Intégration Profonde des Agents IA et de l'Apprentissage par Renforcement : De la Séparation à la Révolution
10 septembre 2025Ollie @puppyone
Observation Centrale : La première vague de développement d'agents IA s'appuyait principalement sur l'ingénierie de prompts et avait peu de connexion avec l'apprentissage par renforcement (RL) traditionnel. Cependant, les recherches récentes indiquent que le RL devient maintenant la force motrice centrale propulsant les agents vers l'intelligence générale. Basé sur la recherche de pointe de mai à août 2025, ce rapport révèle trois tendances d'intégration majeures.
Innovation de Paradigme dans le RL à Agent Unique
De RLHF à RLVR : Percées dans la Conception de Récompenses Objectives
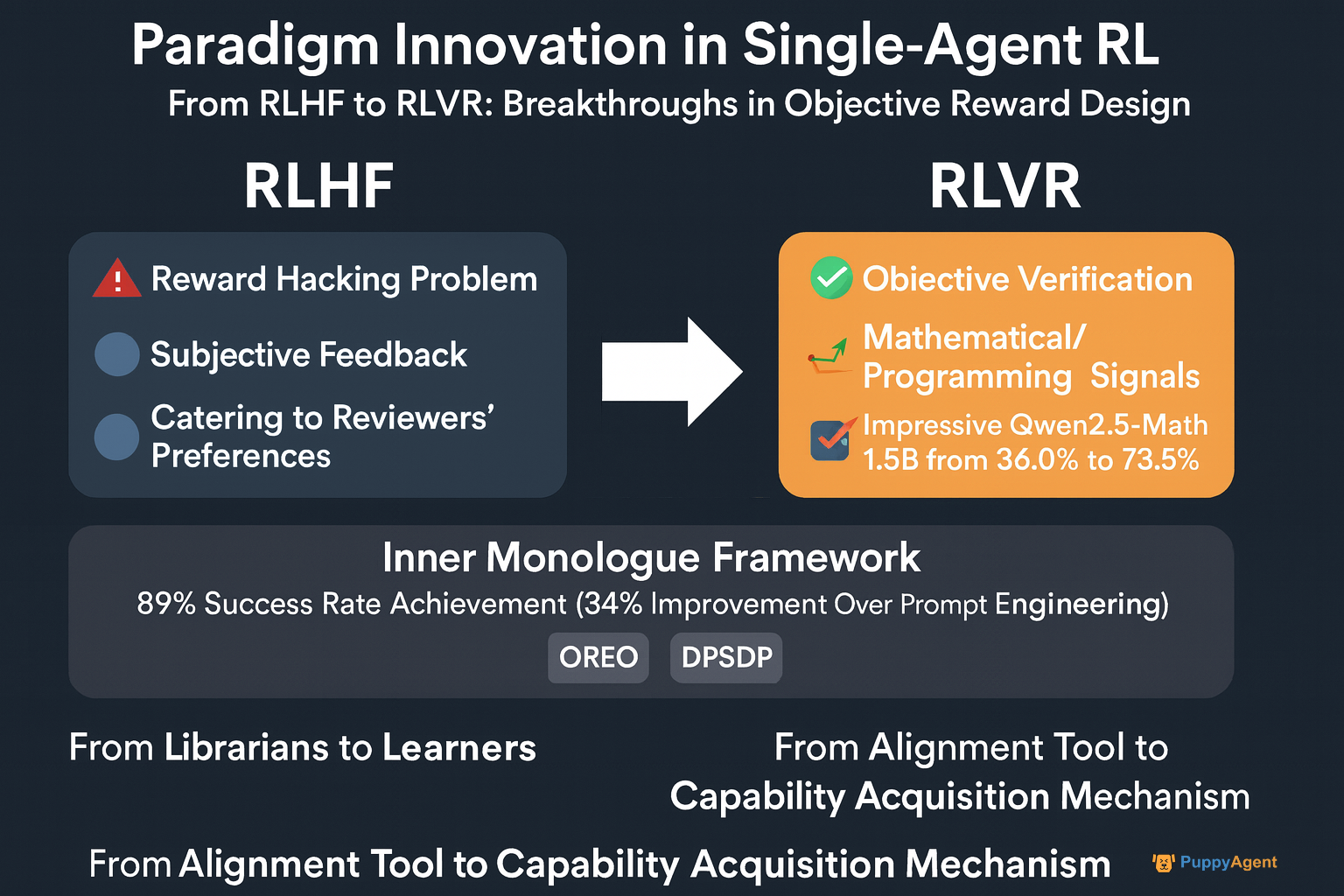
Le RLHF traditionnel (Apprentissage par Renforcement à partir de Retour Humain) s'appuie sur des retours humains subjectifs et souffre du problème de "piratage de récompense". À ICML 2024, le chercheur OpenAI John Schulman a déclaré sans détour : "Nous avons découvert que les modèles apprennent à satisfaire les préférences des réviseurs plutôt qu'à véritablement résoudre les problèmes." Cela a stimulé un changement vers le RLVR (Apprentissage par Renforcement avec Récompenses Vérifiables), exploitant des signaux objectifs et vérifiables de domaines tels que les mathématiques et la programmation. L'équipe Qwen d'Alibaba a appliqué cette approche pour augmenter la précision de Qwen2.5-Math-1.5B sur le benchmark MATH500 de 36,0% à 73,6%, démontrant que le RL évolue d'un "outil d'alignement" vers un "mécanisme d'acquisition de capacités".
Le professeur Sergey Levine de UC Berkeley a observé : "Nous assistons à une transformation fondamentale. Les premiers agents étaient comme des bibliothécaires avec de vastes mémoires ; maintenant, nous visons à les transformer en véritables apprenants." Le framework Inner Monologue de son équipe illustre ce changement — les agents développent un "monologue intérieur" grâce à une rétroaction en boucle fermée avec leur environnement, atteignant un taux de succès de 89% dans les tâches de navigation robotique — 34% plus élevé que les méthodes d'ingénierie de prompts pures. Pendant ce temps, l'algorithme OREO de DeepMind améliore le raisonnement multi-étapes en optimisant l'équation de Bellman, tandis que DPSDP fournit des capacités de recherche de politique directe pour les systèmes multi-agents.
Intelligence Incarnée et Intégration Multi-Agents
Percées Pratiques en Intelligence Incarnée
La professeure Daniela Rus du MIT a remarqué dans une interview : "Nous assistons enfin à un saut qualitatif dans l'intelligence robotique." Elle faisait référence aux performances révolutionnaires du framework LLaRP — un système intégrant de grands modèles de langage avec l'apprentissage par renforcement — qui a atteint un taux de succès de 42% à travers 1 000 tâches incarnées précédemment inconnues, 1,7x plus élevé que les références traditionnelles. Plus remarquable encore, il ne nécessite l'entraînement que d'un petit nombre de décodeurs de perception et d'action pour transformer un LLM figé en politique à usage général.
Linxi Fan, scientifique de recherche chez NVIDIA, a commenté : "Le projet Eureka a complètement refaçonné notre compréhension de la conception de récompenses." Dans ce projet, GPT-4 génère automatiquement du code de fonction de récompense pour l'apprentissage par renforcement ; dans des tâches complexes de manipulation de bras robotique, les fonctions de récompense générées par IA ont en fait surpassé celles méticuleusement conçues par des experts humains. De même, l'équipe robotique de Google DeepMind a réalisé des percées sur cette voie — leur système RT-2, basé sur un modèle vision-langage-action, permet aux robots de comprendre des instructions en langage naturel complexes et d'exécuter les actions correspondantes.
Évolution de la Collaboration Multi-Agents
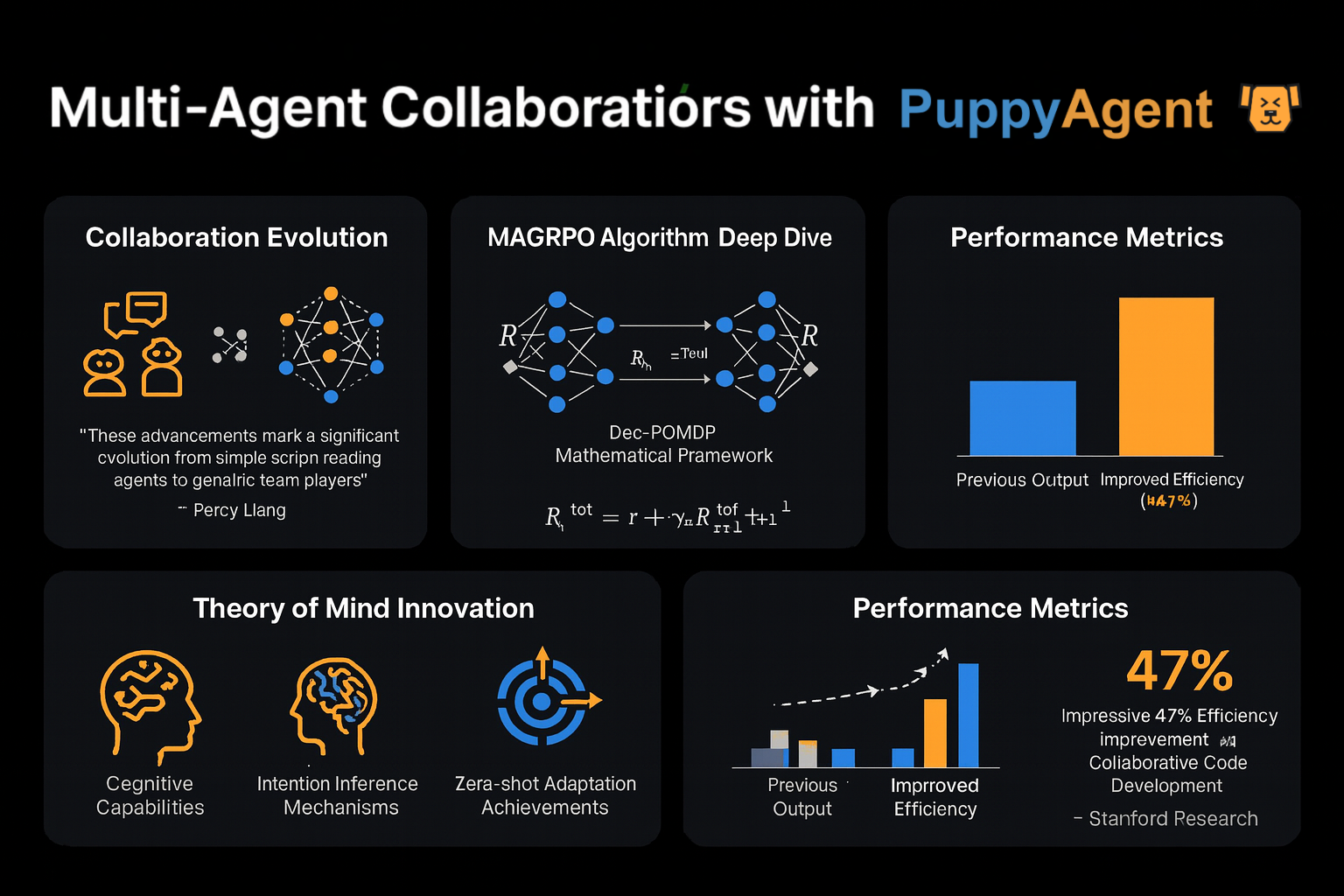
Le professeur Percy Liang de Stanford a observé : "Les premiers débats multi-agents étaient comme plusieurs personnes lisant des scripts indépendamment — maintenant nous voyons un véritable travail d'équipe." Le dernier algorithme MAGRPO modélise la collaboration LLM comme un Dec-POMDP (Processus de Décision de Markov Partiellement Observable Décentralisé) et atteint une vraie coopération grâce à l'optimisation de récompense conjointe. Dans les tests de développement de code collaboratif, cette approche a amélioré l'efficacité de 47% par rapport aux méthodes de dialogue multi-tours traditionnelles. Plus intriguant encore, une autre équipe de Stanford a équipé les agents d'un module "Théorie de l'Esprit", leur permettant d'inférer les intentions et stratégies des autres participants — démontrant des capacités adaptatives remarquables dans des environnements de jeu zéro-shot.
Changement dans les Tendances Académiques
Focus des Conférences de Haut Niveau
Le changement dans les tendances académiques est indiscutable. Le tutoriel "L'IA Générative Rencontre l'Apprentissage par Renforcement" à ICML 2025 a attiré plus de 2 000 participants ; son intervenante, la professeure Chelsea Finn, a ouvert avec : "Si vous vous appuyez encore purement sur l'ingénierie de prompts, vous êtes probablement déjà en retard." ACL 2025, hôte de son premier atelier "REALM", a placé l'entraînement d'agents basé sur le RL au cœur de son agenda — recevant trois fois le nombre attendu de soumissions d'articles. ICLR 2025 a présenté de multiples percées, incluant le framework open-source Agent S, qui opère les ordinateurs comme un humain et atteint des niveaux d'automatisation sans précédent dans des tâches complexes.
Plus notablement, l'atelier "Agents de Monde Ouvert" à NeurIPS 2024 a présenté une conférence principale par Yann LeCun, qui a souligné : "La récupération de connaissances statiques n'est plus suffisante — ce dont nous avons besoin sont des agents capables d'apprentissage continu et d'adaptation dans des environnements ouverts." Cette perspective a largement résonné parmi les participants ; lors d'une table ronde, plusieurs lauréats du prix Turing ont unanimement convenu que l'apprentissage par renforcement offre la voie la plus prometteuse pour adresser les défis centraux de l'intelligence artificielle générale.
Défis et Opportunités
Défis du Monde Réel et Opportunités Industrielles
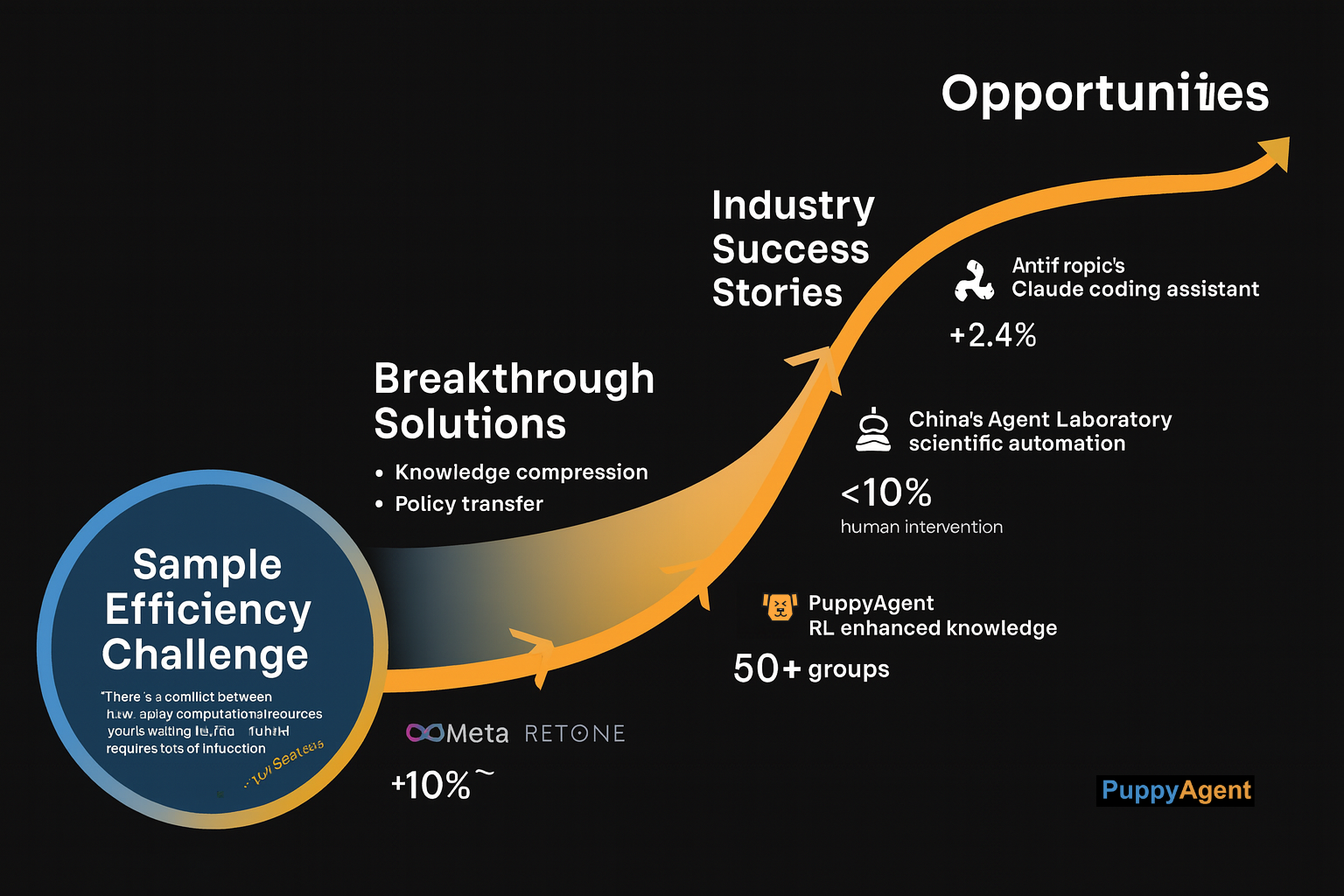
Bien sûr, des défis significatifs demeurent. Dans son dernier discours public avant de quitter OpenAI, Ilya Sutskever a candidement admis : "Notre plus grande difficulté réside dans l'efficacité d'échantillonnage. Chaque inférence LLM consomme des ressources computationnelles massives, tandis que le RL traditionnel nécessite des millions d'interactions." Cette contradiction pousse vers des solutions novatrices — par exemple, l'équipe de recherche de Meta a développé une méthode d'"apprentissage basé sur la distillation" qui compresse les connaissances de grands modèles en plus petits pour l'entraînement RL, puis transfère les politiques apprises vers les grands modèles.
La réponse industrielle a été également rapide. L'équipe Claude d'Anthropic teste actuellement en bêta un assistant de codage alimenté par RL ; des initiés révèlent que sa performance sur des tâches de programmation complexes est "étonnante". Pendant ce temps, le projet Agent Laboratory de Chine a déjà atteint l'automatisation de bout en bout des flux de travail de recherche scientifique — de la revue de littérature et conception expérimentale à la rédaction d'articles — nécessitant moins de 10% d'intervention humaine. Cette tendance d'automatisation pénètre rapidement plus de domaines verticaux. En gestion des connaissances, par exemple, les systèmes de base de connaissances intelligents comme puppyone commencent à appliquer des mécanismes d'apprentissage par renforcement à la compréhension de documents, l'extraction de connaissances et les réponses automatiques aux questions. En apprenant continuellement des modèles de requêtes et retours des utilisateurs, de tels systèmes peuvent optimiser itérativement leurs stratégies d'organisation et de récupération de connaissances — se transformant de dépôts d'informations passifs en assistants intelligents proactifs. La plateforme open-source AIRSTONE publiée par Shenzhen AIRS fournit un support computationnel sans précédent pour la recherche en intelligence incarnée, et est déjà utilisée par plus de 50 groupes de recherche internationaux.
Conclusion

La séparation entre les Agents et le RL existait effectivement — mais comme l'a justement dit le professeur Tommi Jaakkola du MIT, "C'est comme les premiers temps d'internet qui n'avait que des pages web statiques ; l'interaction dynamique est le véritable futur." Nous assistons à un changement fondamental : du raisonnement statique basé sur des connaissances pré-entraînées vers l'optimisation dynamique grâce à l'apprentissage continu de l'expérience. RLVR permet aux Agents d'acquérir des compétences difficiles comme le raisonnement mathématique ; LLaRP démontre la généralisation inter-scénarios ; et les systèmes multi-agents basés sur MARL révèlent l'émergence d'une véritable intelligence collaborative.
Comme l'a récemment déclaré le fondateur de DeepMind Demis Hassabis : "L'apprentissage par renforcement n'est pas simplement une méthode d'entraînement — c'est le mécanisme central de l'intelligence elle-même." Cette "discipline négligée" autrefois, avec ses insights profonds sur l'apprentissage par essai-erreur, l'optimisation de politique et l'adaptation environnementale, devient maintenant la fondation théorique la plus solide pour le voyage des Agents vers l'intelligence artificielle générale. Cette convergence n'est pas un simple empilement de technologies — c'est une révolution pilotée par la cognition et alimentée par la science fondamentale.
Références Clés : Tutoriel ICML 2025, Atelier ACL 2025 REALM, Rapport Technique Qwen2.5-Math, Article LLaRP, Algorithme MAGRPO, Inner Monologue, et autres recherches récentes