Hybrid Indexing & Structured Know‑How for Dev Velocity
20 de marzo de 2026Ollie @puppyone
Indexación híbrida y Know‑How estructurado: RAG para desarrolladores que acelera las fusiones de PR
La velocidad del desarrollador no se estanca porque la gente olvide cómo programar. Se estanca cuando los equipos no pueden encontrar, confiar o reutilizar el conocimiento que ya existe dentro de sus repositorios y documentos. Eso es la entropía del conocimiento: ADRs dispersos en wikis, contratos de API enterrados en PDFs, pérdida de propiedad debido a la rotación organizacional. La generación aumentada por recuperación (RAG) puede ayudar, pero solo si se basa en una columna vertebral de recuperación que sea tanto semántica como determinista. Ahí es donde la indexación híbrida sobre el Know‑How estructurado cambia las reglas del juego para las fusiones de PR y las refactorizaciones más seguras.
Puntos clave
- La indexación híbrida + Know‑How estructurado reduce las alucinaciones y produce citas precisas y revisables que aceleran las revisiones de PR.
- Trate el RAG para desarrolladores como un sistema de ingeniería: instrumente la precisión@k, la exactitud de las citas, el tiempo de fusión (time‑to‑merge) y la tasa de reversión.
- Utilice un recuperador híbrido (léxico disperso + vectores densos + claves estructurales/grafo) para responder preguntas sobre el código base con rutas de archivo exactas e IDs de ADR.
- Comience con microflujos de trabajo: un asistente de descripción de PR con citas y un asesor de refactorización basado en ADRs/propiedad.
- Prefiera despliegues privados/locales, redacción de secretos antes de la incrustación (embedding) y puertas de enlace con intervención humana para cualquier sugerencia de escritura.
RAG para desarrolladores: qué funciona y qué falla
RAG combina un LLM con un recuperador que extrae evidencia de su código, documentos e historial de diseño. Cuando funciona, los desarrolladores obtienen resúmenes fundamentados y borradores de texto para PR con fuentes. Cuando falla, se obtienen respuestas incorrectas con total seguridad y la confianza se desploma.
Patrones de fallo a vigilar:
- Los vectores de solo texto omiten identificadores exactos (ADR-1234, nombres de funciones), devolviendo fragmentos plausibles pero incorrectos.
- La recuperación excesiva inunda los prompts; los revisores ven ruido, no señales.
- La falta de citas significa falta de confianza; los revisores deben repetir la búsqueda.
Las correcciones de mejores prácticas se basan en guías bien documentadas: fragmentación semántica, recuperación híbrida y re-clasificación (reranking). Para una visión arquitectónica concisa, consulte los patrones orientados a producción en el artículo de InfoQ sobre pipelines de RAG, que enfatiza la composición y evaluación de la recuperación, no los prompts mágicos (InfoQ — Effective Practices for Architecting a RAG Pipeline). Y para flujos de trabajo de desarrolladores basados en agentes en tiempo de CI, la discusión de GitHub sobre IA continua muestra cómo los asistentes pueden redactar y verificar artefactos en el bucle (GitHub Blog — Continuous AI in practice: agentic CI for developers).
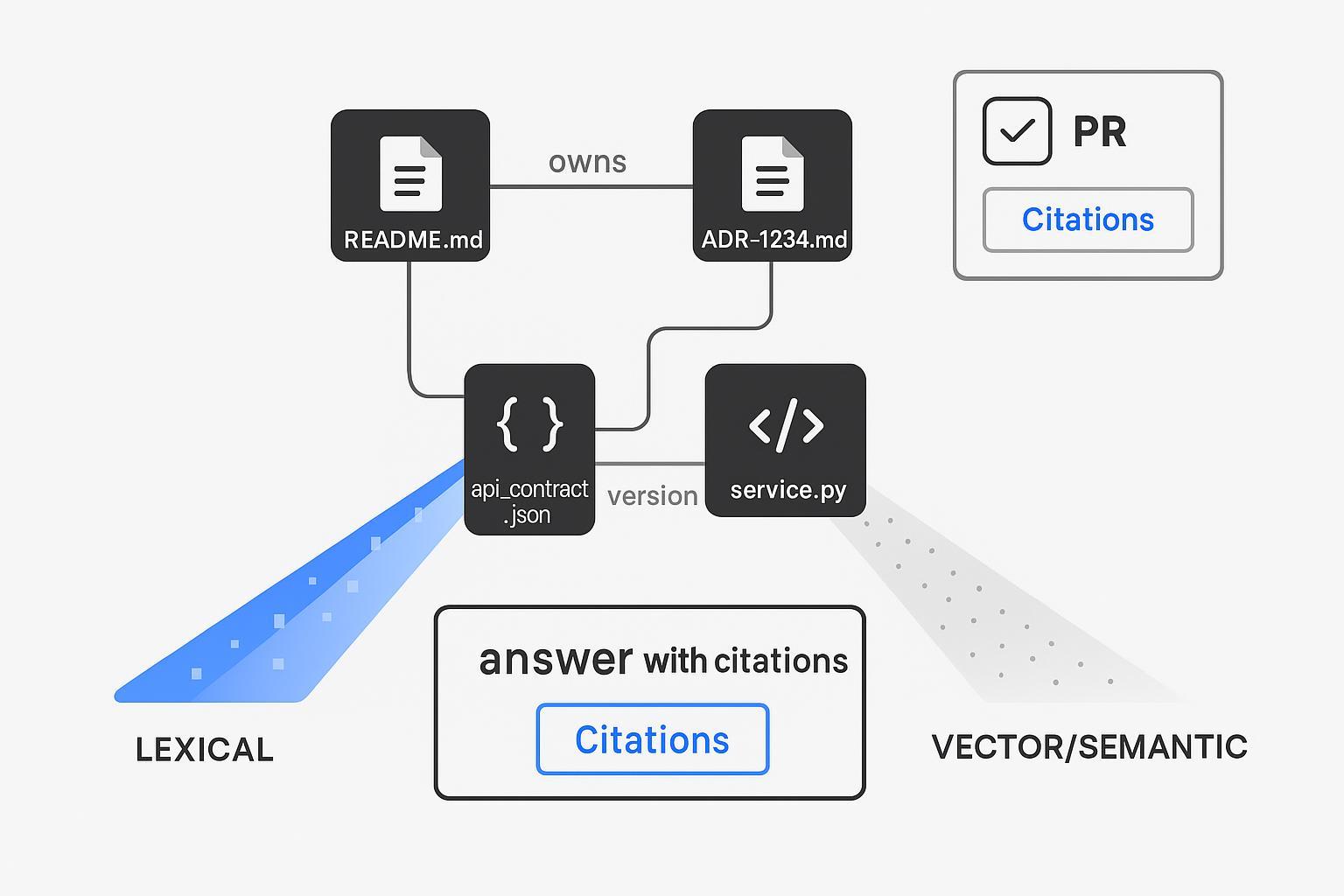
Know‑How estructurado + indexación híbrida como columna vertebral de recuperación
El texto por sí solo no puede sostener sus flujos de trabajo de desarrollo. Modele el Know‑How empresarial explícitamente y recupere a través de texto y estructura.
Un esquema de Know‑How mínimo (ilustrativo):
{
"type": "adr",
"adr_id": "ADR-1234",
"title": "Deprecate legacy payment gateway",
"status": "accepted",
"decision": "Move to PayFast v3",
"owners": ["@payments-core"],
"links": {"repo_paths": ["/services/payments"], "docs": ["/docs/payments/adr-1234.md"]},
"supersedes": ["ADR-0899"],
"date": "2025-11-06",
"version": "1.2"
}
Diseño del recuperador híbrido (de un vistazo):
- Léxico: filtros exactos (repo_path:/services/payments, file:*.md), BM25 para identificadores.
- Denso: embeddings de código/documentos para paráfrasis e intención.
- Estructural: uniones (joins) deterministas por claves (adr_id, owner, module) para extraer los archivos/propietarios correctos.
- Opcional: re-clasificación con un cross‑encoder para asegurar la fidelidad.
Este patrón refleja la guía de proveedores y de la comunidad sobre búsqueda híbrida: fusión densa + dispersa con re-clasificación opcional, tal como lo documentan los recursos de ingeniería de búsqueda híbrida de Qdrant (Qdrant — Hybrid Search Revamped; Qdrant Docs — Hybrid Queries). El resultado es una capa de recuperación que puede citar rutas de archivo exactas e IDs de ADR, no solo "algo parecido". Esa es la palanca de confianza que los revisores necesitan.
Microflujos de trabajo que agilizan las PR
- Asistente de descripción de PR con citas
Objetivo: Redactar un cuerpo de PR fundamentado a partir del diff y el Know‑How local.
Pasos principales:
- Expandir el título de la rama/PR en variantes de consulta.
- Recuperar los top‑k de: (a) rutas modificadas (filtros léxicos), (b) documentos/fragmentos semánticamente similares, (c) claves estructurales (ADRs/propietarios).
- Generar un cuerpo de PR que siempre incluya un bloque de Citas con enlaces permanentes.
Ejemplo de plantilla de cuerpo de PR:
#### Summary
- Implements PayFast v3 retry policy in /services/payments/retry.go
#### Rationale
- Aligns with ADR-1234 (Deprecate legacy payment gateway). See details below.
#### Impact
- Touches retry.go; no public API changes. Adds metric payments.retry.backoff_ms.
#### Citations
- ADR-1234 — /docs/payments/adr-1234.md#decision
- Code — /services/payments/retry.go#L120-L168
- Runbook — /ops/runbooks/payments-retries.md#rollback
- Asesor de refactorización potenciado por ADRs y propiedad
Objetivo: Hacer que las refactorizaciones grandes sean más seguras al mostrar automáticamente la intención del diseño y los propietarios.
Pasos principales:
- Dado un plan de refactorización propuesto, recuperar ADRs superpuestos y propietarios de módulos afectados.
- Generar una lista de verificación: "notificar a @payments-core", "actualizar pruebas de contrato", "confirmar ventana de depreciación según ADR‑0899".
- Emitir citas para cada fuente para que los revisores puedan verificar rápidamente.
Medir la velocidad del desarrollador y la calidad de la recuperación
Trate el RAG como un sistema de ingeniería con resultados auditables.
Métricas a seguir:
- Velocidad: tiempo medio de fusión (TTM), tasa de fusión (fusionados/abiertos), iteraciones de revisión por PR.
- Calidad: tasa de reversión, tasa de fallos en CI, defectos post-fusión para refactorizaciones.
- Recuperación: precisión@k, exactitud de las citas (¿la fuente citada respalda la afirmación?), tasa de alucinación.
Plan A/B (8–12 semanas):
- Control: flujo de trabajo estándar.
- Tratamiento: habilitar el asistente de descripción de PR + asesor de refactorización (sugerencias de solo lectura) con citas.
- Instrumentar eventos en recuperar → sugerir → aceptación/anulación del revisor → fusión.
Para un contexto industrial más amplio sobre la medición y mejora de la fidelidad de RAG y el comportamiento de las citas, consulte los trabajos recientes de encuesta y evaluación que formalizan las métricas de relevancia/fidelidad y la auditoría de LLM como juez (arXiv — Evaluation of Retrieval‑Augmented Generation: A Survey; arXiv — Comprehensive and Practical Evaluation of RAG).
De la demo a la producción
No necesita un monolito; necesita un bucle confiable.
- Ingesta: fragmentación consciente del lenguaje para código (funciones/clases) y documentos (encabezados/semántica). Adjunte metadatos (repo_path, module, owner, version). Objetivo de 500–1500 tokens para código; 400–1000 para documentos.
- Cadencia de indexación: volver a generar embeddings al cambiar; lote nocturno para repositorios activos; semanal para los inactivos. Versione su índice para posibles reversiones.
- Gobernanza: prefiera despliegues privados/locales; alinee las ACL de recuperación con los permisos del repositorio; redacte secretos antes de la incrustación.
- Servicio: limite k para controlar los tokens; almacene en caché consultas frecuentes; considere la re-clasificación con cross-encoder para espacios de nombres complicados.
- Monitoreo: rastree precisión@k, exactitud de las citas, latencia y costo por consulta. Alerte sobre desviaciones (caídas en precisión/exactitud de citas).
Las señales del mundo real muestran por qué vale la pena hacerlo. Amazon ha informado que Amazon Q Developer redujo las actualizaciones de Java a gran escala de días a minutos en decenas de miles de aplicaciones, ahorrando un estimado de 4,500 años-desarrollador y contribuyendo a un impacto anual de $260 millones (AWS DevOps & Developer Productivity Blog, 2024), evidencia de que los asistentes de desarrollo integrados pueden desbloquear cambios significativos en el rendimiento cuando se integran en el SDLC (AWS DevOps Blog — Amazon Q Developer milestone). Y la historia de cliente de GitHub sobre Mercado Libre apunta a una adopción en toda la organización con un ~50% menos de tiempo dedicado a escribir código y un rendimiento de PR extraordinario, lo que sugiere que el techo es alto cuando los asistentes están en la ruta crítica (GitHub Customer Stories — Mercado Libre).
Notas sobre herramientas: pilas que funcionan bien
- Vectorial + disperso: Qdrant, Pinecone, Weaviate admiten patrones híbridos; elija según el control sobre la fusión de puntuaciones, la madurez de operaciones y el costo.
- Orquestación: LangChain/LlamaIndex para una composición rápida; Dagster/Airflow para operaciones de ingesta.
- Embeddings: elija modelos ajustados para código para los repositorios; monitoree la desviación y vuelva a incrustar selectivamente.
- Grafo/estructura: Neo4j/TigerGraph para grafos de Know‑How explícitos o JSON/kv ligero para equipos más pequeños.
- CI de agentes: integre asistentes en ganchos (hooks) de PR y comentarios de CI según la guía de CI agéntica de GitHub.
Ejemplo práctico: uso del Know‑How estructurado e indexación híbrida de puppyone
La indexación híbrida solo brilla cuando su conocimiento está modelado para máquinas. Una forma neutral de implementar esto es almacenar el conocimiento empresarial como Know‑How estructurado (JSON/grafo) y fusionar búsquedas léxicas, vectoriales y estructurales en un solo recuperador.
Flujo de trabajo de ejemplo (ilustrativo, neutral):
- Modelar ADRs, propiedad y contratos de API como nodos de Know‑How de primera clase (por ejemplo, adr_id, status, decision, owners, repo_paths, version).
- Ingerir fragmentos de código/documentos con metadatos (repo_path, symbols, owners). Construir un índice híbrido donde se combinen filtros léxicos (por ejemplo, ruta del repositorio), vectores (similitud semántica) y uniones estructurales (adr_id → archivos/propietarios relacionados).
- En el asistente de PR, requerir un bloque de Citas con enlaces permanentes a ADRs y rangos de líneas de archivos para que los revisores puedan verificar rápidamente.
Este patrón está respaldado por materiales conceptuales públicos sobre puppyone, que se posiciona en torno al Know‑How estructurado y la indexación híbrida para una recuperación determinista y citas precisas. Para una visión general de este enfoque, consulte el artículo de la empresa sobre indexación híbrida, que resume cómo se pueden combinar el texto y la estructura para una fundamentación confiable en flujos de trabajo de agentes (vea el resumen en "Ultimate Guide to Agent Context Base: Hybrid Indexing") (puppyone’s hybrid indexing guide). Utilice esto como referencia conceptual al diseñar su propio esquema y recuperador; adáptelo a su pila tecnológica y restricciones de gobernanza.
Conclusión y próximos pasos
Si su objetivo son PRs más rápidos y seguros, invierta primero en Know‑How estructurado y en un recuperador híbrido que pueda probar cada afirmación con una cita. Pilote un asistente de descripción de PR y un asesor de refactorización, mida el TTM y la exactitud de las citas, luego escale lo que funcione. Si está explorando el Know‑How estructurado y la indexación híbrida, puede evaluar puppyone en un piloto pequeño y privado y compararlo con su pila actual.