Guía definitiva de indexación híbrida para el aprendizaje por contexto
7 de febrero de 2026Ollie @puppyone
Puntos clave
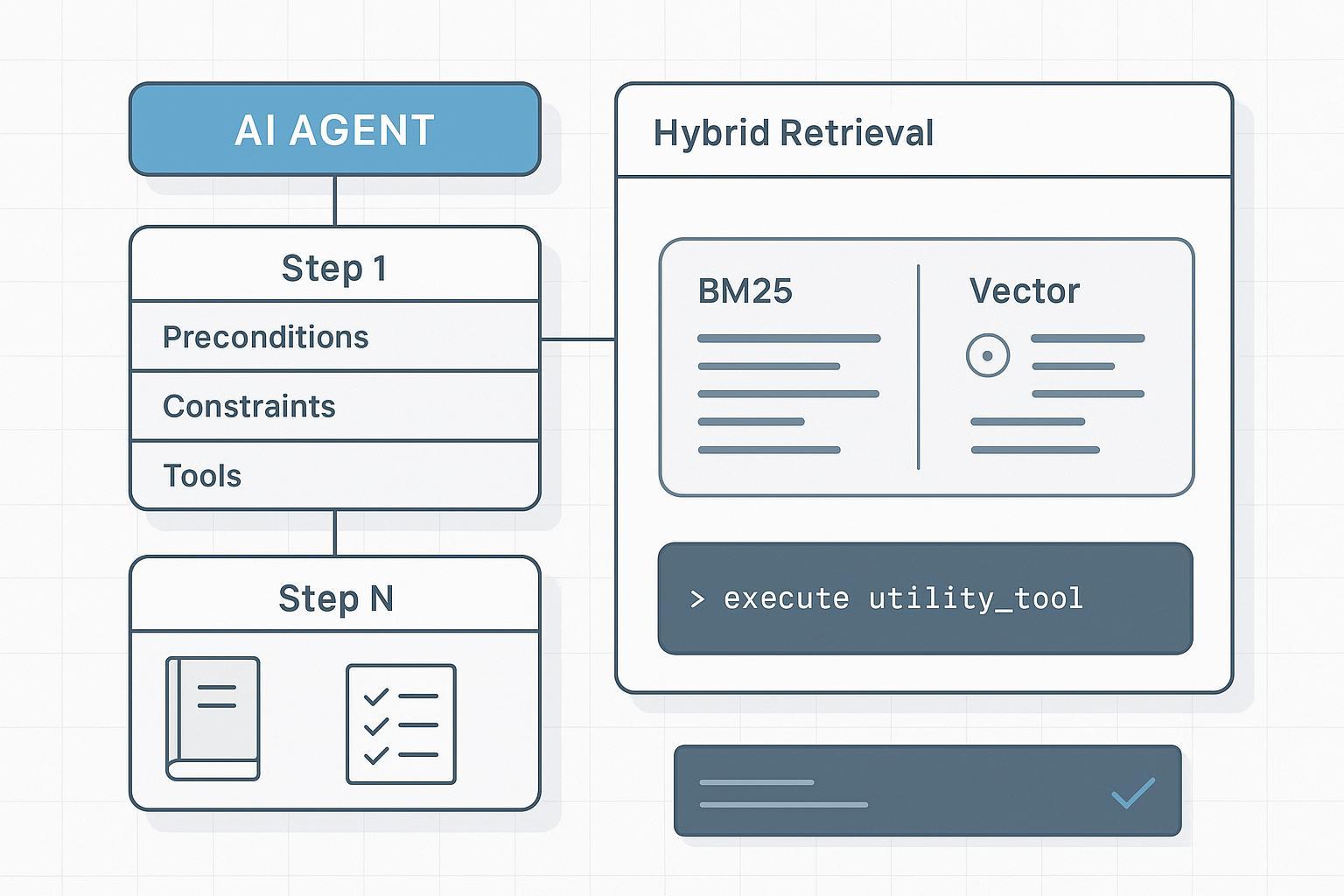
- La recuperación híbrida y consciente de campos supera a «simplemente alargar el contexto». Necesita por paso rebanadas deterministas, no un muro de texto.
- Los límites del modelo son reales: los benchmarks muestran tasas altas de contexto ignorado o mal usado; diseñe su pila para prevenir, detectar y corregir estos errores.
- Para Operaciones/Soporte: combine un Know-How JSON/Grafo con indexación híbrida y un bucle agéntico planificador→ejecutor→verificador para adherencia al paso y auditabilidad.
Por qué los modelos ignoran y malusan el contexto en los SOPs
Un benchmark (CL-bench: 500 contextos, 1.899 tareas, 31.607 rúbricas) muestra lo frágiles que son los modelos al aprender del contexto dado: diez modelos de frontera resolvieron solo ~17,2 % de las tareas de media; el mejor llegó a ~23,7 % incluso en modo razonamiento. El error dominante fue no usar correctamente el contexto—omitir detalles clave o aplicar la regla equivocada. Véase CL-bench paper (arXiv), Tencent Hunyuan research blog. El contexto largo por sí solo no lo arregla; LongBench v2 etc. muestran que una mejor ventana sigue dejando huecos en razonamiento y agregación (LongBench v2 ACL). En SOPs multi-paso esto se traduce en saltos de paso, deriva de instrucciones o acciones inseguras.
Modos de fallo habituales del RAG ingenuo en la ejecución de SOPs
Las pilas RAG fallan en flujos de operaciones porque la unidad de recuperación no coincide con la unidad de acción: chunks demasiado amplios → deriva; campos sin ponderar entierran tokens críticos. Los prompts monolíticos fomentan la improvisación. Solución: diseñar para recuperación determinista y ejecución verificable.
Fundamentos: modele sus SOPs como Know-How JSON/Grafo
Los agentes necesitan conocimiento estructurado y por campos. Un esquema práctico codifica pasos, dependencias, restricciones y métodos de verificación. El ejemplo JSON del artículo en inglés (sop.router.reset.v3, step_number, preconditions, constraints, tools_allowed, checkpoints, verification_method, dependencies) se mantiene. Así el recuperador puede ponderar título, step_number, preconditions y constraints más que la narrativa. Context Base: puppyone About.
Indexación híbrida para aprendizaje por contexto en manuales largos y densos
El núcleo no es «más contexto» sino «mejores unidades de recuperación y señales de ranking». En la práctica: indexación híbrida con conciencia de campo y un pequeño paso de rerank.
- Combine señales léxicas dispersas (BM25/BM25F) con vectores densos. Léxico: IDs exactos, advertencias, restricciones; denso: mejor recall en pasos formulados semánticamente. Referencias: Elastic — What is hybrid search, Elastic retrievers and RRF, Weaviate — Hybrid search explained.
- Boosts conscientes de campo: preferir título, step_number, preconditions, constraints, tools_allowed frente a narrativa.
- Recuperar por paso rebanadas mínimas y deterministas; no alimentar toda la SOP cada vez.
- Opcional: rerank del top-k con cross-encoder o reranker consciente de estructura.
RAG agentivo para SOPs: planificador → recuperador → ejecutor → verificador
El planificador descompone en intenciones por paso y formula consultas de recuperación (step_number, herramientas necesarias). El recuperador devuelve rebanadas mínimas con IDs. El ejecutor solo invoca herramientas enumeradas con parámetros validados por esquema y cita los slice IDs. El verificador comprueba checkpoints y restricciones antes de avanzar; en desviación, replan o revisión humana. Véase Anthropic — Multi-agent research system.
Ejemplo práctico: un paso de extremo a extremo
Aviso: puppyone es nuestro producto; aquí se menciona de forma neutra como una posible context base. Más en puppyone. Objetivo: ejecutar el paso 7 de «Router Safe Reset» con recuperación híbrida y bucle agentivo. Plan de consulta, pseudocódigo (estilo Python) y log de estado como en el artículo en inglés. La misma cadena puede implementarse con Elastic/OpenSearch/Vespa/Weaviate o RDBMS+pgvector+BM25.
Playbook de evaluación: demostrar fiabilidad, luego escalar
Calidad de recuperación: Recall@k, MRR/nDCG por paso, Context Precision, Context Sufficiency. Ejecución: Step Adherence %, Action Success Rate, Instruction Drift Rate, incidentes por 1.000 ejecuciones, Time-to-Resolution. Por paso SOP guardar slice IDs de ground truth y patrones de herramienta/resultado esperados; afirmar que el ejecutor cita el slice usado y que los checkpoints pasan antes de avanzar. Resumen: RAG evaluation survey (2024).
Alternativas y paridad
| Stack | Opciones de fusión híbrida | Boosts conscientes de campo | Encaje on-prem/VPC | Notas |
|---|---|---|---|---|
| Elasticsearch | RRF, mezcla ponderada | BM25F, boosts multi-campo | Self-host maduro | APIs retriever, rerankers cross-encoder |
| OpenSearch | Ponderado + patrones rerank | Boosts por analizadores | Self-host first-class | Trabajo perf vector |
| Vespa | Lexical + ANN + rerank | Características por campo | Self-host, scale-out | Pipeline ranking/ML |
| Weaviate | RRF/híbrido ponderado | Pesos/filtros de propiedad | Managed + self-host | Documentación híbrida clara |
Para el enfoque «Agent Context Base»: por ejemplo puppyone. Criterios: puntuación consciente de campo, garantías de slicing determinista, logs de auditoría, soporte de harness de evaluación.
Cómo se ve «bueno» en la práctica
En pilotos, el paso de prompts de documento completo a rebanadas por paso y por campos reduce la deriva de instrucciones y aumenta la adherencia al paso. La indexación híbrida para aprendizaje por contexto pone la superficie exacta de restricciones en manos del agente y exige verificación antes de continuar.
Próximos pasos
Si está evaluando un enfoque de grado producción para automatización de SOPs—Know-How estructurado, indexación híbrida y bucle planificador→ejecutor→verificador—revisemos juntos su corpus y restricciones. Reserve una demo técnica centrada en indexación híbrida + RAG agentivo para su entorno.