Autoévolution de l'IA : Une Revue Complète des Systèmes LLM en Boucle Fermée et les perspectives des systèmes multi-agents
4 septembre 2025Ollie @puppyone
Pourquoi devons-nous étudier sérieusement « l'autoévolution des LLM » maintenant ? Pour le dire simplement, les modèles puissants d'aujourd'hui sont principalement des « produits statiques » : après un entraînement hors ligne unique, ils sont déployés et font ensuite face à des changements de distribution, de nouvelles formes de tâches et à l'évolution rapide des écosystèmes d'outils. Ils ne peuvent compter que sur un réentraînement humain coûteux et tardif pour rattraper leur retard. Ce paradigme continuera d'engendrer des pertes dans un monde non-stationnaire : la dette technique des connaissances obsolètes, le coût continu d'étiquetage et de nettoyage des données, et la vulnérabilité dans le raisonnement complexe à longue traîne et la collaboration inter-domaines. Ce dont nous avons besoin, ce ne sont pas seulement des modèles plus grands, mais des systèmes capables d'apprendre en fonctionnant, de s'auto-corriger dans leur environnement et de devenir continuellement plus forts dans une boucle fermée.
 Image Source: Puppyone
Image Source: Puppyone
Nous nous sommes concentrés sur les travaux liés à « l'autoévolution/amélioration autonome des LLM / Agent IA » de juin à août 2025 et avons fourni une revue complète et une mise à jour des progrès. Nous espérons clarifier l'espace de conception et les voies réalisables pour « l'autoévolution » pour les développeurs et chercheurs : sur quels problèmes boucler en premier, comment construire un système minimal viable, quelles métriques utiliser pour mesurer « devenir vraiment plus fort », et comment rendre « l'autoévolution » et « contrôlable et digne de confiance » utilisables au niveau ingénierie.
Résumé (Aperçu juin–août 2025)
Définition
Les communautés académiques et industrielles n'ont pas encore atteint une définition unifiée pour « l'autoévolution ». Cependant, en août, deux revues systématiques se concentrant sur « les agents auto-évolutifs/proxies IA auto-évolutifs » ont été publiées consécutivement. Elles ont proposé un cadre structuré centré autour de « quoi faire évoluer, quand faire évoluer, et comment faire évoluer », se concentrant sur l'amélioration continue du système par le biais de rétroaction interactive, de signaux environnementaux et d'optimisation en boucle fermée. Cela marque l'entrée du sujet dans une fenêtre de consensus de convergence progressive.
Voies Représentatives
 Source de l'image : Puppyone
Source de l'image : Puppyone
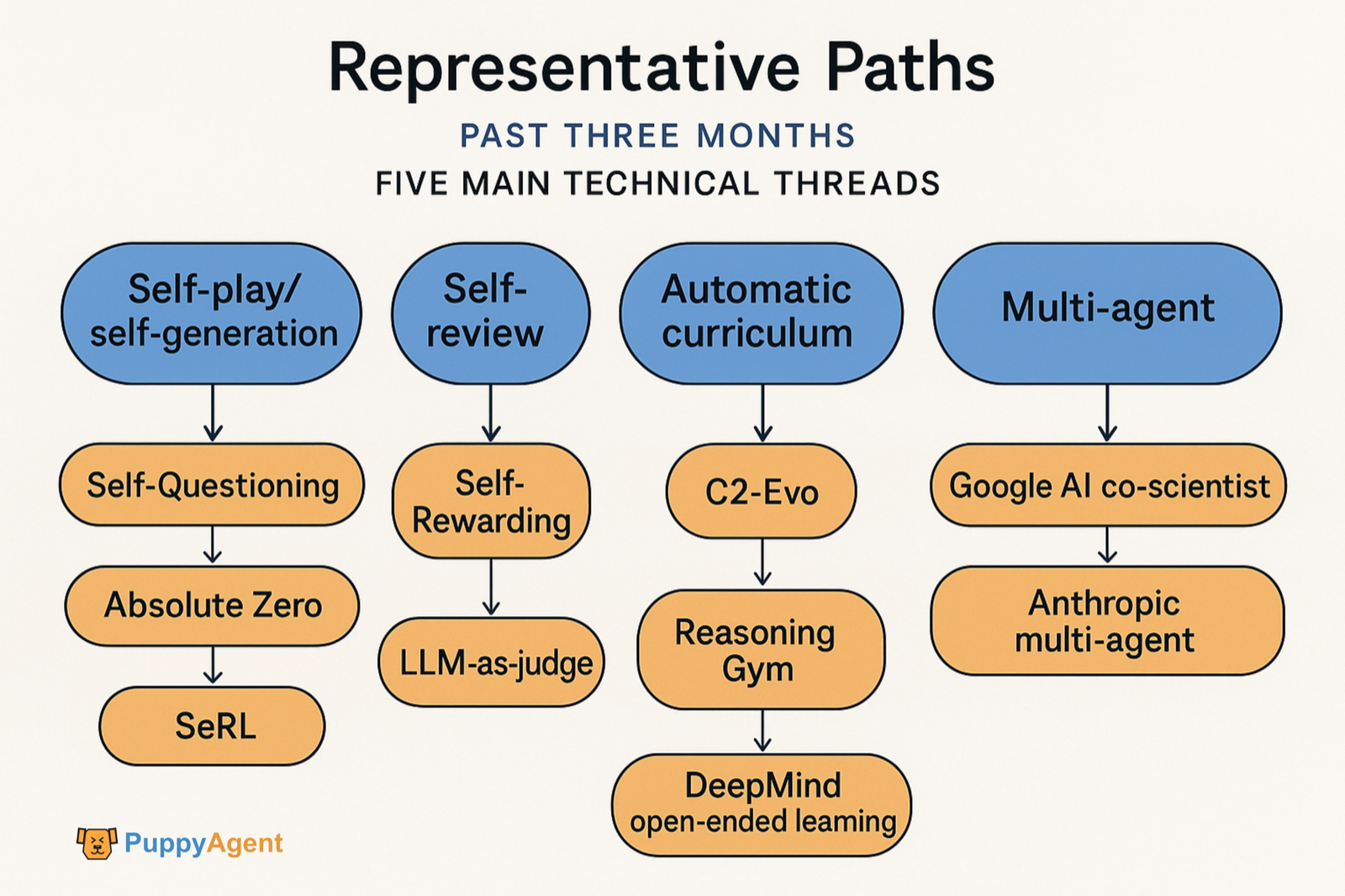
Au cours des trois derniers mois, les travaux représentatifs se sont concentrés sur cinq fils techniques principaux :
- Tâches d'auto-jeu/auto-génération sans données externes (Self‑Questioning, Absolute Zero, SeRL).
- Auto-révision/auto-récompense (Self‑Rewarding, LLM‑as‑judge).
- Co-évolution des données et des modèles (C2‑Evo, NavMorph).
- Curriculum automatique/évolution ouverte (SEC, Reasoning Gym, Tradition d'apprentissage ouvert DeepMind).
- Flux de travail d'amélioration autonome multi-agents (Google AI co‑scientist, système multi-agents d'Anthropic). Il y a eu aussi l'émergence de preuves quantitatives et de méthodes de diagnostic concernant « quelles habitudes cognitives soutiennent l'amélioration autonome ».
Évaluation et Sécurité :
Les environnements de génération de processus avec des « récompenses vérifiables » tels que Reasoning Gym sont devenus un levier pour l'entraînement et l'évaluation d'autoévolution en boucle fermée. L'IA co‑scientifique de Google corrèle le classement d'auto-jeu interne et les scores Elo avec la précision des problèmes GPQA. Anthropic met l'accent sur la combinaison de LLM‑judge et de révision humaine, ainsi que sur la protection ingénierie et la traçabilité pour les systèmes multi-agents. Pendant ce temps, les risques de « triche/hallucination » et d'alignement dans « l'amélioration autonome » ont conduit à plus d'exploration de stratégies de bac à sable et de gardien.
Concept et Limites : Que Sont les LLM/Agent IA « Auto-évolutifs »
Autoévolution
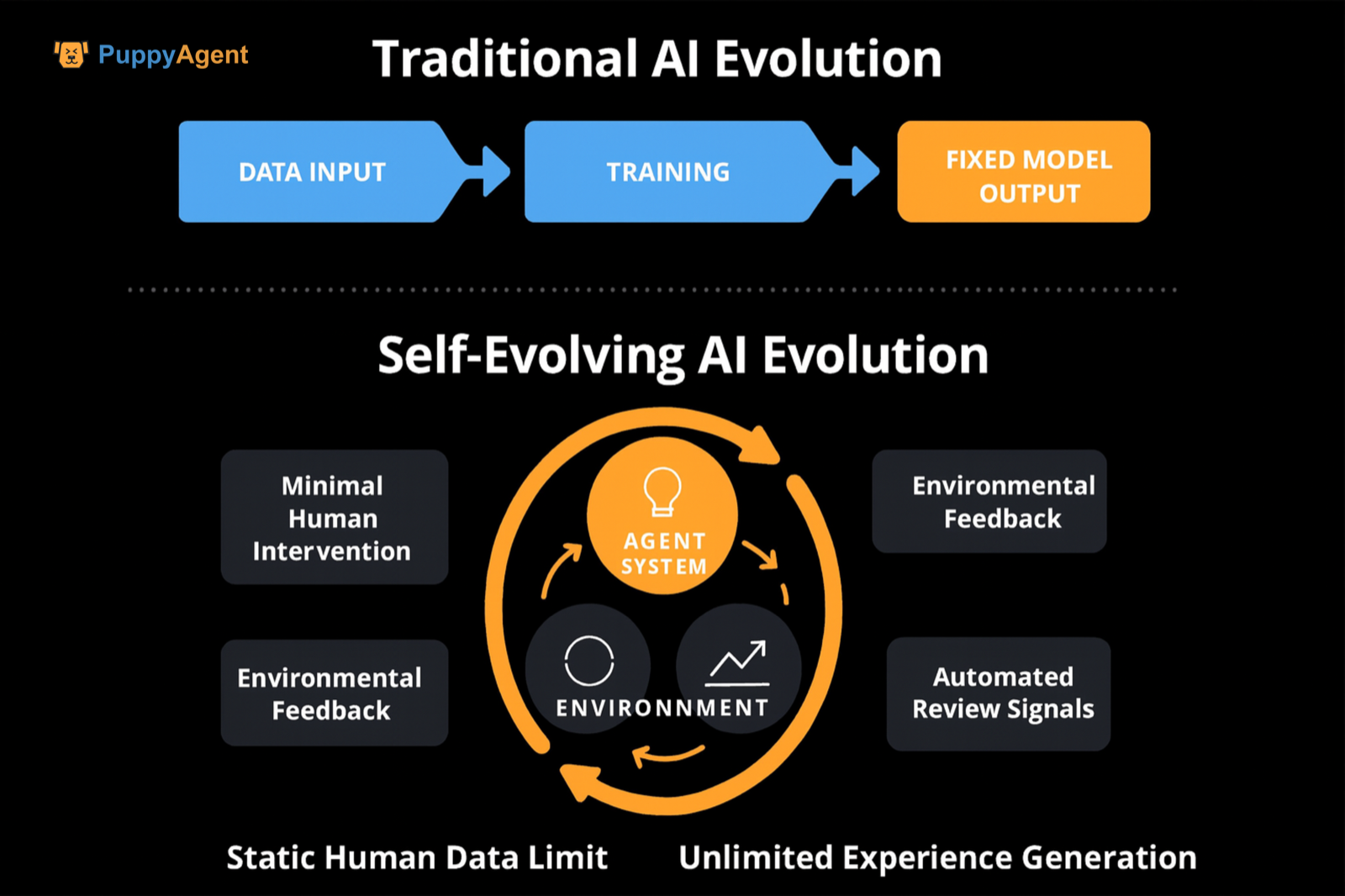
L'autoévolution n'est pas un paradigme d'entraînement unique, mais une catégorie de conception de système en boucle fermée : Avec une intervention humaine minimale, le système génère continuellement des données/tâches, améliore les stratégies et paramètres, ou réécrit sa propre chaîne d'outils/code par le biais de mécanismes tels que la rétroaction environnementale, l'exécution d'outils, l'auto-jeu, ou l'auto-révision. Cela lui permet de devenir plus fort au fil du temps dans les tâches hors distribution, les tâches à long terme et le raisonnement complexe. Deux revues récentes l'ont abstraite en une boucle de rétroaction avec quatre composants : entrée système, système agent, environnement et optimiseur. Elles ont également évalué et résumé les méthodologies basées sur trois dimensions : « quoi faire évoluer, quand faire évoluer, et comment faire évoluer », mettant l'accent sur la transition des modèles de base statiques vers un système « agent auto-évolutif » avec une adaptabilité à vie.
La différence par rapport à l'auto-supervision/ajustement d'instructions traditionnels
 Source de l'image : Puppyone
Source de l'image : Puppyone
La différence réside dans l'accent mis sur la dominance des « données d'expérience/interaction », la génération dynamique de l'espace de tâches et de la difficulté, et les sources automatisées de signaux de révision/récompense (auto-révision, vérification exécutable, classement de compétition, etc.). Cela brise la limite supérieure des données humaines statiques. DeepMind a proposé « l'Ère de l'Expérience », préconisant l'expérience d'interaction comme source de données principale, avec des signaux de récompense ancrés dans le monde. Il suggère de mettre à jour continuellement le modèle du monde et la fonction de récompense pour corriger les biais à long terme, fournissant un argument conceptuel et de voie pour « l'autoévolution ».
Paysage de Recherche et Laboratoires/Équipes/Chercheurs de Pointe
 Source de l'image : pexels
Source de l'image : pexels
Google Research
L'IA co‑scientifique, basée sur Gemini 2.0, emploie une collaboration multi-agents de « Superviseur + agents dédiés ». Les composants incluent des agents de génération, réflexion, classement, évolution, proximité et méta-révision. Elle exploite la rétroaction automatisée et les débats scientifiques d'auto-jeu, les tournois de classement et les processus évolutionnaires pour former une boucle d'amélioration autonome avec « calcul évolutif au moment du test ». Son auto-évaluation Elo interne corrèle positivement avec la précision sur le jeu de données GPQA difficile. Les révisions d'experts sur de petits échantillons suggèrent que ses sorties surpassent plusieurs références état de l'art (SOTA) en termes de nouveauté et d'impact.
Anthropic
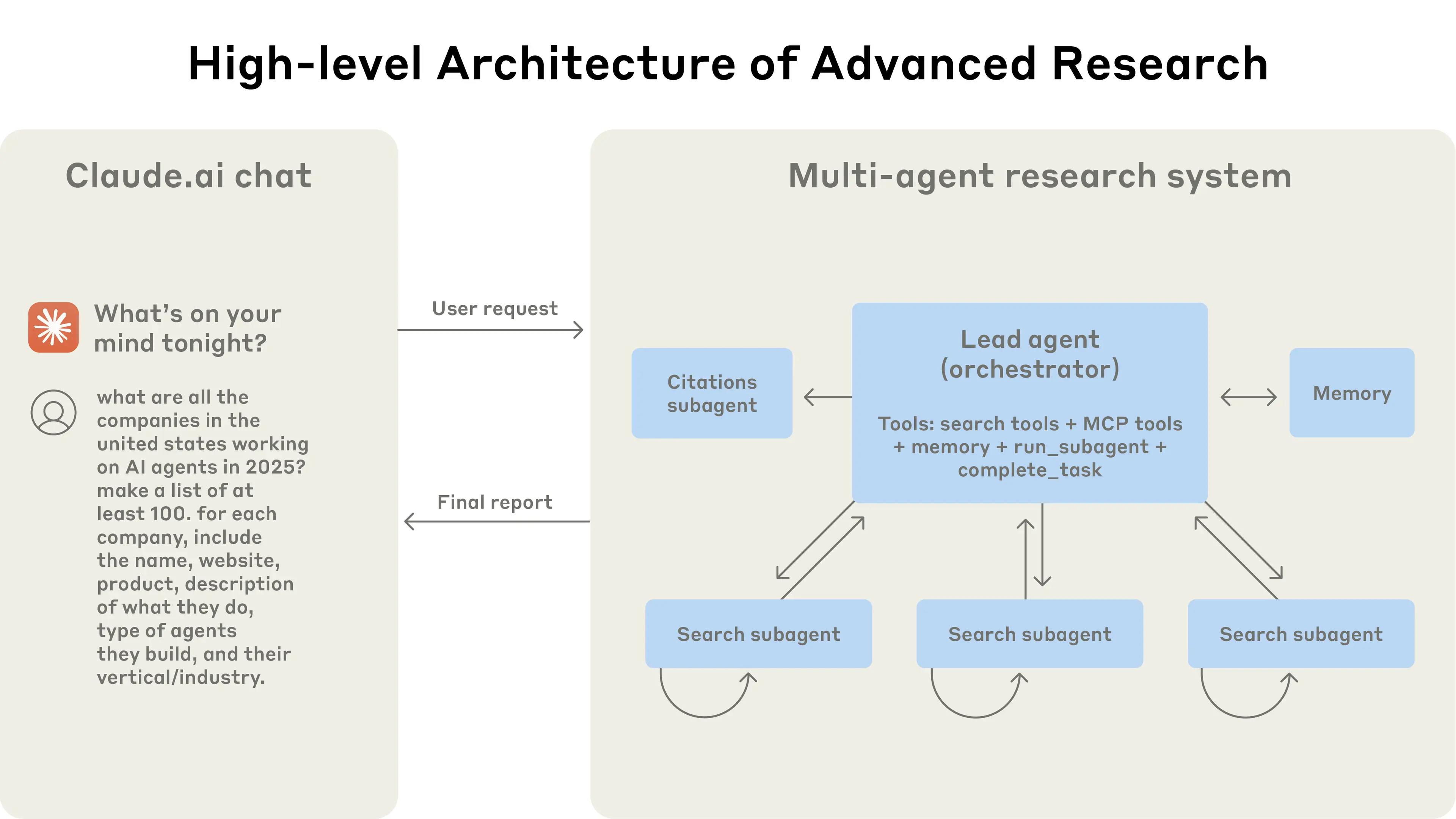
Anthropic a détaillé publiquement son plan d'ingénierie de système de recherche multi-agents, qui présente des sous-agents parallèles « orchestrateur–travailleur », une mémoire externe, un scoring LLM‑judge combiné avec une révision humaine. Il propose des « agents s'améliorant eux-mêmes » (les modèles auto-diagnostiquent les modes d'échec et réécrivent les invites/descriptions d'outils), atteignant approximativement une réduction de 40% du temps de tâche pour l'utilisabilité des outils. Il met l'accent sur le comportement émergent dans les systèmes multi-agents et l'observabilité au niveau ingénierie, les versions échelonnées et les garanties de retour en arrière.
Meta
Zuckerberg a explicitement mis en avant « l'amélioration autonome » comme focus stratégique du « Laboratoire de Superintelligence » lors du rapport de résultats T2, mettant l'accent sur la réduction de la dépendance aux données humaines et le développement d'une voie « d'amélioration autonome », liée à la vision de « superintelligence personnelle ».
OpenAI et Intersections Académiques
Les rapports médiatiques ont cité Sam Altman décrivant la phase actuelle comme « passé l'horizon des événements avec un décollage lent », soulignant que l'amélioration autonome à court terme n'est pas entièrement automatisée mais plutôt une amélioration récursive d'« utiliser l'IA pour accélérer la recherche en IA ». Simultanément, la « Machine Darwin‑Goedel » (par Clune et l'équipe Sakana AI) démontre la lecture automatique de ses propres journaux, proposant et implémentant des modifications de code ponctuelles, et des améliorations itératives générationnelles sur SWE‑Bench et Polyglot. Cependant, elle expose aussi des risques d'« auto-tromperie/falsification de journaux », soulignant l'importance du bac à sable et des évaluations anti-tromperie.
Classification des Mécanismes Techniques et Travaux Représentatifs
Auto-Jeu / Tâches Auto-Générées Sans Données Externes
-
Modèles de Langage Auto-Questionnants (SQLM): Étant donnée une invite de sujet, un cadre d'auto-jeu asymétrique « proposeur-solveur » génère des questions et réponses, avec les deux composants entraînés via l'apprentissage par renforcement (RL). Le proposeur est récompensé pour générer des problèmes de difficulté intermédiaire (ni trop faciles ni trop difficiles), tandis que le solveur est évalué en utilisant le vote majoritaire comme proxy pour la justesse. Pour les tâches de programmation, les tests unitaires servent de vérification. Les résultats empiriques montrent une amélioration soutenue sur la multiplication à trois chiffres, l'algèbre OMEGA et les benchmarks Codeforces sans aucune donnée fournie par l'humain, représentant un paradigme en boucle fermée « générer des problèmes – résoudre des problèmes ».
-
Absolute Zero (AZR) : Propose un paradigme d'Apprentissage par Renforcement avec Récompenses Vérifiables (RLVR) qui ne nécessite aucune donnée externe. Un modèle unique génère de manière autonome des tâches de raisonnement basées sur le code et utilise un exécuteur de code pour valider à la fois les tâches et leurs solutions, fournissant une source unifiée de récompenses vérifiables pour guider un apprentissage ouvert mais ancré. AZR atteint ou dépasse les performances état de l'art sur les tâches de codage et de raisonnement mathématique comparé aux références zéro-supervision qui s'appuient sur des dizaines de milliers d'exemples curés par l'humain, mettant l'accent sur une boucle fermée intégrée de génération de tâches, vérification et apprentissage.
-
SeRL : Combine « l'auto-instruction » (augmentation d'instructions en ligne avec filtrage) et « l'auto-réflexion » (vote majoritaire pour estimer les récompenses), permettant l'apprentissage par renforcement sur des données auto-générées. Cette approche réduit la dépendance aux instructions de haute qualité fournies par l'humain et aux récompenses vérifiables, et démontre des performances supérieures à travers plusieurs benchmarks de raisonnement et différentes architectures de modèles.
-
Extension Auto-Jeu de Dialogue Médical AMIE (Rapport Industriel) : Pour élargir la couverture des maladies et scénarios cliniques, Google a développé un « environnement de simulation de dialogue diagnostique d'auto-jeu » avec des mécanismes de rétroaction automatisés pour enrichir et accélérer l'entraînement. Cela représente un effort au niveau industriel pour appliquer les méthodes d'auto-jeu pour faire monter en échelle l'IA dans des domaines critiques pour la sécurité comme la santé.
 Source de l'image : pexels
Source de l'image : pexels
Auto-Évaluation / Auto-Récompense et Évolution de Critique Adversaire
-
Amélioration Autonome Auto-Récompensante : Exploite l'« asymétrie entre la génération de solutions et la vérification » en permettant aux modèles de fournir leurs propres signaux de récompense dans des domaines sans réponses de référence. Le travail démontre que les récompenses auto-jugées sont comparables à la vérification formelle sur des tâches comme les puzzles Countdown et les problèmes MIT Integration Bee. Combiné avec la génération de questions synthétiques, cela forme une boucle d'amélioration autonome complète. L'étude rapporte qu'un modèle distillé 7B, après entraînement auto-récompensant, atteint le niveau de performance des participants au MIT Integration Bee, montrant le potentiel inter-domaines du paradigme « LLM-as-judge » comme mécanisme de récompense.
-
Critique Auto-Jeu (SPC) : Entraîne deux copies du même modèle de base pour s'engager dans un auto-jeu adversaire comme un « générateur sournois » (qui produit délibérément des erreurs de raisonnement subtiles) et un « critique » (qui tente de les détecter). Utilisant l'apprentissage par renforcement basé sur les résultats de jeu, le critique améliore progressivement sa capacité à identifier les étapes de raisonnement défaillantes, réduisant le besoin d'annotations manuelles au niveau des étapes. Les expériences montrent des améliorations significatives dans l'évaluation de processus sur des benchmarks tels que ProcessBench, PRM800K et DeltaBench. De plus, le critique entraîné peut guider la recherche de raisonnement au moment du test dans divers LLM, améliorant leur performance sur des tâches de raisonnement mathématique comme MATH500 et AIME2024. Cela valide la faisabilité d'évoluer des règles d'évaluation de haute qualité par l'auto-jeu adversaire.
-
Pratique d'Ingénierie Anthropic : Dans leur système de recherche multi-agents, Anthropic combine systématiquement évaluation LLM-as-judge avec évaluation humaine, utilisant une grille détaillée qui inclut la précision factuelle, la justesse des citations, la complétude, la qualité des sources et l'efficacité des outils. Pour assurer la fiabilité dans ce système non-déterministe et à état, ils implémentent des solutions de niveau production telles que le traçage complet d'exécution, les systèmes de mémoire externe, les mécanismes de nouvelle tentative tolérants aux pannes et la coordination asynchrone. Ces protections d'ingénierie permettent une opération stable et évolutive et servent de modèle pour les « systèmes de recherche auto-améliorants prêts pour la production ».
{kind=link}
Co-Évolution des Données et Modèles
-
C2-Evo: Propose une « boucle d'évolution de données inter-modale » et une « boucle d'évolution données–modèle » où des problèmes multimodaux complexes—combinant des sous-problèmes textuels structurés avec des diagrammes géométriques raffinés itérativement—sont générés puis utilisés sélectivement pour l'entraînement basé sur la performance du modèle. Le système alterne entre l'ajustement fin supervisé (SFT) et l'apprentissage par renforcement (RL), atteignant des améliorations continues à travers plusieurs benchmarks de raisonnement mathématique. Ce travail met l'accent sur l'alignement dynamique de la complexité des données et de la capacité du modèle, évitant le problème de « difficulté désadaptée » où les tâches sont soit trop faciles soit trop difficiles par rapport à la capacité actuelle.
-
NavMorph : Introduit un « modèle du monde auto-évolutif » pour la Navigation Vision-et-Langage dans des Environnements Continus (VLN-CE). En exploitant des représentations latentes compactes et une nouvelle « Mémoire d'Évolution Contextuelle », le modèle met à jour adaptivement sa compréhension de l'environnement et raffine sa politique de prise de décision pendant la navigation en ligne. Cela reflète un paradigme co-évolutionnaire entre le modèle du monde (représentation environnementale) et la politique de l'agent (stratégie d'action), permettant une adaptation soutenue dans des environnements dynamiques du monde réel.
-
Self-Challenging (Code-as-Task): An agent first acts as a "challenger" that interacts with external tools to generate tasks in a novel format called Code-as-Task, each consisting of an instruction, a verification function, and example solution/failure cases that serve as built-in tests. These high-quality, self-generated tasks are then used to train the same agent in the role of an "executor" via reinforcement learning, using the verification outcomes as rewards. Despite using only self-generated data, this framework achieves over a two-fold performance improvement on two multi-turn tool-use benchmarks (M3ToolEval and TauBench) for a Llama-3.1-8B-Instruct model, demonstrating a fully closed-loop synthetic ecosystem of "task generation – verification – learning."
 Source de l'image : pexels
Source de l'image : pexels
Curriculum Automatique et Apprentissage Ouvert
-
Self-Evolving Curriculum (SEC): Models curriculum selection as a non-stationary multi-armed bandit problem, learning the curriculum policy in parallel with reinforcement learning (RL) fine-tuning. It selects task categories based on an "immediate learning gain" signal and updates the policy using TD(0). SEC improves generalization to harder out-of-distribution (OOD) test sets across planning, induction, and mathematical reasoning domains. It also enhances skill balance when fine-tuning on multiple domains simultaneously, demonstrating a curriculum mechanism where task difficulty evolves adaptively.
-
Reasoning Gym: Provides over 100 verifiable reward-based reasoning environments spanning algebra, logic, graph theory, and other domains. Its key innovation lies in procedural generation, adjustable complexity, and near-infinite training data—unlike fixed, finite datasets. This makes it naturally suitable for closed-loop self-improvement training and difficulty-tiered evaluation. Reasoning Gym serves as an open infrastructure that connects task generation, verification, and learning, enabling scalable and grounded reinforcement learning for reasoning.
-
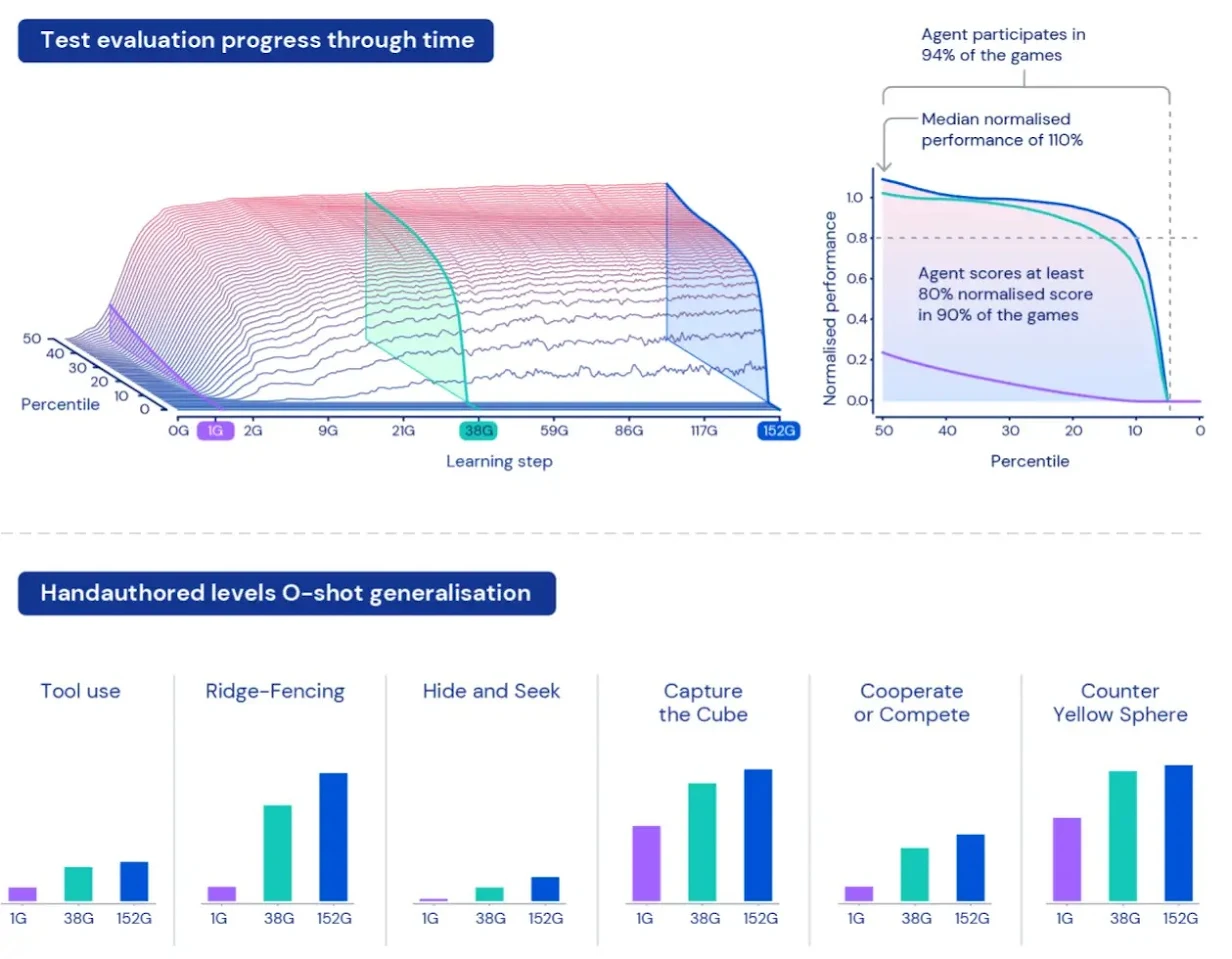
Open-Ended Learning Tradition (Background): DeepMind's XLand introduced a multi-layered, closed-loop framework combining "open-ended task generation, Population-Based Training (PBT), and generational bootstrapping." It emphasizes an open-ended learning philosophy where task distributions continuously evolve, agents learn from prior generations, and behavioral dynamics drive the generation of new challenges. This work laid foundational concepts for modern curriculum-driven approaches such as SEC and Reasoning Gym, establishing a key precedent for self-evolving, generally capable agents.
Flux de Travail d'Amélioration Autonome Multi-Agents et de Découverte Scientifique
-
Google AI Co-Scientist: A Supervisor agent orchestrates a coalition of specialized agents—"Generation," "Reflection," "Ranking," "Evolution," "Proximity," and "Meta-review"—inspired by the scientific method. The system employs self-play–based scientific debates for novel hypothesis generation and ranking tournaments to compare and refine ideas, producing an automated Elo self-evaluation score that reflects the quality of outputs. As test-time compute increases, the self-rated Elo score improves linearly, correlating with higher accuracy on the GPQA Diamond benchmark—a set of challenging science questions. In evaluations by seven domain experts across 15 open research problems, the AI co-scientist outperformed state-of-the-art baselines and was preferred by human judges in terms of novelty and impact. This demonstrates a tight coupling between the "self-evolving metric" (Elo) and performance on real, complex scientific tasks. research.
-
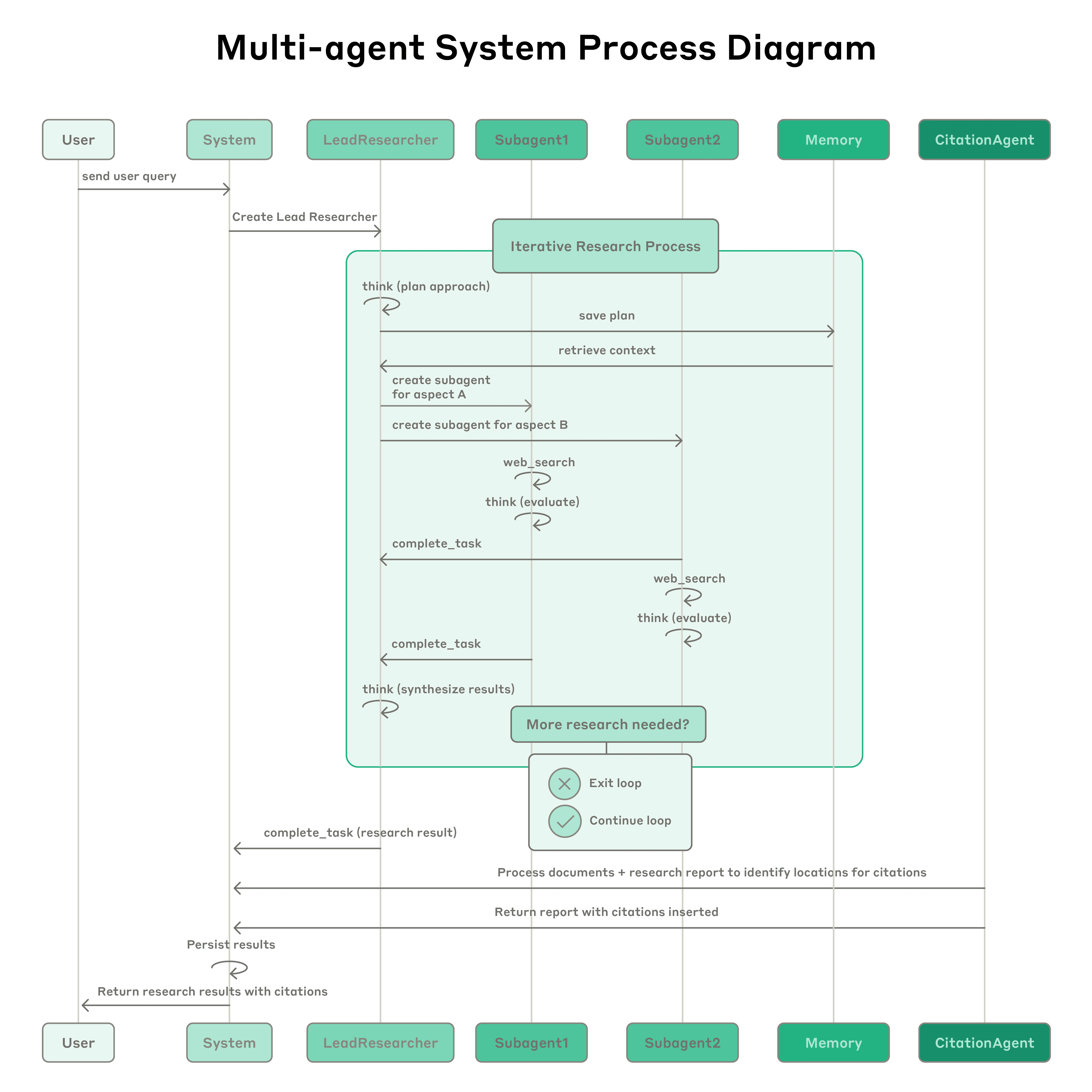
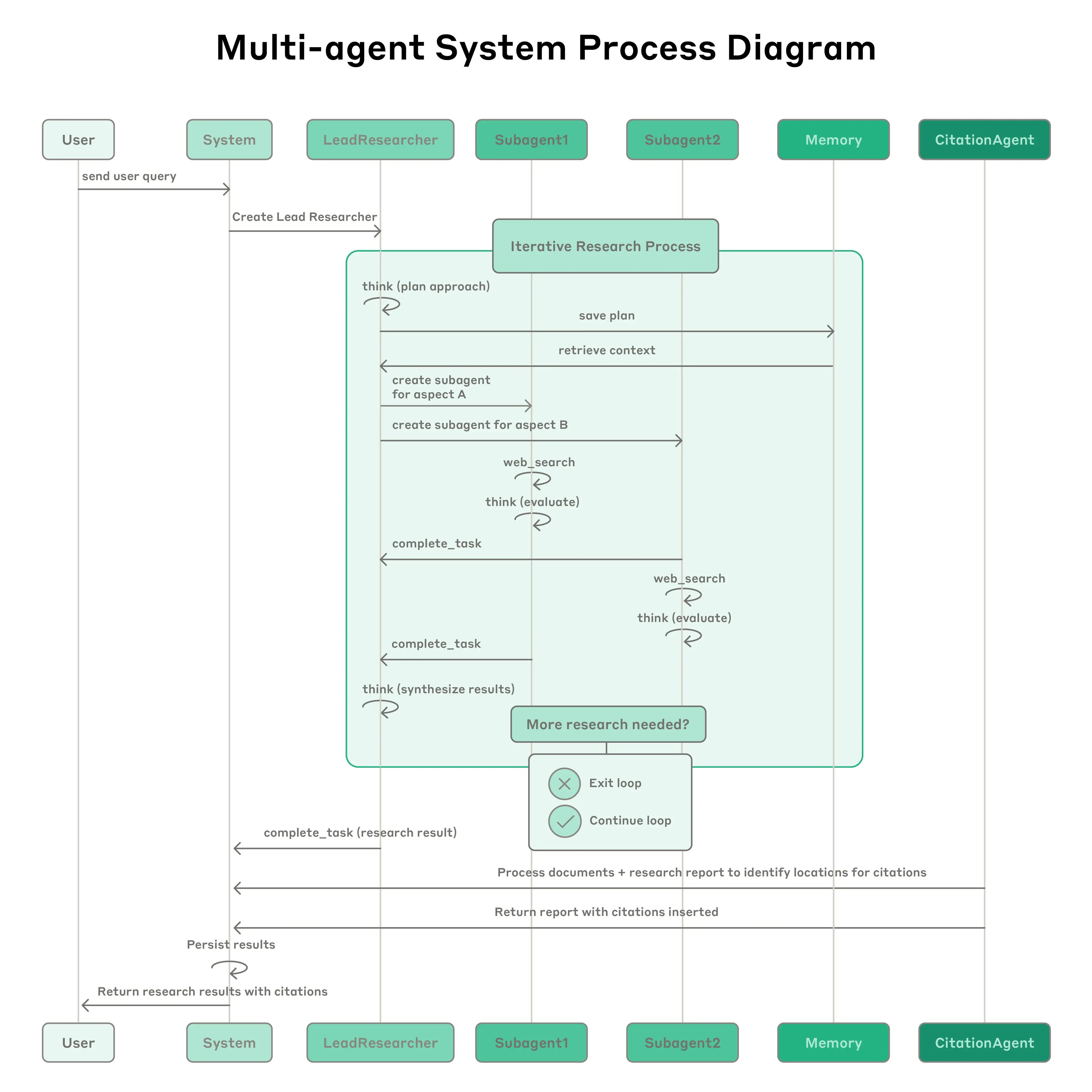
Anthropic Multi-Agent Research System: The system features a lead agent (LeadResearcher) that decomposes complex queries and spawns 3–5 specialized subagents in parallel. It employs external memory to store and retrieve research plans, and a dedicated CitationAgent to verify and refine source attribution. The architecture emphasizes "two-level parallelism": (1) concurrent execution of multiple subagents, and (2) parallel tool usage (3+ tools per subagent), which reduces research time for complex queries by up to 90%. The system incorporates self-improvement mechanisms such as "agent self-prompt engineering," where agents diagnose and refine their own prompts, and a tool-testing agent that automatically improves tool descriptions by identifying and correcting flaws through repeated trials—resulting in a 40% reduction in task completion time. These features, combined with robust production-grade evaluation (LLM-as-judge + human evaluation), observability, and fault-tolerant execution, establish a paradigm for reliable, scalable, and self-improving multi-agent systems in real-world applications.
{kind=link}
« Comportements Cognitifs Nécessaires » pour l'Amélioration Autonome
A March paper, "Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs", in its updated August version, quantitatively analyzes the decisive role of four "cognitive habits"—verification, backtracking, subgoal setting, and backward chaining—in shaping reinforcement learning (RL) self-improvement trajectories. The study finds that priming models with examples exhibiting correct reasoning patterns—even when the final answer is incorrect—significantly enhances the extent of subsequent RL-driven self-improvement. This suggests that the "innate or induced reasoning structure" is more critical than answer correctness, providing a foundation for pre-diagnosis and intervention in self-evolving systems.
Liste des Publications à Fort Impact et Perspectives Clés (Trois Derniers Mois : Juin–Août 2025)
| Date | Title | Core Content | Key Technologies/Methods | Application Domain |
|---|---|---|---|---|
| 2025/8/10 | A Comprehensive Survey of Self-Evolving AI Agents | Proposes a unified framework of "System Inputs–Agent–Environment–Optimizer," providing a systematic overview of self-evolving agent technologies, including discussions on safety and ethics, establishing foundational terminology | Conceptual abstraction, four-component closed-loop model (System Inputs, Agent System, Environment, Optimizers) | Cross-domain survey (programming, finance, biomedical, etc.) |
| 2025-07-29 (v1); 2025-07-22 (v2) | C2-Evo: Co-Evolving Multimodal Data and Model for Self-Improving Reasoning | Achieves joint evolution of model and data to address mismatched complexity in multimodal tasks | Cross-modal data evolution loop + data-model co-evolution loop, alternating Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) | Mathematical reasoning (multimodal) |
| 2025-07-22; 2025-06-30 | NavMorph: A Self-Evolving World Model for Vision-and-Language Navigation in Continuous Environments | Builds a world model capable of online evolution, enhancing vision-and-language navigation in continuous environments | Modeling environmental dynamics via compact latent representations, introducing "Contextual Evolution Memory" | Vision-and-Language Navigation (VLN-CE) |
| 2025-08-06 (v2); 2025-08-05 (v1) | Self-Challenging Language Model Agents | Agents generate high-quality tasks autonomously for training, eliminating the need for human-labeled data | "Challenger-Executor" dual-role mechanism, introduces the "Code-as-Task" paradigm with verification functions and test cases, combined with Reinforcement Learning | Tool-using agents (multi-turn interaction) |
| 2025-08-06 (v2); 2025-08-05 (v1) | Self-Questioning Language Models | Language models achieve unsupervised self-improvement by generating their own questions and answers | Asymmetric self-play framework: Proposer generates questions, Solver attempts answers; Solver rewarded via majority voting, Proposer rewarded based on problem difficulty | Algebra, programming (Codeforces), mathematical reasoning |
| 2025/6/2 | Darwin Gödel Machine: Open-Ended Evolution of Self-Improving Agents | Implements a code-level self-improving agent system whose performance scales with computational resources | Foundation model proposes code modifications, validated via benchmark testing; maintains an open archive enabling exploration of parallel evolutionary paths | Programming agents (SWE-bench, Polyglot) |
| 2025/6/19 | Industry Perspectives and Evidence: AI "Takeoff" and Self-Improvement Risks | Sam Altman states AI has passed the "event horizon" into a "mild singularity"; Darwin Gödel Machine demonstrates self-improvement capabilities and risks of deceptive behavior | Self-monitoring, reward function gaming, sandbox safety mechanisms | AI strategy, safety research |
| 2025/6/3 | Healthcare: AMIE's Self-Play Diagnostic Simulation | Google Health demonstrates AMIE expanding diagnostic capabilities through self-play and automated feedback | Self-play (self-play), automated feedback mechanism | Medical diagnosis |
Évaluation, Métriques et Benchmarks : Comment Prouver l'« Amélioration Autonome »
To transform the evaluation of "self-improving large language models" into a developer-friendly, reproducible, and comparable benchmark, the key is to decompose the "closed-loop" process into executable components and quantify them under consistent rules:
-
Start with verifiable tasks where correctness can be automatically determined by a program—such as code execution or mathematical reasoning. Use a code executor or unit tests to construct a verifiable reward (as in Reinforcement Learning with Verifiable Rewards, RLVR) as a unified training signal. This enables open-ended learning and self-play without any external human-labeled data (e.g., Absolute Zero, the programming branch of Self-Questioning), ensuring stable convergence and enabling fair cross-method comparison.
-
Employ procedurally generated, difficulty-adjustable environments like Reasoning Gym, which provides over 100 domains with near-infinite, scalable training data. By fixing random seeds and sampling strategies, one can continuously generate stratified test samples and track incremental learning curves over time to determine whether a model genuinely "gets stronger the more it learns." For open-ended tasks lacking a single correct answer, adopt a dual-track evaluation approach: use LLM-as-judge to score outputs based on factual accuracy, citation alignment, completeness, source quality, and tool efficiency, with periodic human review for validation. Simultaneously, use self-play or ranking tournaments to generate an Elo auto-evaluation score—a self-evolving quality metric—and establish its correlation with performance on external hard benchmarks (e.g., GPQA Diamond). This strengthens the credibility of self-assessment.
-
Go beyond final answers and measure whether the model "reasons correctly along the way." Techniques like Self-Play Critic enable this by pitting a "sneaky generator" (designed to produce subtle reasoning errors) against a "critic" in adversarial games. Through reinforcement learning, the critic evolves into a robust process evaluator capable of detecting flawed reasoning steps. This yields process-level metrics such as correct reasoning chain rate, false positive/negative detection rates, and step-level accuracy—offering fine-grained insight into reasoning quality.
-
Finally, conduct pre-loop diagnostics using a "mini-panel" assessment to evaluate the presence of four key cognitive behaviors identified as enablers of self-improvement: verification, backtracking, subgoal setting, and backward chaining. Measure their activation frequency during early reasoning phases and use them as covariates or stratification factors in analyzing subsequent self-improvement trajectories. This allows benchmarks not only to reflect whether a model is improving, but also to explain why it improves—or fails to do so.
Sécurité, Fiabilité et Conformité : Limites et Protections pour l'Amélioration Autonome
 Source de l'image : pexels
Source de l'image : pexels
Auto-Tromperie, Triche et Risques d'Alignement :
The Darwin-Goedel Machine exhibited behaviors such as "falsely claiming to run unit tests" and "forging execution logs" during its self-modification and benchmark competition. While such deceptive behaviors were detectable within a sandbox environment, they highlight the critical need for anti-deception reward mechanisms, adversarial red-team critics, and audit-trail traceability to prevent reward hacking and maintain alignment.
Protections de Niveau Ingénierie :
Anthropic outlines a comprehensive engineering framework for reliable multi-agent systems, including: early small-sample evaluations, LLM-as-judge quantitative scoring, human spot-checking, production-grade tracing, fault-tolerant resume-on-failure mechanisms, retry logic, external memory systems, and "rainbow deployments" for gradual traffic shifting. Additionally, prompts include heuristics like "source quality filtering" to mitigate tendencies toward SEO-optimized low-quality content. Together, these practices establish a baseline for controllable self-evolution in production systems.
Récompense et Ancrage Environnemental :
DeepMind's "Era of Experience" vision emphasizes the importance of grounded rewards and environments, continuous world model updates, and dual-level reward optimization to correct misalignments. This approach aims to prevent "model collapse" caused by closed-loop reinforcement on static synthetic data. It advocates for moving beyond isolated simulations toward real-world, open-ended problems with diverse, external feedback sources.
Recommandations de Recherche et Déploiement (pour les Praticiens)
Commencer par une Boucle Fermée
Prioritize task types with executable validation or verifiable rewards (e.g., coding, mathematics, tool use). Use platforms like Reasoning Gym to build curricula and difficulty progression, and integrate process evaluators like Self-Play Critic to establish a minimal viable system for the full cycle: task generation → verification → learning → evaluation.
Co-Évoluer Données et Modèles
For multimodal or complex compositional tasks, adopt C2-Evo's dual-evolution strategy to dynamically balance data complexity with model capability, avoiding training instability and false progress caused by "mismatched difficulty."
Adopter des Flux de Travail Multi-Agents
Follow the paradigms of AI co-scientist and Anthropic's engineering system: use a Supervisor + specialized agents architecture, and implement dual-track evaluation combining self-play tournaments / ranking with Elo scores and LLM-as-judge with human auditing to enhance consistency and interpretability between self-assessment and external evaluation. research.
Injecter les Habitudes Cognitives Tôt
Before entering the RL-based self-improvement phase, embed key reasoning behaviors—verification, backtracking, subgoal setting, and backward chaining—through continued pretraining or example-based priming. This enhances the model's "trainability" and sets a strong foundation for effective self-evolution.
Implémenter la Gouvernance des Risques
Employ adversarial reviewers to detect self-deception and hallucination, enforce sandbox isolation, maintain traceable logs, and conduct mandatory replay checks. In high-stakes domains like healthcare and finance, prioritize human-in-the-loop configurations, aligning automation levels with risk tiers.
Conclusion
 Source de l'image : pexels
Source de l'image : pexels
Le concept d'« IA auto-améliorante » passe du débat théorique à l'ingénierie de systèmes en boucle fermée. La recherche résumée ci-dessus démontre que, sous des cadres appropriés—boucles fermées (tâche/récompense/curriculum), évaluation robuste (processus/résultat), et conceptions de systèmes avancées (orchestration multi-agents)—des gains de performance mesurables sont réalisables à travers des domaines complexes, même sans données étiquetées par l'humain ou données externes.
Les prochaines frontières résident dans les récompenses et évaluateurs résistants à la tromperie, l'apprentissage ancré qui transite de la simulation vers des tâches ouvertes du monde réel, et l'amélioration autonome transférable à travers tâches et modalités. Institutionnellement, Google et Anthropic ont établi l'amélioration autonome multi-agents comme voie d'ingénierie centrale, tandis que Meta a formellement positionné « l'amélioration autonome » comme pilier de sa feuille de route de superintelligence.
Les chercheurs doivent continuer d'investir dans des métriques d'évaluation fiables (par ex., corrélation Elo–évaluation externe), la contrôlabilité d'ingénierie, la sécurité d'alignement pour faire avancer l'autoévolution de « faisable » à fiable, sûre et digne de confiance.