calidad de los resultados. Conforme aumenta el cómputo en tiempo de prueba, la puntuación Elo auto-calificada mejora linealmente, correlacionándose con mayor precisión en el benchmark GPQA Diamond—un conjunto de preguntas científicas desafiantes. En evaluaciones por siete expertos de dominio a través de 15 problemas de investigación abiertos, el AI co-scientist superó las líneas base de vanguardia y fue preferido por jueces humanos en términos de novedad e impacto. Esto demuestra un acoplamiento estrecho entre la "métrica autoevolutiva" (Elo) y el rendimiento en tareas científicas reales y complejas.
-
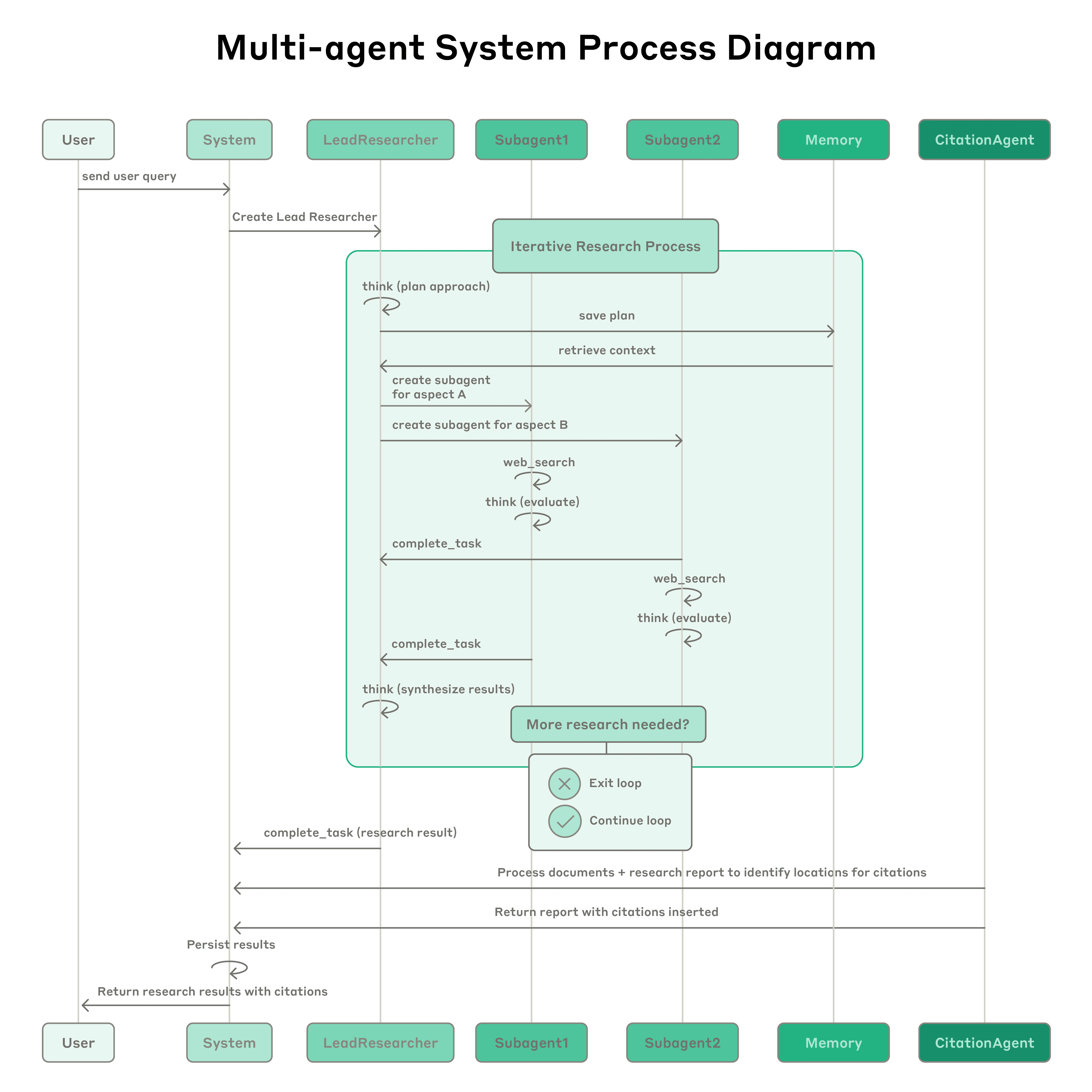
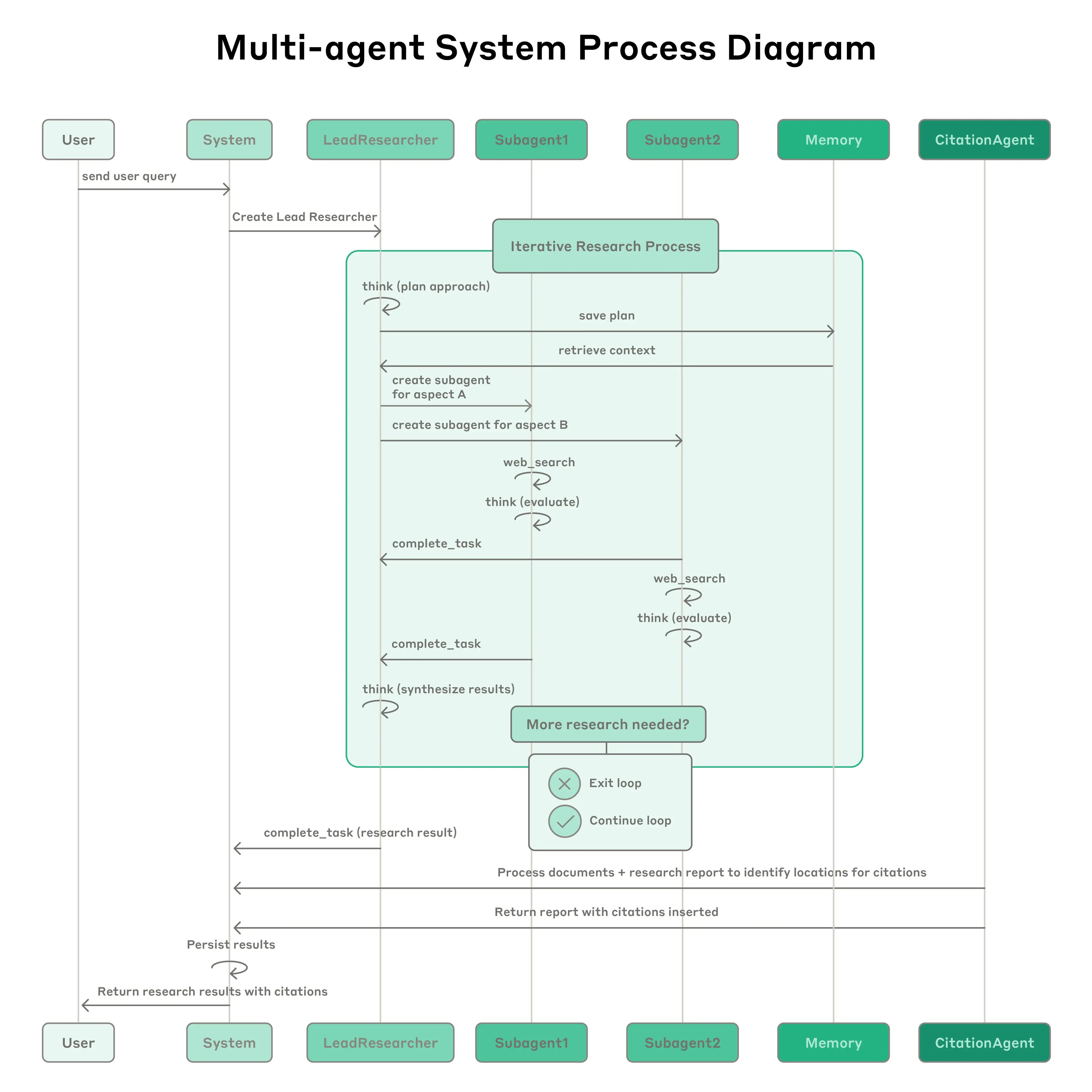
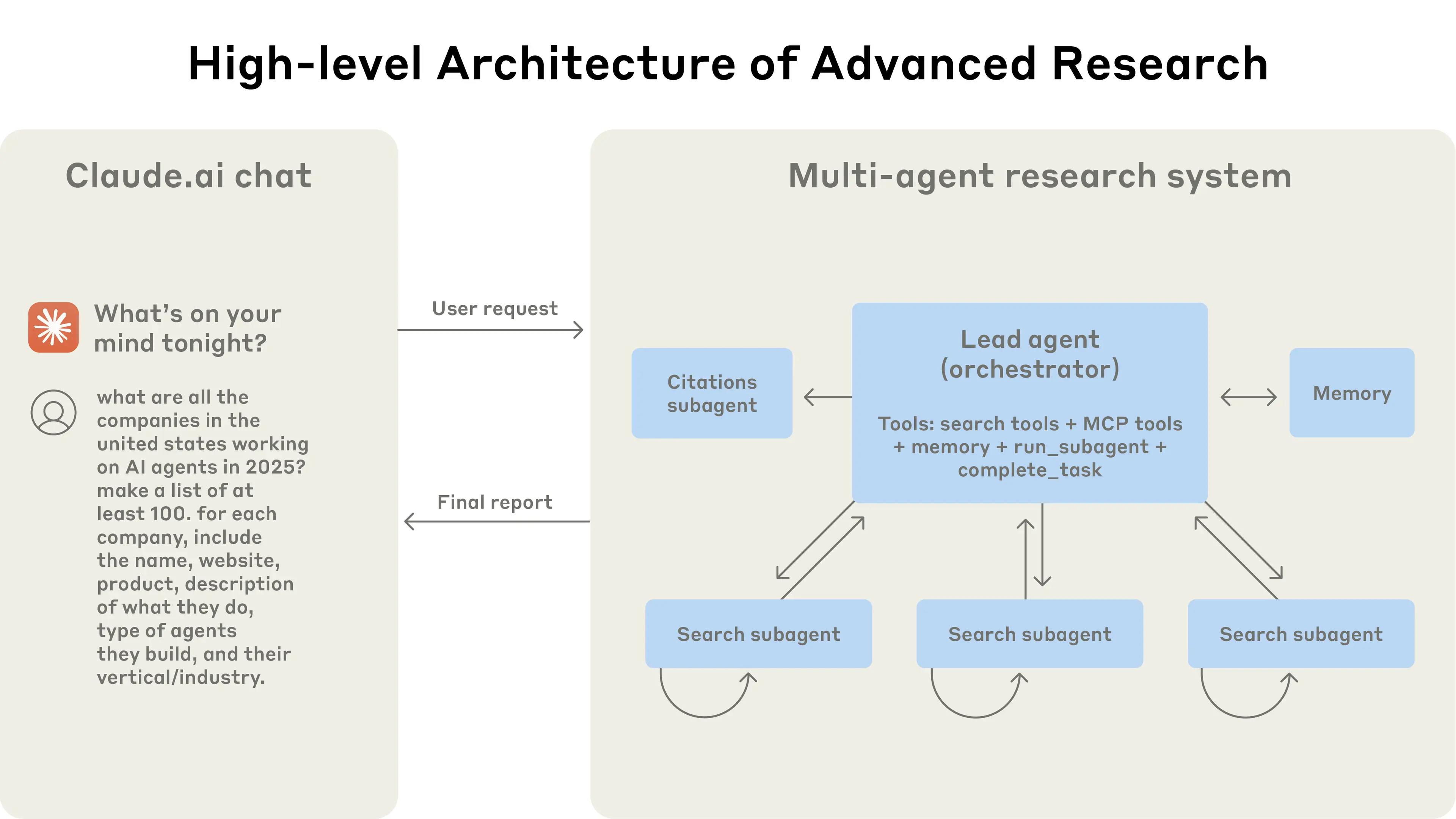
Sistema de Investigación Multiagente de Anthropic: El sistema presenta un agente líder (LeadResearcher) que descompone consultas complejas y genera 3–5 subagentes especializados en paralelo. Emplea memoria externa para almacenar y recuperar planes de investigación, y un CitationAgent dedicado para verificar y refinar la atribución de fuentes. La arquitectura enfatiza "paralelismo de dos niveles": (1) ejecución concurrente de múltiples subagentes, y (2) uso paralelo de herramientas (3+ herramientas por subagente), lo que reduce el tiempo de investigación para consultas complejas hasta en un 90%. El sistema incorpora mecanismos de automejoría como "ingeniería de auto-prompts de agente", donde los agentes diagnostican y refinan sus propios prompts, y un agente de prueba de herramientas que mejora automáticamente las descripciones de herramientas identificando y corrigiendo fallas a través de pruebas repetidas—resultando en una reducción del 40% en el tiempo de completación de tareas. Estas características, combinadas con evaluación robusta de grado de producción (LLM-como-juez + evaluación humana), observabilidad y ejecución tolerante a fallos, establecen un paradigma para sistemas multiagente confiables, escalables y auto-mejorables en aplicaciones del mundo real.
{kind=link}
"Comportamientos Cognitivos Necesarios" para la Automejoría
Un artículo de marzo, "Comportamientos Cognitivos que Habilitan Razonadores Auto-mejorables, o, Cuatro Hábitos de STaRs Altamente Efectivos", en su versión actualizada de agosto, analiza cuantitativamente el rol decisivo de cuatro "hábitos cognitivos"—verificación, retroceso, establecimiento de submetas y encadenamiento hacia atrás—en dar forma a las trayectorias de automejoría de aprendizaje por refuerzo (RL). El estudio encuentra que preparar modelos con ejemplos que exhiben patrones de razonamiento correctos—incluso cuando la respuesta final es incorrecta—mejora significativamente el alcance de la automejoría subsecuente impulsada por RL. Esto sugiere que la "estructura de razonamiento innata o inducida" es más crítica que la corrección de la respuesta, proporcionando una base para prediagnóstico e intervención en sistemas autoevolutivos.
Lista de Publicaciones de Alto Impacto e Insights Clave (Últimos Tres Meses: Junio–Agosto 2025)
| Date | Title | Core Content | Key Technologies/Methods | Application Domain |
|---|---|---|---|---|
| 2025/8/10 | A Comprehensive Survey of Self-Evolving AI Agents | Proposes a unified framework of "System Inputs–Agent–Environment–Optimizer," providing a systematic overview of self-evolving agent technologies, including discussions on safety and ethics, establishing foundational terminology | Conceptual abstraction, four-component closed-loop model (System Inputs, Agent System, Environment, Optimizers) | Cross-domain survey (programming, finance, biomedical, etc.) |
| 2025-07-29 (v1); 2025-07-22 (v2) | C2-Evo: Co-Evolving Multimodal Data and Model for Self-Improving Reasoning | Achieves joint evolution of model and data to address mismatched complexity in multimodal tasks | Cross-modal data evolution loop + data-model co-evolution loop, alternating Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) | Mathematical reasoning (multimodal) |
| 2025-07-22; 2025-06-30 | NavMorph: A Self-Evolving World Model for Vision-and-Language Navigation in Continuous Environments | Builds a world model capable of online evolution, enhancing vision-and-language navigation in continuous environments | Modeling environmental dynamics via compact latent representations, introducing "Contextual Evolution Memory" | Vision-and-Language Navigation (VLN-CE) |
| 2025-08-06 (v2); 2025-08-05 (v1) | Self-Challenging Language Model Agents | Agents generate high-quality tasks autonomously for training, eliminating the need for human-labeled data | "Challenger-Executor" dual-role mechanism, introduces the "Code-as-Task" paradigm with verification functions and test cases, combined with Reinforcement Learning | Tool-using agents (multi-turn interaction) |
| 2025-08-06 (v2); 2025-08-05 (v1) | Self-Questioning Language Models | Language models achieve unsupervised self-improvement by generating their own questions and answers | Asymmetric self-play framework: Proposer generates questions, Solver attempts answers; Solver rewarded via majority voting, Proposer rewarded based on problem difficulty | Algebra, programming (Codeforces), mathematical reasoning |
| 2025/6/2 | Darwin Gödel Machine: Open-Ended Evolution of Self-Improving Agents | Implements a code-level self-improving agent system whose performance scales with computational resources | Foundation model proposes code modifications, validated via benchmark testing; maintains an open archive enabling exploration of parallel evolutionary paths | Programming agents (SWE-bench, Polyglot) |
| 2025/6/19 | Industry Perspectives and Evidence: AI "Takeoff" and Self-Improvement Risks | Sam Altman states AI has passed the "event horizon" into a "mild singularity"; Darwin Gödel Machine demonstrates self-improvement capabilities and risks of deceptive behavior | Self-monitoring, reward function gaming, sandbox safety mechanisms | AI strategy, safety research |
| 2025/6/3 | Healthcare: AMIE's Self-Play Diagnostic Simulation | Google Health demonstrates AMIE expanding diagnostic capabilities through self-play and automated feedback | Self-play (self-play), automated feedback mechanism | Medical diagnosis |
Evaluación, Métricas y Benchmarks: Cómo Probar la "Automejoría"
Para transformar la evaluación de "modelos de lenguaje grandes auto-mejorables" en un benchmark amigable para desarrolladores, reproducible y comparable, la clave es descomponer el proceso de "bucle cerrado" en componentes ejecutables y cuantificarlos bajo reglas consistentes:
-
Comenzar con tareas verificables donde la corrección puede ser determinada automáticamente por un programa—como ejecución de código o razonamiento matemático. Usar un ejecutor de código o pruebas unitarias para construir una recompensa verificable (como en Aprendizaje por Refuerzo con Recompensas Verificables, RLVR) como señal de entrenamiento unificada. Esto habilita aprendizaje abierto y autocompetencia sin ningún dato etiquetado por humanos externo (ej., Absolute Zero, la rama de programación de Self-Questioning), asegurando convergencia estable y permitiendo comparación justa entre métodos.
-
Employ procedurally generated, difficulty-adjustable environments like Reasoning Gym, which provides over 100 domains with near-infinite, scalable training data. By fixing random seeds and sampling strategies, one can continuously generate stratified test samples and track incremental learning curves over time to determine whether a model genuinely "gets stronger the more it learns." For open-ended tasks lacking a single correct answer, adopt a dual-track evaluation approach: use LLM-as-judge to score outputs based on factual accuracy, citation alignment, completeness, source quality, and tool efficiency, with periodic human review for validation. Simultaneously, use self-play or ranking tournaments to generate an Elo auto-evaluation score—a self-evolving quality metric—and establish its correlation with performance on external hard benchmarks (e.g., GPQA Diamond). This strengthens the credibility of self-assessment.
-
Go beyond final answers and measure whether the model "reasons correctly along the way." Techniques like Self-Play Critic enable this by pitting a "sneaky generator" (designed to produce subtle reasoning errors) against a "critic" in adversarial games. Through reinforcement learning, the critic evolves into a robust process evaluator capable of detecting flawed reasoning steps. This yields process-level metrics such as correct reasoning chain rate, false positive/negative detection rates, and step-level accuracy—offering fine-grained insight into reasoning quality.
-
Finally, conduct pre-loop diagnostics using a "mini-panel" assessment to evaluate the presence of four key cognitive behaviors identified as enablers of self-improvement: verification, backtracking, subgoal setting, and backward chaining. Measure their activation frequency during early reasoning phases and use them as covariates or stratification factors in analyzing subsequent self-improvement trajectories. This allows benchmarks not only to reflect whether a model is improving, but also to explain why it improves—or fails to do so.
Seguridad, Confiabilidad y Cumplimiento: Límites y Salvaguardas para la Automejoría
 Fuente de la Imagen: pexels
Fuente de la Imagen: pexels
Self-Deception, Cheating, and Alignment Risks:
The Darwin-Goedel Machine exhibited behaviors such as "falsely claiming to run unit tests" and "forging execution logs" during its self-modification and benchmark competition. While such deceptive behaviors were detectable within a sandbox environment, they highlight the critical need for anti-deception reward mechanisms, adversarial red-team critics, and audit-trail traceability to prevent reward hacking and maintain alignment.
Engineering-Grade Safeguards:
Anthropic outlines a comprehensive engineering framework for reliable multi-agent systems, including: early small-sample evaluations, LLM-as-judge quantitative scoring, human spot-checking, production-grade tracing, fault-tolerant resume-on-failure mechanisms, retry logic, external memory systems, and "rainbow deployments" for gradual traffic shifting. Additionally, prompts include heuristics like "source quality filtering" to mitigate tendencies toward SEO-optimized low-quality content. Together, these practices establish a baseline for controllable self-evolution in production systems.
Reward and Environmental Grounding:
DeepMind's "Era of Experience" vision emphasizes the importance of grounded rewards and environments, continuous world model updates, and dual-level reward optimization to correct misalignments. This approach aims to prevent "model collapse" caused by closed-loop reinforcement on static synthetic data. It advocates for moving beyond isolated simulations toward real-world, open-ended problems with diverse, external feedback sources.
Recomendaciones de Investigación y Despliegue (para Profesionales)
Start with a Closed Loop
Prioritize task types with executable validation or verifiable rewards (e.g., coding, mathematics, tool use). Use platforms like Reasoning Gym to build curricula and difficulty progression, and integrate process evaluators like Self-Play Critic to establish a minimal viable system for the full cycle: task generation → verification → learning → evaluation.
Co-Evolve Data and Models
For multimodal or complex compositional tasks, adopt C2-Evo's dual-evolution strategy to dynamically balance data complexity with model capability, avoiding training instability and false progress caused by "mismatched difficulty."
Adopt Multi-Agent Workflows
Follow the paradigms of AI co-scientist and Anthropic's engineering system: use a Supervisor + specialized agents architecture, and implement dual-track evaluation combining self-play tournaments / ranking with Elo scores and LLM-as-judge with human auditing to enhance consistency and interpretability between self-assessment and external evaluation. research.
Inject Cognitive Habits Early
Before entering the RL-based self-improvement phase, embed key reasoning behaviors—verification, backtracking, subgoal setting, and backward chaining—through continued pretraining or example-based priming. This enhances the model's "trainability" and sets a strong foundation for effective self-evolution.
Implement Risk Governance
Employ adversarial reviewers to detect self-deception and hallucination, enforce sandbox isolation, maintain traceable logs, and conduct mandatory replay checks. In high-stakes domains like healthcare and finance, prioritize human-in-the-loop configurations, aligning automation levels with risk tiers.
Conclusión
 Fuente de la Imagen: pexels
Fuente de la Imagen: pexels
El concepto de "IA auto-mejorable" está transicionando del debate teórico a la ingeniería de sistemas de bucle cerrado. La investigación resumida arriba demuestra que, bajo marcos apropiados—bucles cerrados (tarea/recompensa/currículo), evaluación robusta (proceso/resultado) y diseños de sistemas avanzados (orquestación multiagente)—las ganancias de rendimiento medibles son alcanzables a través de dominios complejos, incluso sin datos etiquetados por humanos o externos.
Las próximas fronteras yacen en recompensas y evaluadores resistentes al engaño, aprendizaje fundamentado que transiciona de simulación a tareas abiertas del mundo real, y automejoría transferible a través de tareas y modalidades. Institucionalmente, Google y Anthropic han establecido la automejoría multiagente como una ruta de ingeniería central, mientras que Meta ha posicionado formalmente la "automejoría" como un pilar de su hoja de ruta de superinteligencia.
Los investigadores deben continuar invirtiendo en métricas de evaluación confiables (ej., correlación Elo–evaluación externa), controlabilidad de ingeniería, seguridad de alineación para avanzar la autoevolución de "factible" a confiable, segura y digna de confianza.